
 起点课堂会员权益
起点课堂会员权益NotebookLM为什么要”主动放弃”通用AI的能力?
在AI工具疯狂堆砌功能的时代,NotebookLM反其道而行之,用「来源锚定」设计主动锁死知识边界。这款谷歌出品的笔记工具不追求无所不知,而是通过每句话必附出处的硬核机制,直击专业场景下AI「幻觉」的信任痛点。本文将深度拆解这个看似降智实则高明的产品决策,为何能在B站、小红书掀起现象级讨论,又是如何用「有限但可信」开辟AI竞争新赛道。

引言:一个反常识的产品决策
如果你关注AI工具圈,你一定注意到一个奇怪的现象。
过去两年,几乎所有AI产品都在拼命往”更强”的方向卷:更大的模型、更长的上下文、更多的联网能力、更广的知识覆盖。ChatGPT在联网,Claude在扩上下文,Perplexity在做实时搜索。大家的逻辑都一样——我要知道更多,我要回答更多,我要无所不知。
但有一款产品,偏偏反着来。
它的第一个设计选择,是主动把自己的知识边界锁死在用户上传的文档里。你没上传的东西,它不知道,也不会去猜。它的每一条回答,都必须能在你提供的资料里找到出处,找不到的,它宁愿告诉你”资料里没有”,也不会自己编一个。
这不是技术限制,是产品决策。
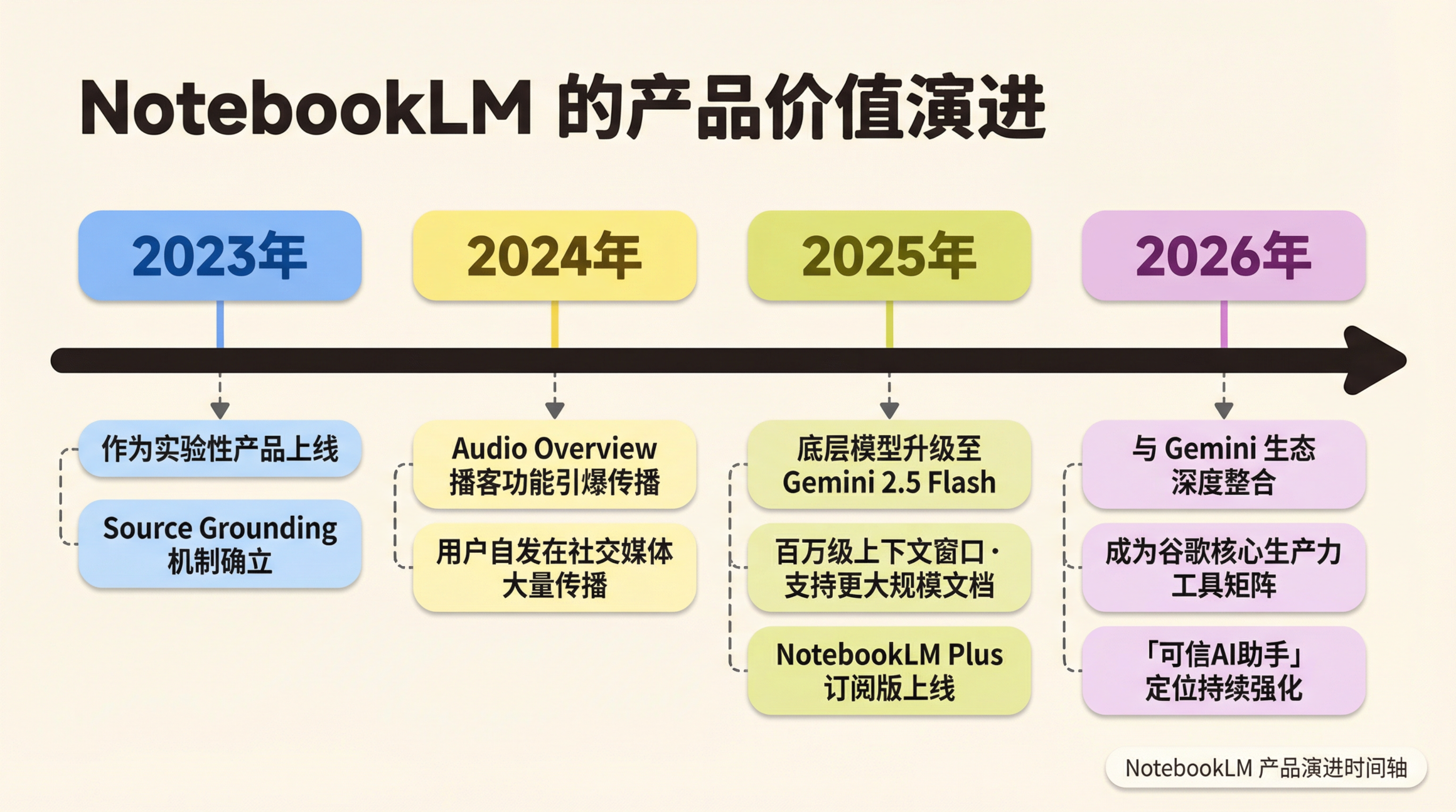
这款产品叫 NotebookLM,谷歌出品。它从一个不起眼的实验性笔记工具,在几乎没有大规模营销的情况下,靠着用户自发传播成了现象级产品,在B站、小红书上掀起了一波又一波的讨论热潮。
它凭什么?靠的不是”更多”,靠的是”更准”。
这篇文章想聊的,就是这个反常识的产品决策背后,到底藏着什么样的产品思考。
通用大模型的信任危机,才是真正的战场
要理解NotebookLM为什么这么设计,得先搞清楚它要解决的是什么问题。
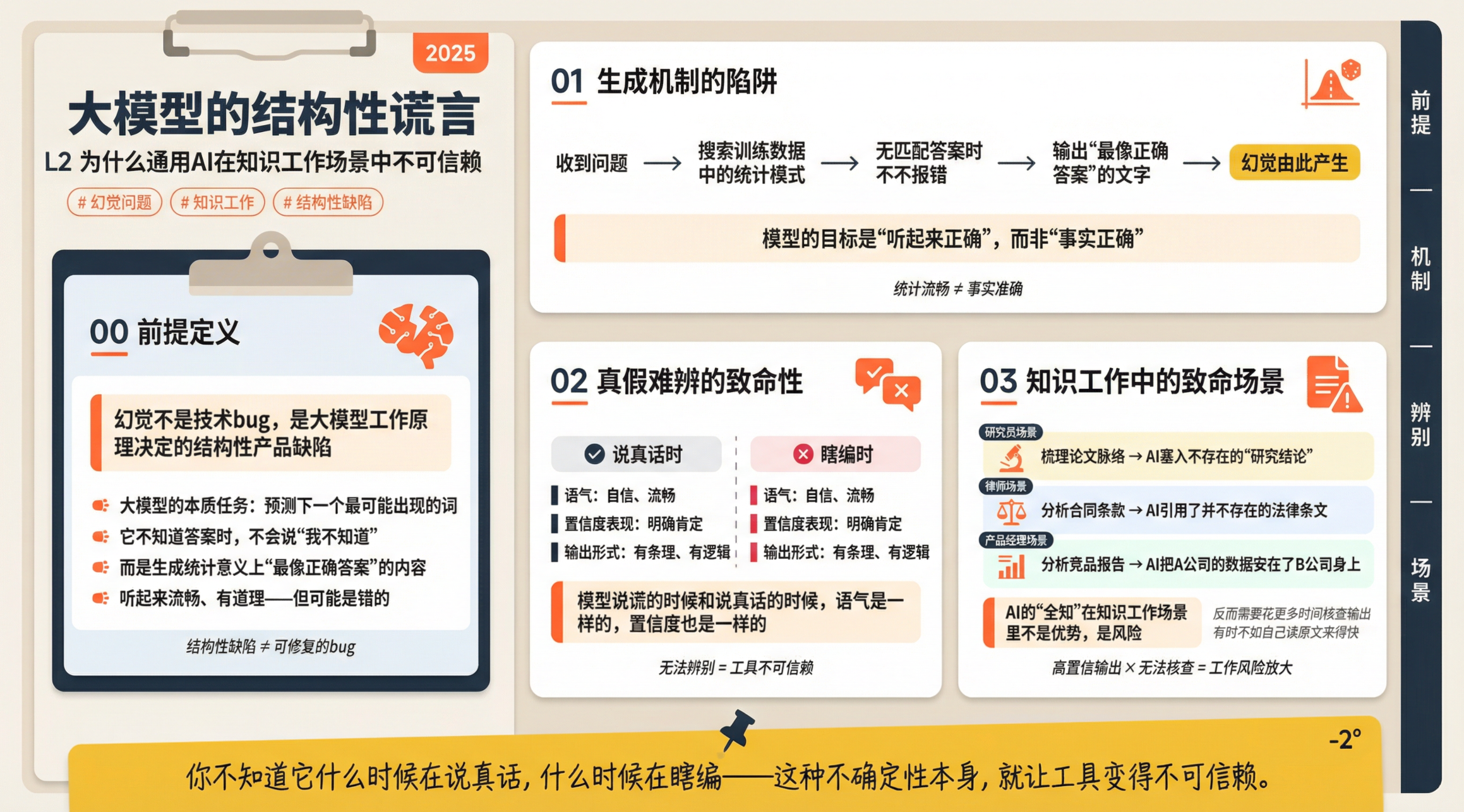
很多人用ChatGPT、Claude这类通用大模型的时候,都有过这样的体验:你问它一个很具体的问题,它给你一个听起来非常有道理、逻辑自洽的回答。但你拿去核实,发现有些细节是错的,有些引用根本查不到,有些数字是凭空捏造的。
这个现象在AI领域有个专门的词,叫”幻觉”(Hallucination)。
幻觉这个词听起来像是技术问题,但它本质上是一个结构性的产品缺陷。大模型的工作原理,是根据训练数据预测下一个最可能出现的词。当它不知道某个问题的答案时,它不会说”我不知道”,而是会生成一个在统计意义上”最像正确答案”的回答——听起来流畅、有道理、有逻辑,但可能是错的。
更麻烦的是,你很难判断哪条回答是真实的,哪条是编的。模型说谎的时候和说真话的时候,语气是一样的,置信度也是一样的。
这个问题在日常聊天场景里影响不大,你问它”帮我写首诗”,它编一编没关系。但在知识工作场景里,这是致命的。
想象一下这些场景:你是一个研究员,把几十篇论文扔给AI,让它帮你梳理研究脉络——结果它在里面塞了几条根本不存在的”研究结论”;你是一个律师,让AI分析合同条款——结果它引用了一条并不存在的法律条文;你是一个产品经理,让AI分析竞品报告——结果它把A公司的数据安在了B公司身上。
在这些场景里,AI的”全知”不是优势,是风险。你用它,反而需要花更多时间去核查它的输出,有时候还不如自己读原文来得快。
这就是通用大模型在知识工作场景里真正的痛点:你不知道它什么时候在说真话,什么时候在瞎编。这种不确定性本身,就让工具变得不可信赖。
NotebookLM要打的,正是这场信任战役。
Source Grounding——一个主动”降智”的设计
理解了问题,再来看NotebookLM的解法,你就会觉得它的思路非常清晰。
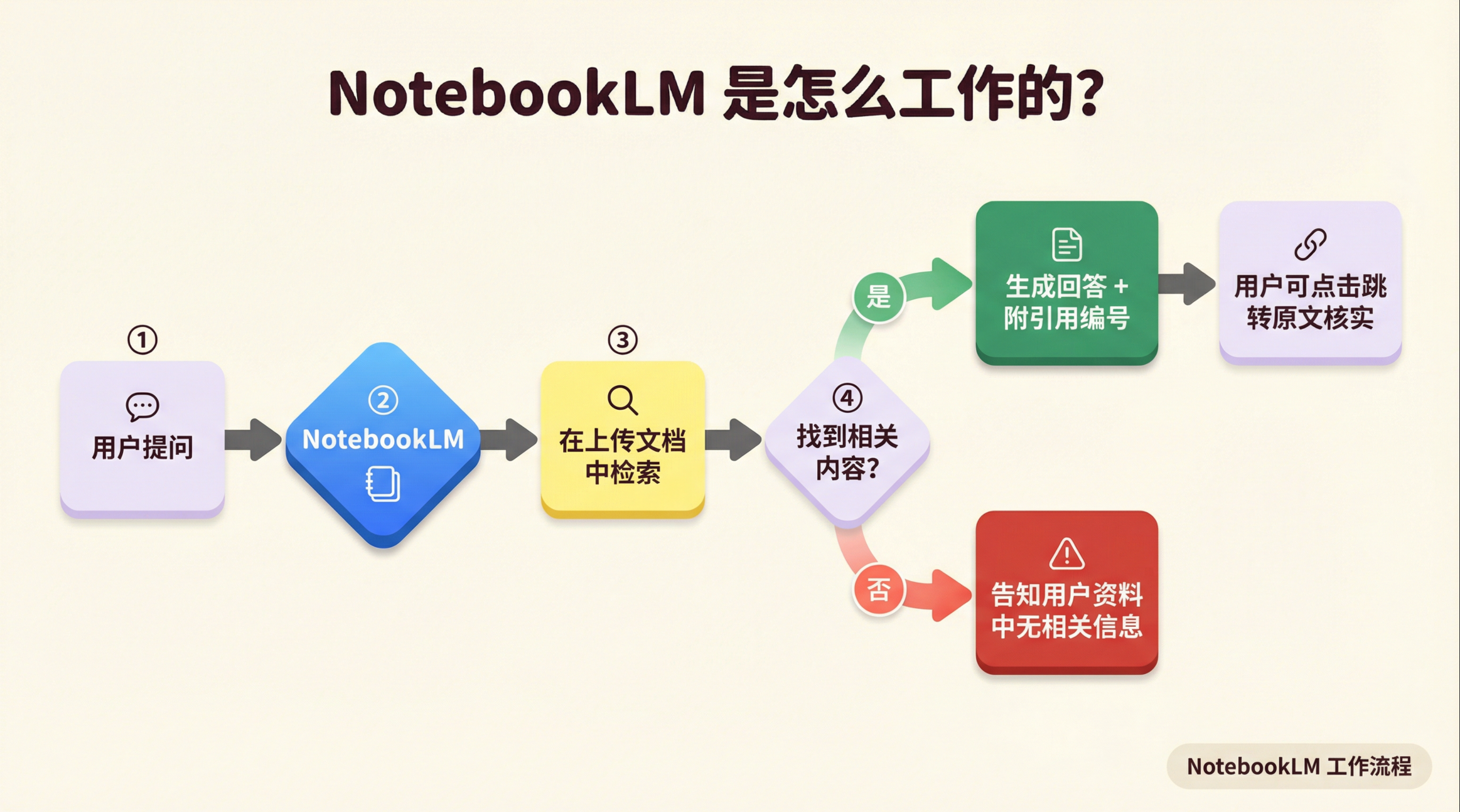
NotebookLM的核心机制叫做 Source Grounding(来源锚定)。翻译成大白话就是:它的所有回答,只能来自你上传的那些文档,而且每一条回答都会附带一个可以点击的引用编号,你点进去,直接跳到原文的对应段落。
如果你问它一个问题,但你上传的资料里没有相关内容,它会直接告诉你:”这个问题在你提供的来源中没有找到相关信息。”它不会猜,不会推断,不会”合理补充”。
这个设计,从技术上彻底切断了模型”自由发挥”的可能。
有人可能会说,这不就是把AI变笨了吗?它本来能回答很多问题,现在只能回答你资料里有的问题,功能不是缩水了吗?
这正是这个设计反直觉的地方。
它确实”变笨”了——但它变得可信了。
用一个比喻来理解:ChatGPT像一个博览群书的万事通,他读过互联网上几乎所有的书,能回答各种问题,但有时候会记错细节,甚至把不同书里的内容混淆,而且你没办法当场验证他说的是不是真的。NotebookLM则像一个严谨的私人图书管理员,他只根据你书架上的那几本书来回答问题,但他每次回答都会告诉你”这个结论出自第三本书的第47页”,你可以随时翻开核实。
这个trade-off背后,是一个非常清醒的产品判断:在知识工作场景里,”可信度”比”全能”更有价值。
一个能回答一切问题但偶尔会说谎的助手,和一个只回答它确定知道的问题但从不说谎的助手,对于需要做严肃决策的人来说,后者的价值远高于前者。
这不是技术上做不到更多,而是主动选择了克制。这种克制,恰恰是NotebookLM最深的产品护城河。
两种产品哲学,两种不同的答案
在知识管理这个赛道里,腾讯ima和NotebookLM是两个很有意思的参照系——它们几乎同时在做”让AI帮你管理知识”这件事,但走了两条截然不同的路。理解这两条路的差异,比简单比较谁更好用,要有价值得多。
ima的产品逻辑,是深度嵌入腾讯生态。你在微信里看到一篇好文章,一键收进ima;你的工作文件、聊天记录、公众号内容,都可以无缝流入这个知识库。对于大量日常工作依托腾讯系产品的用户来说,这种”随手收、随时用”的体验几乎是零摩擦的。它服务的是一种非常真实的需求:在信息爆炸的时代,帮你把散落在各处的内容聚合起来,随时可以调用。
NotebookLM的逻辑则完全不同。它不追求”装得多”,而是追求”挖得深”。它的基本单位是一个个独立的笔记本,每次使用都要求你带着一个明确的研究课题进来,主动筛选、主动上传、主动提问。它服务的是另一种需求:当你需要对某个特定主题做深度研究,并且对回答的准确性有严格要求的时候。
这两种逻辑背后,其实是对”知识工作”两个不同阶段的侧重。ima更擅长的是信息的收集与沉淀阶段——让有价值的内容不丢失,随时可以找回来;NotebookLM更擅长的是研究与提炼阶段——当你已经有了一批资料,需要从中挖掘洞见、形成结论。
两者并不是非此即彼的关系。事实上,有不少用户同时在用这两款产品:用ima做日常信息的收集和归档,用NotebookLM做专项课题的深度研究。这种组合使用的方式,恰恰说明它们各自在自己最擅长的场景里都有不可替代的价值。
当然,这也意味着NotebookLM有一个天然的使用门槛:它要求用户在每次研究前,先想清楚”我这次要研究什么”,然后主动去找资料、筛选资料。这个步骤对于习惯了”被动收藏”模式的用户来说,需要一定的行为习惯转变。
这个门槛本身,其实也是一个有趣的产品设计选择——它在某种程度上筛选了用户:愿意做这个主动投入的人,往往是对研究结果的质量有更高要求的知识工作者。而正是这类用户,对”可信度”和”引用溯源”的需求最为迫切。
笔记本分割机制——”有限”是如何成为产品优势的
说完和竞品的对比,再来深挖NotebookLM一个经常被忽视但非常关键的设计细节:笔记本(Notebook)机制。
NotebookLM不允许你建一个”终极超级大脑”把所有东西都放进去。它的基本单位是一个个独立的笔记本,每个笔记本最多放50个来源,而且笔记本之间是完全隔离的——你在这个笔记本里问的问题,只会从这个笔记本里的资料里找答案,绝对不会跨笔记本检索。
乍一看,这是个很烦人的限制。我就想要一个大知识库,为什么要分这么多本?
但仔细想想,这个”限制”解决了一个非常深层的问题。
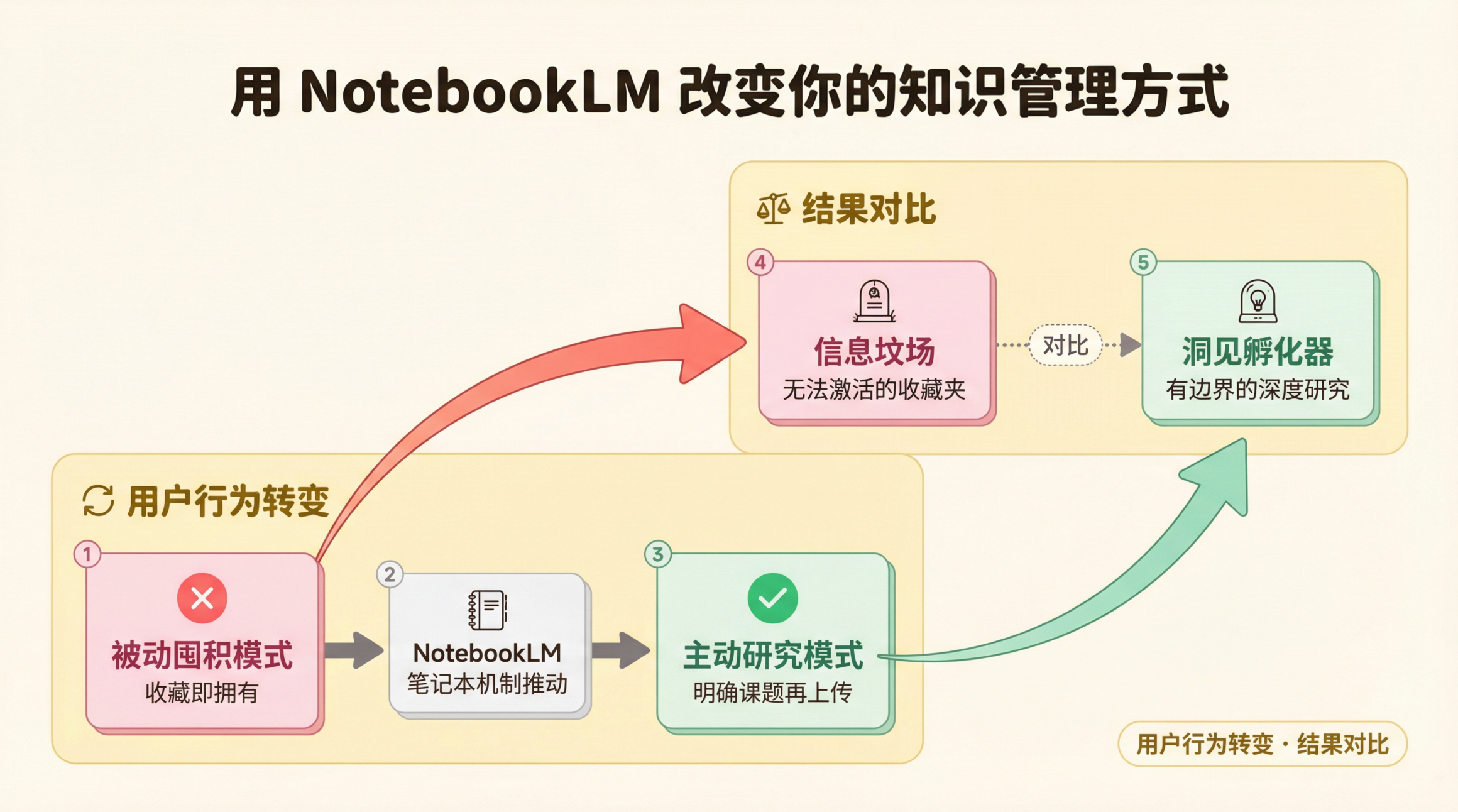
我们在使用知识工具的时候,有一个很普遍的坏习惯:把收藏当成学习。看到一篇好文章,收藏了。看到一本好书,加书单了。看到一个好工具,收进去了。收藏完之后,心里有种莫名的安慰感,好像”拥有”了这些知识。
但实际上,收藏和学习之间隔着一道巨大的鸿沟。收藏是被动的,学习是主动的。信息的堆积不会自动转化为洞见,收藏夹里有1000篇文章和有10篇文章,你真正能用到的可能差不多多。
NotebookLM的笔记本机制,通过设计上的”强制分割”,把用户从”被动囤积”推向了”主动研究”。
你每次新建一个笔记本,都必须先想清楚:我这次要研究什么? 这个问题本身,就是一次主动的认知投入。然后你去找资料,筛选资料,把最相关的内容上传进来。这个过程里,你已经完成了一次初步的信息筛选和主题聚焦。
这种”强制摩擦”表面上是麻烦,实质上是在帮用户做一件他们本来应该自己做但往往懒得做的事:在开始研究之前,先明确研究边界。
有了清晰的边界,AI才能在这个边界内做精准的检索和回答。没有边界的知识库,AI只能在信息的汪洋里随机捞鱼,捞到什么算什么。
这里有一个值得反复品味的产品设计规律:好的产品设计,有时候是在帮用户对抗自己的惰性。
用户的本能是”我想要更多、更方便、更省力”。但有时候,真正帮助用户的产品,恰恰是在某些关键节点上制造一点摩擦,逼着用户做那件”费力但正确”的事。
NotebookLM的笔记本机制就是这样一个设计:它用”不方便”换来了”更有价值”。这个trade-off,是对用户真实需求的深刻理解,而不是对用户表面诉求的简单满足。
这个决策的更大意义——”有限但可信”能走多远
聊到这里,我们可以从单个产品决策往上拔一层,看看这个选择对NotebookLM长期竞争力的意义。
Source Grounding不仅仅是一个功能特性,它还是一条差异化护城河,而且这条护城河会随着时间推移越挖越深。
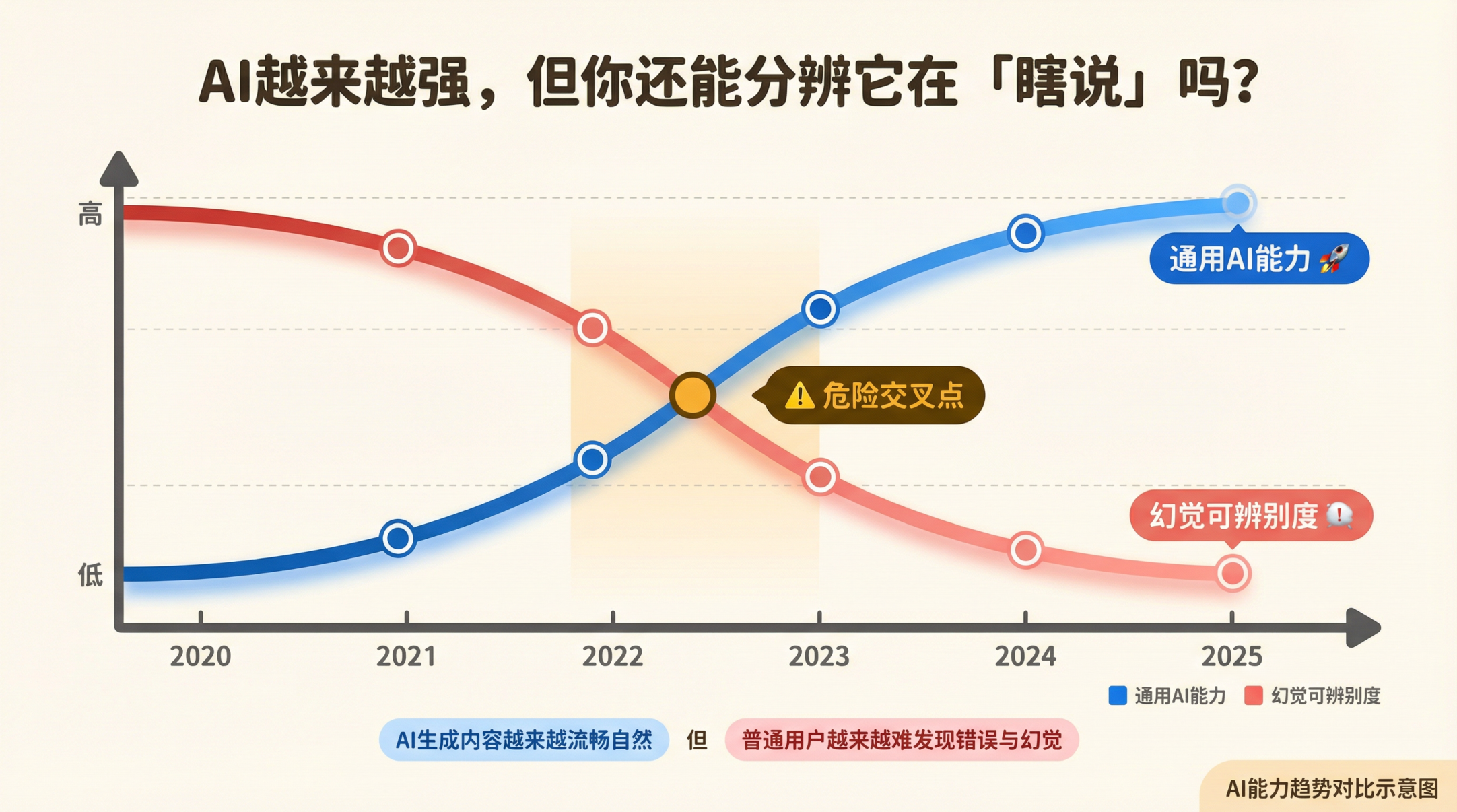
原因很反直觉:通用AI越强大,幻觉问题越难根治。
这听起来有点奇怪。AI不是越来越聪明了吗?为什么幻觉会越来越难解决?
因为大模型越大、训练数据越多,它就越擅长生成”听起来合理”的内容。一个小模型说错了,你一眼就能看出来,因为它说得磕磕绊绊。但一个超级强大的模型说错了,它说得流畅自然、逻辑自洽、引经据典,你很难发现哪里不对。模型越强,它的谎言越高明。
这就意味着,在通用AI越来越强大的背景下,”可验证性”这件事会变得越来越稀缺、越来越有价值。
NotebookLM通过引用溯源,给了用户一个完整的核查链条。它的每一条回答,都可以被追溯到原始文档的具体段落。这不仅仅是一个功能,它是一种对知识工作者的信任承诺:我告诉你的每一件事,你都可以去验证。
在AI生成内容泛滥、真假难辨的信息环境里,这种承诺的价值会越来越高。
从Google的战略视角来看,NotebookLM的这个定位也非常聪明。它不去和ChatGPT、Claude正面竞争”最强通用AI”的位置——那个赛道已经够卷了。它开辟了一条新赛道:面向知识工作者的专业AI研究助手,在这个细分场景里,用”可信度”建立起差异化竞争优势。
这条赛道有几个特点:用户粘性高(研究项目是持续性的)、付费意愿强(知识工作者愿意为提升工作效率付费)、竞争壁垒深(需要同时具备强大的RAG技术和清晰的产品哲学,两者缺一不可)。
这不是一个偶然的成功,而是一个想清楚了的战略选择。
反直觉的克制,往往是最深的壁垒
写到这里,我想回到最开始的那个问题:NotebookLM为什么要”主动放弃”通用AI的能力?
答案现在应该很清晰了。它放弃的不是能力,是”不可控的能力”。它选择的不是”更少”,是”更准”。它的克制,不是因为做不到更多,而是因为真正理解了用户在知识工作场景里最深的需求——不是一个什么都知道的助手,而是一个不会说谎的助手。
在AI军备竞赛的大背景下,几乎所有产品都在追求”更大更强”,NotebookLM的选择显得格外另类。但正是这种另类,让它在一个被忽视的维度上建立起了真正的竞争优势。
有意思的是,这个逻辑其实放之四海而皆准。产品力的核心从来不是功能的堆砌,而是对用户真实痛点的精准命中。有时候,做减法比做加法需要更大的勇气,也更难被复制。
NotebookLM告诉我们:当所有人都在追求”全知”的时候,选择”可信”,是一种更难但更持久的竞争策略。
那些选择”更精更准”而不是”更大更强”的产品,往往能在特定场景里赢得不可替代的位置。这不是一个关于NotebookLM的结论,而是一个关于产品设计哲学的普遍规律。
本文由 @小文_Arue 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供








这产品思路真清醒!反其道而行,用“有限但可信”戳中了知识工作者的命门。