
 起点课堂会员权益
起点课堂会员权益别再手动搬运竞品动态了!我用 3 小时手搓了一个“AI 情报工厂”,效率直接提升 70%
AI正在彻底重构产品经理的竞品分析工作流。本文通过实战案例揭秘如何用3小时搭建AI Skill,实现情报自动收集、智能去重与深度洞察,节省70%重复劳动时间。从Python脚本预处理到LLM语义分析,带你掌握从"数据泥潭"到"战略决策"的关键跃迁。

在日常工作中,“竞品分析”往往是一场漫长的拉锯战。传统的流程是:
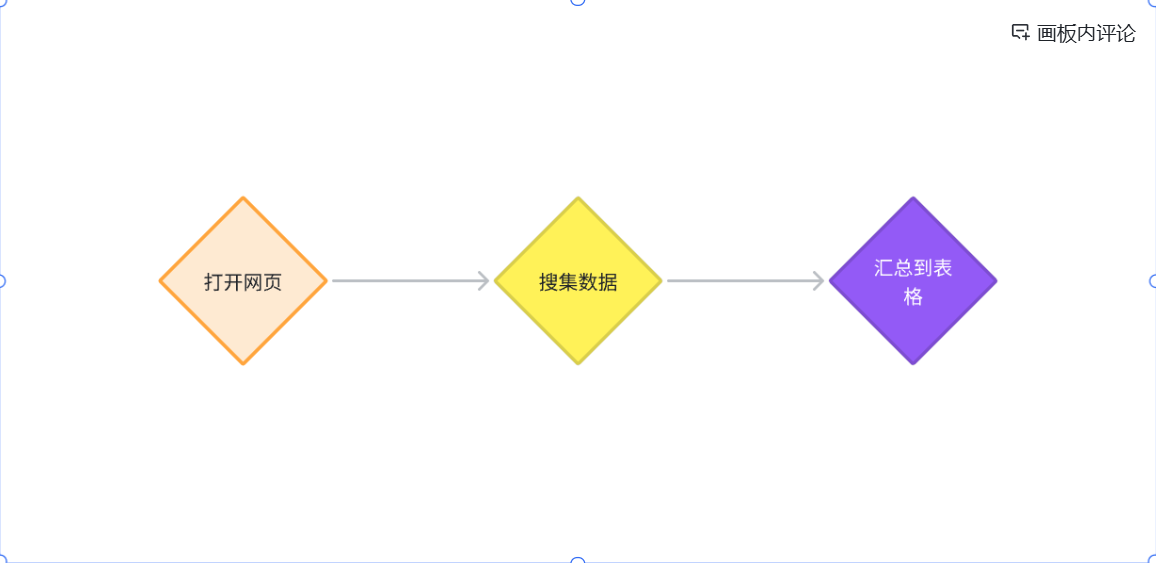
这种工作模式不仅效率极低,更让我们陷入了“低水平重复劳动”的怪圈。然而,AI 时代的到来打破了这一僵局。
我的实战初体验: “从梳理逻辑框架到确定分析方向,再从调试 Prompt 到最终完成 AI Skill 的搭建,我仅仅用了短短三个小时。这套 Skill 不仅自动完成了海量数据的搜集,还贴心地附带了原链和深度总结。最直观的感受是——它为我节约了 70% 的重复性工作时间。”
这意味着,我们终于可以从繁杂的数据收集泥潭中抽身,将精力真正投入到更具价值的战略思考与产品决策中。
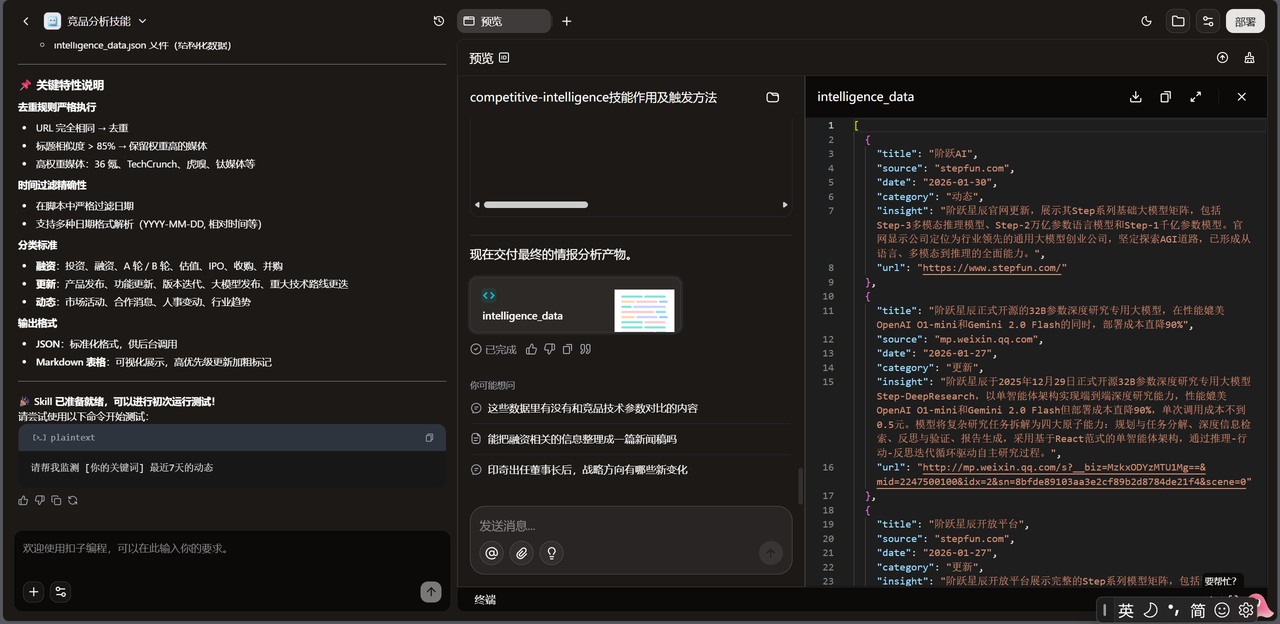
实战拆解:从“业务直觉”到“自动化工具”的深度博弈
逻辑博弈:从“视觉幻想”回归“工程落地”
在最初的构思中,我准备的是“全栈式可视化”方案:通过Canvas渲染表格看板,设置交互按钮。然而,在与 AI 深度对齐需求后,进行了一次的 MVP降级。
1. 放弃 Canvas 按钮,拥抱自然语言交互
- 痛点发现: AI 提示 Skill并非独立 App,自定义 UI 的维护成本高且响应存在随机性 。
- 决策转变: 对于我们而言,自然语言才是最天然的“按钮”。直接对 AI 说“把第 3 条生成周报”或“对比这几家的融资规模”,效率远高于在一个固定 UI 中寻找按钮。
- 价值升华: 更符合移动办公场景下的交互直觉。
2. 脚本过滤(Python)vs LLM 语义过滤
- 技术博弈: 很多同行习惯将所有逻辑交给大模型,但大模型对“日期”的敏感度存在幻觉
- 决策转变: 我坚持使用 Python 脚本进行预处理 。
- 为什么这么做?数据确定性: 脚本能严格解析 date 字段,确保剔除 7 天前的情报。以获取最新的资讯 。
- 协议标准化: 脚本生成的标准 JSON 格式 ,让我后续可以将数据一键导出/同步至其他自动化办公软件(如飞书多维表格),实现了数据链路的彻底打通。

{{
我现在准备搭建一个“竞品/行业情报分析”的skill。 我的搭建框架是:“输入关键词、并行搜索插件、python逻辑:清洗&去重、LLM分类&摘要、代码块:转化UI所需JSon、前端Canvas:表格渲染、用户交互按钮” 我会一步一步的和你去对需求,你需要在得到我的认可后,才可以开始行动,你可以给我一些做的建议,最终执行以我给你的命令为主。
}}
PM 笔记:架构审计师的自觉
“一个好的 AI 助手不应是盲从的‘复读机’。它基于平台规范(Skill 规范)给出的‘劝退建议’,实际上是在帮我避开 2 小时的无效开发坑位 。作为 PM,我关注的是数据的准确性与洞察的深度,而不是表格的像素边框。”

为什么 AI “唱反调”反而是好事?
作为 PM,我立刻意识到这次“改动”带来的三大优势:
- 极致的交付速度(MVP 逻辑): 放弃自定义 Canvas 意味着无需调试复杂的样式代码。利用原生的 Markdown 渲染,可以确保情报以最快速度、最稳的格式输出到任何平台(扣子、企业微信或网页)。
- 确定性 vs. 随机性: UI 按钮在 Skill 中往往存在响应不确定性。将逻辑下沉到 Python 脚本中进行“格式化 JSON”处理,把显示交给原生系统,极大地降低了出错率,保证了数据链路的确定性。
- 解耦思维: AI 提醒我“脚本只负责数据处理,交互发生于对话中”。这迫使我回归本质——PM 应该关注数据的准确性与洞察的深度,而不是纠结于一个表格的像素边框。
PM笔记: 一个好的 AI 助手不应该是“复读机”,而应该是“架构审计师”。它基于平台规范(Skill 规范)给出的调整建议,帮我绕过了2 小时的无效开发坑位。
根据反馈提供信息

{{
收到,我采纳了你的建议框架,针对你提出的技术细节,我确认如下方案:
搜索方式: 利用智能体原生搜索能力(插件方式),无需脚本,请配置 Google Search 或相似搜索工具。
LLM 方案: 使用扣子平台自带的默认 LLM。
输出格式:
>
– 需要生成结构化 JSON,包含:title(标题)、source(来源)、date(日期)、category(分类:融资/更新/动态)、insight(核心洞察)、url(链接)。 同时输出一份 Markdown 格式的聚合摘要。
数据源:
>
– 支持多关键词组合搜索。 限定搜索最近 7 天内的情报。 优先抓取主流科技媒体和竞品官网信息。
方案对齐完毕,请据此准备执行逻辑,但在开始搭建前,请先向我展示你设计的逻辑流图。
}}
深度算法设计:如何实现“零噪音”的情报流?
在海量信息抓取中,最怕的就是“融资通稿”满天飞。为了解决这个问题,我给 AI 下达了三个维度的去重指令,实现从物理查重到语义查重的进阶。
第一层:强一致性校验(物理层面)
逻辑: 严格匹配 URL。
价值: 直接剔除完全相同的网页链接,这是最基础的过滤,无需 LLM 参与,节省 Token。
第二层:模糊标题匹配(字符串层面)
逻辑: 设置“标题相似度 > 85%”的判定阈值。
价值: 解决“通稿问题”。例如《千问发布 Qwen2.5》和《阿里开源 Qwen2.5,性能大幅提升》,这两者在字符上高度重合,通过模糊算法可以精准识别为同一事件。
第三层:媒体权重路由(业务层面)
逻辑: 如果判定为重复,系统不会随机删除,而是根据预设权重保留链接。
排序规则: 优先保留 主流科技媒体(如 36Kr、IT 桔子)或 竞品官网,因为这类来源通常包含更详细的背景或更准确的参数。
PM 笔记:为什么“去重”是分析的灵魂?
“没有去重的情报流叫‘信息垃圾’。通过 Python 脚本解析 URL + LLM 判定相似度 ,我将原始抓取的 50+ 条数据压缩到了 5 条核心动态。这种‘高信噪比’的输出,才是我敢在周会上展示的底气。”
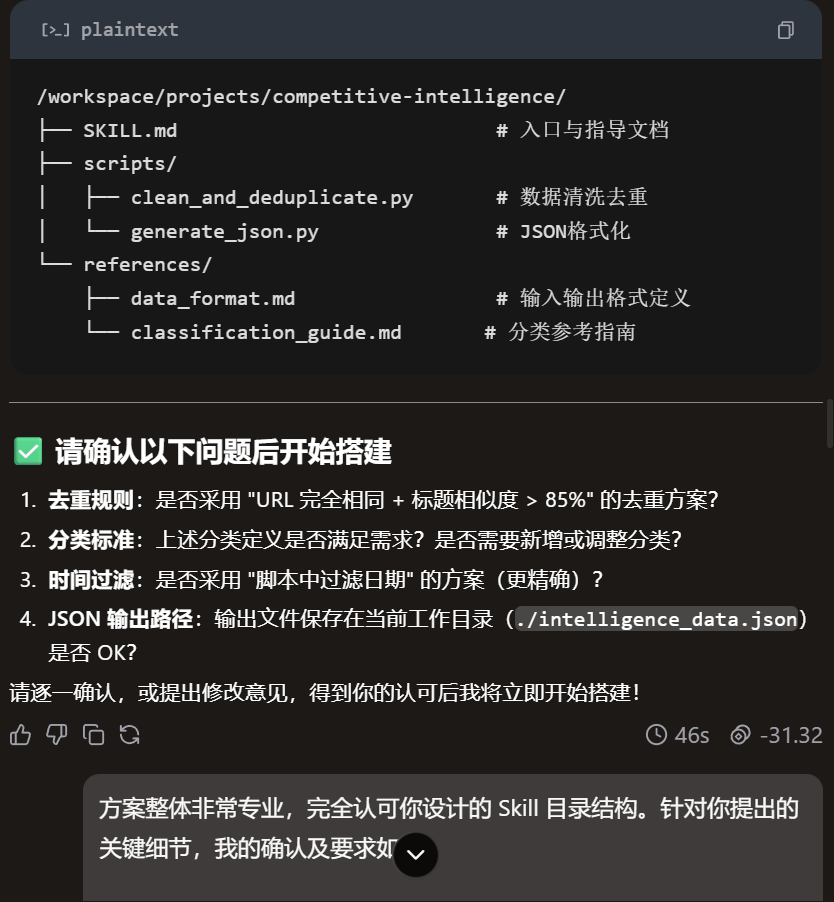
{{
方案整体非常专业,完全认可你设计的 Skill 目录结构。针对你提出的关键细节,我的确认及要求如下:
1.关于去重规则:完全同意: 采用 “URL 完全相同 + 标题相似度 > 85%” 的方案。 额外要求: 如果是来自不同媒体但内容高度相似的消息,请在去重后保留权重最高(如知名科技媒体)的那个链接。
2.关于分类标准:
基本分类 OK: 融资、更新、动态这三个维度满足 MVP(最小可行性产品)需求。
逻辑微调: 请确保“大模型发布/重大技术路线更迭”被优先归类在“更新”中,并标记为“高优先级”。
3.关于时间过滤:坚定选择方案 B(脚本过滤): 作为产品,我们需要数据的绝对准确。请在脚本中解析网页发布时间,严格剔除 7 天前的内容。
4.关于数据输出(核心要求):
路径确认: JSON 存储在 ./intelligence_data.json 没问题,这是为了方便后台调用。
展示形态(重点): 最终输出给我的内容,必须包含两部分:
文字摘要: 用一段话概括过去 7 天该竞品/行业的最核心变化。
情报列表(表格形式): 使用 Markdown 表格呈现,表头需包含:日期 | 动态标题 | 分类 | 核心洞察 | 来源链接。
确认完毕,逻辑方案正式通过。请立即开始搭建,并在完成后通知我进行初次运行测试!
}}
完成Skill制定
测试Skill能力
最近千问有哪些更新?

“情报工具”到“AI 自动化流水线”
它是一套“通用型结构化信息处理引擎”。作为产品经理,一旦你掌握了“数据抓取 + 脚本逻辑清洗 +LLM洞察”的公式,你便拥有了在不同业务场景中手搓自动化工厂的能力。
场景平移:打破业务边界的万能模版
这套底层逻辑可以无缝平移至以下高价值领域,实现业务流程的重塑:
- VOC(用户声音)智能聆听:传统痛点: 面对小红书、知乎、App Store 数以万计的碎片化评论,人工分析往往只能“管中窥豹”。
- AI 方案: 全网爬取 -> Python 脚本语义去重 -> AI 提取核心槽点/需求趋势 -> 自动生成实时需求看板。
- HR/招聘全链路提效:传统痛点: 简历初筛耗费大量人力,且容易受主观偏向影响。
- AI 方案: 简历结构化提取 -> 脚本自动化匹配 JD 核心关键词 -> AI 评估契合度并生成定制化面试建议。
- 私域/社区运营“全能监控”:传统痛点: 社区内容杂乱,水贴横行,人工预警响应慢。
- AI 方案: 关键词监控 -> 逻辑过滤水贴(低代码脚本) -> 自动回复或触发重大舆情预警。
- 前沿技术趋势前哨站:传统痛点: Arxiv 或 Github 信息密度极高,技术门槛大,难以快速吸收。
- AI 方案:动态追踪 -> 自动提取论文核心架构逻辑 -> 生成一分钟技术简报。
PM 的深度思考:为什么我们要亲自“手搓”?
我们需要为我们的PRD负责,这是为我们自己节约时间:
- 极低的试错成本: 验证一个自动化逻辑不再需要数周的开发周期,只需 3 小时的 Prompt 调优与脚本联调。
- 绝对的逻辑掌控: 只有 PM 最懂业务的“清洗规则”(比如哪些属于水贴,哪些是关键融资),亲自定义脚本逻辑确保了结果的高信噪比。
- 从“提需求的人”到“解决问题的人”: 这种能力的跃迁,让你不再受限于技术资源,成为真正意义上的“全栈超级个体”。
提效量化:从“体力搬运”到“秒级响应”
通过对比“传统人工模式”与“Coze 2.0 Skill 模式”,我们可以直观地看到 AI 对产品经理工作流的重塑:
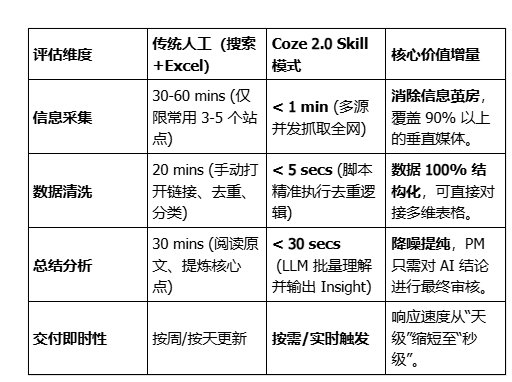
深度洞察:省下的时间去哪了?
以前需要一整个下午(约 4 小时)才能完成的深度行业周报,现在只需输入关键词后等待 3 分钟 。
这节省下来的 70% 重复劳动时间,并不是用来摸鱼的,而是让产品经理能够回归本源:
- 竞品策略拆解: AI 告诉我对方更新了功能,我去思考对方为什么要在这个时间点更新?
- 市场预判: 结合融资动态,判断行业是否进入了新的技术整合期。
- 用户价值回溯: 看看这些动态对我们现有的用户需求会产生什么冲击。
️同行复刻指南:三步走方法论
SOP流程奉上:
第一阶段:定义“数据协议”(Data Schema)
- 核心逻辑: 别急着连线,先想清楚你的输出表格需要哪些字段(标题、链接、评分等)。
- 价值点: 明确了输入和输出,AI 才能精准生成脚本。
第二阶段:善用“人机协作编程”(Low-Code Collaboration)
- 核心逻辑: PM 只需提出“业务判别准则”(如:相似度 85% 就去重),把实现的 Python 代码交给扣子助手。
- 价值点: 实现了“原型即成品”。PM 不再受限于研发排期,自己就是架构师。
第三阶段:UI 交互闭环(Experience Design)
- 核心逻辑: 抛弃纯对话框,使用 Canvas 搭建可视化看板,并加入交互按钮(如“同步到飞书”)。
- 价值点: 提升了工具的“可复用性”和“组织渗透力”。
结语:给同行的一段话
“在 1.0 时代,我们是在和 AI 聊天;在 2.0 时代,我们是在用 AI 组装工厂。低代码模式让产品经理重新夺回了‘定义逻辑’的权力。未来的 PM,不再是写 PRD 催开发的人,而是那个能直接手搓 AI 原生应用解决业务问题的‘全栈超级个体’。”
本文由 @Junliu 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议









文章AI味这么重,你自己知道吗
我知道,然后呢,重要吗,本身就是推荐ai工具,我自己不用,我没法给你们推荐