
 起点课堂会员权益
起点课堂会员权益再谈OpenClaw记忆范式:启发、不足和方向
OpenClaw的记忆系统正在重新定义AI产品的交互逻辑。它将记忆分层为短期、近端与长期结构,通过动态检索与智能写入构建用户画像。然而高门槛、检索局限与token消耗等问题也暴露无遗。本文深度解构其三层记忆架构,揭示国产化改进背后的技术博弈与产品设计启示。

刚才整理思路时,忽然意识到:我可能是中文互联网第一个意识到openclaw/clawdbot价值的传播者吧
在1月26号的文章Clawdbot爆火|范式演进:全网首个架构解剖中提到:clawdbot的价值在国内被低估了,当时我搜索了中文互联网只有1篇介绍的文章,是当做一个普通工具来介绍的,但我意识到,这可能就是未来的个人agent范式,类似个人电脑MAC、个人手机iPhone(老是用这个类比,因为太羡慕乔布斯那个创造时刻了),我兴奋得不得了,半夜三点睡不着,爬起来写作。
那时没后来这么笃定,只是觉得对应到《科学革命的结构》中,即便不是发现“氧气”的时刻,也是命名为“燃烧素”这样的时刻(科学家发现有氧气就能燃烧),是一种关键范式演进,在同一天的一连更新了第二篇文章全网首曝:Clawdbot用自动化记忆破局“不可能三角”中进一步介绍了clawdbot记忆系统的独特性。
有些激动,很是上头。这种亲自参与到历史过程的感觉,必将终身难忘。
一个月过去了,吹捧openclaw的文章汗牛充栋了,我却想谈谈这个记忆系统的不足。

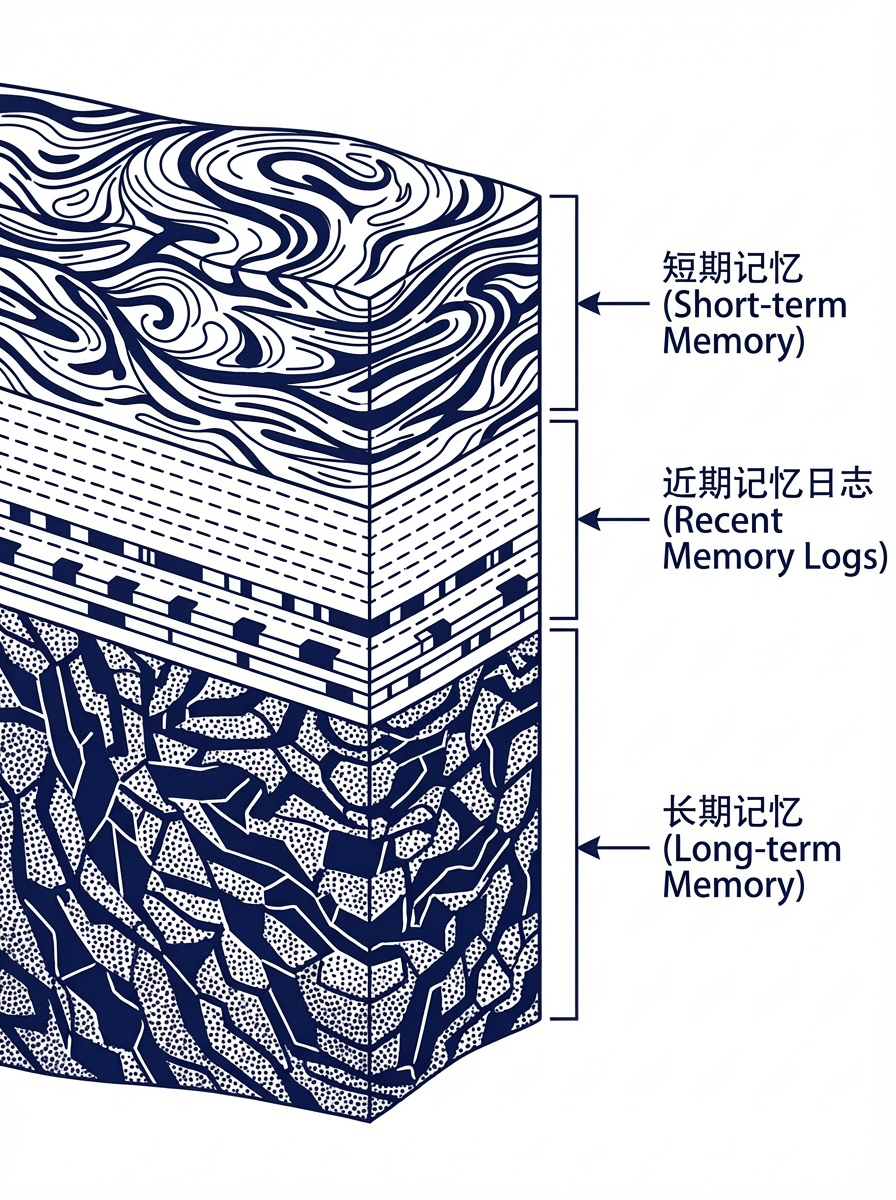
01 记忆的三个层次
之前大多数AI产品的记忆,停留在第一层。
OpenClaw的架构把记忆分得很清楚,三层,各司其职:
第一层:Chat Context(短期)
当前会话里,直接塞给模型的那段token。受context window限制,会话结束即清空。它不是记忆,它是工作台——用完就收。
第二层:Daily Log(近端)
每天一个append-only的日志文件,记录当天发生的事情、决策、重要上下文。新会话开始时,系统读取”今天+昨天”的日志,给Agent最近48小时的连续感。
这一层解决的问题是:Agent知道昨天发生了什么。
第三层:结构化长期记忆(长期)
这才是真正的记忆。OpenClaw的实现是一组Markdown文件:
preferences.md → 你的偏好和习惯projects.md → 你在做什么,进展如何contacts.md → 相关的人learnings.md → 解决过的问题和经验tools.md → 常用工具和工作流custom/*.md → 用户自定义分类
这一层解决的问题是:Agent知道你是谁。
三层的分工:
Chat Context → 你现在说了什么Daily Log → 你最近经历了什么长期记忆 → 你是一个什么样的人
缺任何一层,Agent对用户的理解都是残缺的。
02 上下文怎么进入模型
记忆存在磁盘上,但模型只能读token。
这中间有一个关键的工程问题:怎么把磁盘上的记忆,变成模型推理时真正有用的上下文?
答案不是把所有记忆硬塞给模型。那样做,context window会爆,推理质量会下降,成本会失控。
OpenClaw的解法是:检索+动态拼接。
第一步:Hybrid Search
用户发来一条消息,系统先做检索,从记忆库里找最相关的片段。
检索用的是混合策略:
- BM25关键词检索:找到包含相关词汇的记忆
- Embedding语义检索:找到语义上相关的记忆
- 两者结合,取最相关的若干片段
第二步:Prompt Builder动态拼接
检索结果出来之后,Prompt Builder把以下内容组装成最终的prompt:
系统指令(Agent身份和约束) +相关记忆片段(检索结果) +近期对话历史(Session History Loader提取) +当前用户输入 =最终送给模型的prompt
第三步:Context Window Guard兜底
在送给模型之前,Context Window Guard监控token总量。接近上限时,触发压缩——把长历史总结成短摘要,防止上下文爆炸导致模型输出质量下降。
这个设计的核心思想是:
模型不需要知道所有事,只需要知道此刻最相关的事。
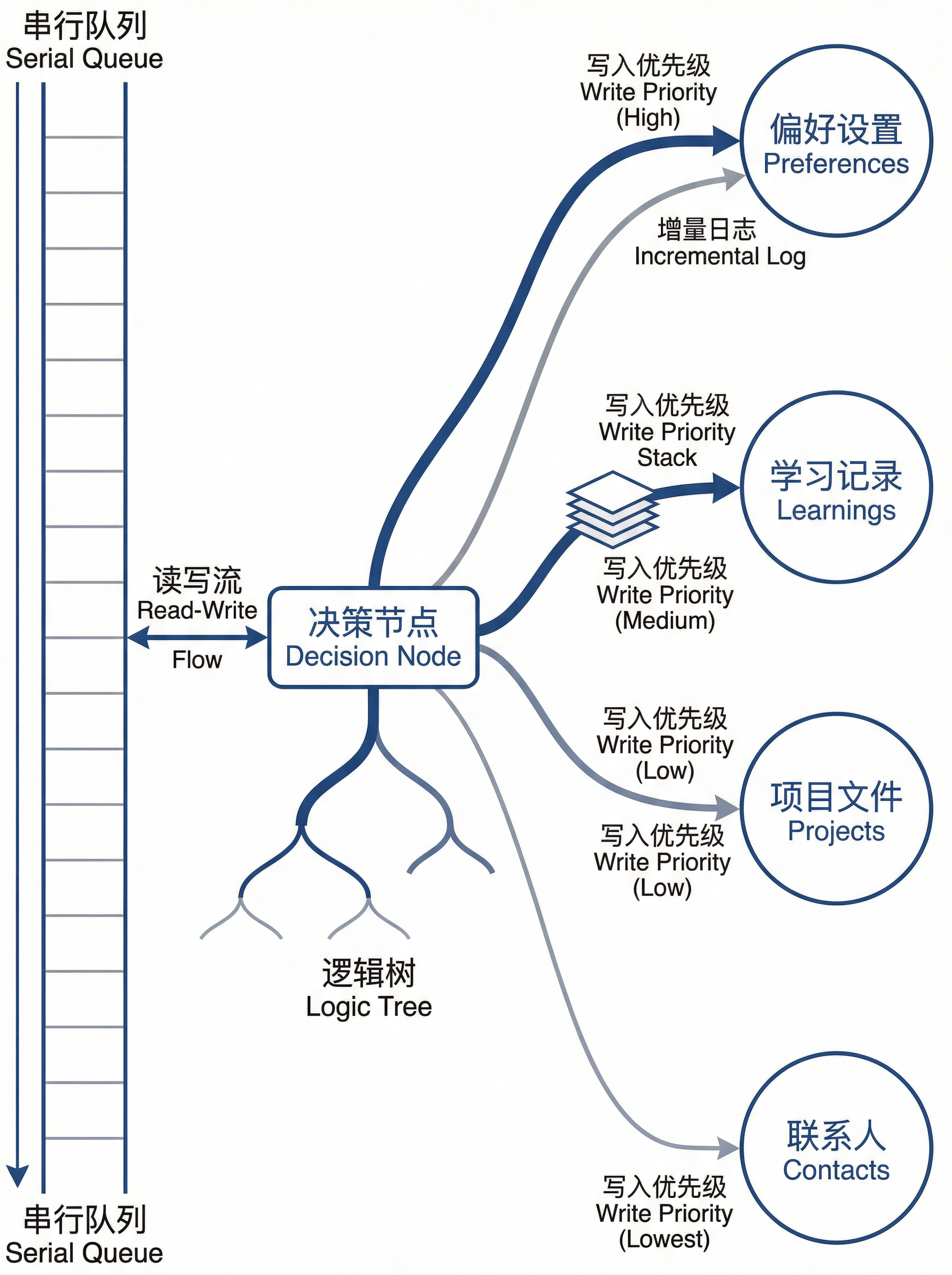
03 记忆怎么写入
检索解决了”怎么读”,写入解决的是”怎么存”。
OpenClaw的写入原则只有一条:只写有价值的东西。
两类写入触发:
自动写入:每次会话中的重要步骤、决策、异常,追加进当天的Daily Log。这是append-only的,不覆盖,只追加。
识别写入:当系统判断某个信息”长期有用”时,写入对应的长期记忆文件。判断标准是稳定性——这个信息会在未来的多次会话里持续有价值吗?
写入的分类逻辑:
用户说”我以后都用深色模式”→ 稳定偏好 → preferences.md用户完成了一个复杂问题的解决→ 可复用经验 → learnings.md用户开始了一个新项目→ 项目状态 → projects.md用户提到了一个重要的人→ 人物信息 → contacts.md
一个重要的架构细节:
OpenClaw把记忆写入视为与工具调用同级的动作。这意味着写入不是后台静默发生的,而是Agent推理过程的一部分——Agent决定”这件事值得记住”,然后执行写入。
同时,Lane Queue确保写入和读取串行执行,避免竞争条件导致记忆文件损坏。
用户的显式控制:
除了系统自动写入,用户可以用自然语言直接操作记忆:
“记住我以后都用深色模式” → 写入preferences.md”忘掉我之前项目的所有内容” → 清理projects.md相关内容”你记住了我哪些东西?” → 读取并总结相关记忆
这让记忆系统对用户是透明的、可控的。
04 记忆系统的产品设计启示
从OpenClaw的架构出发,如果你在设计一个面向用户的AI产品,记忆系统有五个问题必须想清楚。
问题一:你的长期记忆存什么?
不是存所有东西,是存”跨会话持续有价值”的东西。
对不同产品,这个答案完全不同。一个写作助手的长期记忆,核心是用户的写作风格和偏好;一个学习产品的长期记忆,核心是用户的知识边界和学习路径。
在设计之初就想清楚:你的用户,哪些信息是跨会话持续有价值的?
问题二:你的检索策略是什么?
记忆存得再多,检索不准,等于没存。
Hybrid Search是目前最稳健的方案——关键词检索兜底,语义检索提升相关性。两者结合,比单独用任何一种都准。
但检索策略还有一个更深的问题:检索的输入是什么? 是用户当前的输入,还是用户输入+当前会话摘要+用户画像?输入越丰富,检索结果越准。
问题三:什么值得写入长期记忆?
这是最难的判断。写太多,长期记忆变成噪音;写太少,Agent对用户的理解停留在表面。
一个可操作的判断标准:这个信息,在三次以上未来的会话里会有价值吗? 如果是,写入长期记忆;如果只是当下有用,写入Daily Log或不写。
问题四:用户怎么知道Agent记住了什么?
记忆系统对用户不透明,是信任的最大杀手。
用户不知道Agent记住了什么,就不知道该不该信任它的判断。OpenClaw的解法是让用户可以随时查询记忆内容。
产品设计上,这可以是一个”Agent对你的理解”页面——展示Agent当前对用户的理解,让用户看到、确认、纠正。
问题五:用户怎么纠正错误的记忆?
记忆会出错。Agent可能误判用户的偏好,可能把一次性的情况写成了稳定偏好。
纠正机制必须设计得足够轻量——不能让用户去找一个设置页面手动删除某条记忆。最好的方式是自然语言直接操作,就像OpenClaw的设计:用户说”忘掉这件事”,系统执行。
05 这套设计的真实不足
OpenClaw的记忆架构是目前最完整的工程实现之一,但在实际使用中,它的问题同样清晰。
1. 高上限高门槛
本地文件化记忆系统可控性强但使用门槛高。这种“高上限、高门槛”特性,所以这就给了国产化的机会,如天工、网易、阿里都出了仿款,还开源促使在中国土壤的生长。
2. 进了上下文窗口,就难逃被压缩的命运
长期记忆的读取路径是:从文件读入→塞进上下文→随对话变长被summary或截断。
一旦进入模型上下文,记忆就暴露在压缩风险里。被概括错、细节丢失、session结束后没有写回——这些情况加在一起,等于”记了,但没真正记住”。
3. 向量检索不理解关系
默认把记忆文件切成约400 token的chunk做embedding,用SQLite做向量检索。数据少时勉强够用,文件一多就暴露出根本性的局限:
周一写入:”Alice manages the auth team”周五提问:”who handles auth permissions?”向量检索的结果:找到了”有Alice的块”找到了”有auth的块”但不会把两者连起来,推断出Alice负责权限问题
记得很多,但不会推关系。这是纯向量检索的天花板,不是调参能解决的。
4. 维护成本随规模线性增长
file-first的设计带来了极高的可见性,但也带来了持续的维护负担:目录结构要手动设计,跨项目共享记忆要自己搭脚本,随着workspace变大,索引更新、重嵌入、清理无用记忆都需要人工介入。
5. Token消耗偏高
为了”怕忘”而在每轮对话里塞入过多记忆片段,token消耗会快速飙升。LinkedIn等团队的实战经验明确指出:OpenClaw执行经常”token-hungry”,记忆系统是主要原因之一。Token消耗是其他工具的3-5倍,和Claude code共同造成了全球token消耗的10倍增长。
6. 基础设施的脆弱性
默认使用OpenAI embeddings,环境变量配置不当就会频繁401,记忆检索直接挂掉。非英语环境下,早期版本的embedding质量也被明确指出有回忆准确度不足的问题。
06 改进方向:生态在往哪里走
这些不足催生了一批改进方案,在OpenClaw的架构上加层。
Mem0:自动捕获,解决”需要人工布置”的问题
Mem0做的事情可以理解为:给记忆系统加一层自动化。
它的核心改进是两个动作的自动化——自动捕获和自动回忆。不需要手写记忆写入逻辑,插件从对话中自动抽取”事实性、长期有用”的内容存入持久层;新对话开始时,自动根据当前问题检索相关记忆注入上下文。
同时,它把记忆从”上下文窗口内”搬到了”独立持久层”,避免compaction把事实压坏,也为多Agent共享记忆提供了基础。
QMD:更精准的检索,解决Token浪费
QMD作为更高级的memory backend,重点解决检索精度问题。
它不是单纯的相似度检索,而是混合字段、权重和query-time合成规则,实现有上下文感知的检索。配置层面可以限制maxResults、maxSnippetChars、超时和scope,减少无关片段注入上下文的情况。
效果是双重的:检索更准,Token消耗更可控。
知识图谱型记忆:解决”记得很多但不会连”
以Cognee为代表的一路改进,用知识图谱弥补向量检索的关系性缺陷。
设计思路是把”谁管理谁、哪个项目依赖哪个组件”这类关系结构化为节点和边,而不是散落在独立chunk中。查询时不只按相似度找文本,还可以按图结构浏览相关实体和关系。
对于多跳关系和组合事实的查询,知识图谱的表现显著优于纯向量检索。
多Agent共享记忆层:解决重复消耗
MemOS等方案让多个Agent共享同一记忆层,不需要手动在prompt之间复制上下文。
数据层面,在LOCOMO数据集的测试中,token使用量从1560万降到440万,减少约72%。这个数字背后的逻辑是:不同Agent间记忆各自为战,导致重复问、重复算、重复消耗——共享记忆层从根本上消除了这个浪费。
MemSearch:把记忆子系统抽出来独立使用
还有一条路是把OpenClaw的记忆子系统抽取出来,做成通用组件。
MemSearch将其git-backed memory独立开源,让团队可以单独使用”文件+索引+git历史”这套记忆层。好处是团队协作可以用git审核、回滚AI记忆,OpenClaw的”可见性+可编辑性”理念也得以在其他Agent框架里复用。
07 三个“正向演化轴”
1. 记忆时间轴:
- 短期记忆(当前对话 / chat context)
- 近端记忆(最近几天或当前任务的工作记要 / daily logs)
- 长期记忆(稳定偏好、长期项目、复用知识 / long-term store)
2、记忆操作轴:
- 自动捕获(系统自动决定“什么值得记”)
- 精准检索(只取当下问题真正需要的那一点点)
- 关系理解(不只是找到文本块,而是理解“谁和谁、事和事之间怎么关联”)
3. 系统范围轴:
- 单 Agent(每个 Agent 自己有一小块记忆)
- 多 Agent 共享(团队/系统级公共记忆,减少重复和上下文搬运)
唯一需要补充的是:
- “更大的上下文窗口”仍然有价值,但更多是底层算力/模型能力的演进;
- “更聪明的分层管理”则是系统设计层的演进,两者是互补而不是完全对立。
未来记忆系统的核心竞争力,不在单纯拉大上下文窗口,而在于围绕“分层记忆 + 自动捕获 + 精准检索 + 关系理解 + 多 Agent 共享”构建一套聪明的记忆管理策略。
本文由 @AIGC从0到1 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


