
 起点课堂会员权益
起点课堂会员权益DeepSeek V4最大的遗憾
DeepSeekV4技术报告缺席的Engram模块引发业界热议。这个由DeepSeek与北大联合开发的记忆优化技术,本可让大模型实现知识直接查询而非重复计算,显著提升效率与性能。尽管未出现在V4中,Engram的理念已在CXL内存池化、视觉移植等方向开花结果,为下一代AI模型埋下伏笔。

DeepSeekV4的技术报告里有mHC,有CSA,有HCA,有Muon,有FP4……
唯独没有Engram。
Engram去哪了?
这个话题一度成为网友们讨论的热点。
Engram在今年1月由DeepSeek和北大联合开源,主要研究大模型的记忆与效率问题。
自挂上arXiv的那一刻起,圈子里围绕它的探讨就没有停止过…
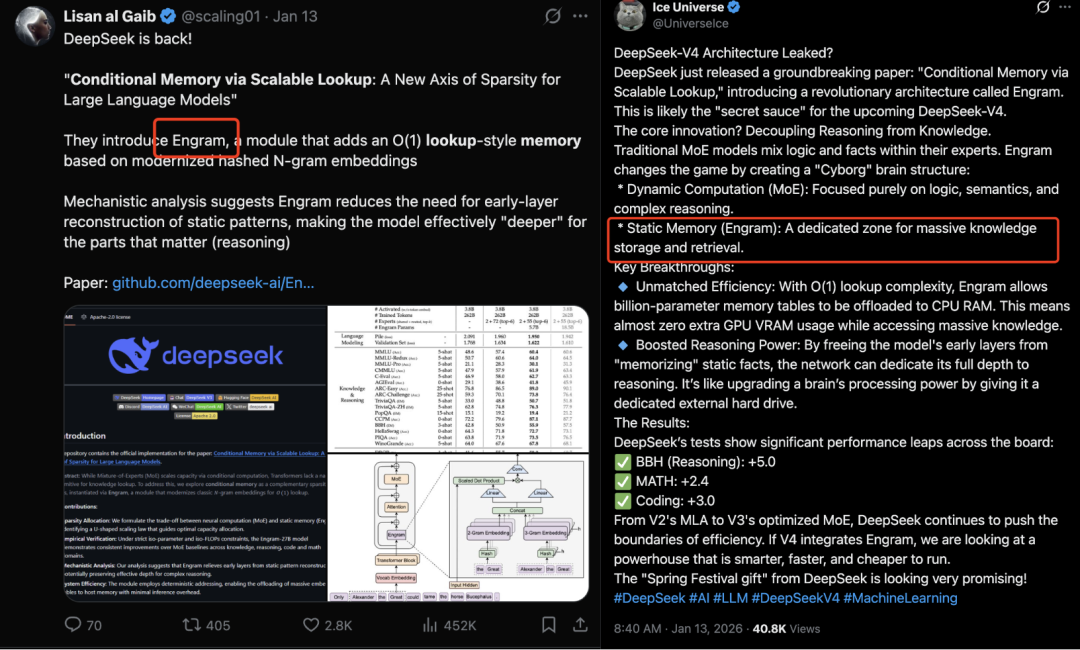
不仅仅因为它是V4的前奏,而是有了Engram,「伦敦是英国首都」这种事实,模型不用动用整个深层网络去重新推一遍,直接查就行。
不仅省显存,还能释放深层网络容量,用于更高阶的推理。
正因如此,自1月初论文发表以来,所有人都觉得,Engram就是V4的架构地基,所有人都在盼。
以至于V4发表后,大家第一时间就是command+f去论文里找Engram,可惜并没有。
以至于不少网友甚至觉得,没有Engram,V4就是不完整的。
没有Engram,可能是DeepSeekV4最大的遗憾。
不过,Engram并没有消失。随后三篇值得注意的论文接力出现:CXL内存池化版本:把Engram放进多机共享的CXL内存池,解决大模型多机部署的存储问题。无冲突热层实验:对Engram的多头哈希优化进行了实证检验,证伪了一些直觉式改进方案。视觉Tiny Engram:AutoArk团队把文本Engram搬到视觉模态,扩展了它的应用边界。
所以,虽然V4没有Engram,但它的理念、探索和后续应用已经悄然铺开,为下一代模型打下基础。Engram到底是什么
把时间倒回2026年1月12日。
那一天,DeepSeek联合北大放出了一篇33页的论文《ConditionalMemoryviaScalableLookup》。第一作者ChengXin,北大博士生,曾经署名过V3。最后一位作者,梁文锋。

先来一句话速通版,Engram是给Transformer加的一个原生知识查表模块。能查的别算,先查一下。
团队的核心观察是,语言建模其实包含两种性质完全不同的任务,一种是需要深度动态计算的组合推理,另一种是检索静态知识。
之前的问题在于,Transformer把这两件事混在一起做。模型识别一个实体时,得消耗好几层注意力和前馈网络逐层拼凑特征。
论文里举了个例子,「Diana,Princess of Wales」。模型要走6层才能把这个识别完。
前几层还在纠结「Wales是英国的一个地区」、「Princess of Wales是某种头衔」这些中间状态,最后一层才反应过来这是戴安娜王妃。
这种「用昂贵的运行时计算重建一个静态查找表」的活,本来可以让深层网络去干更高阶的推理。
对此,Engram的思路相当直接,既然经典的N-gram模型就能用O(1)的时间复杂度捕获这些局部依赖,那干脆把这能力直接嵌进Transformer。
打个比方,就像你做数学题,该用的公式不必每次从头推一遍,翻表代进去就行。Transformer之前没这张表,只能每道题都从公理走起。Engram等于把这张表交到模型手里。
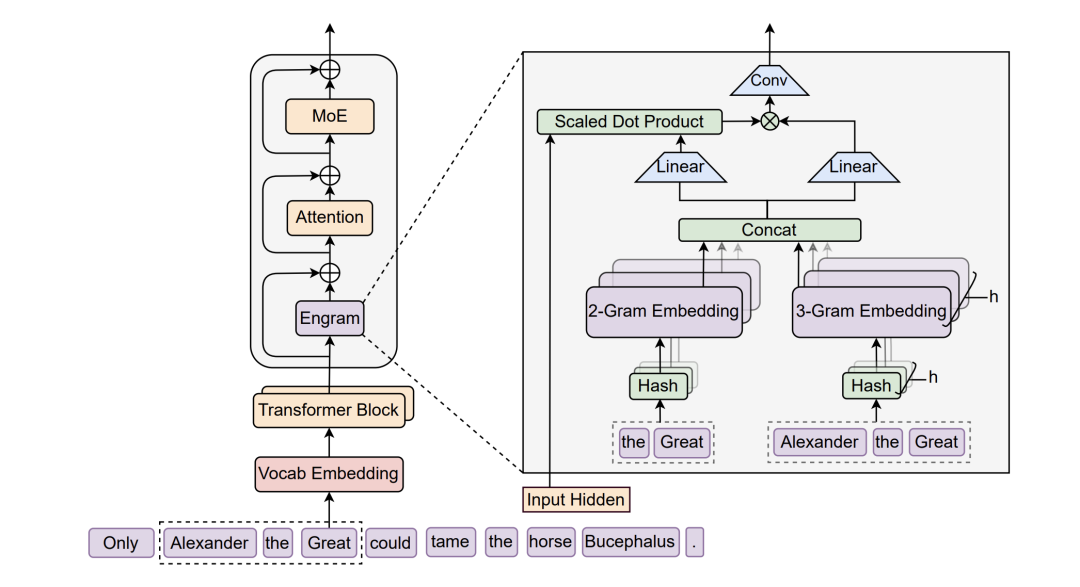
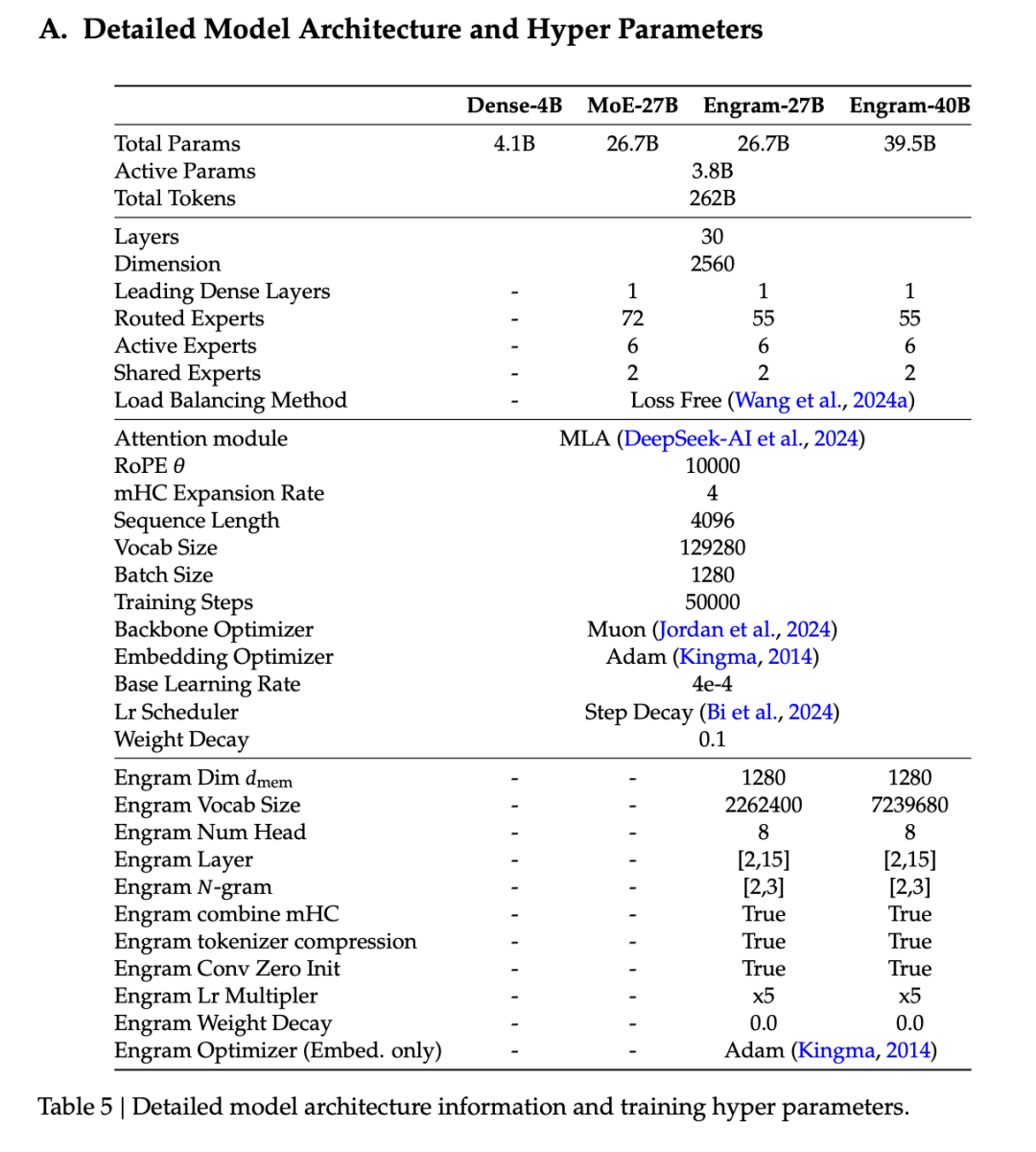
具体做法是,在Transformer的第2层和第15层之间各插入一个Engram模块。
每个位置的输入会触发一次哈希查找,把当前token和前面几个token组成的N-gram映射到一个巨大的嵌入表里,直接取出对应的向量。
门控机制保证查到的内容跟当前上下文不匹配时自动屏蔽。比如「张」是个常见姓氏,但「张仲景」三个字凑一起就是固定历史人物实体了,门控就负责认出这种区别。
Engram的定位是MoE之外的另一条稀疏轴。MoE是把计算稀疏化,只激活一部分专家。Engram是把存储稀疏化,只查一部分条目。两者互补,不冲突。
论文最核心的一段实验,是固定总参数和每token激活参数,然后让MoE专家和Engram记忆抢预算,得到一条U形曲线。
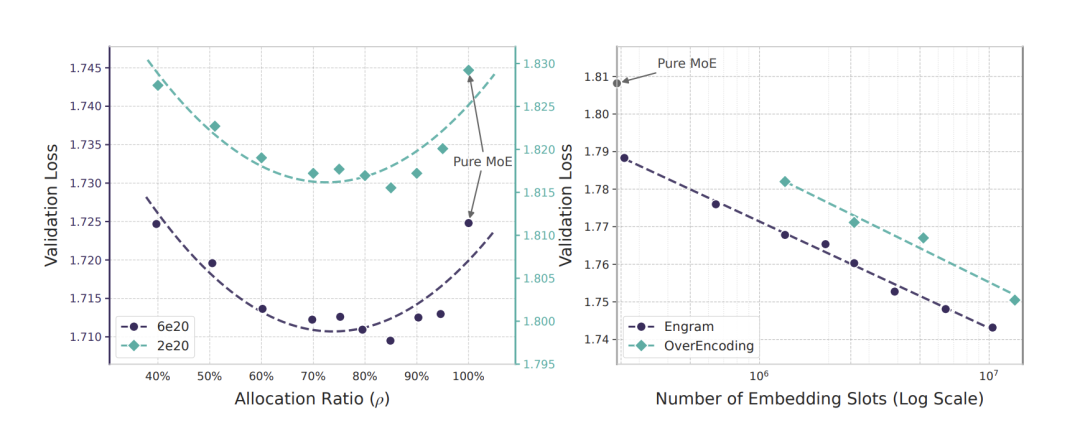
纯MoE不是最优解。把大约20%-25%的稀疏参数分给Engram,模型loss达到最低点。
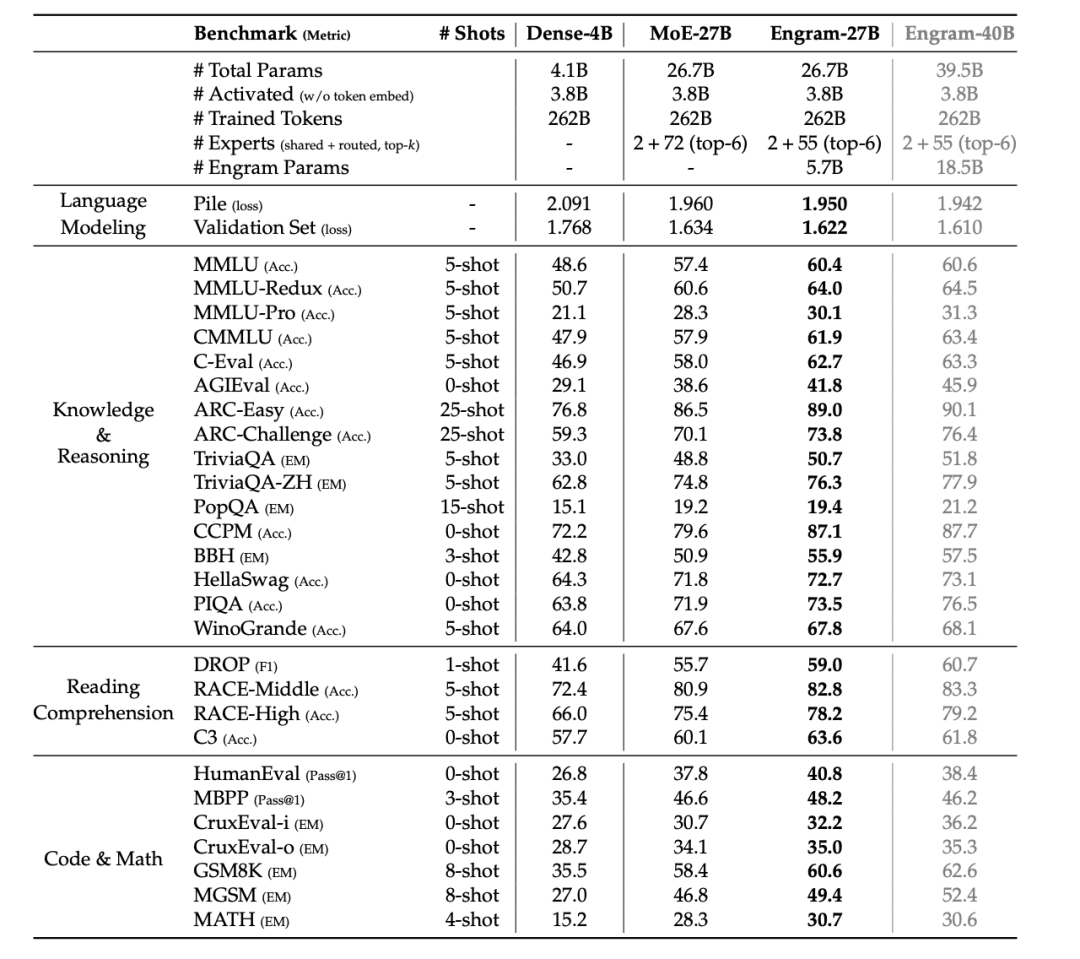
按这个曲线指导,团队把Engram扩到27B验证。激活参数3.8B,训练262B tokens,严格跟MoE-27B基线对齐。
结果知识密集型任务的提升符合预期(MMLU +3.4,CMMLU +4.0),但通用推理和代码数学的提升超出预期(BBH +5.0,ARC-Challenge +3.7,HumanEval +3.0,MATH +2.4),长上下文场景更夸张,Multi-Query NIAH从84.2%跃升到97.0%。
那么,为什么记忆模块还能反过来提升推理?
LogitLens和CKA给出了答案,Engram-27B第5层的表征,跟MoE基线第12层的表征最相似。
Engram把模型的早期层从「重建静态知识」这种苦力活里解放出来,这部分网络深度被腾出来做更复杂的推理。Engram不是新增了一块记忆,它还变相把网络加深了。
工程上。论文把一个1000亿参数的Engram表整个甩到host DRAM,在H800上跑推理,8B-Dense的吞吐损失只有2.8%。
靠的是Engram索引的确定性,只取决于输入token序列,完全可以提前算,CPU异步预取跟GPU计算重叠。
可以说,这个模块天生就不靠HBM,只可惜如今V4来了,Engram没来。没在v4,但在其他地方
发明者把它放在那里没动,但路上还是有人。三个月里,至少出现了三个值得说一下的工作。把Engram塞进CXL内存池
3月10日,北大、阿里云、山东英信、人大、港大联合发了一篇系统论文,《Pooling Engram Conditional Memory in Large Language Models using CXL》。

他们没改Engram本身,而是回答了一个更工程的问题,如果Engram真的成了下一代标配,内存放哪。
答案是CXL内存池化。GPU HBM放计算权重,本地DRAM做二级缓存,CXL池做三级。8台服务器共享4TB内存池,XConn XC50256交换芯片做拓扑,512GB/s带宽。
整套集成进SGLang,做了预取-计算重叠,跑下来端到端吞吐损失小于5%。Engram论文里那句「1000亿嵌入表卸载DRAM」的轻描淡写,被他们做成了27B和40B两个规模的真实测试。
结论很清楚,Engram这种确定性寻址、可预取的负载,几乎是为CXL量身定做的。一个反直觉的实验
Engram论文上线第十一天,1月23日,一个叫TaoLin的研究者,单作者,放出了《A Collision-FreeHot-Tier Extension for Engram-Style Conditional Memory》。

他想验证一个看上去显然的优化,Engram用多头哈希查表会有冲突,如果把高频N-gram用Minimal Perfect Hash Function完全消除冲突,模型会不会更好。
他设计了Engram-Nine,把记忆分成无冲突的「热层」和保留多头哈希的「冷层」。
结果反直觉。在严格iso-parameter控制下,无冲突设计没有稳定提升验证loss。
route-stratified评估还发现,训练初期热路径(高频)loss更低,但训练后期冷路径反过来超过热路径。
一个看上去显然的优化方向,被一个真做实验的人证伪了。把Engram推到视觉(AutoArk/TinyEngram)
GitHub上一个叫AutoArk的团队搞了Tiny Engram。

基于Qwen-3完整复现文本Engram之后,他们做了一件论文里没做的事,把Engram搬到Stable Diffusion上。
视觉patch经过分层编码,底层抓纹理,中层抓部件,高层抓风格,然后整套丢进哈希查表。
跟LoRA比下来,达到同等效果,Engram需要的额外参数只有LoRA的15%到30%。连续注入多个新概念时,LoRA会出现明显的概念退化,Engram不会。
Engram原本是为文本设计的。AutoArk等于把这扇门撞开了,凡是能离散化、能哈希的模态,Engram都能搬。
三个月里,Engram这条路上,发明者最沉默,跟进者各自走了一步。
一个团队替它解决多机内存层级,一个独立研究者证伪了它一个看似显然的优化方向,一个开源团队把它推到了视觉。
而deepseek-ai/Engram这个仓库,最后一次提交还停在1月14日。One more thing
Engram论文的摘要结尾有一句话:
我们认为条件记忆将是下一代稀疏模型不可或缺的建模原语。

看来,这个下一代得是V5了,难不成会是V4.1?
参考链接
[1]https://arxiv.org/pdf/2601.07372
[2]https://arxiv.org/pdf/2603.10087
[3]https://arxiv.org/pdf/2601.16531
henry 发自 凹非寺量子位 | 公众号 QbitAI
本文由人人都是产品经理作者【量子位】,微信公众号:【量子位】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


