
 起点课堂会员权益
起点课堂会员权益砍掉75%的Token,性能几乎不变——视觉AI的_断舍离_哲学
多模态AI处理图像和视频时为何总是卡顿?V²Drop技术突破揭示了一个关键真相:视觉Token的爆炸式增长是根本瓶颈。这项来自中国顶尖实验室的创新方案,能在砍掉75%冗余Token的同时保持97%性能,彻底解决了与FlashAttention的兼容难题,为工业质检、自动驾驶等实时场景带来革命性提速。

把一段5分钟的会议录像丢给AI,它卡了将近10秒才开始回答。让GPT-4o分析一张高清产品图,响应时间是处理同等长度文字的好几倍。这种体验,相信用过多模态AI工具的人都不陌生。
很多人以为这是网络问题,或者服务器太忙。但实际上,背后有一个更根本的技术瓶颈——视觉Token数量的爆炸式增长。
所谓Token,是大模型处理信息的最小单元。文字被切成一个个词片,图像则被切成一个个小块,每一块就是一个视觉Token。问题在于,当你输入一张高分辨率图片时,它可能会产生数千个Token;而一段长视频,更可能膨胀到数万个。由于Transformer架构的注意力计算复杂度与序列长度近似呈平方关系,Token数量翻倍,计算量可能翻四倍。这就是为什么多模态大模型在处理图像和视频时,会显著慢于纯文本任务。
这个问题随着AI能力的提升正在急剧恶化。GPT-4o、Qwen2-VL、LLaVA等模型越来越擅长理解高分辨率图像和长视频,但”越能看”的代价,是”越难跑”。对于需要实时响应的应用场景——比如工业质检、自动驾驶感知、实时视频分析——这个瓶颈已经从学术问题变成了真实的工程痛点。
就在今天(2026年3月15日),来自四川大学、上海交通大学EPIC Lab和浙江大学的研究团队,在CVPR 2026上正式发布了他们的解法:V²Drop。这是一个能在几乎不损失性能的前提下,把视觉Token砍掉75%、让推理速度提升最高1.87倍的新方法。
而他们找到这个解法的路径,和所有人的直觉都不一样。
Token压缩赛道:两年200篇论文,一个共同的”坏习惯”
面对视觉Token膨胀的问题,学术界的反应非常迅速。一个名为”Token压缩”的研究方向在过去两年内迅速爆发,仅相关论文就涌现出约200篇,FastV、SparseVLM、PDrop、DART等方法相继出现。
Token压缩的核心逻辑其实很直觉:图像里有大量冗余信息。一张街景照片,路面、天空、远处模糊的建筑——这些区域对于”识别路牌上写的什么”这个任务来说,几乎毫无价值。如果能在推理过程中把这些”废Token”提前丢掉,只保留真正关键的部分,计算量自然大幅下降。
问题在于:怎么判断哪些Token是”废的”?
主流方案给出的答案是:看注意力权重(Attention Score)。注意力权重是Transformer模型在计算时自然产生的一个中间量,直觉上,模型”关注”某个Token的程度越高,那个Token就越重要。这个逻辑听起来无懈可击,整个赛道几乎都在沿着这条路走。
然而,V²Drop的研究团队在深入分析后发现,这条路上暗藏着两个几乎被所有人忽视的致命缺陷。
注意力方法的两大”暗伤”
暗伤一:它根本不看内容,只看位置
研究团队在LLaVA-1.5-7B和Qwen2-VL-7B两个主流模型上,做了一个看似简单却极具揭示性的实验:统计SparseVLM和FastV这两种注意力方法,在相同输入下,到底倾向于保留序列中哪些位置的Token。
结果让人瞠目结舌。
两种方法的Token保留概率曲线,都呈现出一种单调递增的阶梯形状——序列末尾(对应图像底部区域)的Token保留率高达80%到100%,而序列前端(对应图像顶部区域)的保留率仅有10%到30%。这个分布与图像内容毫无关联。无论你输入的是一张人脸特写、一张文档截图还是一段体育赛事视频,注意力方法都会机械地倾向于保留图像下半部分的Token。
这就是所谓的”位置偏差(Positional Bias)”——一种系统性的、与内容无关的偏见。它导致的直接后果是:如果关键信息恰好在图像上方(比如标题、Logo、人物面部),这些Token极有可能被错误地丢弃,进而引发多模态幻觉,让模型”看图说瞎话”。

暗伤二:它和最重要的加速工具天然冲突
第二个缺陷更加致命,因为它是架构层面的根本性矛盾。
FlashAttention是当前大模型推理加速的标配算子,几乎所有主流推理框架都在使用它。它的核心思想是通过分块计算,避免将完整的注意力矩阵写入显存,从而大幅降低内存访问开销、提升计算效率。
但问题在于:注意力方法的Token压缩,恰恰需要读取这个完整的注意力矩阵来判断Token重要性。而FlashAttention的设计原则,正是不输出这个中间矩阵。
两者的冲突是根本性的:你要么用FlashAttention加速推理,要么用注意力权重剪枝Token,鱼和熊掌,不可兼得。这意味着,现有的大多数Token压缩方法,在工程落地时都面临一个尴尬的选择:要么放弃FlashAttention的加速收益,要么放弃Token压缩的效率提升。两个本应叠加的优化手段,反而互相抵消。
这正是为什么,尽管Token压缩论文发了两百篇,真正被主流LVLM广泛采用的方案却寥寥无几。

一个反直觉的洞见:变化才是价值
V²Drop的研究团队没有继续在注意力权重上做文章,而是换了一个完全不同的视角:如果不看模型”关注”什么,而是看Token自身在模型各层之间”变化”了多少,会怎样?
这个想法背后有一个朴素的直觉:如果一个视觉Token在经过LLM的每一层处理后,其表示几乎没有变化,那说明这个Token对模型的理解过程没有产生什么影响——它是一个”惰性Token”,丢掉它对最终结果影响微乎其微。反过来,那些在各层之间变化剧烈的Token,才是真正携带了关键语义信息、正在被模型深度加工的部分。
为了验证这个直觉,研究团队设计了两个典型实验样本:
实验一:百事可乐瓶识别。 当任务是识别图中瓶子上的品牌Logo时,L2 Norm变化量指标在瓶身Logo所在区域出现了显著峰值,而背景区域的变化量则相对平坦。
实验二:球衣号码识别。 当任务是读取运动员球衣上的号码时,变化量热图精准地在数字所在区域形成高亮,无论这个区域位于图像的哪个位置,都能被准确捕捉——完全没有位置偏差。
更重要的是,研究团队测试了L1 Norm、L2 Norm、余弦相似度三种不同的变化量度量方式,发现三者都能精准定位语义关键区域,只是L2 Norm的综合性能最优,因此被选为V²Drop的默认度量。
这个发现还有一个更深刻的含义:变化量是一种”任务无关(task-agnostic)”的内在属性。不管你问的是”图里有几个人”还是”背景里写的什么字”,重要的视觉区域,其Token变化量就是更大。这意味着V²Drop不需要根据具体任务调整策略,一套方案可以通吃所有场景。
研究团队还通过一阶Taylor展开从数学上证明了这一点:Token的变化量幅度与其对模型输出的影响正相关,丢弃低变化量Token能够最小化输出扰动。Transformer架构中的残差连接、Layer Norm和平滑激活函数三大属性,共同为这一理论假设提供了严格保证。
V²Drop是怎么工作的:三步”断舍离”
理解了核心洞见之后,V²Drop的实现逻辑其实相当简洁优雅。整个流程可以用”三步断舍离”来概括:
第一步:给每个Token打”活跃度分数”。 在每个预定义的剪枝层,V²Drop计算每个视觉Token当前表示与上一层表示之间的L2距离,将这个距离作为该Token的重要性得分。变化越大,得分越高。这个计算的额外开销仅为单层注意力计算量的0.022%,几乎可以忽略不计。
第二步:按活跃度排名,保留Top-K。 将所有视觉Token按变化量得分从高到低排序,保留最”活跃”的前K个,直接丢弃那些”一动不动”的惰性Token。整个过程完全不依赖注意力矩阵,因此与FlashAttention天然兼容。
第三步:分三阶段渐进式压缩。 这是V²Drop最精妙的设计之一。它不是一次性把Token砍到位,而是在LLM的浅层、中层、深层三个阶段依次执行剪枝,形成M→Ka→Kb→Kc的渐进压缩路径,每一阶段保留的Token数量逐步减少。
为什么不一次性全砍?消融实验给出了清晰的答案:渐进式剪枝比一次性剪枝在POPE幻觉评估指标上高出9.3%,在MME综合评测上高出5.9%。原因在于,模型在浅层处理的是低层次的纹理和细节信息,在深层处理的是高层次的语义概念,不同层次对Token数量的敏感程度不同,渐进式策略能更好地适应这种层次性差异。
成绩单:数据才是最有力的论据
说了这么多原理,最终还是要看数字。V²Drop在多个主流模型和基准测试上的实验结果,可以用”全面碾压”来形容。
图像理解
在LLaVA-1.5-7B上,V²Drop压缩掉66.7%的Token(从576个压缩到192个),综合性能仍然保持在原始性能的97.6%,超越了此前最优方法PDrop的96.0%。换句话说,扔掉三分之二的Token,性能几乎纹丝不动。
在更具挑战性的Qwen2-VL-7B高分辨率场景中,V²Drop在66.7%和77.8%两档压缩率下,全面超越FastV和DART。尤其值得一提的是POPE幻觉抑制指标——这正是位置偏差问题的重灾区,V²Drop在这里的优势最为突出,直接验证了消除位置偏差对减少幻觉的实际效果。
视频理解
视频场景是V²Drop最能体现优势的战场。在LLaVA-OV-7B上,V²Drop仅保留25%的Token,综合性能即达到98.6%,超越了保留30% Token的DyCoke(97.7%)——以更少的Token实现了更好的性能。
在最难的长视频任务(VideoMME-Long)上,V²Drop持续领跑,有效缓解了VideoLLM普遍存在的”末帧偏置”问题(这与图像任务中的末端Token偏置是同一类问题的视频版本)。
在Qwen2-VL-7B场景下,仅保留20%的Token时,综合性能达93.3%,其中MVBench以62.1分大幅领先DART(58.9分)和FastV(50.9分),优势尤为突出。
效率分析:最亮眼的数字在这里
性能保持住了,效率提升了多少?
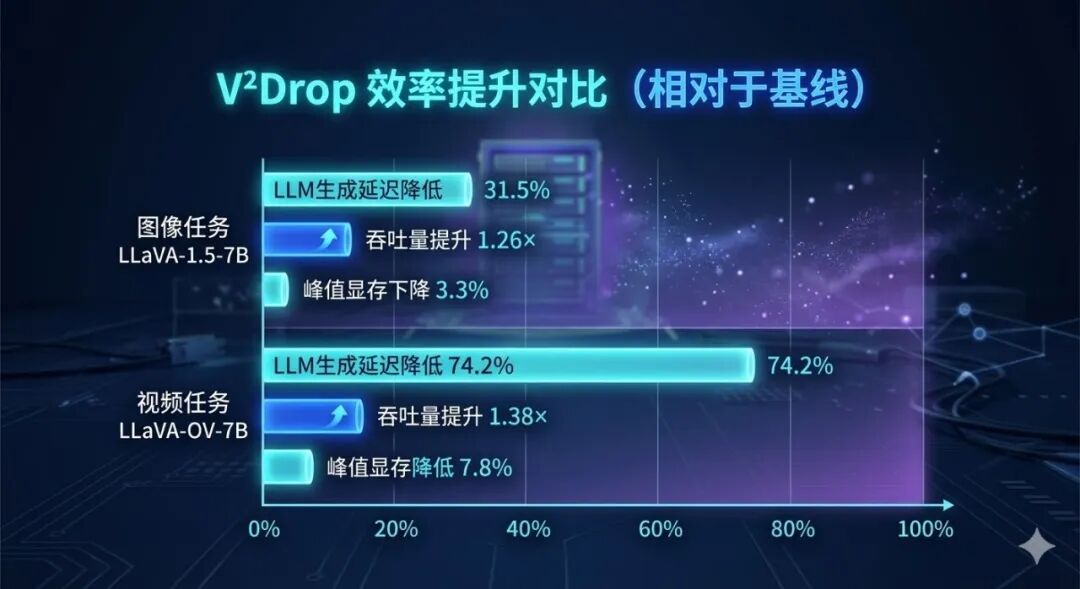
图像任务中,LLM生成延迟降低31.5%,吞吐量提升1.26倍,峰值显存同步下降3.3%。视频任务中,LLM生成延迟大幅削减74.2%,吞吐量提升1.38倍,峰值显存降低7.8%。
而与之形成鲜明对比的是竞争对手们的表现:SparseVLM、FastV、PDrop在视频场景下,峰值显存分别暴增54.8%、39.2%和37.8%。它们虽然在速度上也有提升,但代价是显存的急剧膨胀——这在实际部署中意味着需要更贵的GPU,或者无法处理更长的视频。
V²Drop是目前唯一一个能在提速的同时还能降低显存占用的Token压缩方案。这背后的原因很简单:它不需要计算注意力矩阵,从根本上消除了一块额外的显存开销。
为什么这件事值得关注:从实验室到现实世界
看到这里,你可能会想:这是一篇学术论文,和我有什么关系?
关系很大。
首先是即插即用,门槛极低。 V²Drop不需要修改模型权重,不需要重新训练,代码已经开源在GitHub上(github.com/xuyang-liu16/V2Drop),直接套在现有的LLaVA或Qwen2-VL模型上就能用。对于企业来说,这意味着几乎零迁移成本就能获得接近两倍的推理速度提升。
其次是真正解锁了双重加速。 在V²Drop之前,工程师们面临一个痛苦的选择:要用FlashAttention,就不能用注意力剪枝;要用注意力剪枝,就得关掉FlashAttention。两个优化手段互相打架。V²Drop彻底解决了这个工程难题——它与FlashAttention完全兼容,两者可以同时开启,叠加收益。
最后是对终端用户的实际意义。 当你在手机上运行本地多模态模型,或者企业用更少的GPU跑更大规模的视频分析业务,V²Drop这类技术正是让这些场景成为可能的底层支撑。推理成本下降,意味着服务定价可以更低;延迟降低,意味着实时交互成为可能;显存需求减少,意味着更小的硬件也能跑起来。
从医疗影像分析到工业视觉质检,从自动驾驶的实时感知到短视频平台的内容理解,多模态AI的应用场景正在快速扩张。而每一个场景的落地,都绕不开推理效率这道坎。
更大的图景:Token压缩赛道的竞争格局
把V²Drop放回到更宏观的技术趋势中来看,这个赛道正在经历一次深刻的范式转变。
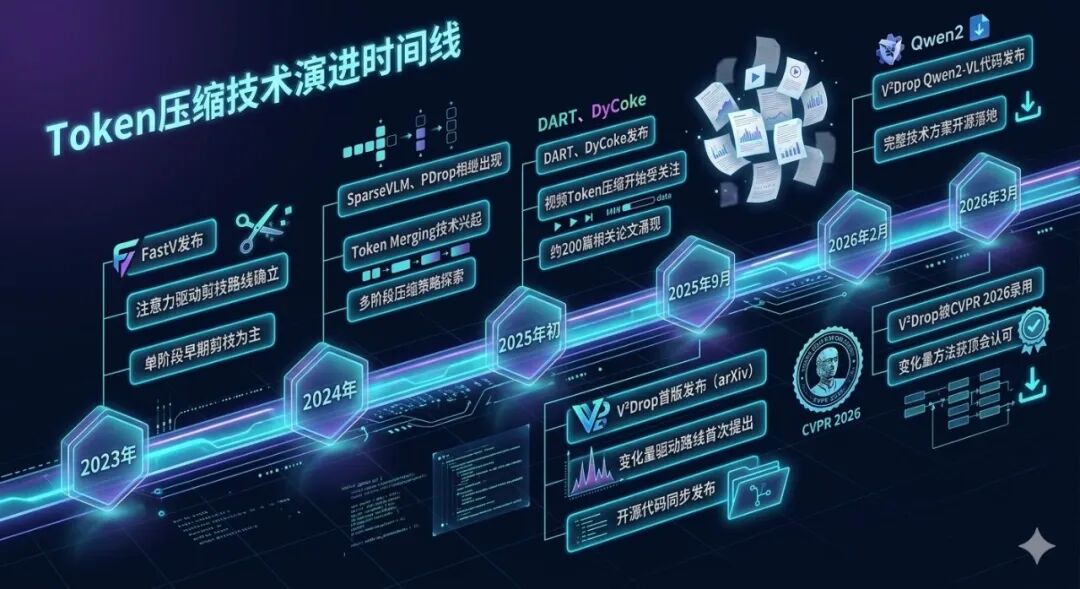
当前赛道主要形成了三条技术路线的竞争格局:
- 注意力驱动路线(FastV/SparseVLM)是最早也是最主流的方向,优点是直觉清晰、实现简单,缺点正是本文详细分析的位置偏差和FlashAttention不兼容问题。
- 结构感知路线(如Nüwa空间感知框架)试图引入图像的空间结构信息来指导剪枝,在空间推理任务上有独特优势,但通用性相对较弱。
- 变化量驱动路线(V²Drop)是最新出现的方向,凭借任务无关性、无位置偏差、与高效算子完全兼容三大优势,在CVPR 2026上获得认可,代表了这个方向的最新水位。
值得关注的是,这个领域的下一个前沿正在向”自适应混合压缩”演进——根据输入内容的特点,动态地在”软聚合”(Token Merging,将相似Token合并)和”硬剪枝”(Token Dropping,直接丢弃Token)之间切换。当内容高度冗余时用软聚合,当语义已经足够稀疏时用硬剪枝,两种策略各取所长。
另一个重要趋势是训练时压缩与推理时压缩的协同设计。目前包括V²Drop在内的大多数方法都是纯推理时的即插即用方案,无需修改训练过程,这是其工程优势所在。但研究表明,如果在训练阶段就引入压缩感知,模型可以学会更好地在压缩条件下保持性能,进一步提升压缩率的上限。这是下一代方法的重要探索方向。
结语:”少即是多”,AI的下一个效率革命
大模型的进化故事,长期以来被一个叙事主导:参数越来越多,能力越来越强。GPT-3有1750亿参数,GPT-4据说超过万亿,每一代模型的”大”都在刷新认知上限。
但V²Drop代表的是另一种进化方向:在有限资源下做更精准的选择。
它的核心洞见——”变化才是价值”——其实是一种极其朴素的认知。真正重要的信息,总是在动的。一个在模型各层之间毫无变化的Token,就像一个在会议室里全程沉默的人,把他请出去,会议效率反而更高。
这种”断舍离”的哲学,正在成为AI效率优化的核心思路。不是堆更多算力,而是让每一个计算单元都用在刀刃上;不是保留所有信息,而是精准识别哪些信息真正重要。
当AI学会”只看重点”,而不是”看所有”,才是真正意义上的智能成熟。V²Drop只是这场效率革命的一个缩影——但它已经足够说明,多模态AI的下一个战场,不在于模型能看多少,而在于它能多快、多准地看到最关键的那一眼。
论文链接:arxiv.org/abs/2509.01552
本文由 @鱼尾落晴朝 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供






- 目前还没评论,等你发挥!


