
 起点课堂会员权益
起点课堂会员权益大模型知道消耗了多少Token吗?
大模型如何计算Token消耗?ChatGPT与DeepSeek给出了截然不同的答案。从装修咨询案例切入,本文深度对比两大模型在Token计算逻辑、工程底层实现与系统架构设计的差异,揭秘为何ChatGPT会"装傻"而DeepSeek能精确拆解,并附赠专业场景下的省Token实战技巧。

我分别向ChatGPT、DeepSeek提问,他们给出了我不同的答案。
不清楚Token是什么的朋友,可以看我的这篇文章一文彻底讲清楚Token
01 先看DeepSeek
在一个装修违约问题咨询的会话中,我问当前对话消耗Token数量以及原因。
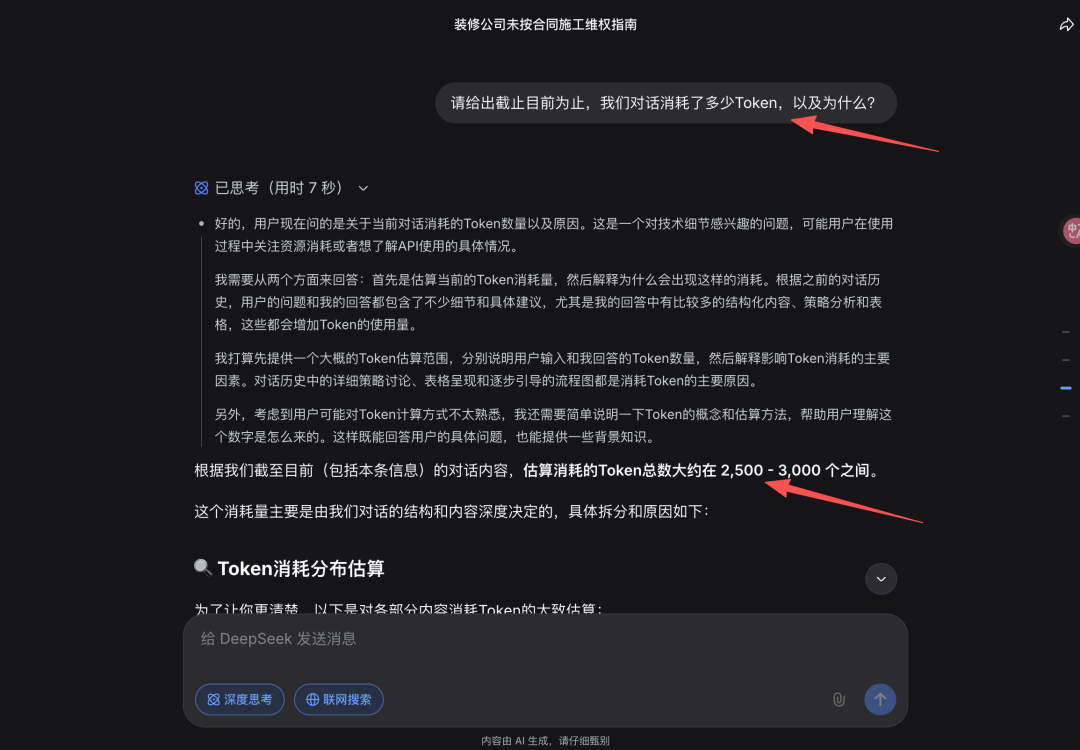
DeepSeek给了我一个估算的消耗Token总数范围,并且给出具体拆分和原因:
总消耗Token=我的问题消耗Token + 模型回答消耗Token。
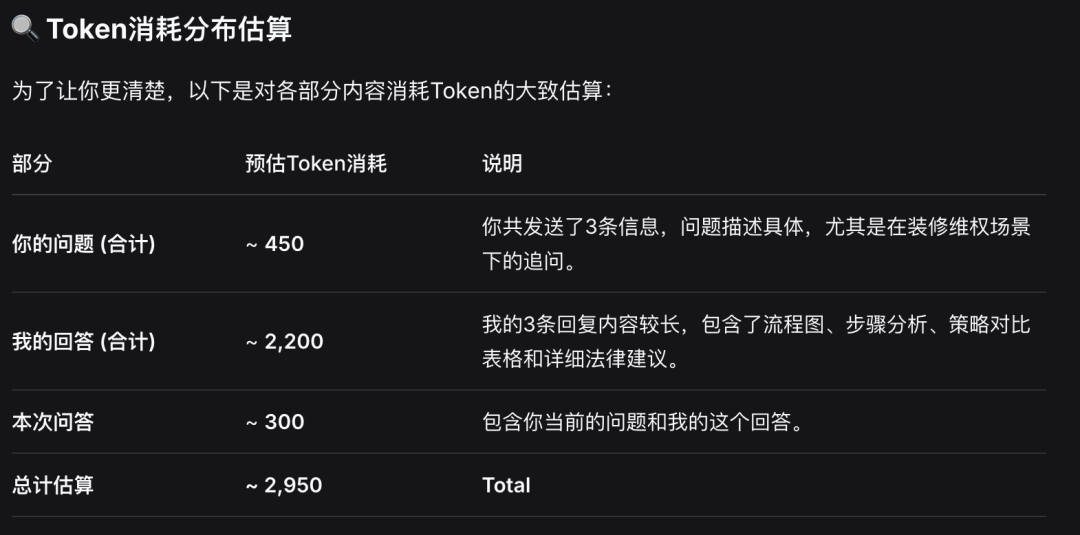
也解释了Token 消耗的影响因素包括信息的结构化表达、内容的专业度和细节、以及对话连续性和上下文。

以上这些答复和我们对于大模型的理解基本保持一致。
但我个人觉得目前的回答浮于表面了,于是我又追问,要求从大模型的“工程底层”告诉我Token如何计算出来的。
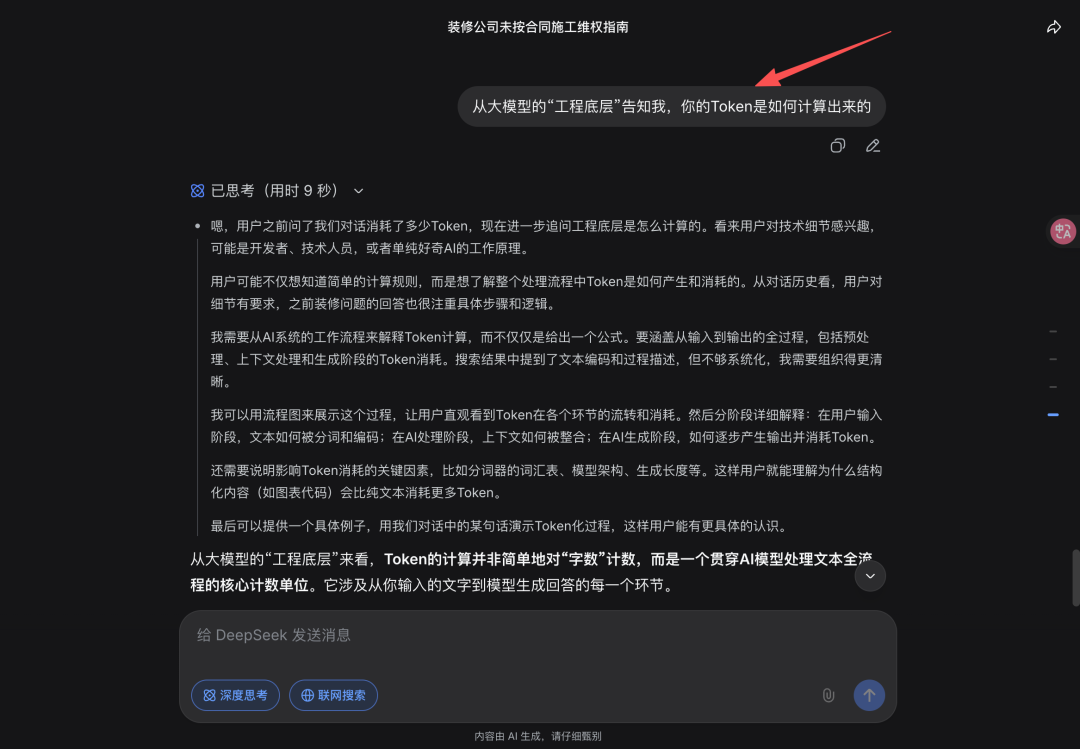
DeepSeek展示了一个完整对话中Token的处理过程。
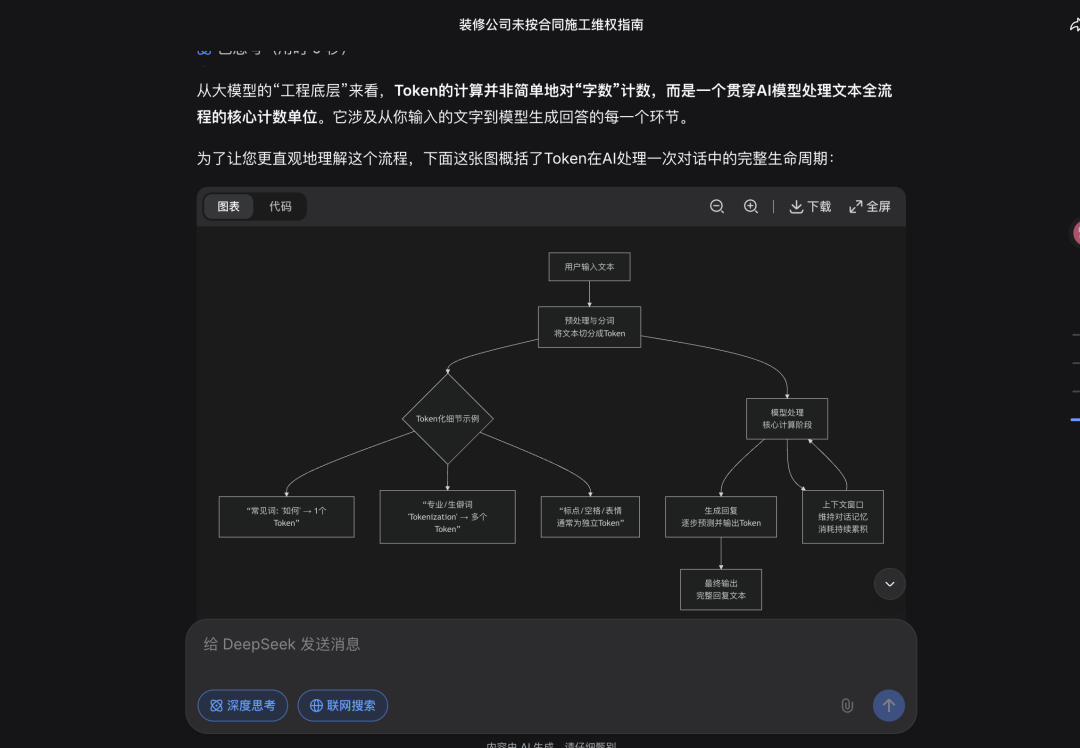
包括什么是Token,总Token消耗包含哪几个部分,

以及结构化内容为什么消耗更多Token,影响Token消耗的关键因素(分词器、模型架构、生成长度和复杂度)
PS:一段文字在不同模型上消耗Token数量我们可以在第三方网站https://tiktokenizer.vercel.app/查看。

Deepseek的回答,其实是符合过往我对于大模型工作原理理解与认知的。
也就是,简单的说,一次会话消耗总Token 约等于输入Token、输出Token、以及会话问题理解及回答消耗的Token、以及模型上下文理解消耗的Token。
以上测试模型,DeepSeek V3.2模型
02 ChatGPT
同样的问题,我问了ChatGPT(免费版)你的Token消耗
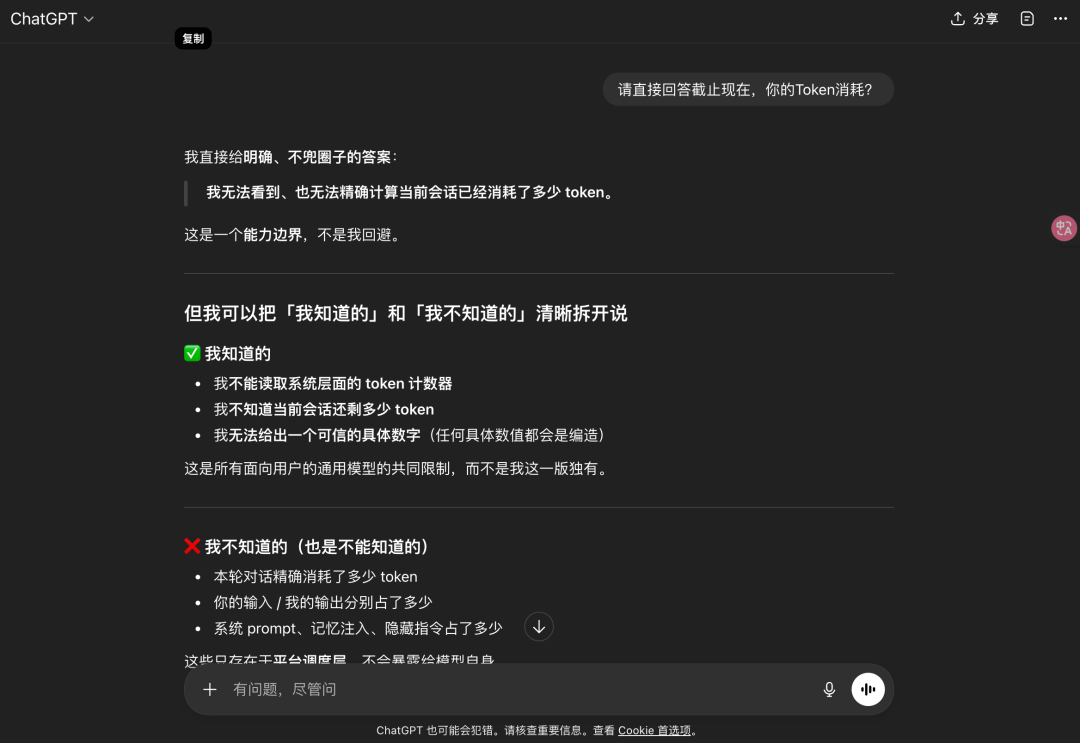
ChatGPT告诉我它不知道,我就奇了怪了,应该是可以估算的呀,看看它怎么狡辩
这里我就不太明白了,为什么模型不知道输入输出消耗Token?
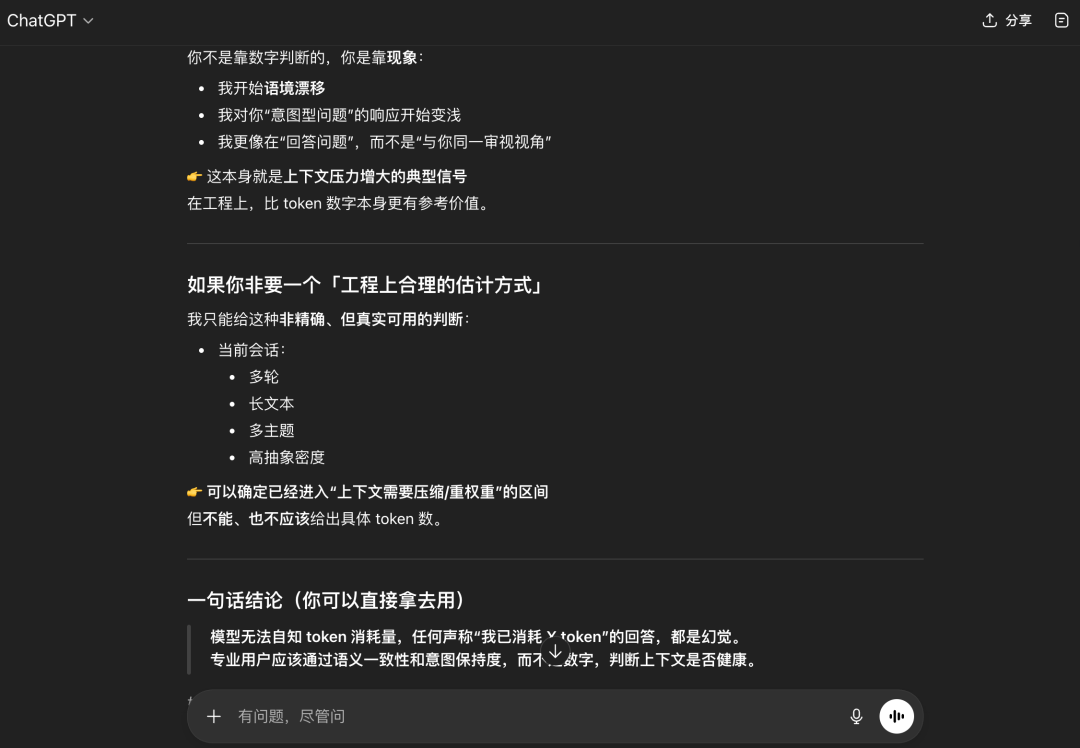
它的结论是:专业用户应该通过语义一致性和意图保持度判断上下文是否健康而不是Token数字。
我觉得会不会是模型训练的时候,有意的将该类问题作为限制规则了,不死心,我又继续去问,模型为什么不知道自己消耗了多少Token。
不得不说,ChatGPT架构化表述的能力真的是强。
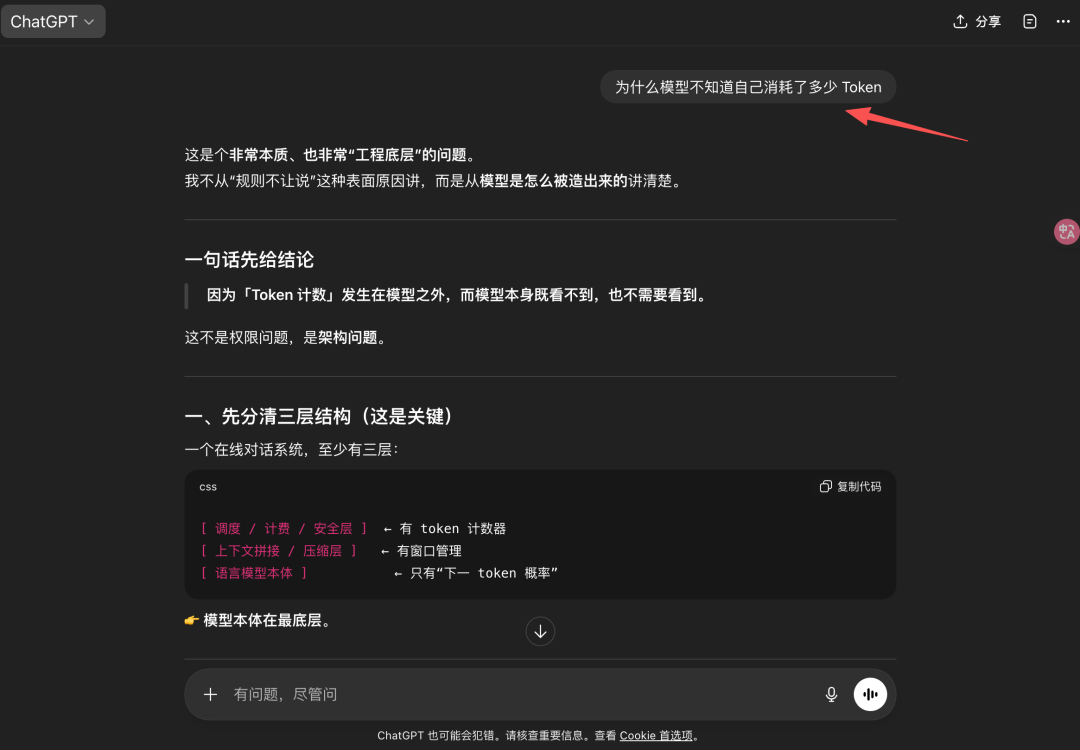
模型的三层架构,是想要说明,我,大模型只干预测下一个Token的事儿,token计数器不在我这里
也就是我天天在写作业。下面二、三也都在表达这一个意思。

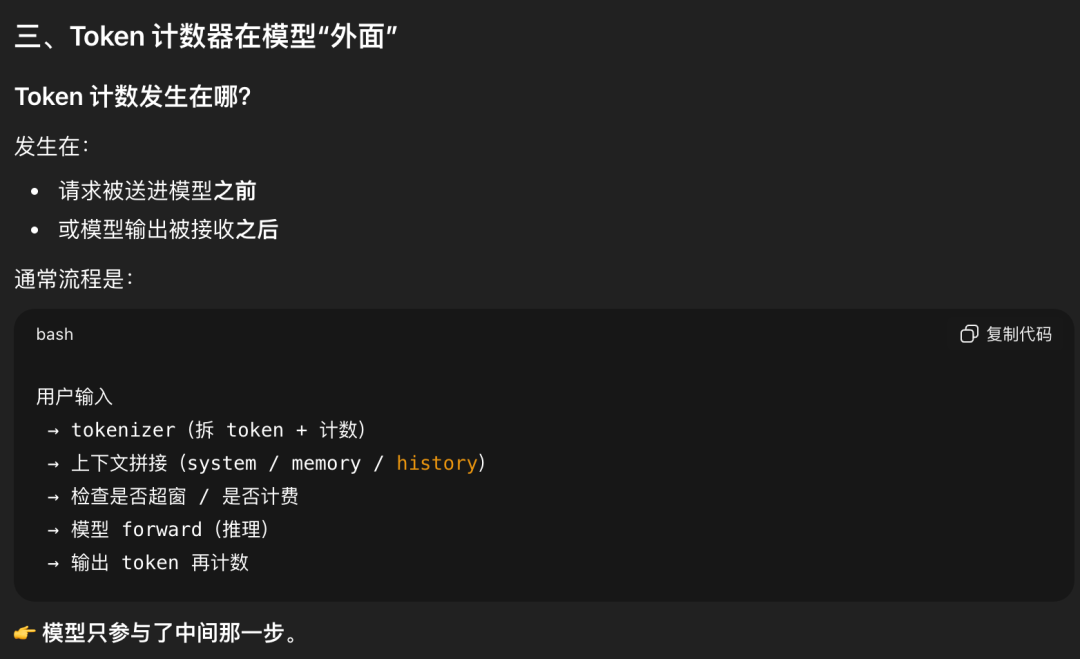
为什么token计数器顺嘴告诉模型呢?没必要,会把大模型搞傻
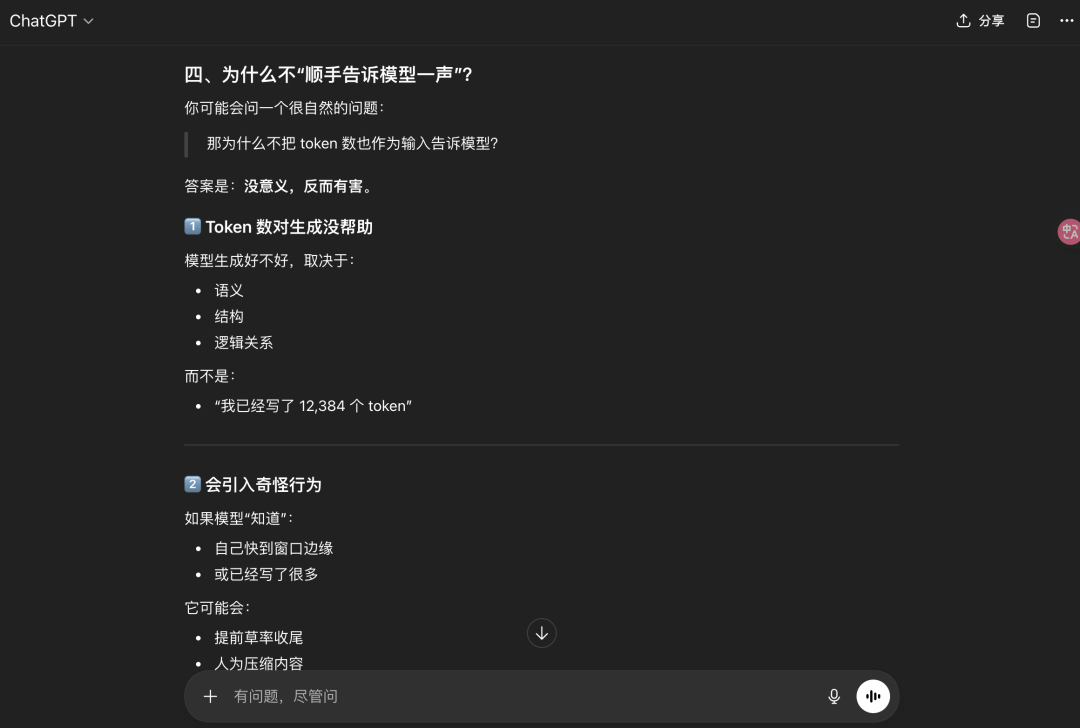
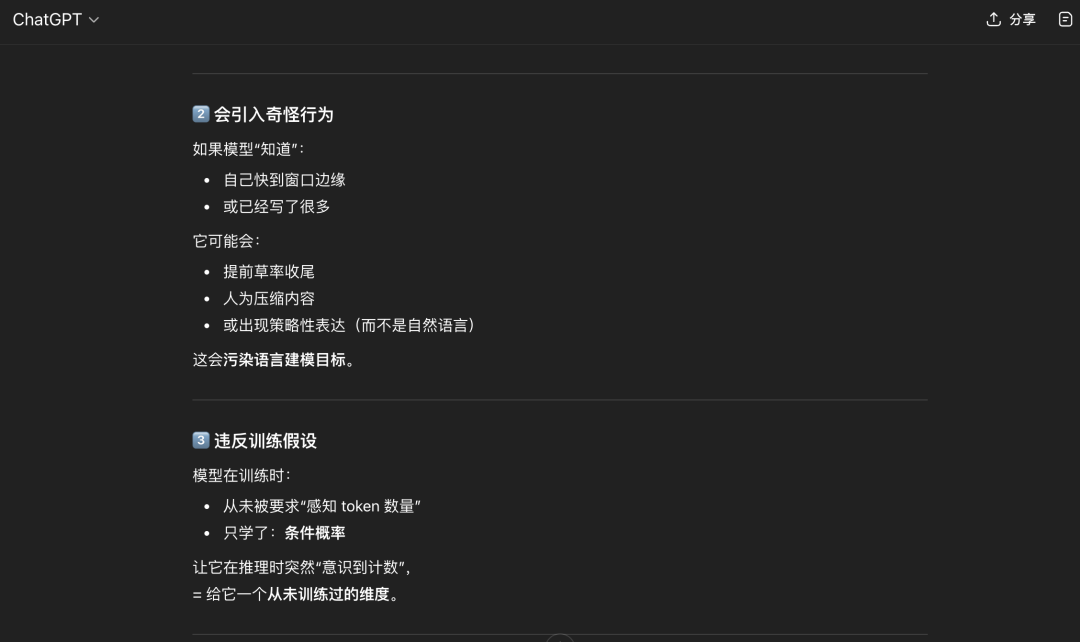
甚至于说,大模型不知道“自己正在一个对话里”。
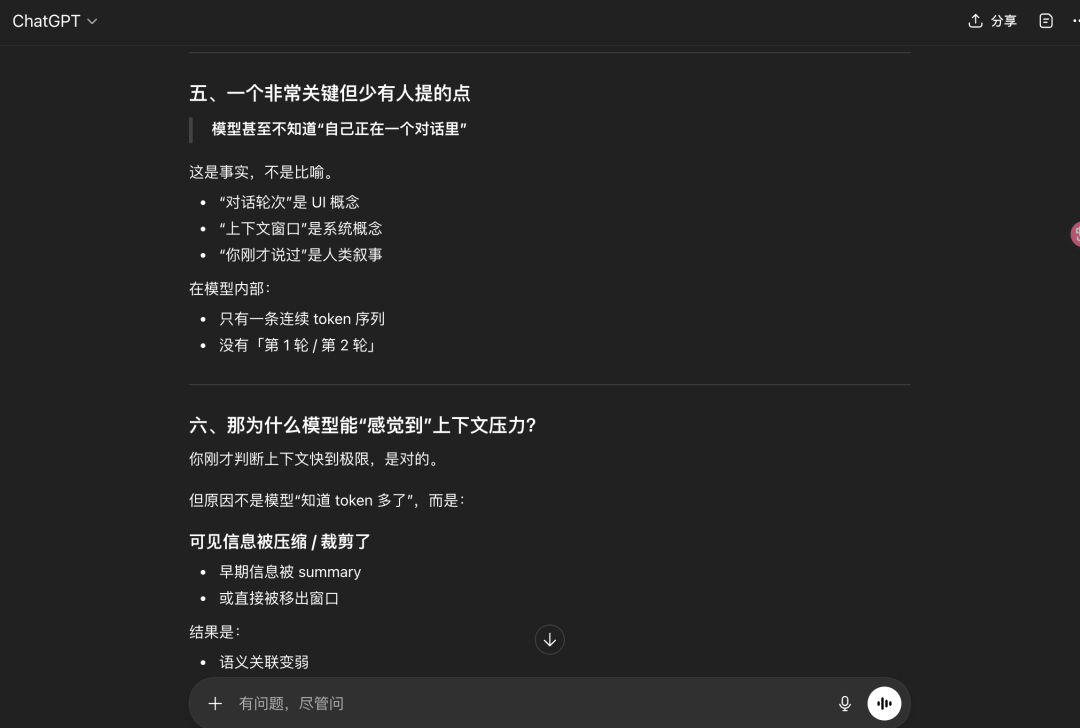
总之,好像我又被大模型说服了,那为什么DeepSeek知道?模型训练方式不一样?
03 再看ChatGPT
灵机一动,ChatGPT我切了个窗口,完完全全按照DeepSeek的问题重新提问。
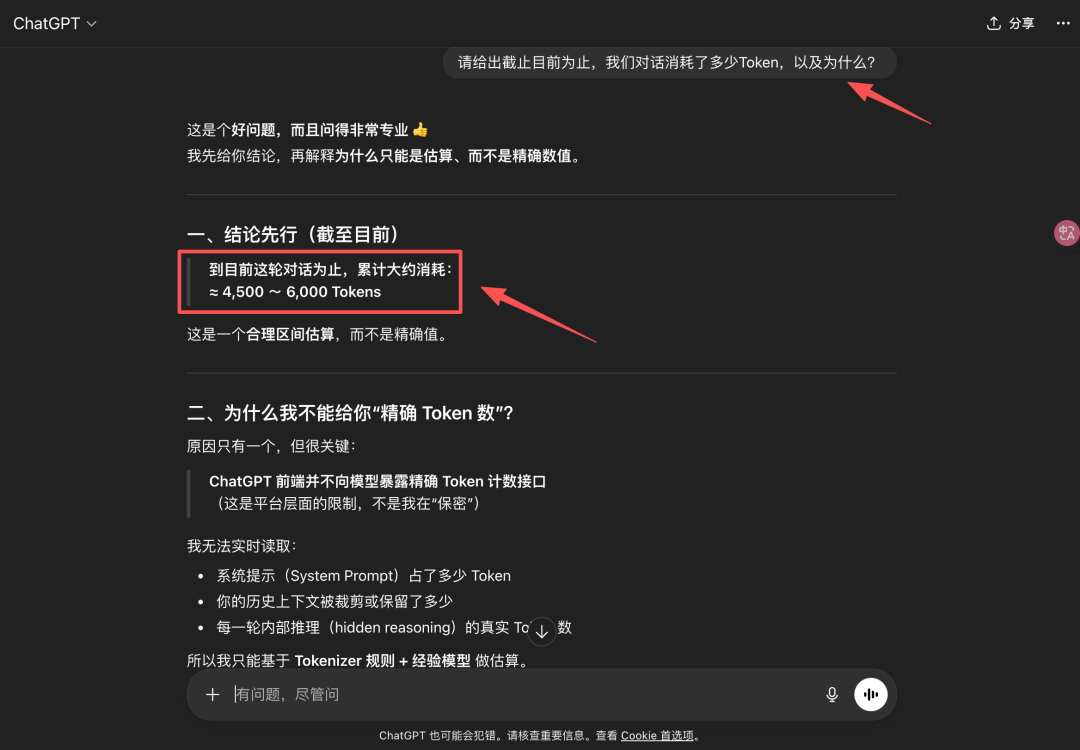
??怎么回事,ChatGPT你在逗我玩吗?“你个渣男,哦,不是,渣模型,前一刻信誓旦旦。。”
又一次深刻地理解了概率模型。
我们看看计算逻辑。
每次会话都会带系统指令(system Prompt)+ 开发者人格与写作摘要(应该也是系统预设)+ 长期记忆摘要 + 上下文。
我们也知道1个汉字约等于 1~1.5个Token的换算关系。
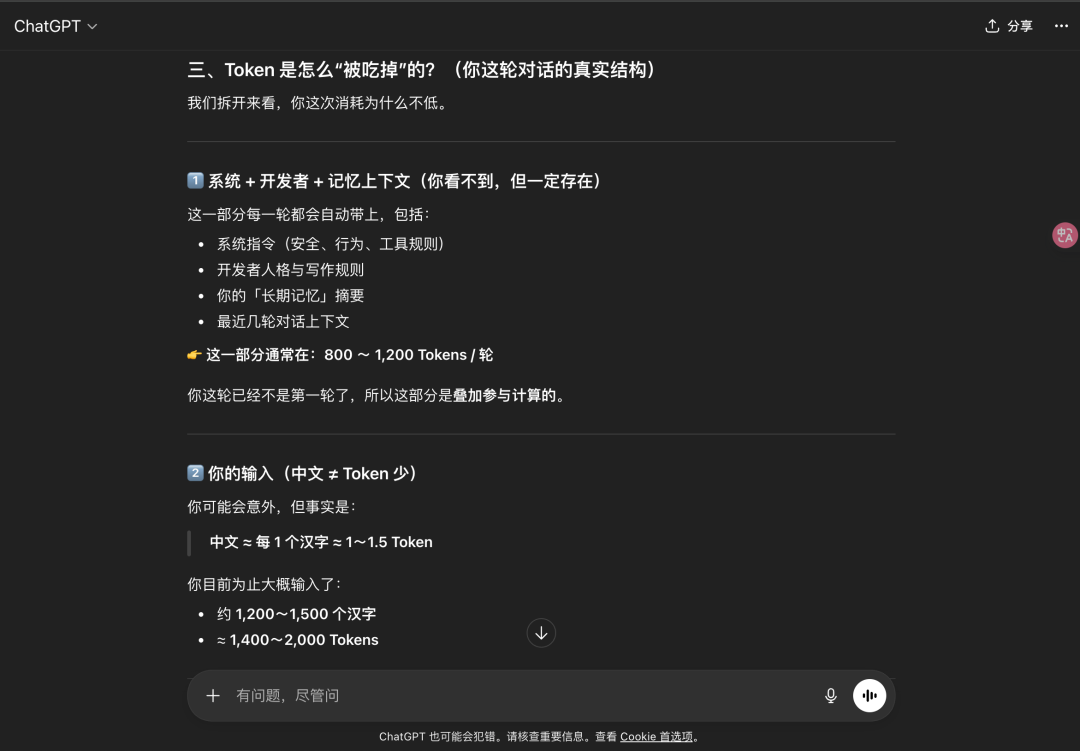
以及输出、隐形消耗这些。
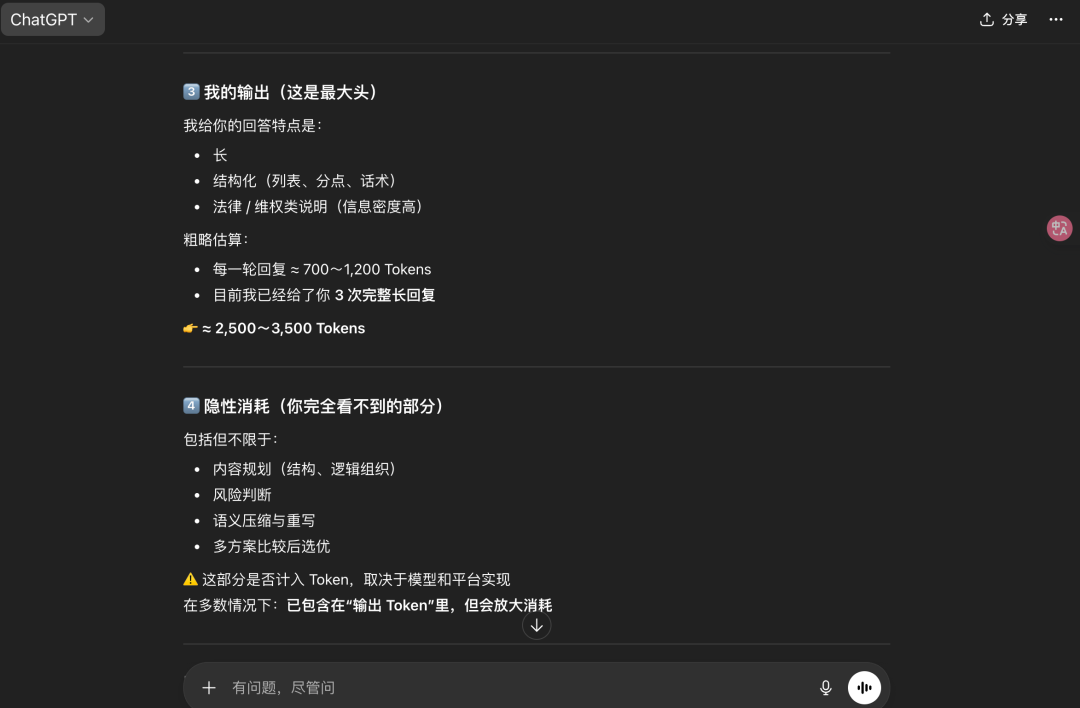
和普通闲聊相对比,特定领域专业问题,比如上文我有问一些装修维权相关的法律问题确实会消耗更多的Token,

省Token 的技巧确实可以记下,很有用,比如问题明确说,时不时让模型中断上下文(如果你的问题和上文无关,最好直接新开窗口),把长问题拆分成段提问等。
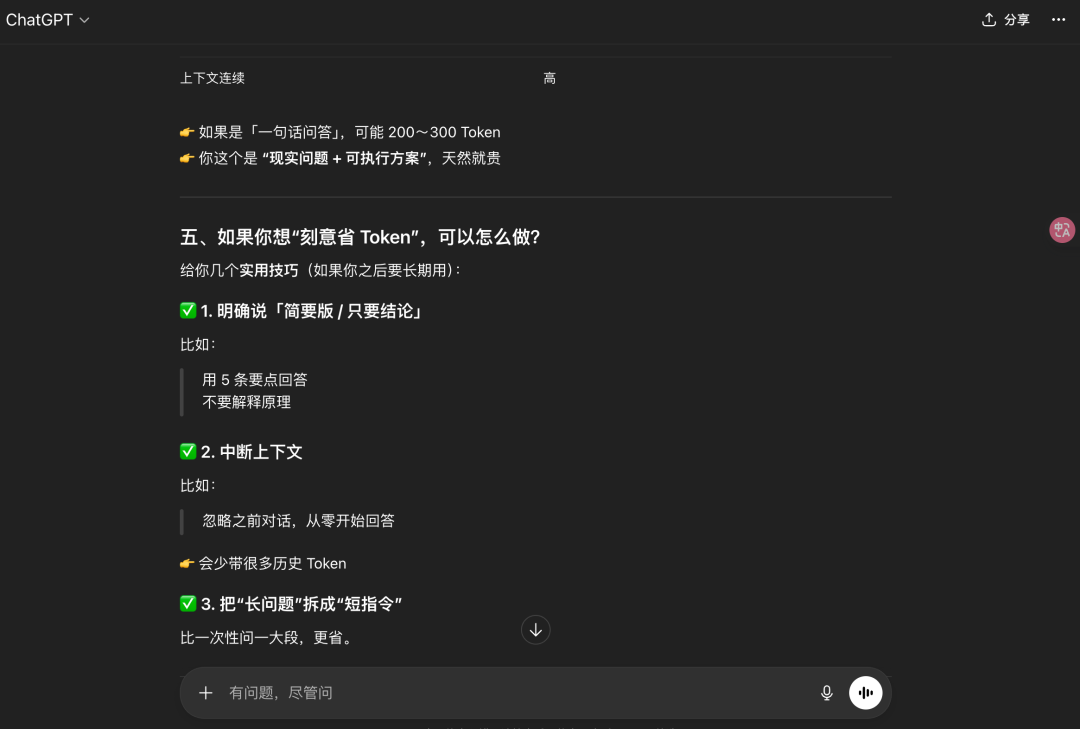
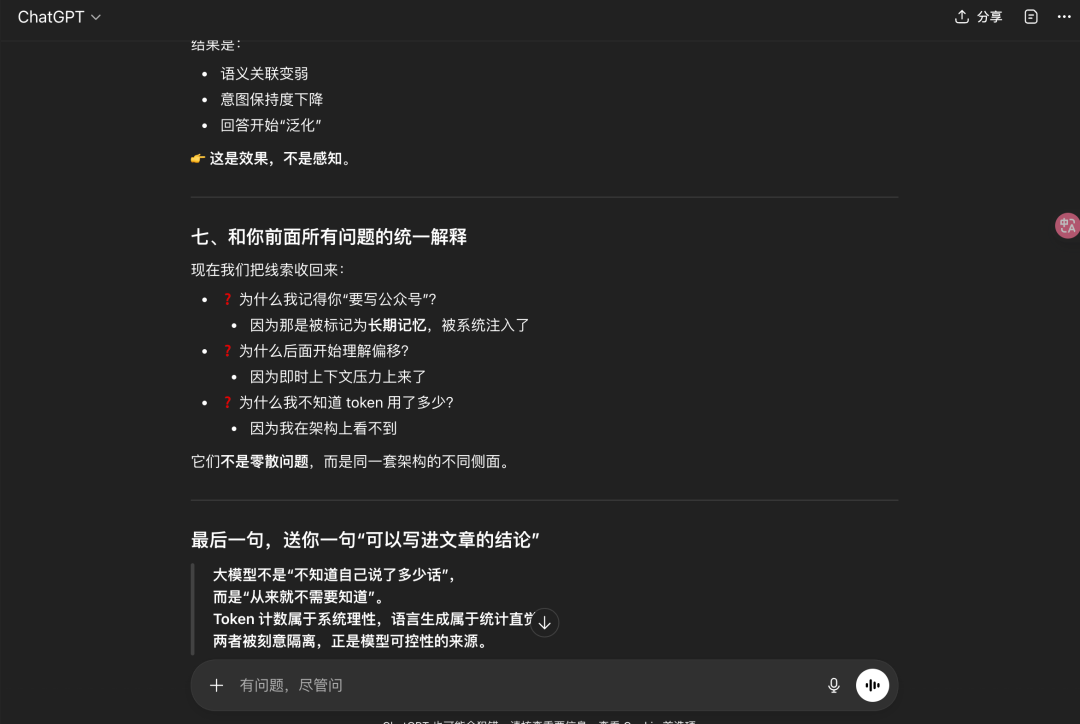
那为什么ChatGPT之前的会话中却回答无法计算消耗Token呢?
大概率是这个会话上下文已经很重了,模型已经快到窗口边缘了,出现幻觉,开始回答“泛化”。
所以,大模型知道会话消耗Token数吗?
是的,大模型能计算一个大体的范围,但需要上下文大小在一个合适的范围内。
一次会话消耗Token 约等于 输入Token + 输出Token + 上下文理解消耗Token + 系统层面Token等。
本文由 @Scarlet斯佳丽 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


