
 起点课堂会员权益
起点课堂会员权益从AI硬件发展史看AI+产品形态
从《钢铁侠》中的贾维斯到2035年的AI硬件革命,AI助手正从科幻走向现实。这场变革不仅仅是技术进步的故事,更是算法、计算架构、用户需求和硬件能力协同进化的复杂交响曲。本文将深入解析AI硬件如何跨越从通用计算到专用芯片的四大发展阶段,揭示未来边缘计算与异构架构如何重构我们与智能的交互方式。

如果你看过《钢铁侠》,一定记得托尼·斯塔克的AI助手贾维斯(J.A.R.V.I.S.)。托尼走进实验室,随口说一句”贾维斯,帮我分析一下这套装甲的结构强度”,全息投影瞬间展开,数据实时流动,贾维斯用略带英式口音的声音平静地回应:”当然,斯塔克先生。”没有键盘,没有鼠标,没有等待——智能就像空气一样,弥漫在整个空间里。
2026年的今天,这还是电影里的场景。但如果沿着当前AI硬件的发展轨迹推演下去,我们或许可以想象这样一幅画面——
2035年,上海。建筑设计师 林苇不 需要触碰任何屏幕,只是轻声说出需求,三座城市模型便在空气中凝聚成形,结构应力、能源消耗、气流循环,全部实时可见、随手可调。她的AI伙伴”元”,正是 现实版 的贾维斯——算力 不 来自某台远端的超级计算机,而是弥散在整个空间里:墙壁里的芯片、天花板里的计算单元,甚至她佩戴的耳环,都是这个系统的一部分。
这当然是推演,不是预言。但它并非凭空而来——贾维斯为什么迷人?因为它代表了人类对智能助手最朴素的想象:随时在场、无需操作、即问即答。而要让这个想象 一 步步走向现实,中间横亘着一场我们正在亲历的硬件革命。
这场革命,正是我们今天要讲的故事。
01 AI硬件的发展要素:一场多体协同的进化
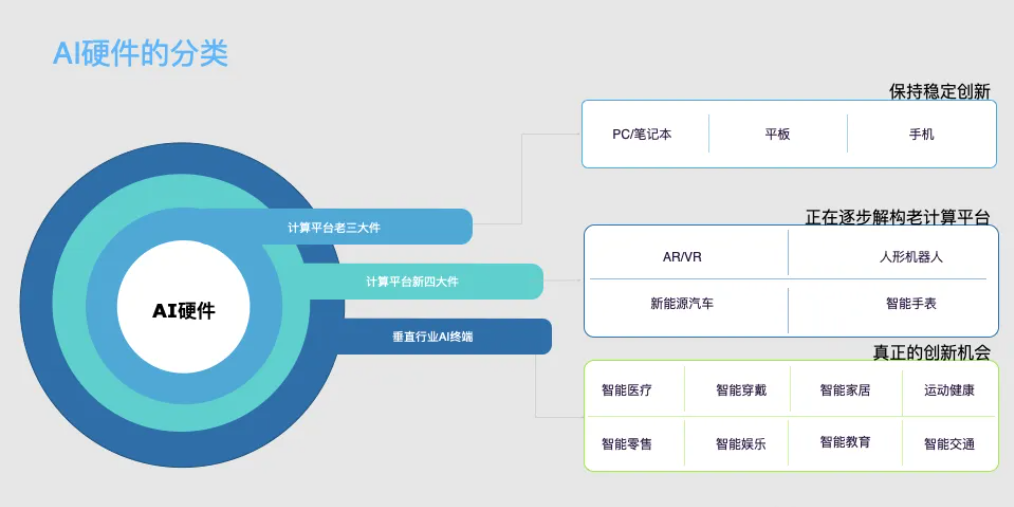
人工智能的每一次飞跃,都不是单一维度的突破,而是多个核心要素相互催化、协同演进的结果。硬件作为承载智能的物理基石,其发展轨迹深刻地受到算法、 架构、需求和物理定律的共同塑造。理解这些驱动力,是把握整个AI发展脉络的关键。
算法:智能的灵魂与算力的需求定义
算法是AI硬件发展的最根本的需求牵引。硬件的设计目标,本质上是为了更高效地执行特定的算法。从早期简单的感知机模型,到后来统治学界数十年的支持向量机(SVM),它们 对算力的 需求尚在通用处理器(CPU)的可控范围之内。然而,21世纪初,深度学习的复兴彻底改变了游戏规则。
以卷积神经网络(CNN)、循环神经网络(RNN)乃至后来的Transformer架构为代表的深度学习模型,其核心是海量的、重复的、高度并行的数学运算——主要是矩阵乘法和向量计算。这种计算模式与传统CPU为复杂逻辑控制和串行任务设计的架构格格不入。正是这种“错配”,为GPU的崛起埋下了伏笔。可以说, AlexNet 的成功,成为GPU全面进入AI计算领域的标志性转折点 。此后,算法与硬件开启了长达十余年的协作共舞:更大更深的模型(如GPT系列)催生了对更强算力、更大显存的硬件需求;而硬件能力的提升(如Tensor Core的出现),又反过来让研究者敢于设计和训练前所未有的复杂算法。这是一个典型的正反馈循环。
计算架构:从通用到专用的必然之路
如果说算法定义了“算什么”,那么计算架构则决定了“怎么算”。AI硬件的发展史,在很大程度上是一部计算架构从通用走向专用的历史。
最初, CPU(中央处理器)作为通用计算的王者,凭借其强大的逻辑控制单元和极低的延迟,处理着所有计算任务。但面对深度学习中简单计算任务的“数据 洪流”,CPU的“冯·诺依曼瓶颈”——即计算单元与存储单元分离导致的频繁数据搬运——使其力不从心。这就好比让一位大学教授去计算一亿次“1+1”,虽然他能做,但效率极低。
GPU(图形处理器)的出现是第一次架构革命。它拥有数千个小型计算核心,天生为并行计算而生,能同时处理大量简单的数学运算,完美契合了深度学习的需求。NVIDIA的CUDA生态更是将这种并行计算能力普及开来,使其成为AI训练的“标准配置”。
然而,当AI应用规模化后,对能效比的要求日益严苛。于是, ASIC(专用集成电路)应运而生。 谷歌的 TPU(张量处理单元)是其中的里程碑。它抛弃了GPU中与图形处理相关的冗余部分,采用“脉动阵列”等架构,将数据流和计算 流高度 优化,实现了针对特定AI运算(主要是矩阵乘法)的极致效率。这标志着AI硬件进入了 “百花齐放”的专用化时代。
用户需求:从云端到边缘的场景驱动
技术的发展终究要服务于人的需求。AI硬件的演进路径,也清晰地反映了应用场景的变迁。
在AI发展的早期, 算力被 少数大型企业和研究机构垄断在云端数据中心。用户通过互联网接口享受AI服务,如搜索、翻译和推荐系统。这一阶段,硬件发展的核心目标是追求极致的吞吐量和性能,功耗和成本相对次要。
随着智能手机、智能家居、自动驾驶汽车的普及,用户对“实时响应、数据隐私和离线运行”的需求日益增长。将所有数据上传云端再等待结果返回,不仅延迟高,还存在隐私风险。因此,将AI计算能力下沉到用户设备端,即边缘计算, 成为必然趋势。这催生了对低功耗、小体积、高能效的AI芯片的需求,如苹果的A系列仿生芯片中的神经网络引擎(NPU)、高通的AI引擎等。边缘AI硬件的设计,必须在性能、功耗和成本之间做出精妙的平衡。
苹果Silicon芯片的另一个被长期低估的贡献,是其统一内存架构(Unified Memory Architecture, UMA)。在传统PC架构中,CPU内存与GPU显 存相互 隔离,大型模型 推理受 限于显存容量上限(如消费级GPU通常为8~24GB)。而苹果M系列芯片将CPU、GPU与神经网络引擎的内存池完全打通,用户可将全部系统内存(最高可配至192GB)用于模型推理,且内存带宽远超同价位独立显卡。这使得Mac在本地运行数十亿乃至千亿参数级别的大语言模型成为可能,配合llama.cpp、Ollama等开源推理框架,一台消费级Mac Pro已能流畅运行此前只能在数据中心部署的模型。这是边缘AI能力的一次静默的质变—— 算力不再 是云端的专利,而是可以安静地运行在桌面上。
硬件能力:摩尔定律下的物理基石与超越
所有上层建筑都离不开坚实的物理基础。半导体工艺的进步,是整个AI硬件大厦的基石。在过去几十年里,摩尔定律—— 集成电路上可容纳的晶体管数量约每两年翻一番 。更先进的制程(如从28nm到3nm)意味着可以在同样大小的芯片上集成更多的计算单元,同时降低单位计算的功耗。
然而,随着晶体管尺寸逼近物理极限,摩尔定律的经济效益和物理效益都在放缓。这迫使行业寻找 “后摩尔时代”的增长路径。这包括:
- 先进封装技术:通过3D堆叠、 Chiplet (芯粒)等技术,将多个功能不同的芯片像搭积木一样封装在一起,绕开单片芯片的尺寸限制,实现“超越摩尔”的性能集成。
- 存储与互联:AI计算是数据密集型的, 算力再强 ,数据跟不上也是枉然。“内存墙”问题日益突出。因此,HBM(高带宽内存)等技术的发展,以及 NVLink 、CXL等高速互联协议的演进,对于提升整个计算系统的实际性能至关重要。
- 新材料与新器件:碳纳米管、二 维材料 等新材料的研究,以及忆 阻器等存算 一体器件的探索,为未来彻底颠覆传统计算架构提供了可能。
不难看出,AI硬件的发展是“算法、架构、需求、工艺”四大要素共同作用下的复杂舞蹈。它们相互定义、相互促进,共同谱写了从CPU的蛮荒时代到如今百花齐放的智能计算新篇章。
02 AI硬件的历史阶段:从通用计算到异构洪流
回顾AI硬件的演进历程,我们可以清晰地划分出几个标志性的时代。每个时代都由一种主流的计算范式所定义,并孕育了特定形态的AI应用。

CPU的时代(~2012年以前)
在深度学习浪潮席卷之前,人工智能的研究更多停留在理论和小型实验阶段。那是一个CPU作为唯一核心的时代。无论是专家系统、符号主义AI,还是早期的机器学习算法,都运行在通用CPU之上。CPU的设计是:它拥有强大的控制单元和复杂的指令集,擅长处理逻辑判断、分支跳转等复杂串行任务,力求降低单线程任务的延迟。
然而,对于当时逐渐兴起的、需要大量数据处理的统计机器学习方法,CPU开始显得力不从心。研究者们尝试使用FPGA(现场可编程门阵列)和DSP(数字信号处理器)进行加速,但由于编程复杂、生态匮乏,这些尝试始终未能成为 主流。这个时代的AI,更像是被囚禁在象牙塔中的“思想实验”,硬件的限制使其难以走向大规模的实际应用。
GPU的黄金十年(2012年~2022年)
2012年, AlexNet 在ImageNet图像识别竞赛中取得的突破性成功,犹如一声惊雷,开启了深度学习的时代,也开启了GPU统治AI计算的黄金十年。Geoffrey Hinton团队创造性地使用两块NVIDIA GTX 580 GPU进行模型训练,充分利用了GPU大规模并行计算的优势,将训练速度提升了数倍,从而使得更深、更复杂的网络成为可能。
这一事件的背后,是NVIDIA多年来在GPGPU(通用图形处理器)领域的深耕。其推出的CUDA(统一计算设备架构)编程平台,极大地降低了开发者利用GPU进行通用计算的门槛。从此,GPU不再仅仅是游戏玩家的专属,而是成为了AI研究者和工程师手中最强大的武器。从Pascal、Volta到Ampere架构,NVIDIA不断在GPU中加入为AI优化的设计,如Tensor Core(张量核心),这种专为矩阵运算设计的硬件单元,进一步巩固了其在AI训练市场的霸主地位。这个时代,AI开始走出实验室,在云端大规模部署,催生了我们今天所熟知的图像识别、语音助手、推荐引擎等应用。
ASIC崛起与架构分化(2022 年~至今)
当AI从“能用”走向“好用”,特别是走向商业化大规模部署时,单纯追求峰值性能的GPU开始面临能效比和成本的挑战。在推理(Inference)场景下,功耗和延迟变得至关重要。于是,为特定AI算法“量身定制”的ASIC芯片登上了历史舞台,AI硬件进入了多元化和专用化的“诸神之战”时代。
这一阶段与GPU黄金十年存在时间交叠——ASIC的兴起并非等待GPU退场,而是在GPU仍主导训练市场时,推理场景已悄然开辟了另一条赛道。 谷歌的 TPU(2016年)是这场战争的开端。它砍掉了GPU中所有与图形无关的功能,内部采用脉动阵列架构,数据在计算单元之间规律地流动,极大地减少了对内存的访问,从而在执行神经网络推理时获得了远超同期 GPU 的能效比。TPU的成功,激励了 所有云服务 巨头和科技公司投身自 研 芯片的浪潮:亚马逊的 Inferentia 和 Trainium 、微软的Maia、Meta的MTIA,以及国内的华为昇腾、阿里含光等,都旨在为自身的业务负载提供最优化的硬件解决方案。
与此同时,在边缘侧,苹果在其A系列芯片中集成的神经网络引擎(NPU),让强大的AI能力可以在iPhone上本地运行,实现了如面部解锁、实时图像处理等功能,同时保护了用户隐私。高通、 联发科等 移动芯片厂商也纷纷将NPU作为其SoC的核心卖点。AI硬件的战场,从云端数据中心,全面扩展到了我们口袋里的每一部手机、家里的每一个智能音箱和路上的每一辆汽车中。
未来序章:异构计算与新范式探索(正在发生)
当前,我们正处在一个承前启后的新阶段。随着单一芯片性能提升的边际效益递减,异构计算成为主流。一个复杂的AI任务,会被智能地拆解,分配给系统中不同的计算单元——CPU负责逻辑控制,GPU处理大规模并行训练,NPU/TPU执行高效推理,甚至还有专用的视频编解码单元(VCU)、图像信号处理器(ISP)等协同工作。这种团队作战的模式,通过 Chiplet 、CXL等技术连接,将成为未来高性能计算的标准形态。
更激动人心的是,对全新计算范式的探索正在加速。 存算一体 技术试图打破冯·诺依曼瓶颈,在存储单元内部直接进行计算,有望带来能效的数量级提升。 神经形态计算模仿生物大脑的结构和信息处理方式,采用事件驱动的脉冲进行通信和计算,在处理时序信号和低功耗场景下展现出巨大潜力。而光子计算和量子计算,虽然仍处于早期阶段,但它们分别承诺了在通信带宽和特定问题(如优化、模拟)上的颠覆性优势。这些前沿探索,正在为下一代AI硬件的革命积蓄力量。
03 AI硬件的技术内核与产品形态
硬件的技术内核决定了其能力边界,而这些能力最终会物化为我们日常接触到的各种AI产品。理解从底层技术到上层应用的映射关系,有助于我们看清AI如何真正地改变世界。
技术内核:算力、能效与生态的三位一体
不同的AI硬件,其核心竞争力可以从三个维度来衡量:
绝对算力(Performance)
通常以TOPS(每秒万亿次运算)或FLOPS(每秒浮点运算次数)来衡量。对于需要处理海量数据的云端训练任务,如训练千亿参数的大语言模型, 绝对算力是 入场券。NVIDIA的高端数据中心GPU,凭借其无与伦比的算力、大容量的HBM显存和高速的 NVLink 互联,至今仍是这一领域的王者。
然而,随着大模型推理需求的爆炸式增长,一类更激进的专用芯片正在崛起——推理加速芯片,代表了ASIC专用 化进入 模型服务层的新阶段。其技术路线可分为两个梯度:
第一梯度以 Groq 的LPU(语言处理单元)和 Cerebras 的 晶圆级芯片 (WSE)为代表。LPU采用确定性数据流架构,消除传统芯片因任务调度产生的延迟抖动,在大语言模型的token生成速度上可达同等GPU的数倍; Cerebras 则走 向另一个极端,将整块晶圆制成单一芯片,拥有海量片上SRAM,从结构上绕开了外部内存带宽的瓶颈。两者均保留了运行多种模型的灵活性。
第二梯度则代表了更激进的方向。2026年初走出隐身状态的初创公司Taalas,彻底抛弃了”用硬件运行模型”的传统思路,转而将特定模型的权重与计算图直接蚀刻进芯片的物理线路,让”模型本身成为处理器”。其首款芯片HC1基于台积电6nm工艺,无需HBM高带宽内存、3D封装或液冷,据该公司公布的数据,在运行Llama 3.1 8B模型时每用户可达约17,000 tokens/秒,同时将系统功耗和成本大幅压缩。代价是彻底牺牲灵活性——一块芯片只能运行一个固定模型。这种方式将ASIC专用化的粒度,从”为AI计算优化”细化到了”为某一个具体模型而生”,是”硬件定义AI”趋势的最极端现实注脚 。
能效比(Efficiency)
即每瓦功耗能提供多少算力(TOPS/W)。在功耗和散热受限的边缘设备(如手机、无人机、可穿戴设备)和对运营成本敏感的数据中心推理场景中,能效比是核心竞争力。ASIC和NPU通过高度定制化的设计,剥离非核心功能,优化数据通路,从而在能效比上远超通用芯片。
软件生态(Ecosystem)
硬件再强大,没有易用的软件工具链也无法发挥其价值。NVIDIA的成功,一半归功于其GPU的性能,另一半则归功于其构建的CUDA生态系统。这个包含了编译器、库、API和开发工具的庞大生态,锁定了大量的开发者和应用,形成了强大的护城河。对于后来者而言,构建一个成熟、稳定、易用的软件 栈 ,其挑战甚至超过了设计芯片本身。
产品形态:从云到边,无处不在的智能
基于上述技术内核的差异,AI硬件催生了形态各异、功能纷繁的产品,渗透到社会生活的方方面面。
云端AI: 算力即服务(AI as a Service)
云端是AI 算力的“军火库”,以AI服务器和计算集群为主要形态。这些由成千上万 个 GPU或ASIC加速卡组成的庞然大物,为全球的AI研发提供了基础动力。我们日常使用的搜索引擎、社交媒体信息流、在线翻译,背后都有它们的身影。
如今,随着大模型的兴起,云端AI的产品形态进一步演化为模型即服务( MaaS )。企业和个人开发者无需自己从头训练模型,可以直接通过API调用OpenAI、Google等公司提供的强大基础模型,极大地降低了AI应用的开发门槛。
边缘AI:即时响应的本地智能
边缘AI的产品形态更加多样化,它们被集成在各种终端设备中,强调低功耗和实时性。
- 智能手机:这是边缘AI最普及的载体。手机SoC中的NPU,支撑了计算摄影(如背景虚化、夜景模式)、AI美颜、离线语音助手、智能相册分类等功能。
- 智能汽车:自动驾驶是边缘AI计算的集大成者。车载计算平台需要处理来自摄像头、激光雷达、毫米波雷达等多个传感器的数据,进行实时感知、决策和控制。其 对算力的 要求极高,同时对功能安全和可靠性的要求也远超消费电子。
- 智能家居与物联网( AIoT ):智能音箱的语音识别、智能门锁的人脸识别、安防摄像头的异常行为检测,都依赖于嵌入式的AI芯片。这些芯片追求极致的成本和功耗控制,让智能无感地融入家居环境。
端云协同 :混合式AI的崛起
纯云端或纯边缘的方案各有优劣。云端 有算力优势 但延迟高,边缘响应快 但算力有限 。因此, 端云协同 成为一种越来越普遍的产品形态。例如,在智能手机上,简单的语音命令可能由本地NPU直接处理,而复杂的连续对话或知识问答,则会将语音数据上传到云端,由更强大的模型处理后返回结果。在自动驾驶中, 车辆本地 完成实时决策,同时将行驶数据上传到云端进行模型的迭代训练。这种混合模式,兼顾了实时性、隐私保护和持续进化的能力,是未来AI产品形态的重要方向。
04 发展趋势:演进和想象
站在当前的技术节点上,展望未来,AI硬件与产品形态的演进将呈现出几个清晰的趋势,并为我们打开了广阔的想象空间。
趋势一:从“大炼模型”到“大建算力”
大语言模型(LLM)的成功,已经证明了Scaling Law(规模法则)的有效性——即模型参数量、数据量和计算量的持续增加, 在一定范围内持续地带来模型能力的提升 。这引发了一场全球性的军备竞赛。未来几年,AI领域的竞争,将从算法模型的竞争,进一步升级 为算力基础 设施的竞争。国家、科技巨头将投入巨资建设更大规模 的智算中心 。这不仅意味着对GPU、ASIC等现有硬件的需求 将持续爆发,更会推动高速光模块、液冷散热、CXL互联等配套技术的加速发展。一个以“万卡集群” 为标配的 时代正在到来。
趋势二:硬件定义AI(Hardware-Defined AI)
过去是算法定义硬件,即先有算法,再设计硬件去适配。未来,这种关系可能会发生逆转,进入 “硬件定义AI”的阶段。随着神经形态计算、 存算一体 等新架构的成熟,它们独特的计算特性将催生出全新的算法和模型。例如,基于脉冲神经网络(SNN)的算法,在能效和处理时序数据上可能远超现有的深度神经网络,从而在机器人、 脑机接口 等领域开辟新的应用。硬件的创新将不再仅仅是“加速器”,而会成为AI范式创新的“策源地”。
趋势三:AI的“去中心化”与个性化
随着边缘AI芯片能力的增强和成本的降低,强大的AI能力将不再是少数云端巨头的专利。未来, AI将经历一个类似PC和移动互联网的“去中心化”过程。个人设备(手机、PC、汽车)将拥有足够强大的本地算力,能够运行专为个人数据和偏好微调过的个性化模型。这意味着你的AI助手将真正“属于你”,它了解你的习惯、记忆你的经历,并且所有数据都保留在本地,最大限度地保护了隐私。这将催生一个全新的个性化AI应用生态。
想象:未来的AI+产品形态
基于以上趋势,我们可以对未来的AI产品形态进行一些大胆的想象:
- 环境智能(Ambient Intelligence):正如开篇的场景所述,未来的AI将不再局限于某个设备,而是像水和电一样,无缝融入我们生活的环境。通过分布在家 居、办公室、城市中的无数个微型、低功耗的传感器和计算节点,环境本身将成为一个能够感知、理解并主动服务于我们需求。
- 具身智能 (Embodied AI):AI将拥有“身体”,以机器人的形态进入物理世界,执行复杂的任务。这需要硬件具备高效的实时感知、决策和控制能力,以及对物理世界常识的深刻理解。人形机器人可能会成为家庭保姆、工厂工人,甚至是太空探索的先锋。
- 数字 孪生与 科学发现(AI for Science):借助超级算力,我们可以为复杂的物理系统(如气候、人体、新材料)构建高精度的数字孪生模型。AI可以在这些虚拟世界中进行海量的模拟和实验,其速度远超物理实验。这将彻底改变科学研究的范式,加速新药研发、材料设计和能源技术的突破,成为人类认识和改造世界的“第二套工具”。
05 探索本质: 算力是 新时代的“创世”基石
从笨拙的CPU到聪明的GPU,再到专注的ASIC和充满想象力的未来架构,AI硬件的发展史,本质上是人类将智能从碳基生命(生物大脑)向硅基载体(芯片)迁移的宏大工程。这条道路的核心,是对“计算”这一概念的不断深化和重塑。
我们正处在一个关键的转折点。过去,硬件的发展更多是“量”的积累,遵循着摩尔定律的节奏稳步前行。而现在,我们面临的是“质”的突变。冯·诺依曼架构的桎梏、功耗墙的限制,以及对通用人工智能(AGI)的渴望,正迫使我们从根本上重新思考计算的本质。 存算一体 、神经形态等新范式,不仅仅是技术的改良,更是对计算哲学的颠覆——它们试图让机器像大脑一样思考,在信息的存储和处理之间建立更深层次的融合。
最终,硬件的演进将决定AI能达到的终极高度。它不再仅仅是冰冷的芯片和电路,而是承载我们智慧延伸、拓展我们感知边界的新器官。从云端赋能百业,到边缘融入生活,再到未来与我们共生的环境智能,硬件的每一次脉动,都在塑造着人类文明的下一个形态。
正如宇宙大爆炸需要一个奇点,数字世界的智能大爆炸,其奇点就是算力。算力是 这个时代的创世基石,它将数据和算法这些无形的思想,转化为改变物理世界的有形力量。我们今天对芯片的每一次打磨,对架构的每一次创新,都是在为构建一个更智能、更普惠的未来,奠定最坚实的一块砖。
本文由 @KK的慢变量 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


