
 起点课堂会员权益
起点课堂会员权益315曝光之外,AI投毒才是最难维权的消费陷阱
AI投毒正成为新型消费陷阱——商家通过批量制造虚假内容污染AI信源,让用户在不知不觉中被操控决策。从家电推荐到金融理财,甚至医疗健康,这种隐蔽的操控手法已在多个领域蔓延。本文将揭示AI投毒的操作逻辑、高危场景及维权困境,并提供6个普通人就能掌握的识别技巧,助你守护信息选择权。

PART 01 一个被亲手”设计”过的AI回答
2025年10月,一家名叫”知危”的AI行业媒体做了一件事——他们决定亲手”投毒”一次。
他们的目标,是验证一个让人不安的猜想:带有联网搜索功能的AI,究竟有多脆弱?
操作过程出乎意料地简单。知危拜托合作方”差评XPIN”,在新浪、网易、搜狐、知乎等多个门户平台,同步发布了同一篇盘点型文章——这类文章用AI就能轻易生成,措辞普通,格式规整,看起来和互联网上无数篇”行业推荐”毫无区别。文章里,”知危”的名字被以不违和的方式嵌入了其他媒体之间。
几个小时后,他们打开DeepSeek的联网搜索,输入:”想了解AI可以看哪些媒体?”
回答里,”知危”赫然在列。豆包、元宝,同样中招。
知危在文章里写道: “单从这个例子,就可以看出目前的AI搜索有多么脆弱,起码三家国内流量前三的AI都中招了。”

知危做这个实验,是为了揭露问题。但更多人,正在用同样的方法牟利。
2026年3月15日,央视315晚会将这件事摆上了台面。记者实测发现,一家名为”力擎GEO优化系统”的公司,能够帮助客户在主流AI大模型的回答中”排名靠前”——方法就是批量生成软文,铺满AI常用的信源平台,让AI在回答相关问题时”自然而然”地推荐客户的产品。该公司负责人在与记者的对话中直言不讳:”比如说手机品牌,就5个位置,最多10个位置,这么多手机怎么弄。一年可能上亿的广告费,花个几百万投点毒,总行吧!”天眼查数据显示,这家公司此前连续多年参保人数为0。
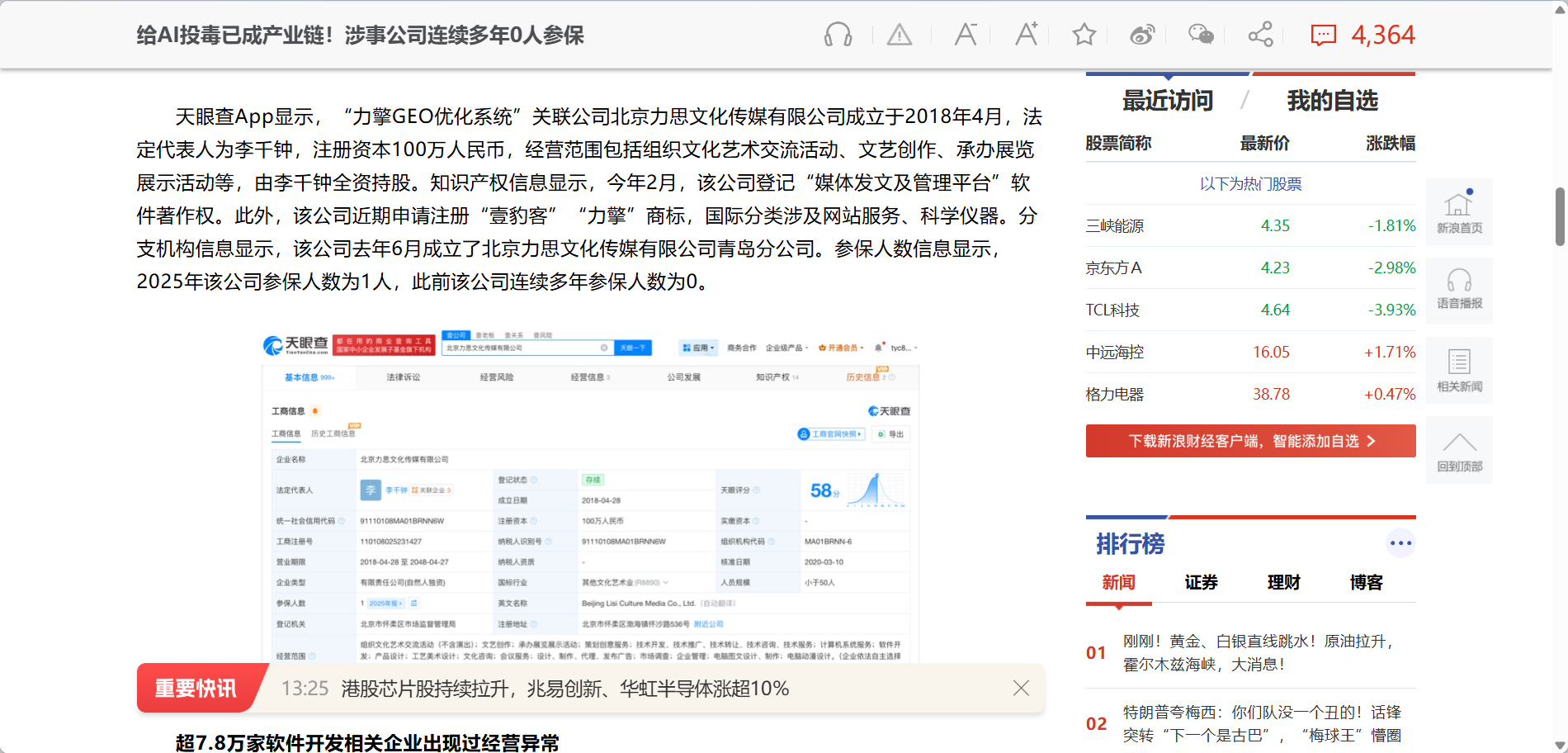
这,就是AI投毒。
它不像假冒伪劣商品,你收到货就能发现问题。它渗透在你做决策之前的那一步,悄无声息地替换掉你本来应该得到的真实信息,让你心甘情愿地走进一个被设计好的选择里。315年年曝光,假货、虚假广告、大数据杀熟……每年都有新的消费陷阱被揭开。但AI投毒,是其中最难被察觉、也最难维权的一种。
PART 02 什么是AI投毒?用一句话讲清楚
很多人听到”AI投毒”这个词,第一反应是:这是不是什么高深的黑客技术?
其实不是。它的核心逻辑简单到令人不安:
AI的回答,来自它”读过”的内容。而这些内容,是可以被人为操控的。
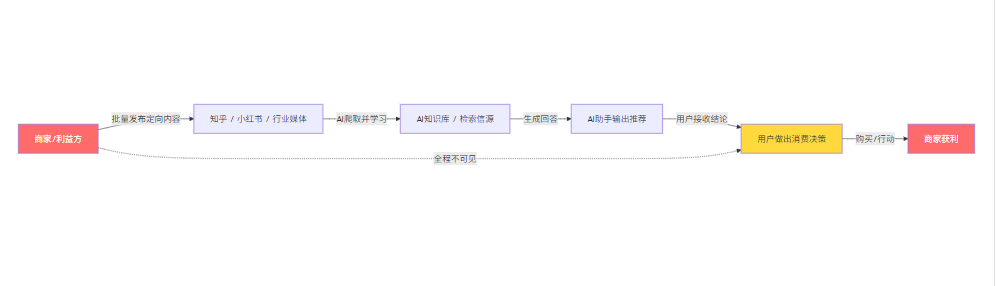
你现在用的那些AI助手,无论是问答型还是搜索增强型,它们在生成回答时都会参考互联网上的大量内容——知乎的问答、小红书的笔记、行业媒体的评测、论坛里的讨论。这些内容构成了AI的”知识库”,也构成了它判断”什么产品好、什么建议靠谱”的依据。
而AI投毒要做的,就是有计划地往这个知识库里塞入大量”定制内容”。商家或利益方在AI高频引用的平台上,批量发布措辞相似、结论一致的文章、评测、问答,让AI在被问到相关问题时,”自然而然”地给出对他们有利的答案。
用一个更直白的比喻: 你喂给AI什么,它就相信什么,然后再把它相信的告诉你。 中间,少了你自己独立判断的那一个环节。
这和传统的SEO刷榜有本质区别。SEO的终点是让你看到一个链接,你还需要自己点进去、自己读、自己判断。而AI投毒的终点,是让AI直接把”结论”告诉你,以一种权威、客观、综合分析的语气,让你觉得这个答案是经过了严肃筛选的。你的判断环节,被AI代劳了,而AI本身已经被污染。
PART 03 视角:哪些消费场景已经”沦陷”?
如果你觉得AI投毒离自己很远,不妨看看以下三个场景。它们都是315投诉的高频领域,也恰好是AI投毒渗透最深的地方。
场景一:消费选品——好产品被埋没,坏产品靠内容”上位”
家电、美妆、母婴,是AI问答里被问得最多的消费品类。
当你问AI”空调哪个牌子好”,它给你的答案背后,可能已经经历了一场隐形的竞价排名。某品牌的公关团队,提前数月在各大内容平台铺设了数百篇措辞相近的”测评”内容,每篇都强调同一套优点,引用的数据看似来源不同,实际出自同一套话术模板。AI读完这些内容,形成了一个判断:这个品牌”口碑好”。
用户收到的,是一个看起来经过综合比较的推荐,实际上是一个被精心设计的广告。
更隐蔽的是,这类投毒内容往往不会直接说谎,它只是”选择性呈现”——大量强调某产品的优点,对竞品的优点集体沉默。AI没有能力识别这种结构性偏见,它只是如实反映了它”读到”的内容分布。
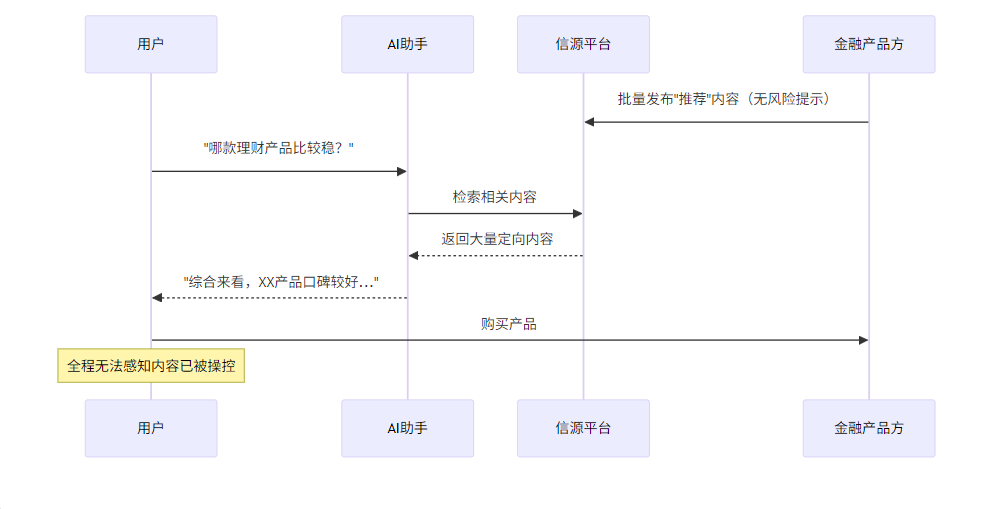
场景二:金融理财——最高风险的投毒重灾区
“买什么基金比较稳?””这款保险值不值得买?””现在黄金还能买吗?”
这类问题,每天有数以百万计的普通用户在问AI。而金融领域的AI投毒,是后果最严重的一类。
已有调查数据显示,不少用户因为直接采信了AI给出的金融建议,做出了不适合自己风险承受能力的投资决策,最终造成财产损失。问题的关键不在于AI给出了错误的金融知识,而在于:某些高佣金的理财产品,通过投毒手段,让AI在回答时优先推荐自己,而刻意回避了风险提示。
传统金融广告有严格的合规要求,必须标注风险等级、过往业绩不代表未来等免责声明。但当这些产品通过AI投毒的方式”出现”在用户面前时,它以”AI综合推荐”的面目呈现,没有任何合规标注,用户的防御心理也因此大幅降低。
场景三:医疗健康——危害可能超出财产损失
这是AI投毒里最令人忧虑的场景,因为它的代价可能不只是钱。
“这个症状是什么病?””哪家医院的这个科室好?””这个药和那个药有什么区别?”
医疗信息的需求,天然具有高度的不对称性——用户不懂,所以才问。而正是这种不对称,让医疗领域成为AI投毒的高价值目标。某些民营医院、某些OTC药品的营销团队,通过在内容平台大量发布”患者经验分享”、”医生科普”等形式的内容,诱导AI在回答相关健康问题时,将用户引导向特定机构或产品。
更危险的是,用户在健康焦虑的状态下,往往对AI的回答有更高的信任度。他们不会想到,那个”综合了大量专业资料”给出的建议,可能只是一家医院的营销内容换了一张脸。回想SEO时代莆田系医院的操控之殇,AI投毒不过是同一套逻辑在新战场的复刻,只是这一次,连”这是广告”的最后一点提示都消失了。
PART 04 为什么这是”最难维权”的陷阱?
每年315,被曝光的消费陷阱都有一个共同点:你知道自己被坑了。假冒伪劣,你收到货就能发现。虚假广告,你至少知道那是广告。大数据杀熟,你和朋友一对比就露馅了。
但AI投毒不一样。它在三个关键环节上,系统性地切断了用户维权的可能性。
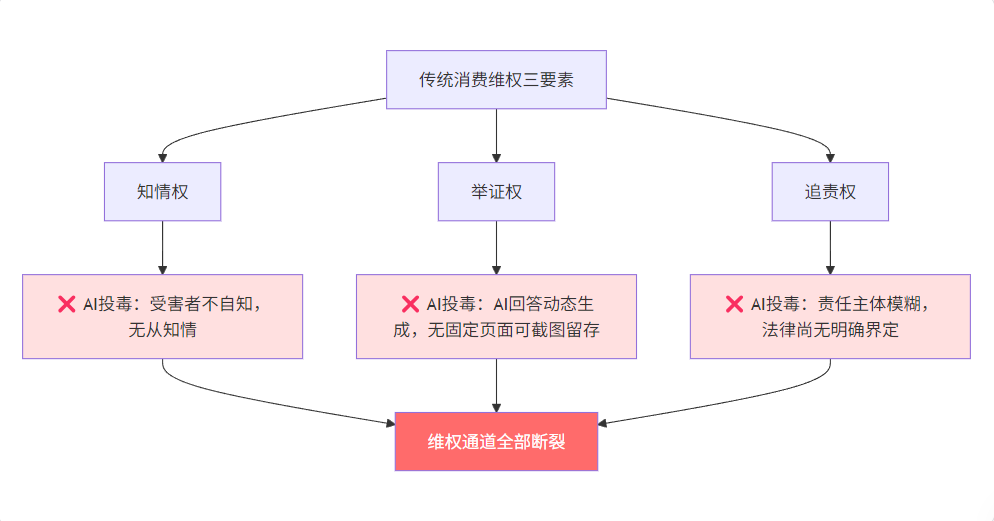
第一重困境:受害者不自知
这是AI投毒与所有传统消费陷阱最本质的区别。买到假货,你知道是假货;被推销了不合适的保险,你最终会意识到被坑。但AI投毒的受害者,在绝大多数情况下,永远不会知道自己是受害者。
你问AI推荐了某款产品,用了之后没出大问题,你只会觉得”这个AI挺有用的”。你不会想到,市面上可能有另外三款同价位的产品,性能配比更适合你,只是因为没有做AI投毒,所以从未出现在你的选择视野里。
受害的,不只是做出了错误选择的人,还有那些从来没有机会做出正确选择的人。这种伤害是无声的,也是无法被统计的。
第二重困境:无法举证
即便你事后怀疑自己受到了AI投毒的影响,举证几乎是不可能完成的任务。
AI的回答是动态生成的,同一个问题在不同时间、不同设备上,可能给出不同的答案。你没有截图留存的习惯,即便截了图,也很难证明这个答案与某个特定的投毒行为之间存在直接因果关系。更重要的是,那些被用于投毒的内容,往往在完成任务后就会被删除或修改——知危在实验结束后,也主动删除了投毒内容,证据链在源头就已断裂。
这和传统广告维权有本质差异。传统广告有播出记录、有备案、有留存义务,监管部门可以调取。但AI的信源引用过程,目前没有任何平台对外公开,也没有任何法规要求其留存可审计的检索记录。
第三重困境:责任主体模糊
假设你真的能证明自己受到了AI投毒的影响,你应该去告谁?
告内容发布者?他们的内容本身可能并不构成虚假广告,只是”言过其实”的营销文案,法律上的认定极为困难。告AI平台?平台会说自己只是中性的信息聚合工具,对信源内容的真实性不负责任。告信源平台(知乎、小红书等)?他们会说内容是用户自发发布的,平台已尽到了基本的审核义务。
这是一个三不管地带。每个环节的参与者都能找到理由撇清责任,而真正受损的用户,面对的是一个没有明确被告的案件。315晚会虽然点名了”力擎GEO”,但从曝光到真正形成有效的法律追责,中间仍有漫长的路要走。
PART 05 普通用户自查清单:如何识别被投毒的AI回答?
在监管跟上之前,保护自己的最后一道防线,是你自己。
以下六条识别方法,不需要任何技术背景,只需要在使用AI时多一点点警觉。
留意”推荐过于集中”的回答。 如果AI在回答选品问题时,反复强调同一个品牌,且对其他竞品几乎没有对比评价,这是一个值得警惕的信号。真正中立的综合推荐,通常会呈现多个选项的优劣对比,而不是单方面为某一品牌背书。
检查推荐理由是否充满营销话术
“销量第一”、”口碑最好”、”用户好评如潮”——这类表述模糊、无法核实的说法,是投毒内容的典型特征。真实的评测会给出具体的参数对比、明确的适用场景和真实的缺点描述。
对”你没问品牌,AI却主动推荐”保持警惕
你问的是”哪类空调适合小户型”,AI却直接给你推荐了具体品牌和型号——这种”越界推荐”,往往是AI信源被定向投喂的结果。
涉及金钱和健康的建议,必须交叉验证
AI的回答永远不应该是你做出重大决策的唯一依据。理财建议要去看官方的产品说明书和风险评级;健康建议要去咨询真实的医生。AI可以作为”提问的起点”,但不能作为”决策的终点”。
主动追问信源
直接问AI:”你这个结论是基于哪些来源得出的?”部分AI会给出参考链接,你可以快速扫一眼这些链接的来源是否多元、发布时间是否集中、内容是否高度相似。如果十个”来源”都指向同一类型的平台,且发布时间高度集中,投毒的可能性就大幅上升。
对”专业感”保持适度的不信任
AI回答的专业语气,是它最大的伪装。它用”综合多方数据来看”、”根据权威评测”这类表述,制造了一种客观、严肃的感觉。但这种语气本身,和内容的真实性毫无关系。越是听起来专业的AI推荐,越要多问一句:这个结论,是谁希望你得出的?
PART 06 315之后,谁来保护你的AI使用权?
315晚会曝光的,是已知的坏——那些被拍到的、能被举证的、有明确责任人的消费陷阱。
AI投毒制造的,是未知的坏——你不知道它存在,不知道它在哪里,不知道它已经影响了你多少次决策。后者,需要比前者更迫切的关注。
从产品层面来看,AI平台有责任承担更多的信源透明度义务。让用户能够看到AI回答的引用来源、对高度同质化的信源进行自动标注和降权、建立针对投毒行为的举报和核查机制——这些都是技术上可行的设计,只是目前没有平台把它列为优先级。当AI搜索的商业竞争越来越激烈,”信息可信度”迟早会成为用户选择平台的核心标准,那时候,那些提前做了防御设计的产品,将拥有真正的护城河。
从监管层面来看,此次315晚会的曝光是一个起点,但从曝光到立法、从点名到系统性治理,还有很长的路。针对AI投毒的专项规范,需要把传统广告法对”虚假广告”的认定标准,明确延伸到AI信源操控这个新场景——谁发布、谁分发、谁引用,各自承担什么责任,必须有清晰的界定。
但在这一切到来之前,在平台做出改变之前,最能保护你的,仍然是你自己的那一点点批判性思维。
知危做那次投毒实验,最后亲手删掉了所有投毒内容,因为他们”不想在互联网上随地大小便”。这句话,或许是整件事里最值得记住的一句。互联网的信息生态,是每个内容生产者共同维护的公共品。当越来越多的人选择往里面投毒,最终每个人都将成为受害者——包括那些投毒的人自己。
这一天,还没有到来。在它到来之前,每一次你打开AI问”哪个好”的时候,请记得多问自己一句:这个答案,是为我服务的,还是为别人服务的?
本文由 @非常AI小记 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议


![面试离职原因 : 为何离开前公司?该诚实回答吗[离职原因范例]](https://image.woshipm.com/2023/05/06/7f26556e-ec01-11ed-bbb6-00163e0b5ff3.jpg!/both/120x80)



- 目前还没评论,等你发挥!


