
 起点课堂会员权益
起点课堂会员权益谷歌Nano Banana 2:从“占位符”到视觉代理,重塑大模型生图性能边界与商业格局
Nano Banana 2的发布不仅颠覆了视觉生成AI的行业格局,更在速度、质量和成本之间实现了前所未有的平衡。这款谷歌最新推出的模型通过混合推理架构、动态量化感知训练等技术革新,将4K超清解析力和复杂文本排版能力下放至基础模型,同时将单张生成成本砍半至0.067美元。本文将从技术架构、商业应用和行业竞争三个维度,深度解析这款AI工具如何重塑创意工作流。

2026年2月26日晚,全球人工智能领域迎来了一次极具震撼性的技术发布。谷歌(Google)出人意料地向全球市场推出了其最新一代视觉生成与编辑模型——Nano Banana 2(官方技术命名为Gemini 3.1 Flash Image)。此次迭代并非简单的参数堆砌,而是标志着生成式AI在“推理逻辑”、“生成极速”与“工业级保真度”这三大核心诉求之间,首次找到了完美的商业化平衡点。

回顾过去六个月的科技资本市场,谷歌的AI技术突破与其股价高达47%的飙升形成了强烈的共振。而在技术端,自去年8月初代Nano Banana(Gemini 2.5 Flash Image)问世并在短短四天内为Gemini应用带来1300万首次访问用户、累积生成超50亿张图像以来,该产品线已然成为谷歌在视觉赛道对抗OpenAI与Midjourney的最强利器。然而,初代的“快”建立在牺牲复杂文本渲染和三维空间理解的基础之上;随后的Nano Banana Pro虽然解决了质量问题,却受制于高昂的算力成本与较慢的推理速度。
Nano Banana 2的横空出世,其核心战略意图在于进行一次彻底的“技术降维打击”:将原本专属于Pro级别的4K超清解析力、实时网络检索(Grounding)、以及完美的复杂文本排版能力,全面下放至Flash级别的基础模型中。分析数据显示,该模型不仅在API端将图像生成时间压缩至惊人的4至6秒,更将单张生成成本硬生生砍掉一半至0.067美元。在权威评测平台Arena.ai上,Nano Banana 2上架即以1279的Elo超高得分问鼎文生图榜单首位,彻底改变了原有的行业竞争格局。
一、技术代际演进与“Nano Banana”的模因经济学
在剖析底层硬核架构之前,探究该模型系列的命名哲学与演进轨迹,有助于理解谷歌在多模态战略上的产品定位。
1.1 凌晨两点半的“玩笑”与超级IP的诞生
在严肃的硅谷技术语境中,大模型的命名往往充斥着晦涩的学术词汇(如Transformer、Diffusion、LLaMA等)。然而,“Nano Banana”这一极具互联网模因(Meme)特质的名称,其诞生纯属偶然。根据谷歌Gemini应用团队产品经理David Sharon在播客中的公开披露,该名称源于一次凌晨2点30分的紧急提测:当时项目经理Nina为了将尚未发布的Gemini 2.5 Flash Image提交至LM Arena进行盲测评测,随手输入了“Nano Banana”作为隐藏身份的占位符。
这一充满戏谑色彩的代号在模型以碾压态势登顶榜首后,迅速被全球开发者社区接纳并引爆社交媒体。谷歌敏锐地捕捉到了这种去中心化的传播红利,不仅在官方层面保留了这一昵称,更将其转化为一种视觉沟通策略——在Google AI Studio中将运行按钮设为亮黄色,在Gemini应用中大量植入香蕉表情符号(),甚至推出了限量版周边。这种“将复杂技术包裹在平易近人的故事中”的命名哲学,成功消解了公众对前沿AI技术的距离感,使“轻量、小巧、高效”的Nano理念深入人心。
1.2 视觉模型矩阵的“三步走”演进路线
梳理Nano Banana家族的发展史,可以清晰地看到一条旨在平衡资源与能力的演进路线:
- 初代试水:Nano Banana (Gemini 2.5 Flash Image,2025年8月)
- 重型工业级:Nano Banana Pro (Gemini 3 Pro Image,2025年11月)
- 效能奇点:Nano Banana 2 (Gemini 3.1 Flash Image,2026年2月)
二、破构与重组:Gemini 3.1 Flash Image的底层核心架构
Nano Banana 2之所以能打破“速度、质量、成本”的不可能三角,核心在于其彻底摒弃了传统文生图领域单一的扩散(Diffusion)管线,转而构建了一套由大型语言模型(LLM)驱动的混合推理架构。
2.1 突破单一管道:视觉自回归与扩散的混合机制(Hybrid Architecture)
当前行业内的主流模型(如OpenAI的DALL-E 3、Midjourney的底层架构)通常将用户的文本提示转化为向量后,直接输入到扩散模型中进行像素级去噪。这种机制的弊端在于“盲目性”——模型并不理解物体的物理结构,只是在拟合像素的统计学分布,这也是导致AI经常画出六根手指或空间错乱的根源。
分析指出,Nano Banana 2采用了推理注入的混合架构(Reasoning-Infused Hybrid Architecture),将生成过程升级为“系统2(System 2)”级别的认知任务:
- 语义解构与逻辑规划:当接收到复杂提示(例如:“一张科学图表,展示由水果组成的太阳系”)时,Gemini 3.1大语言模型首先介入。它不会立即作画,而是进行逻辑分解(Decomposition)——推算出太阳系的轨道物理关系,并基于颜色和纹理匹配对应水果(如橙子代表太阳,蓝莓代表地球)。
- 视觉自回归(Visual AR)起草:利用自回归Transformer模型生成图像的粗略标记化表示(Tokenized Representation),构建出全局结构严密、符合物理常识的“草图”布局。
- 扩散细化(Diffusion Refinement):在确保全局骨架正确无误后,最终由优化的扩散模型负责填充高频细节,如光影折射、水果表皮纹理和超高分辨率的像素渲染。这种MMDiT(多模态扩散Transformer)框架,在提升40%文本理解力的同时,降低了35%的计算负载。
2.2 动态量化感知训练(DQAT)与极限边缘部署
要在云端服务器甚至移动端实现“Flash”级的亚秒级响应,模型压缩是必经之路。Nano Banana 2的轻量化主干网络仅约18亿(1.8B)参数,却能匹敌体积大其三倍的开源模型。
这一成就得益于动态量化感知训练(Dynamic Quantization-Aware Training, DQAT)的全面应用。在传统的AI工程中,将模型权重从32位浮点(FP32)降阶到INT8甚至INT4以节省显存,往往会导致严重的生成质量雪崩。然而,DQAT技术允许Nano Banana 2在极端量化的状态下,依然保持超高的信噪比。在近期的技术演示中,该模型在中端移动硬件上跑出了低于500毫秒的推理延迟,甚至在512px分辨率下实现了惊人的30帧/秒实时流合成能力,为未来的实时视频重绘(Video Inpainting)奠定了基石。
2.3 可编程的思考深度(Configurable Thinking Levels)
Nano Banana 2在开发者生态中引入了一项革命性控制参数:思考层级(Thinking Levels)。通过Gemini API,开发者可以决定模型在提笔作画前,花费多少算力去“思考”。
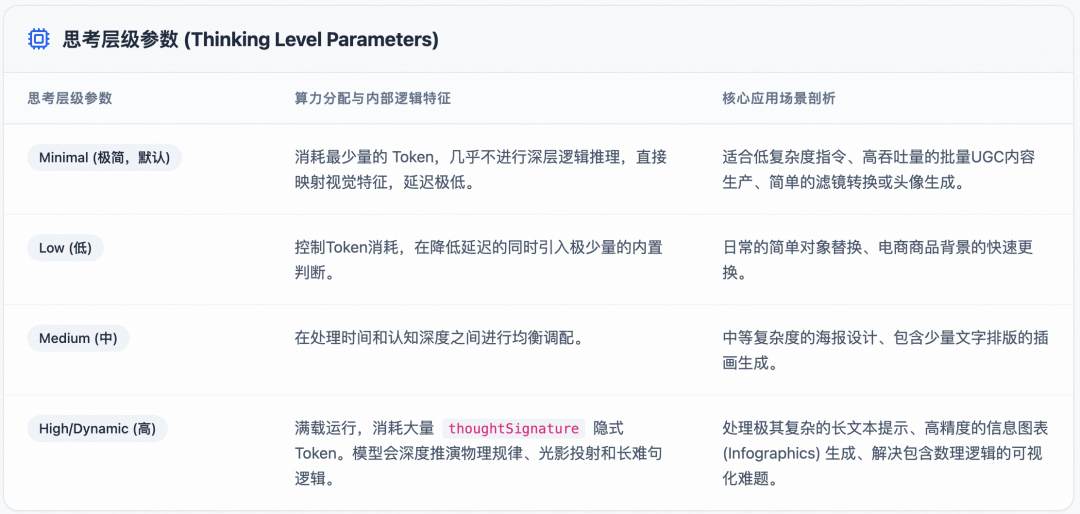
这一机制赋予了Nano Banana 2极大的弹性,使其既能胜任C端用户的娱乐性极速出图,又能满足专业设计师对逻辑严谨性的极致苛求。
三、重塑商业工作流:四大核心技术特性详解
Nano Banana 2的发布并非旨在秀肌肉,而是直击当前数字营销、UI/UX设计和影视分镜工业流中的四大痛点。
3.1 完美的排版级文本渲染与实时本地化(In-Image Localization)
一直以来,图像生成AI在处理文字时堪称灾难——字母扭曲、拼写混乱(业界戏称为“AI乱码”)是Midjourney等模型长期无法攻克的顽疾。Nano Banana 2继承并强化了Pro版的能力,不仅能实现94%以上的文本准确率,更达到了“排版级(Typographic precision)”的极高标准。它能够轻松应对复杂的图表标签、商店招牌和冗长的海报标题。
更为惊艳的是其新增的**图像内本地化(In-Image Localization)**能力。在谷歌展示的“Global Ad Localizer(全球广告本地化器)”演示中,用户只需提供一张英文版的营销海报,模型便能直接在图像内部将英文标语无缝翻译并替换为法语、日语或阿拉伯语。在这个过程中,模型不仅完美保留了原有的字体样式、环境光影和三维透视,甚至还能根据目标市场的文化语境微调视觉元素。对于跨国营销团队而言,这一能力将多语种视觉资产的制作周期从数天压缩至几秒。
3.2 角色与资产的绝对身份锁定(Subject Consistency)
“生成一次惊艳的图像很容易,但让同一个角色在一百张不同场景的图像中保持长相不变,却难如登天。”这是AI生成领域的共识。尽管Midjourney推出了–cref(角色参考)指令,但在进行大幅度动作变换或极端视角切换时,面部特征依然会发生不可控的漂移。
Nano Banana 2在一致性算法上取得了工程学奇迹。分析指出,在一个独立的工作流中,模型能够同时锁定并维持多达5个不同角色的外貌特征,以及高达14个独立物体的高保真呈现。开发者最高可上传10张物体参考图与4张角色参考图。
借助这种被称为“Identity Locking(身份锁定)”的机制,漫画创作者和电影分镜师可以随心所欲地将同一组角色放置于咖啡馆、外太空或是中世纪城堡中,而无需担心主角“换脸”或核心道具的形变。
3.3 消除幻觉的实时网络接地(Real-Time Web Grounding)
绝大多数生成式AI受制于其训练数据的时间截断(Knowledge Cutoff),无法生成与当前现实同步的内容。Nano Banana 2则通过深度挂载Google Search与Google Image Search,彻底打破了这一信息孤岛。
在生成图像的“思考”阶段,该模型会实时调用网络数据以补充事实细节。例如,当指令要求生成“某地当前天气下的街景”时,模型会后台查询天气API,获取真实数据后再渲染雨雪光影;在创建科普图表(如水循环示意图、稀有植物图谱)时,网络接地能力确保了所有标签、叶片形态和科学数据的绝对准确性,极大降低了AI视觉层面的“幻觉”。在官方展示的“Window Seat”应用中,生成的飞机舷窗外景色,正是基于真实的地理坐标与气象云图渲染而成的。
3.4 电影级工业生产规格(Production-Ready Specs)
为了满足从TikTok竖屏短视频到宽屏演示文稿的全场景需求,Nano Banana 2在分辨率与画幅控制上提供了前所未有的自由度:
- 极限分辨率跨度:模型不仅支持原生的4K(4096×4096)超清输出,还特意新增了512px的极低分辨率选项。后者专为高频迭代、实时交互以及视频流的逐帧生成设计,将延迟压缩至极致。
- 极度画幅比例:除了常规的16:9、3:4等,系统新增了4:1、1:4、8:1、1:8等极端全景比例。在这些极端画幅下,模型依然能保持构图的逻辑性,不会出现画面撕裂或元素强行拉伸的现象。
四、行业横向评测:Nano Banana 2 vs. Midjourney vs. DALL-E
在2026年初的视觉大模型竞技场中,Nano Banana 2的入局引发了激烈的板块碰撞。通过对多方基准测试和资深创作者的实测数据进行汇总,本报告构建了详尽的横向性能对比体系。
4.1 综合性能维度对比矩阵
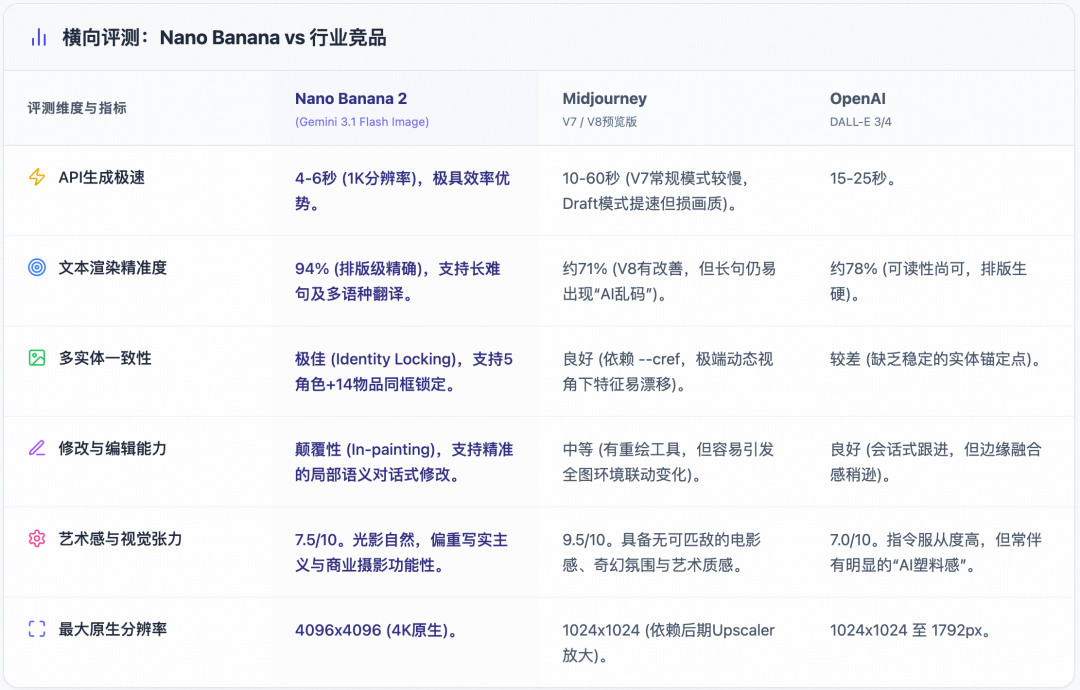
4.2 深度博弈:创造者(Creator)与编辑者(Editor)的较量
Midjourney V7与Nano Banana 2的根本分歧,在于其底层设计哲学的不同。Midjourney凭借其独特的审美偏好(如V7版本强制要求用户进行200张图像盲测以确立个性化风格曲线),在艺术创作、情绪板(Moodboard)设计和超现实主义插画领域依然是无可争议的“审美之王”。
然而,当进入严苛的商业管线时,Midjourney的“过度创造力”往往成为负担。实测显示,当建筑设计师要求将一栋生成好的现代建筑的场景从白天切换为黑夜时,Midjourney几乎无法做到“仅仅改变光影”——它总是会自作主张地修改窗户的排列或植被的位置。相反,Nano Banana 2基于强大的空间推理,能够完美实现“环境替换而主体100%冻结”的操作。
因此,2026年顶尖创意团队的主流工作流已演变为:使用Midjourney进行早期的发散性艺术探索与基调定型;随后将核心资产导入Nano Banana 2,利用其局部重绘、文本渲染和多视角扩展能力,输出最终的商业级高精度交付物。
4.3 成本重构与规模化应用
在经济账本上,Nano Banana 2对竞品造成了降维打击。其API调用价格大幅下调,1K分辨率图像的成本仅为0.067美元(约为Nano Banana Pro的50%)。以一个中度重度用户(每月1000张)为例,使用Nano Banana 2的月成本远低于Midjourney动辄数十至上百美元的订阅费,且节省了大量等待时间。
谷歌同时展示了极其强悍的生态分发能力。在发布首日,Nano Banana 2便作为默认引擎直接贯穿了Google Workspace、Gemini App、Google Search(AI模式与Lens)、Google Cloud Vertex AI以及Google Ads。对于广告主而言,这意味着可以直接在投放后台,用几秒钟时间批量生成带有精确外文文案的高清营销海报,进行A/B测试,极大缩短了商业变现的链路。
五、“导演级”提示词工程(Prompt Engineering)指南
随着大模型从“词袋(Bag-of-Words)”匹配时代跨入“System 2”推理时代,使用者与AI的沟通范式也必须全面升级。研究发现,传统的提示词写法在Nano Banana 2上已不再奏效。
5.1 摒弃“标签汤”,拥抱“导演语言”
过去,用户习惯用逗号堆砌大量修饰词,如“赛博朋克, 霓虹灯, 极高画质, 8K, 虚幻引擎渲染”(即所谓的Tag Soup)。然而,面对具备深度理解力的Nano Banana 2,这种方式反而会限制其发挥。
行业专家建议采用“创意总监(Creative Director)式”的自然语言指令。用户应使用完整的语法结构,清晰界定四个维度:
- 主体人口学特征/物理属性;
- 动作与交互关系;
- 环境空间与镜头语言(焦距、景深、视角);
- 光照物理与材质质感。
例如,官方给出的高质量摄影提示词模板为:“使用35mm镜头,呈现柔和的背景虚化与鲜艳色彩。在柔和的自然光下,一只穿着浴袍的幼年袋鼠正坐在咖啡馆的靠窗座位(Window Seat)上悠闲地喝咖啡,背景中一个模糊的人影戴着一顶同款帽子。” 这种高度结构化的语境,能够被模型精确解析为层级分明的空间透视关系。

5.2 核心实战技巧:对话式微调
Nano Banana 2最强大的隐性能力是其“连续对话状态追踪”。一条黄金冷知识是:如果生成的图像有80%符合预期,绝对不要点击“重新生成(Re-roll)”。
正确的做法是直接输入自然语言修改指令进行增量编辑。例如:
- 局部光影:“保持其他所有元素绝对一致,仅将画面右侧的光源改为温暖的落日逆光。”
- 背景剥离:“保留模特的五官、姿势与丝绸长裙的物理褶皱,将背景替换为极简的高级灰摄影棚幕布。”
- 跨维度转换:“根据上传的真人照片,制作一个盲盒扭蛋(Gashapon)风格的微缩手办。保留人物标志性发型和服装配色,置于透明亚克力胶囊中,底部带有霓虹灯光。”

六、防御深伪:SynthID与数字内容溯源体系
当AI能够以极低成本、在几秒内生成真假难辨的4K图像乃至伪造监控画面时,技术伦理与内容安全便成了悬在科技巨头头顶的达摩克利斯之剑。谷歌在Nano Banana 2的基础架构中强行植入了多重溯源网络,以应对日益严峻的监管合规要求。
6.1 SynthID隐形水印的全面覆盖
所有由Nano Banana 2生成的原始图像及经过深度编辑的图片,都会在像素编码的最深处被嵌入Google开发的SynthID数字水印。区别于传统的显式水印,SynthID通过干预图像的频域分布实现。实验证明,即便这些图像经过了高强度的JPEG压缩、社交媒体滤镜渲染、亮度调整甚至是局部裁剪,专用的验证算法依然能够准确探测到AI生成的痕迹。
然而,社区中也存在持续的技术对抗。在Reddit等开发者论坛上,有用户指出通过将其导入GIMP或Krita等专业图像处理软件并进行特定的底层格式重导出(如转换色彩空间后另存为新PNG),存在抹除SynthID签名的理论可能。这表明单点防御技术仍需不断进化。
6.2 C2PA元数据与生态联防
为修补单点防御的漏洞,谷歌宣布将Nano Banana 2深度接入C2PA(Content Credentials,内容出处与真实性联盟)标准生态。这意味着,从该模型导出的图像文件不仅带有隐形水印,还会在文件头中被强行注入加密的元数据(Metadata)。这些数据记录了图像的生成时间、所用AI模型版本以及后续的编辑历史。
当用户在主流浏览器、社交平台(如Meta的生态)或支持C2PA的图像浏览器中查看这些图片时,系统会直接提供一个“成分标签”,明确标示其AI合成的身份。自2025年底该验证机制在Gemini应用内部署以来,已被全球用户累计调用验证超过2000万次,形成了有效阻断虚假信息传播的第一道防线。
七、结论:迈入“具备常识”的视觉生产新纪元
Nano Banana 2的发布绝不仅仅是一次简单的版本更新,而是生成式AI视觉领域的一个分水岭。通过将大语言模型的逻辑推理能力与视觉自回归、扩散模型深度融合,它宣告了图像生成模型从“基于概率的像素拟合器”正式进化为“具备物理常识与空间逻辑的视觉代理(Visual Agent)”。
在商业维度上,它通过动态量化技术和极限的成本控制(0.067美元/张的API定价与4-6秒的极速响应),彻底摧毁了阻碍高质量AIGC规模化落地的最后一道成本屏障。对于数字营销、游戏资产开发、UI/UX原型设计以及影视分镜等强依赖图文一致性的工业管线而言,Nano Banana 2提供了目前市场上综合ROI(投资回报率)最优的解决方案。
尽管在纯粹的艺术张力与超现实主义氛围营造上,它尚未完全动摇Midjourney的统治地位,但其在文本渲染精度、多实体身份锁定以及多语种实时本地化方面的绝对优势,已经确立了其作为“最强专业图像编辑与生成工具”的不可替代性。在2026年这场愈演愈烈的AI算力与模型混战中,掌握这股兼具“闪电速度”与“精密逻辑”的技术力量,已成为下一代数字内容创作者的核心生存法则。
本文由 @像素呼吸 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


