
 起点课堂会员权益
起点课堂会员权益花了三个月,终于搞懂AI凭什么比我画得快
AI生图技术正在颠覆传统创作领域,Midjourney、Stable Diffusion等工具的崛起让无数创作者感到震撼与困惑。本文深入浅出地拆解了扩散模型的核心训练逻辑,从数据标注到反向传播,用老中医教学徒的生动比喻,带你理解AI如何真正"学会"绘画。同时对比语言模型与图像模型的训练差异,并揭秘为何Midjourney的审美能碾压同行。

一、每次被问到这个问题,我真想翻个白眼
“AI对你们冲击挺大吧?”
我已经不记得这句话被问过多少次了。朋友聚餐问,亲戚拜年问,连我楼下的便利店老板知道我是画画的之后,也若有所思地问了我一句。我每次都忍住了没翻白眼——不是因为我涵养好,是因为我也不知道该怎么回答。
这两年,”AI生图”这件事真的把所有人都搅动了。外行开始蠢蠢欲动,觉得只要会打几个关键词,就能靠AI生图赚外快;设计群里隔三差五有人发”设计要被取代了”的文章;就连一些做了十几年的老插画师,也开始在朋友圈发出灵魂拷问。说实话,我也被震撼过。第一次看到Midjourney生成的某张图的时候,我盯着屏幕看了很久,心里有点说不清楚的感觉——不完全是焦虑,更像是好奇。这东西是怎么做到的?它是怎么”学会”画画的?
我去查,迎面撞上了一堵专业名词的墙:扩散模型、潜在空间、U-Net、CLIP文本编码器、反向传播、梯度下降……每一个词单独看都像在说人话,组合在一起就是天书。我当时的感受是:好的,我不配。但后来,我真的把这些东西一点一点搞懂了,然后发现它其实没有那么神秘——只是没有人用人话把它讲清楚而已。所以这篇文章,就是我来当那个”翻译”的。
二、图像模型是怎么被”训练”出来的
先给你一张地图:图像AI走过的三个时代
在讲具体的训练过程之前,我想先给你一张地图,让你知道我们现在站在哪里。图像AI的发展并不是一蹴而就的,它走过了三个截然不同的时代,每个时代解决一个核心问题,使用一种主流训练技术。
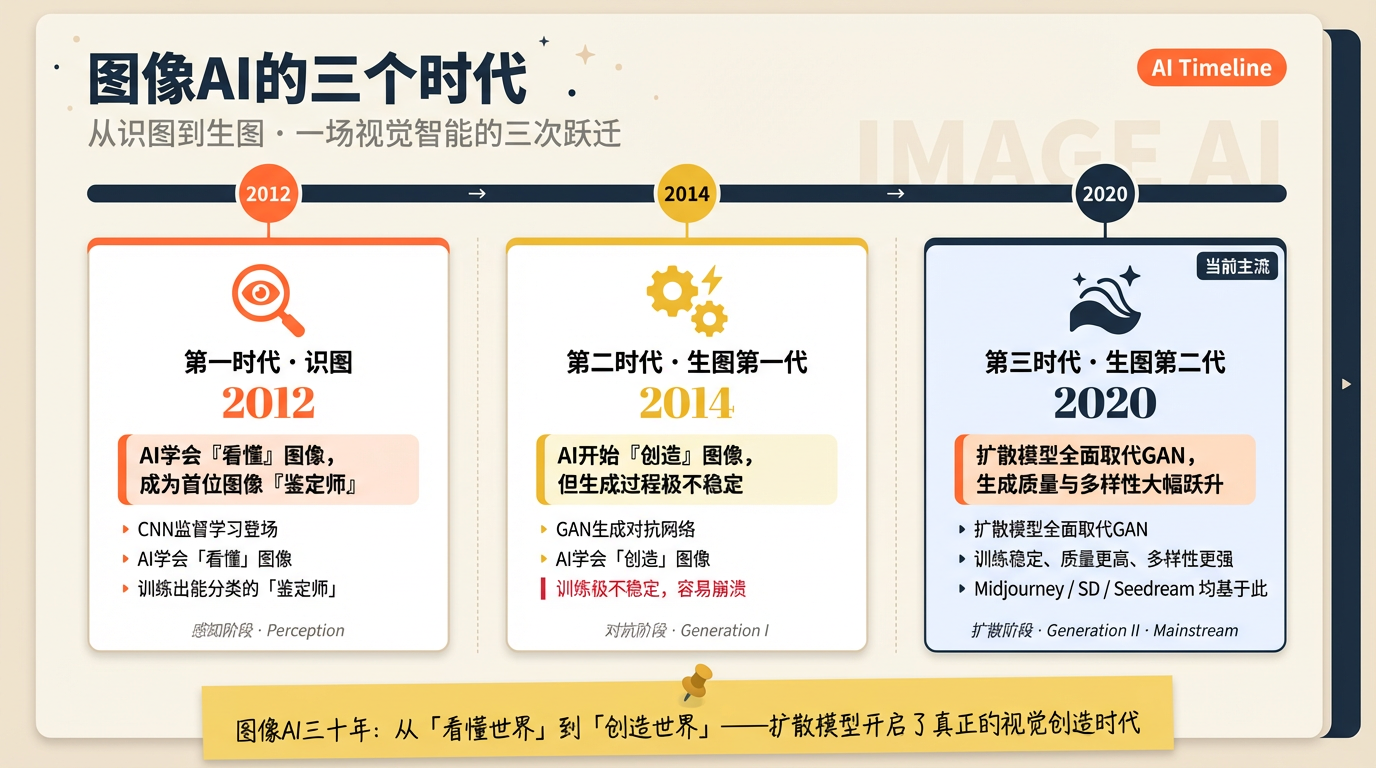
第一个时代(2012年起):让AI学会“看懂”图。 这个阶段的核心技术叫CNN监督学习,训练出来的模型是个”鉴定师”——能认出这张图是猫还是狗,是人参还是当归,但完全不会创作任何东西。这是图像AI最基础的能力,也是后续一切的起点。
第二个时代(2014年起):让AI学会“创造”图。 这个阶段的技术叫GAN(生成对抗网络),原理是让一个”造假者”和一个”鉴别者”互相博弈,最终造假者学会以假乱真。GAN在2018到2019年达到鼎盛,生成的人脸逼真到让人头皮发麻。但它有一个致命缺陷:训练极不稳定,两个模型稍微失去平衡,整个训练就崩溃了——就像两个人吵架,一旦一方太强势,另一方直接躺平,什么也学不了。
第三个时代(2020年起,当前主流):扩散模型全面取代GAN。 扩散模型的训练更稳定、生成质量更高、多样性更强,也更容易被文字引导。你现在听到的Midjourney、Stable Diffusion、Seedream,全部基于扩散模型训练。这就是今天要重点拆解的技术。好,地图有了,我们进城。
所有图像模型训练的通用骨架——外星人学徒的养成故事
不管是哪个时代的图像模型,它们的训练都遵循同一套底层骨架,一共八个步骤。为了让你真的听懂,我打算用一个比喻贯穿始终:一位经验丰富的老中医(研究人员),带着一个记忆力极好、但完全没有地球常识的外星人学徒(图像模型),学习辨认中草药——比如人参和当归。这个外星人学徒脑子里没有”植物”的概念,没有”颜色”的概念,没有任何常识,只能靠形状、颜色、纹理等特征死记和总结规律。
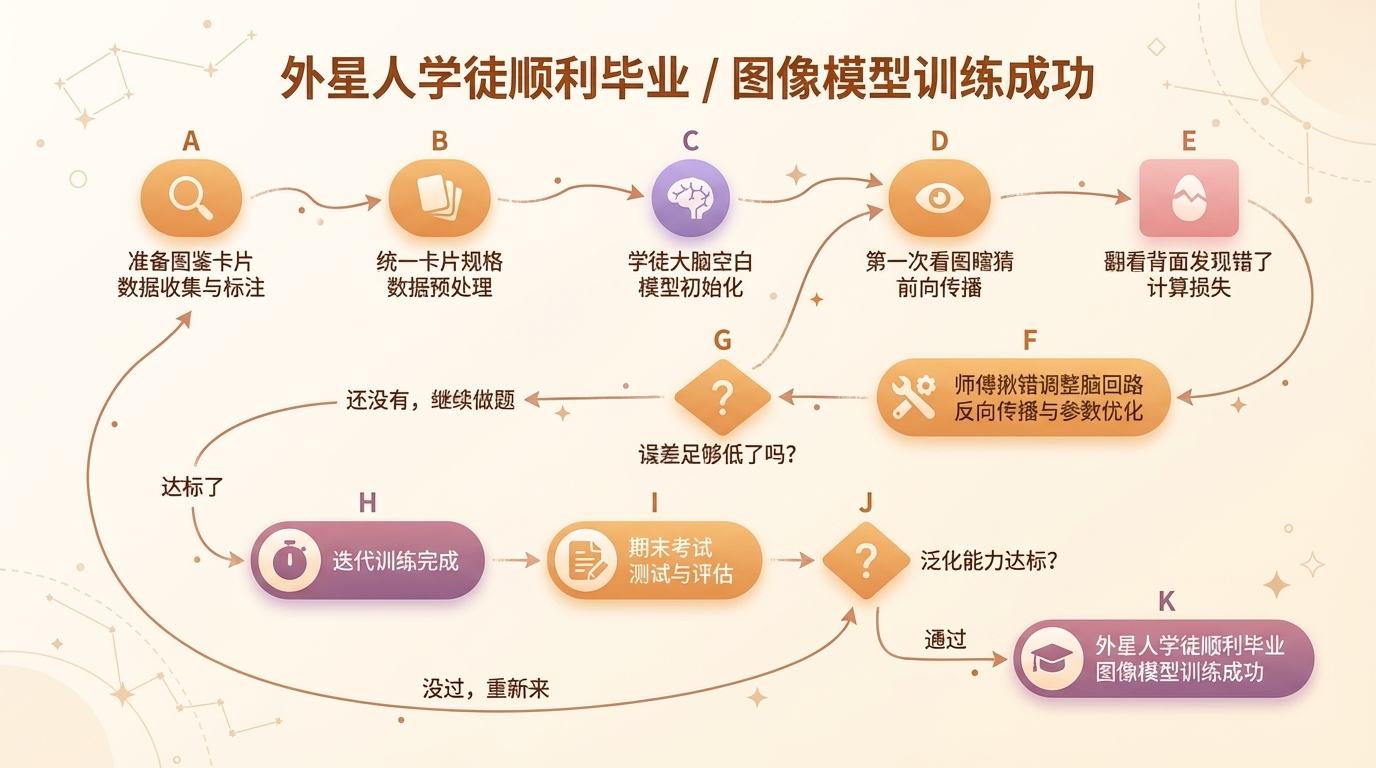
第一步:准备图鉴卡片——数据收集与标注
模型本身没有任何常识,它需要通过海量的数据来学习。老中医跑遍大江南北,拍了十万张人参和当归的照片,在每张照片的背面都写上正确的名字:”这是人参”、”这是当归”。这就是给数据打标签。听起来很简单,但这一步的重要性怎么强调都不为过——数据的数量和质量,在第一步就决定了模型日后能力的上限。你喂给它什么,它就能学会什么。后面我们讲三个顶级模型的时候,会发现它们之间最大的差异,恰恰就藏在这一步。
第二步:统一卡片规格——数据预处理
老中医收集来的照片有大有小,有的在白天拍的,有的在晚上拍的,有的角度奇怪。他把所有照片裁剪成一样大的正方形卡片,统一明暗。然后他做了一件有意思的事:故意把一些照片倒过来放,还故意在某些照片上加了一点模糊和噪点。他告诉学徒:”不管这药材是正着放还是倒着放,不管光线好不好,你都得认出来。”这叫数据增强,目的是让模型适应各种复杂的现实情况,不要死记硬背某一张特定的照片。
第三步:学徒大脑一片空白——模型初始化
外星人学徒第一天上班,脑子里全是乱码。技术上说,这一步是构建一个由许多层”人工神经元”组成的数学网络,网络里所有的参数(权重和偏置)都是随机生成的。此时的模型就像一张白纸——如果你这时候拿一棵人参给他看,他可能会觉得这是一根胡萝卜,或者一块石头,他的判断是完全随机的,毫无规律可言。
第四步:第一次看图瞎猜——前向传播
老中医拿出一张照片给学徒看,不给他看背面的答案。学徒盯着照片上的纹理、颜色、根须看了一会儿,模型开始像流水线一样,一层一层地提取图片的信息:第一层可能只看到边缘和线条,中间层能看出局部轮廓,到了最后一层,把这些特征拼凑起来,给出一个预测结果。学徒凭着自己混乱的直觉瞎猜:”师傅,我觉得这有80%的可能是当归。”
第五步:翻看背面,发现错了——计算损失
老中医把照片翻过来,背面赫然写着”人参”。老中医拿出一个小本本记下:”你这次猜错了,而且错得很离谱,误差值很大!”技术上,这个”小本本”就是损失函数——一个数学公式,专门用来计算模型预测错了多少。误差越大,损失值就越高。这个损失值,是驱动模型改进的核心信号,没有它,模型就不知道自己哪里出了问题,也就无从改进。
第六步:师傅揪错,学徒调整脑回路——反向传播与参数优化
这是整个训练过程中最关键的一步,也是模型真正”学习”的核心所在。老中医开始复盘:”你为什么会猜错?因为你只看了它的颜色偏黄,却没注意它的根须像人的手脚。下次看图,你要把’根须形状’的注意力调高一点,把’颜色’的注意力调低一点。”外星人学徒听完,立刻在自己的脑子里拨动了几万个小开关,改变了自己判断事物的权重标准。这几万个小开关,就是模型的参数。通过一种叫”反向传播”的数学算法,系统从后往前追溯,找出是哪些参数导致了这次判断失误,然后用优化器(梯度下降算法)对这些参数进行极其微小的调整。每一次调整都微乎其微,但方向是对的,目标只有一个:如果下次再看到这张图,误差能稍微小一点。
第七步:没日没夜地做题——迭代训练
一张图片调整一次参数是远远不够的。接下来的一整个月,老中医每天让学徒看这十万张照片,循环往复:看图 → 瞎猜 → 翻背面看答案 → 发现错误 → 调整脑子里的小开关。这个循环要重复成百上千次,每一次完整的循环叫做一个 Epoch。学徒看了几百遍这十万张图,脑子里的小开关被调整到了最完美的角度,慢慢地他不再需要死记硬背某一张照片,而是真正总结出了”人参长什么样、当归长什么样”的本质规律。顺带说一个数字,让你感受一下规模:真实的AI训练里,这个”几百遍”对应的是几亿次参数调整,消耗的算力相当于一台普通家用电脑不间断运行几千年。
第八步:最终的期末考试——测试与评估
学徒出师前,老中医从深山里挖了一棵以前从来没拍过照片的新人参,放在学徒面前:”我不给你看答案,你告诉我这是什么?”学徒端详了一下它的根须和纹理,自信地说:”师傅,虽然我没见过这棵具体的植物,但根据我脑子里调整好的规律,这绝对是人参!”老中医满意地点点头。如果模型不仅能认出训练时见过的图片,还能准确认出这些全新的图片,说明它真正掌握了图像的内在规律——学术上叫具备了良好的”泛化能力”,至此,一个图像模型才算真正训练成功。
现在的生图模型用的是什么训练技术——扩散模型的训练逻辑
上面八个步骤,是所有图像模型训练的通用骨架。但我们今天的主角——Midjourney、Stable Diffusion这类生图模型——用的是扩散模型,它在这套骨架上,出了一道完全不同的”题目”。如果说CNN训练出来的是**”鉴定师”(能认出图是什么),那扩散模型训练出来的是“修复师”——能把一张被破坏的图还原回去。
它的训练题目是这样的:取一张好图,往上面一步步叠加随机噪点,分成几十步,直到它变成一片完全看不出原图的雪花屏。然后让模型学会:猜出每一步加进去的噪声是什么样的。猜得越准,意味着模型对图像结构的理解越深——它知道什么样的像素排列是”有意义的”,因此才能识别出什么是”干扰项”。训练完成之后,这个能力被反向使用:从一片纯噪声出发,一步步减掉噪声,就能”还原”出一张有意义的图。
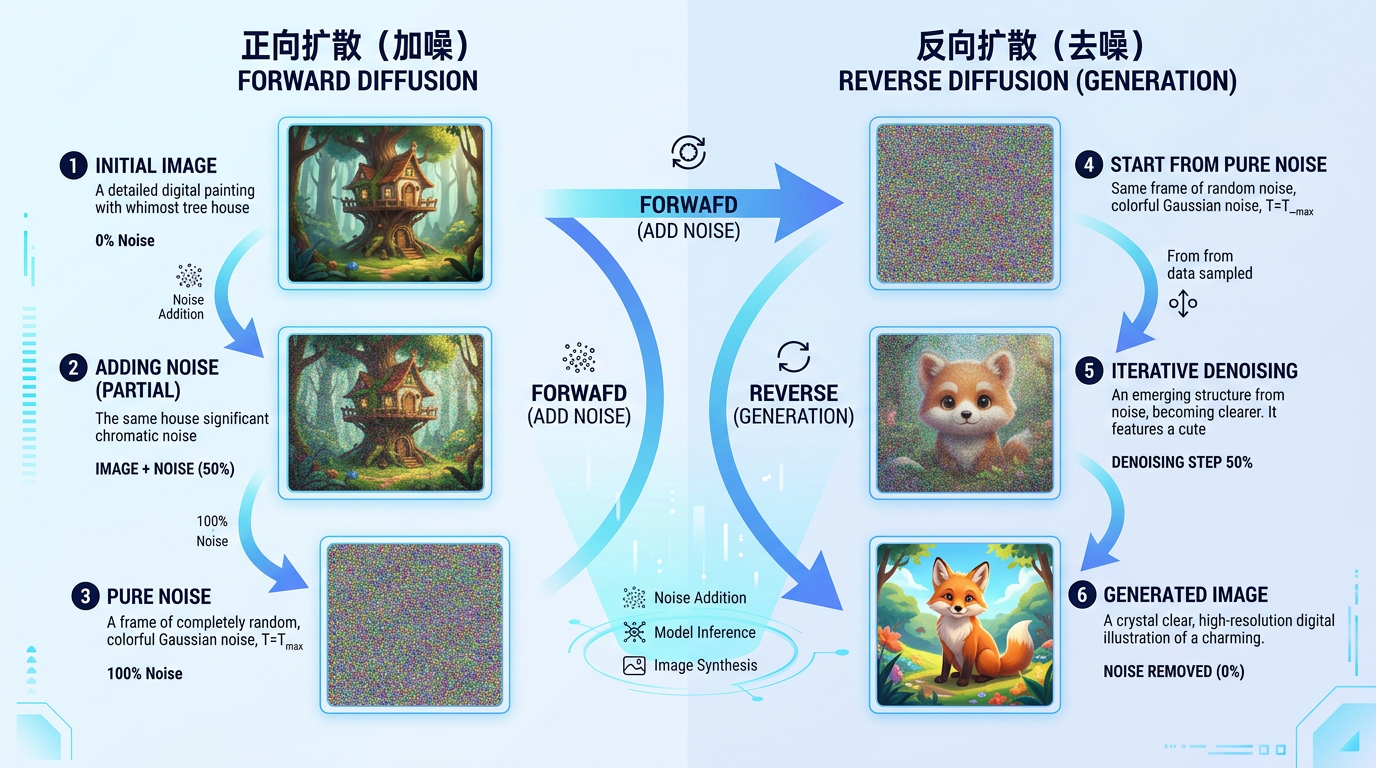
但这里有两个关键问题需要解决。第一个问题:直接在像素上训练,太慢了。 一张512×512的图有将近80万个像素点,直接在像素层面做加噪和识噪训练,计算量极其庞大。解决方案叫潜在空间(Latent Space):先用一个编码器把图像”压缩”成一个小得多的信息包,在这个压缩版本上做训练,完成后再解压回真实图像。就像设计师改稿,不需要每次都打印出A0幅面的全尺寸图纸,在一张缩略草图上标注修改意见就够了,效率提升几十倍,最后再交给输出中心放大还原。这个创新让AI生图的训练成本大幅下降,也让普通消费级设备能够运行生图模型成为可能。
第二个问题:纯扩散模型无法被文字控制。 纯扩散模型训练完之后,能生成图,但你没法控制它生成什么——它可能生成一座金字塔,也可能生成一只猫,完全随机。解决方案是引入CLIP——一个同时学习图像和对应文字描述的模型。CLIP的训练方式是:把四亿张图片和它们的文字说明配对,反复学习,直到它能判断”这段文字”和”这张图”在语义上是否匹配。训练完成后,CLIP就能把任何一段文字翻译成一个”语义方向”,在扩散模型训练中作为条件信号注入,告诉模型:你识噪的方向,要朝着这段文字描述的视觉内容靠拢。这就是为什么你输入”一只戴帽子的猫”,生成的图真的是一只戴帽子的猫。
二、同是”学习”,语言模型和图像模型的训练有什么不一样
搞懂了图像模型的训练之后,很多人会有一个疑问:ChatGPT这类语言大模型,和Midjourney这类图像模型,看起来都是AI,它们的训练到底有什么不一样?
语言模型的训练:一场永无止境的”完形填空”
语言模型的训练,同样遵循那套”看题→猜答案→对答案→调参数→再来”的骨架,但它的训练素材是海量文字,训练目标叫自回归预测——给定前面所有的词,预测下一个最可能出现的词。用老中医的框架来说,这位老中医教的不是认药材,而是教学徒背古籍。老中医给学徒看一句话的前半段:”春眠不觉晓,处处——”,然后问:”下一个字是什么?”学徒猜,老中医翻书对答案,学徒调整小开关,然后下一句,再猜,再调整。整个训练,就是做了几千亿道这样的完形填空题,做到足够多之后,模型就真的理解了语言的逻辑——什么词后面通常跟什么词,什么语境下应该用什么表达。
图像模型的训练:同一套骨架,不同的”题目”
图像模型(扩散模型)的训练目标是噪声预测,操作对象从”文字序列”变成了”图像的像素结构”。
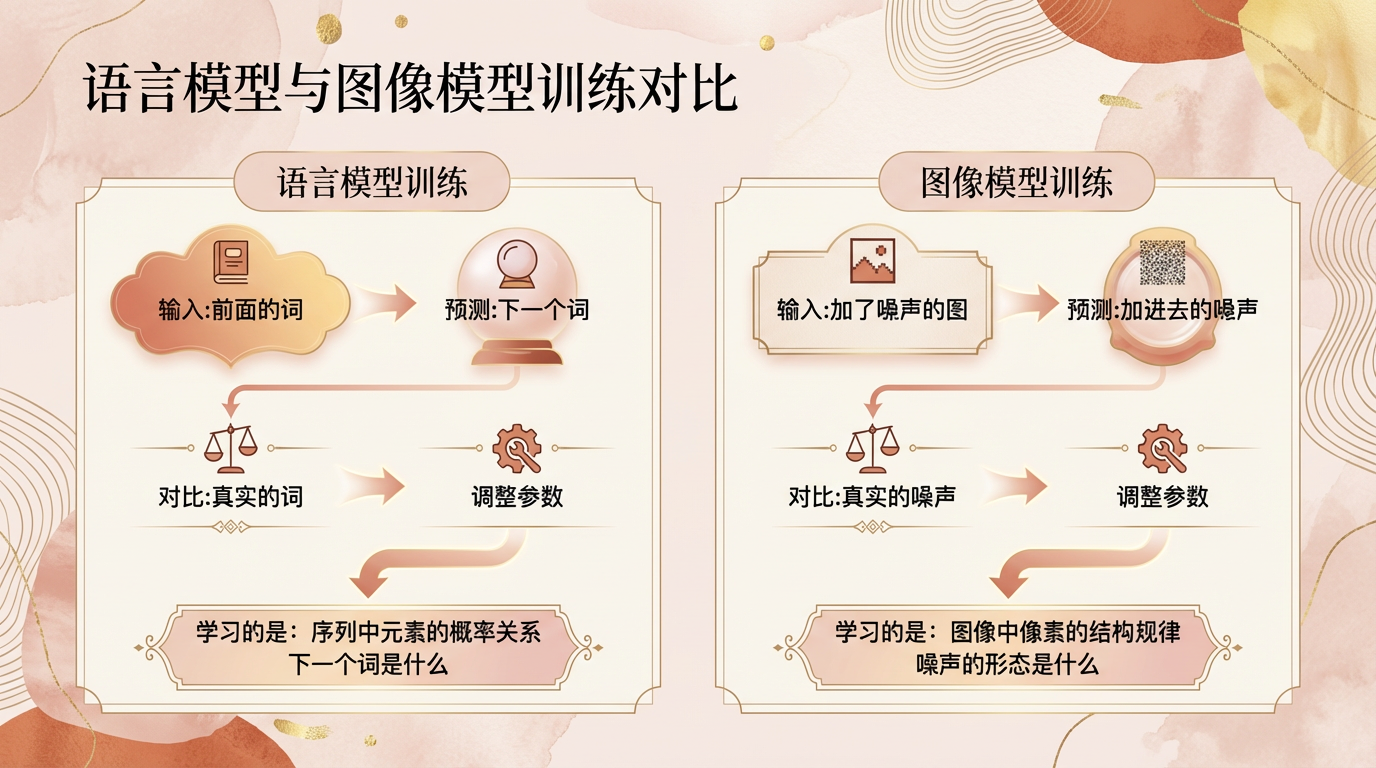
两者最本质的差异在于:语言模型学的是序列中元素的概率关系,图像模型学的是图像中像素的结构规律,一个是顺序预测,一个是结构识别,训练逻辑从根上就不同。用两个学徒来对比:一个每天做完形填空,学会了语言;另一个每天练习”把被划花的画还原回去”,学会了图像。他们用的是同一套”题目→答案→纠错”的学习框架,但练习的内容完全不同,最终掌握的能力也完全不同。
为什么图像模型近年来突飞猛进:它站在了语言模型的肩膀上
图像模型质量近年飞速提升,有一个容易被忽略的原因:它借用了语言模型领域已经验证过的Transformer架构。早期图像模型用CNN处理图像,近年来越来越多的图像模型引入了Transformer的注意力机制,让模型能更好地理解图像不同区域之间的关系,以及图像与文字描述之间的关系。语言模型花了好几年验证的架构,图像模型直接拿来用,省去了大量重复探索的成本。一句话说清楚:同一套工具,既可以用来学语文,也可以用来学画画。
三、同样是扩散模型训练出来的,为什么它们这么厉害
现在你已经知道了扩散模型训练的基本逻辑。但问题来了:Midjourney、Nano Banana、Seedream,都基于扩散模型(或类似框架)训练,为什么它们的表现差异这么大?就像同样是用那八个步骤训练出来的学徒,老中医给他们准备的图鉴卡片不同、出的题目侧重点不同,最终他们各自擅长的东西也截然不同。
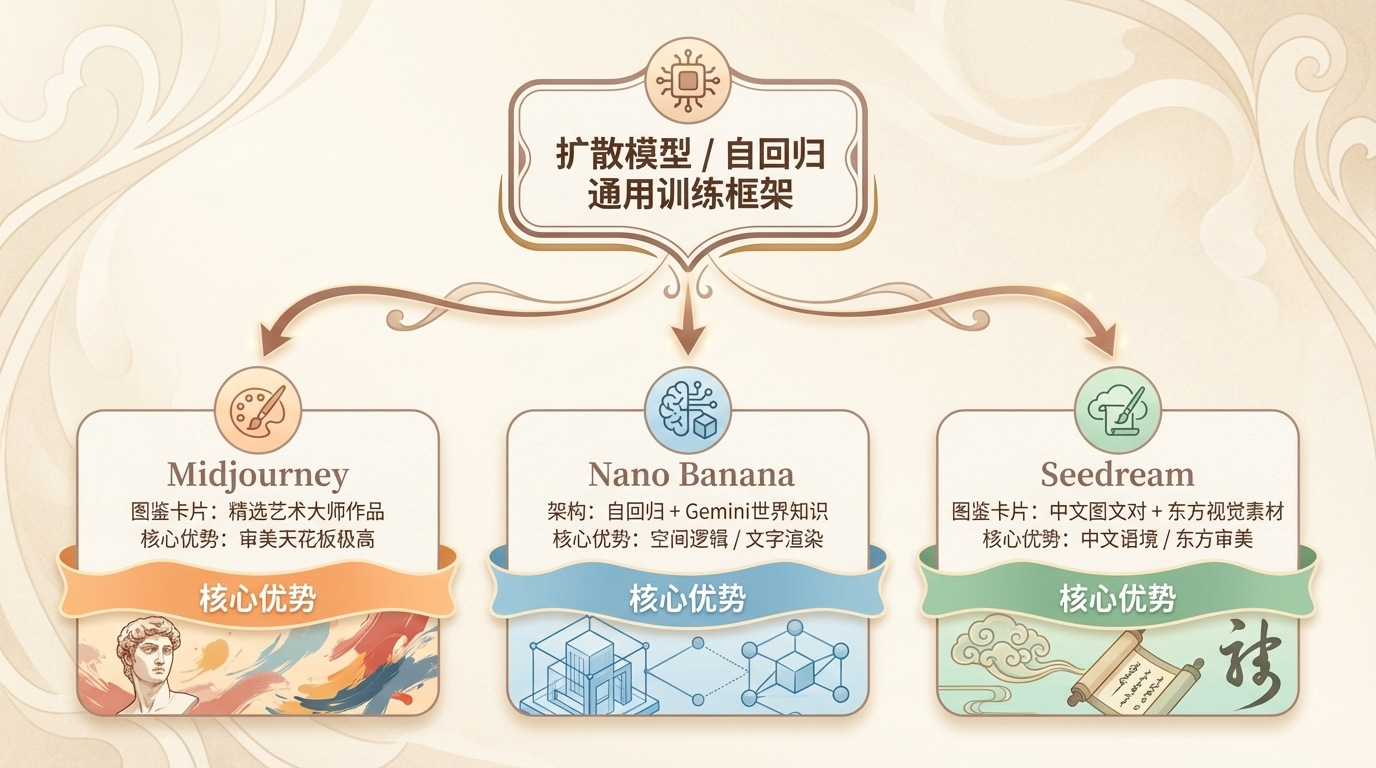
Midjourney:当你只把”大师作品”当图鉴卡片
Midjourney的审美水准至今是行业标杆,生成的图有一种说不清楚的”高级感”,哪怕你随便打几个词进去,出来的东西都不会太难看。核心原因在于训练数据的极度精选——Midjourney没有像其他模型那样用互联网上抓取的海量普通图片来训练,它大量投喂的是经过人工筛选的高质量艺术作品、插画精品、优秀摄影。也就是说,它的图鉴卡片,全是国家级标本馆里最完美的标本照片。
作为一个画画的人,我觉得这个逻辑特别好理解。一个画家从小只临摹大师原作,和一个从小只看路边广告长大的人,最终画出来的东西有本质差异——不是因为谁更努力,而是因为他们的眼睛被”喂”了完全不同的东西。Midjourney做的,就是只给模型喂大师作品,让它从一开始就在最高的审美标准里建立自己对”好图”的理解。训练数据的”品味”在第一步就决定了模型的审美天花板,垃圾进垃圾出,精品进精品出,这在图像模型训练里是铁律。
Nano Banana:当图像模型拥有了”世界知识”
Nano Banana(谷歌Gemini图像模型的代号)是三个模型里最特别的一个,因为它走了一条和Midjourney、Stable Diffusion完全不同的技术路径。其他的生图模型用的是扩散模型——它们在训练时学的是”图像的视觉规律”,像素和像素之间的关系,颜色和颜色之间的关系。但Nano Banana用的是自回归架构,它生成图像的方式,和语言大模型写文章一样,一个”视觉词块”一个”视觉词块”地”写”出图像,每一步都在用它对世界的理解来做决策。
而它的底层,是Gemini语言大模型。这意味着它在训练时,把Gemini已经积累的”世界知识”——物理规律、空间逻辑、因果关系、现实常识——全部带进了图像生成里。这带来了一些纯扩散模型做不到的事:你让它”从俯视角度看这栋建筑”,它能真正推理出俯视角应该是什么样子,而不是靠猜;你让它保持同一个角色在不同场景里出现,它能理解”这是同一个人”,而不是随机生成两张相似的脸;你让它在图里渲染文字,它知道字母应该怎么拼、怎么排,不会出现那种奇怪的乱码字。这些都是”世界知识”在图像生成里的具体体现。用老中医的比喻来说:纯扩散模型的学徒,学的是”图鉴卡片上的视觉规律”;Nano Banana的学徒,除了学图鉴卡片,还读了一整个图书馆的百科全书——前者是视觉专才,后者是带着世界观的通才。
Seedream:用”中文图鉴”训练出来的模型
如果说Midjourney赢在数据品味,Nano Banana赢在世界知识,那Seedream赢在的是语言的母语优势。Seedream在中文语境和东方审美上的表现,是目前所有图像模型里最好的。你输入”水墨风格的山水”,它生成的东西和西方训练的模型生成的东西,差异是肉眼可见的——不是说谁好谁坏,而是它真的”懂”你在说什么,那种感觉就像你用母语和人聊天,跟你用翻译软件和人聊天,完全不是一回事。
背后的原因是训练数据的本土化策略:大量中文图文对、东方视觉风格素材的专项投喂,以及CLIP文本编码器针对中文语义的专项优化。回到老中医比喻:如果老中医准备的十万张图鉴卡片,全是中国各地的药材标本,背面的标注也全是中文描述,那这个学徒对”东方草药”的理解,天然就比一个靠翻译西方植物学教材学出来的学徒更深、更准。一个从小说中文、看中国画、吃中国菜长大的人,对”东方美”的理解,和一个靠翻译才能接触中文的人,有本质差异。Seedream就是用”中文母语数据”作为图鉴卡片训练出来的,所以它在理解”汉服”、”水墨”、”街头烟火气”这类概念时,不需要翻译,直接就懂。
四、搞懂了训练过程,然后呢
当然,搞懂了原理,不代表我的稿费涨了。这是大实话。
但当你真正弄懂一件事的运作逻辑之后,那个黑盒子就不再让你觉得神秘了。时代往前走,拦不住,也没必要拦。画笔还在,热爱还在。偶尔用AI出个草图,偶尔被它生成的某张图震撼一下然后去研究它怎么做到的——挺好的。画画这件事不会因为AI会生图就没了意义,摄影出现了绘画没消失,电影出现了话剧没消亡,每次技术浪潮都会让留下来的东西变得更清晰。
然后,我还挺期待未来的。不是套话式的期待,是真的很好奇那个电影里的科幻世界什么时候到来——悬浮的城市,随手一挥就能生成任何视觉内容的工具。那个世界里画画是什么感觉,我不知道。但作为一个画画的人,我挺想活到那时候去看一眼的。先把眼前的图画好,慢慢等着看。
这篇是这个系列的第一篇,后面还会继续把更多AI的底层逻辑翻译成人话。如果你也曾被那堵专业名词的墙挡在门外,欢迎一起往里走。
本文由 @AI宇宙NPC小文 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


