
 起点课堂会员权益
起点课堂会员权益DeepSeek再发新论文:双路径加载打破存储瓶颈,推理性能提升1.87倍
DeepSeek最新论文揭示了Agentic LLM推理的真正瓶颈——存储I/O带宽分配不合理,而非GPU算力不足。通过创新的双路径加载技术,在不增加硬件成本的情况下,实现了1.87倍的性能提升。本文将深入解析这项突破性技术如何重新定义智能体时代的系统架构,以及它对未来AI应用的深远影响。

2月27日,DeepSeek发布了一篇新论文《DualPath: Breaking the Storage Bandwidth Bottleneck in Agentic LLM Inference》,揭示了一个令人意外的发现:智能体推理的性能瓶颈,根本不在GPU算力,而在存储I/O带宽的分配不合理。
通过双路径加载技术,DeepSeek在不增加任何硬件成本的情况下,将智能体推理性能提升了1.87倍。这不是GPU的问题,是网线的问题。
什么是Agentic LLM?
1.1Agentic LLM面临什么挑战
首先要搞清楚一个问题:什么是Agentic LLM?
不是传统的”用户问一个问题,模型答一句话”这种单轮对话。而是像代码助手、任务Agent这种,会和环境(编辑器、浏览器、Python解释器)反复交互,可能几十甚至上百轮。
每一轮对话,模型都需要:

什么是KV-Cache?

1.2 惊人的数据
DeepSeek在论文里做了一个Agentic Trajectory(多轮对话历史),结果很有意思:
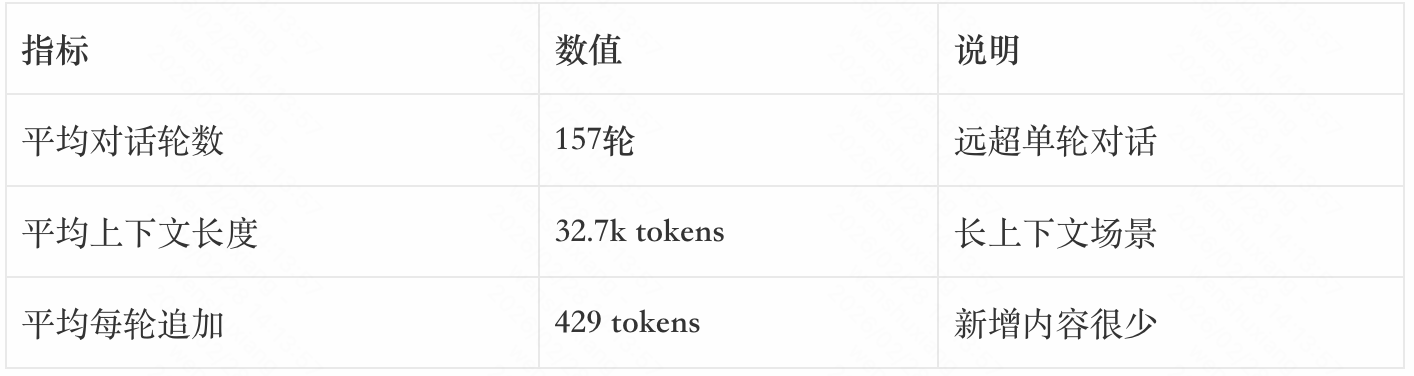
算一下,KV-Cache命中率就是:
(32700 – 429) / 32700 =98.7%
这意味着:98.7%的内容都是重复加载的,只有1.3%是新东西。
关键洞察
模型在干什么呢?主要是在读数据,不是在算东西。agent推理已经是I/O-bound了,不是Compute-bound。
Cache-Compute比率——一个被忽视的指标
论文里给了一个更直观的指标:Cache-Compute比率,就是”要读的数据量”除以”要算的计算量”。
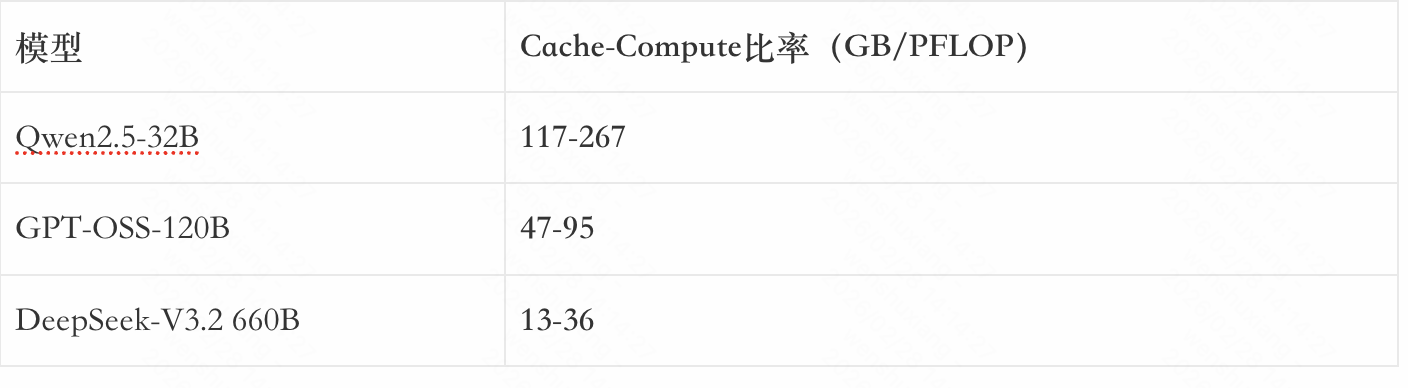
这说明什么?即使是优化最好的DeepSeek-V3.2(用了稀疏注意力),I/O需求也是计算需求的13-36倍。Qwen更夸张,高达267倍。
瓶颈不在存储,在分配
3.1 传统架构:预填充-解码分离
传统LLM推理系统用什么架构?基本上都是“预填充-解码分离”(PD Disaggregation)。
简单说,就是:

分开的好处是可以针对性优化,互不干扰。
3.2 KV-Cache存在哪?
KV-Cache存在分布式存储(通常是SSD)。
问题来了:谁来从存储加载KV-Cache?
传统设计是:全都由预填充引擎加载。
为什么呢?因为预填充阶段需要读历史上下文,然后再处理新输入,逻辑上应该由它负责。
3.3 瓶颈出现
但这里有个问题:预填充引擎的存储网卡(SNIC)带宽有限,通常是400 Gbps。当大量请求进来时,这个网卡很快就饱和了。
那解码引擎呢?解码引擎也有存储网卡,而且基本是闲置的——因为解码阶段主要是在生成新token,不需要读KV-Cache(KV-Cache已经在HBM里了)。
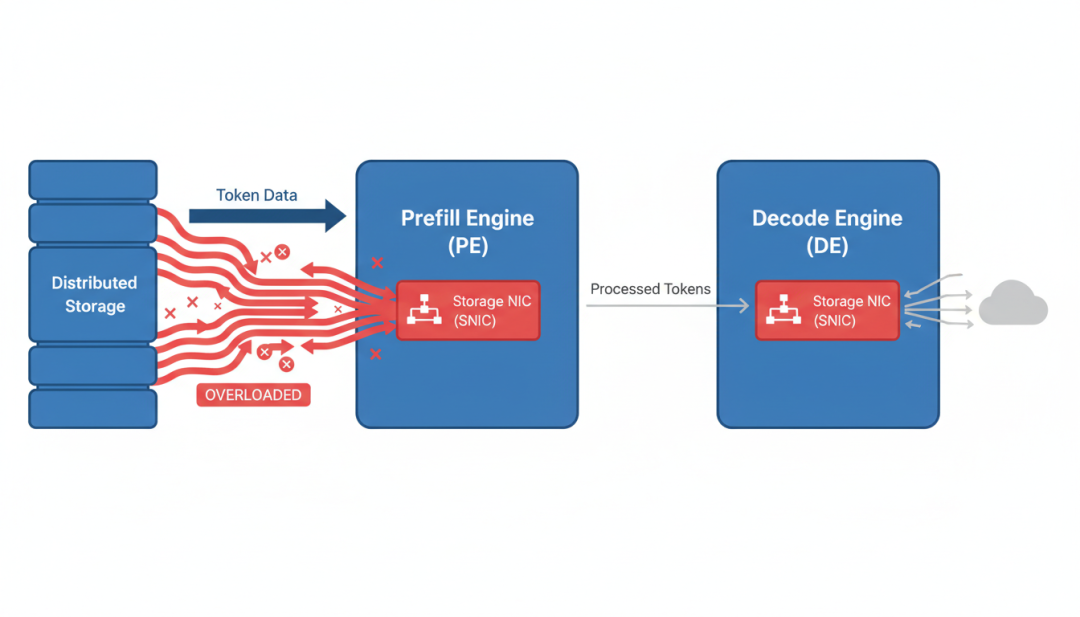
▲ 传统架构:预填充引擎SNIC爆满,解码引擎SNIC闲置
核心问题:一半网卡在加班,另一半在睡觉。整个系统的吞吐量被预填充引擎的I/O能力卡死了,解码引擎的闲置资源完全用不上。
论文的解法——让睡觉的网卡也干活
论文的想法很直接:为什么不大家一起搬砖?
4.1 双路径架构
引入了一个新的路径:存储 → 解码引擎 → 预填充引擎。
传统路径(路径A)还在:存储 → 预填充引擎。
但多了一个新路径(路径B):
- KV-Cache先从存储加载到解码引擎
- 解码引擎通过计算网络(RDMA)传给预填充引擎
- 预填充引擎收到数据后开始处理
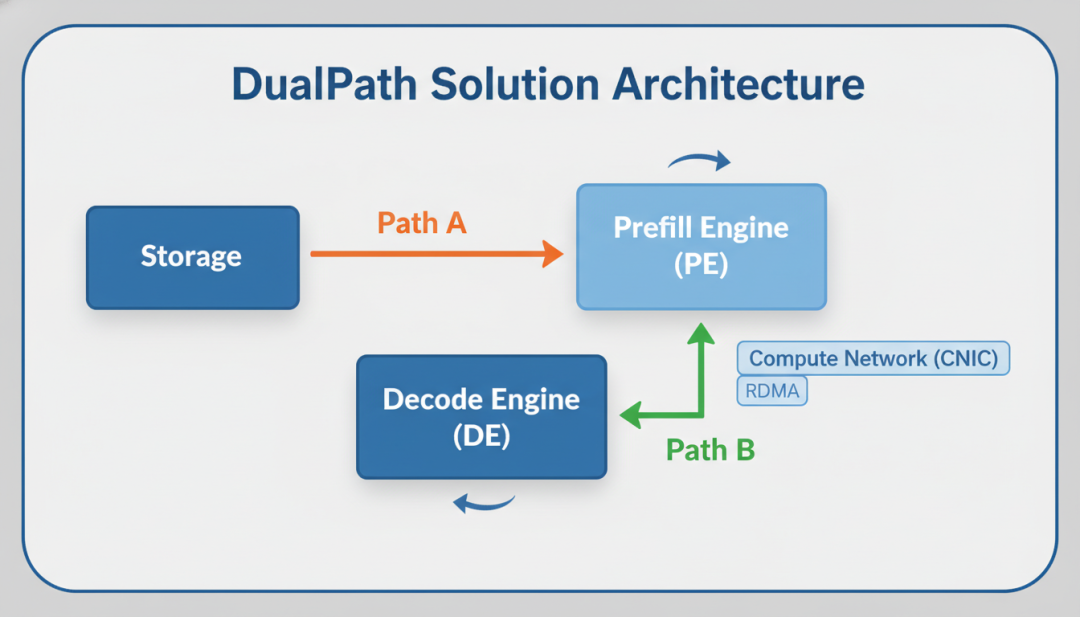
双路径加载架构示意图
为什么这么做?
- 解码引擎的存储网卡闲着,不用白不用
- 计算网络(CNIC)的聚合带宽比存储网络大得多,而且利用率不高
- 模型推理的通信是亚毫秒级的突发,中间有大量空闲时间可以利用
总结一下

4.2 三个技术挑战与解法
挑战1:怎么分配流量?
不能所有请求都走解码引擎,那样解码引擎的SNIC又饱和了。也不能都不走,那瓶颈还在。
解法:全局调度器——负责动态决定每个请求走哪条路径,考虑存储NIC队列长度、GPU负载情况、请求特征等因素。
挑战2:KV-Cache传输会不会干扰模型推理?
计算网络本来是用来做模型推理通信的(比如AllReduce、AllToAll),如果在上面传输KV-Cache,会不会影响延迟?
解法:CNIC-centric流量管理——用虚拟lanes(VLs)做隔离,高优先级给模型推理(99%带宽),低优先级给KV-Cache传输(1%带宽)。
挑战3:如何减少传输开销?
解法:层式传输——KV-Cache是按层组织的。DualPath采用层式传输,把计算和数据传输重叠起来:计算第N层的时候,同时加载第N+1层的KV-Cache。
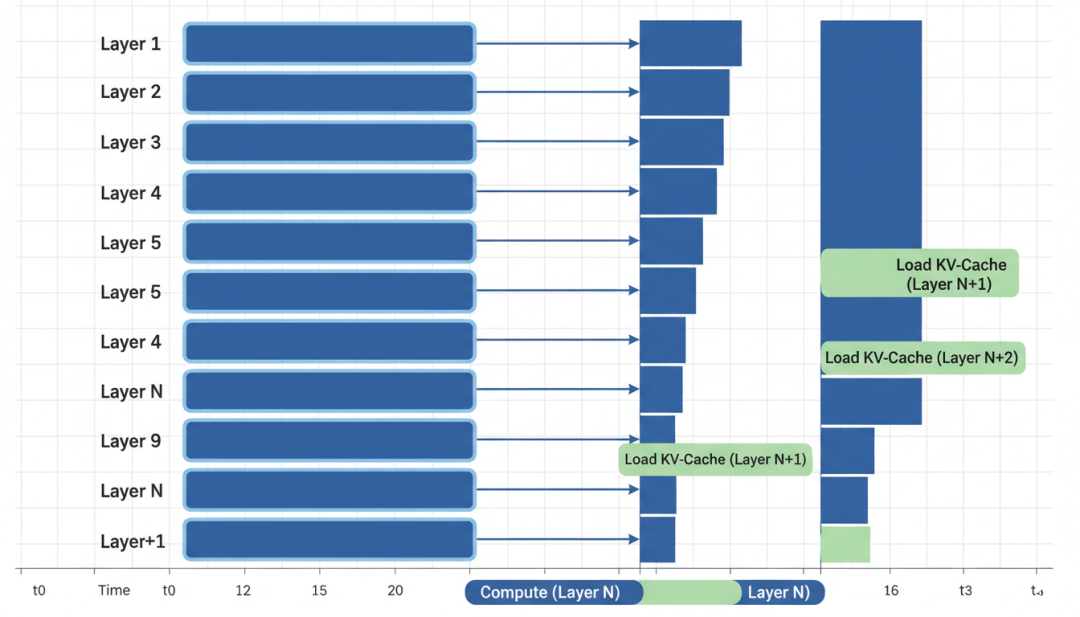
▲ 层式传输:计算与数据传输重叠
实测结果——1.87倍提升
说了这么多理论,效果到底怎么样?
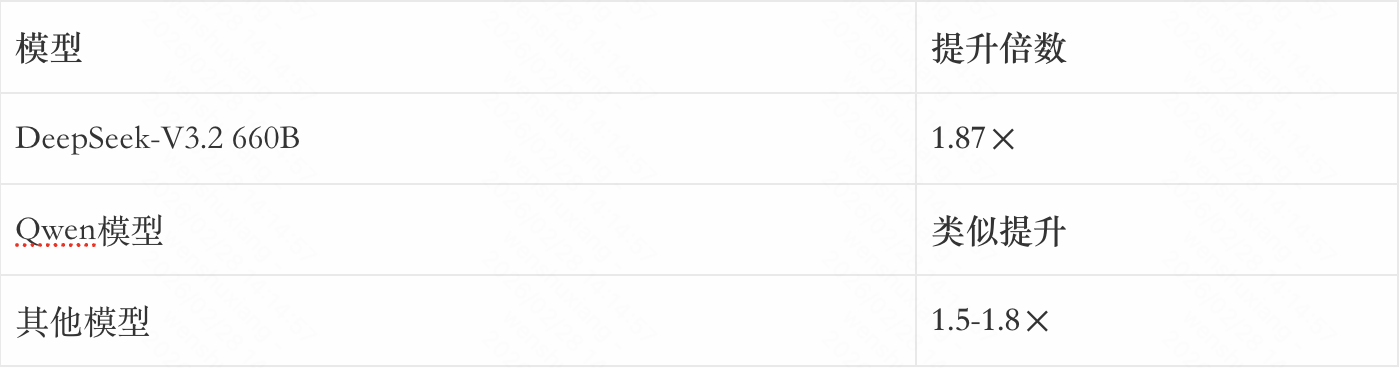
DeepSeek在三个模型上做了实验,用的是生产级的智能体workload。

▲ DualPath性能提升结果
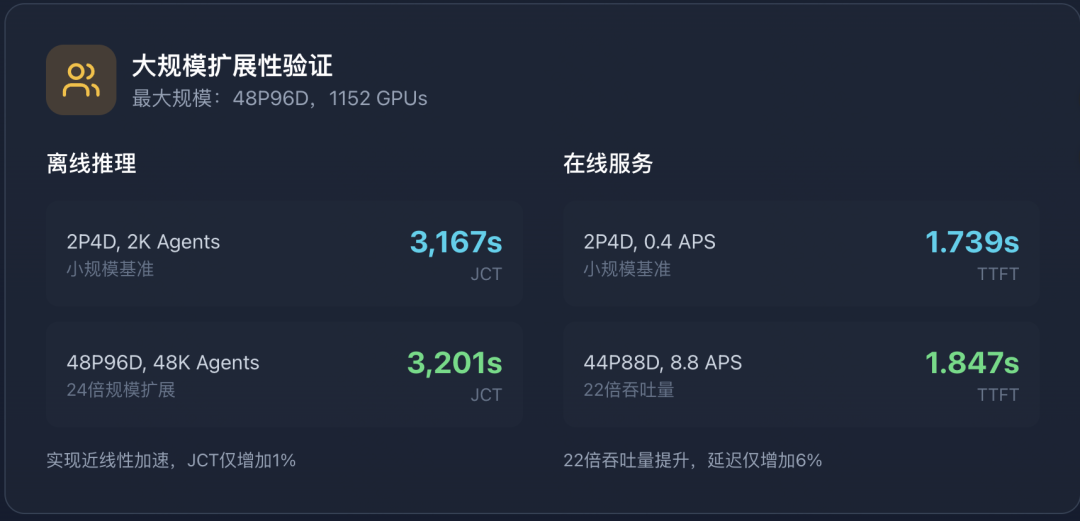
5.1 离线推理(batch模式)
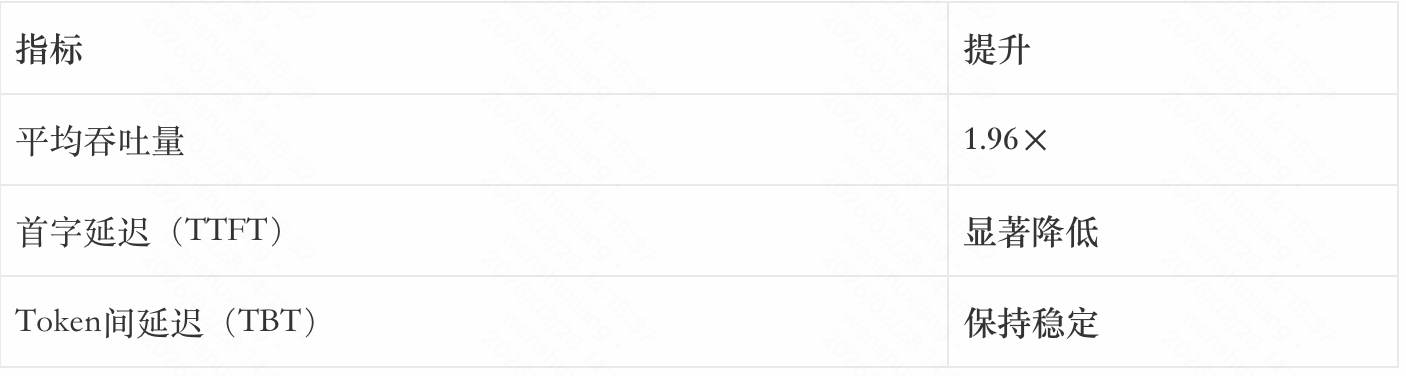
5.2 在线服务
最重要的是:不需要额外硬件
DualPath是在现有架构上的优化,只是改了数据流动的方式。不需要加网卡,不需要换GPU,不需要升级存储。这是“零成本”的性能提升。
大规模验证
论文还做了大规模实验,使用最多1,152个GPU来验证可扩展性。
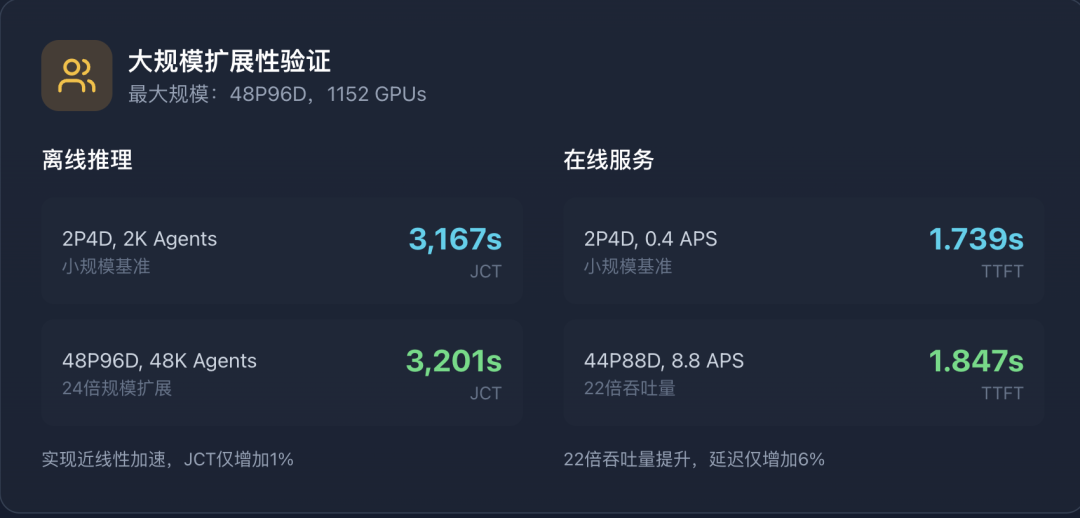
关键发现
从2P4D(2K agents)扩展到48P96D(48K agents),实现了近线性加速(JCT 3,167s vs. 3,201s)。在线服务配置下,44P88D实现了22倍吞吐量(8.8 vs. 0.4 APS),同时保持相似的延迟。
智能体时代的新架构
读完这篇论文,我觉得DeepSeek在传递一个信号:智能体时代需要新的系统架构。
7.1 从单轮到多轮
过去几年,LLM推理系统主要针对的是”单轮对话”这个场景。预填充一次,解码一次,结束。
这种场景下,I/O不是主要矛盾,计算才是。
但现在不一样了。智能体应用是多轮、长上下文、与环境交互的。每一轮都要读历史,都要写缓存。
I/O成了主要矛盾。
7.2 不是推翻,而是优化
传统架构的优势(比如PD分离)还在,但瓶颈转移了。
DeepSeek的DualPath不是推翻PD分离,而是在PD分离的基础上,重新思考KV-Cache的加载方式。
7.3 资源利用的哲学
这让我想到另一个问题:还有哪些资源被浪费了?
除了存储网卡,还有哪些地方存在”一半在加班,一半在睡觉”的情况?
- 可能是HBM的利用不均衡?
- 可能是GPU的利用率不均衡?
- 可能是网络带宽的利用不均衡?
DualPath的思路是:不要只看局部瓶颈,要看整体资源分配。有时候最好的优化不是堆硬件,而是把闲置的资源用起来。
总结
DeepSeek在论文里说,未来还可以探索更多方向:
- 更智能的调度算法
- 跨机房的KV-Cache共享
- 与其他优化(如Mooncake)结合
2026年,智能体时代才刚开始,系统架构的创新空间还很大。
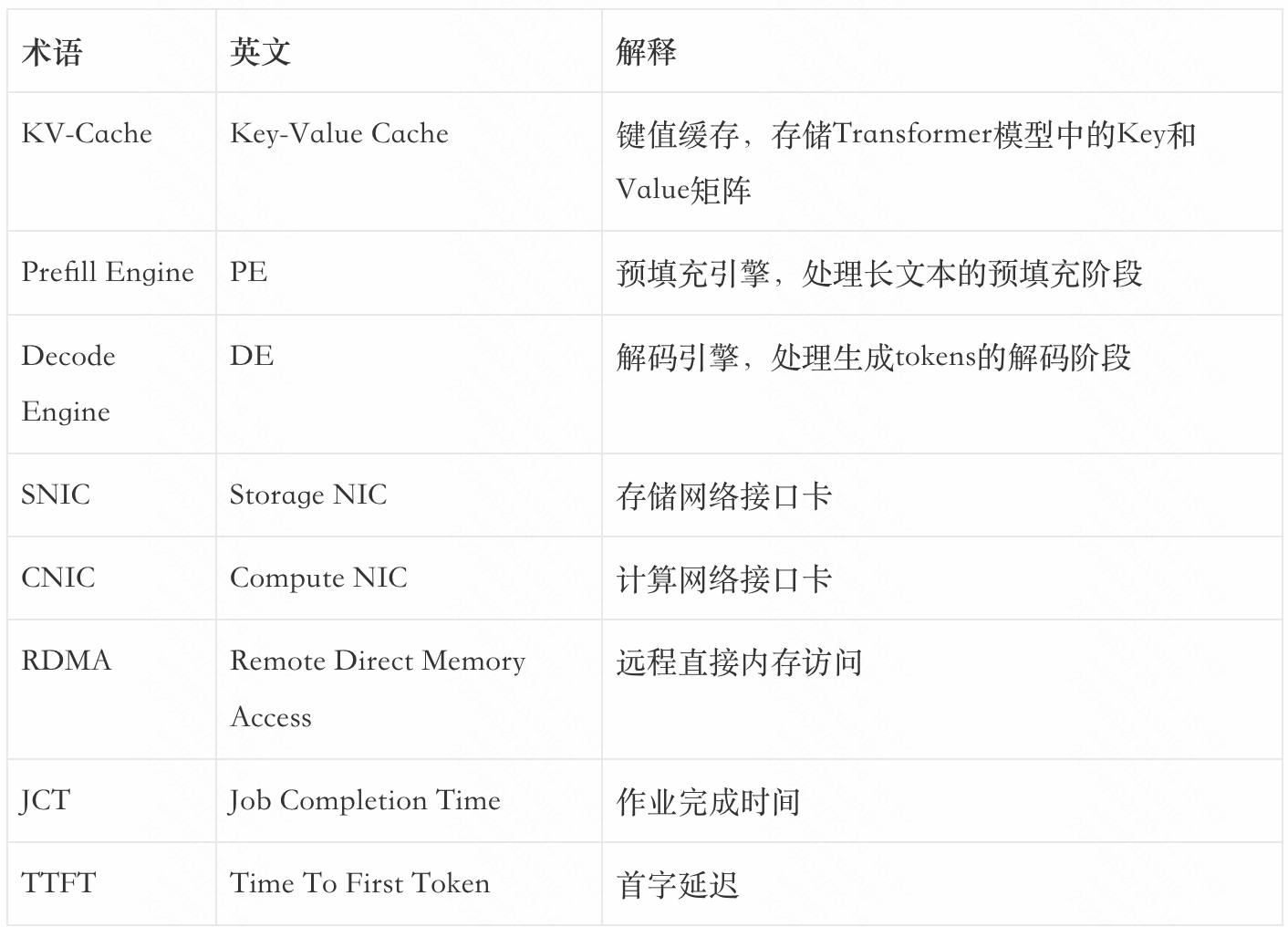
附录:关键术语
原论文链接:https://arxiv.org/pdf/2602.21548
本文由 @卡萨丁AI 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


