
 起点课堂会员权益
起点课堂会员权益敏感数据的双刃剑:AI产业的机遇与挑战并存
在AI产业狂奔的时代,敏感数据正在成为决定产品生死的关键变量。从金融风控到医疗诊断,从个性化推荐到企业决策,那些最具价值的数据往往也最易触碰监管红线。本文将深度剖析敏感数据的三大热点基因,拆解AI产品中的典型数据困境,并给出从数据分级到安全闭环的完整解决方案。未来AI的竞争,不仅是算法之战,更是合规与信任之战。

在AI产业里,技术能不能跑起来,靠的是数据;数据能不能被大规模使用,靠的是合规;而合规里最容易引发争议、新闻、监管、舆情和商业机会的,就是敏感数据。
它天然具备三个“热点基因”:
- 足够高频:AI训练、画像推荐、智能客服、风控识别,都离不开用户数据。
- 足够敏感:一旦涉及身份证、手机号、定位、消费记录、健康信息,公众立刻警觉。
- 足够有产业价值:谁能把敏感数据处理得更安全、更合规,谁就更有机会把AI做大。
换句话说,未来几年AI行业的真正分水岭,不只是“谁模型更强”,而是“谁更会在合规边界内使用数据”。
一、为什么“敏感数据”会成为AI时代的高热主题?
在AI产品经理看来,AI产品的本质是三件事:
- 理解用户
- 预测行为
- 优化决策
而这三件事背后,几乎都要建立在数据之上。尤其是敏感数据,它往往比普通数据更接近真实世界,也更能提升AI效果。
比如:
- 智能金融风控,要看交易行为、设备信息、身份验证信息;
- 医疗AI,要看病历、检查结果、用药记录;
- 零售推荐,要看消费偏好、位置、历史购买记录;
- 企业AI助手,要看员工权限、内部文档、操作日志。
问题来了:越有价值的数据,越容易踩线。
这就是敏感数据最容易引爆热点的原因。
过去,很多公司会想当然地认为:“只要能把数据喂给模型,AI就会更聪明。”
但现在越来越多企业发现:“不是所有数据都能喂,能喂也不一定敢喂,敢喂也不一定能留住用户。”
二、敏感数据,到底敏感在哪里?
很多人一听“敏感数据”,第一反应就是“隐私”。
但从实际场景看,它比“隐私”更复杂。
一般来说,敏感数据可以分为几类:
- 身份类:姓名、身份证号、手机号、人脸信息
- 行为类:浏览记录、消费记录、点击路径、停留时长
- 位置类:GPS轨迹、常驻地、出行习惯
- 财务类:银行卡、支付记录、贷款信息
- 健康类:病历、诊断、体检、用药
- 组织内部类:员工绩效、权限、合同、审批记录
这些数据之所以敏感,不只是因为“不能公开”,而是因为它们一旦被串联起来,就能还原出一个人的完整画像。
比如:
- 你在某平台搜索了“离婚律师”,又在凌晨频繁查看贷款信息,再结合定位和消费记录,AI就可能判断你正处于高压、失眠、财务紧张状态。
这时候,数据已经不是数据,而是人。
也正因为如此,敏感数据进入AI系统后,会立刻引发几个现实问题:
- 是否得到授权?
- 数据是否被过度采集?
- 模型是否会反向泄露用户信息?
- 企业能否解释推荐和判断依据?
- 跨境、跨部门、跨系统流转是否合规?
这几个问题,决定了敏感数据不仅是一个技术问题,更是一个产品问题、法律问题、商业问题。
三、AI行业为什么离不开敏感数据?
很多AI产品做不起来,不是因为模型不够强,而是因为数据质量不够好。
而在真实业务里,最有价值的数据往往恰恰是敏感数据。
1)AI客服:越懂用户,越容易越界
举个很现实的例子。
一个银行的AI客服,如果知道用户最近频繁申请贷款、信用卡逾期、设备被更换,就能更准确判断用户意图,提升服务效率。
但如果系统在没有明确授权的情况下,把这些信息直接暴露给客服人员,甚至在对话中主动提及,就会迅速引发投诉。
用户会觉得:“我只是问个问题,怎么你连我最近借了多少钱都知道?”
这就是AI产品里最常见的矛盾:
个性化越强,惊喜越多;数据越深,风险越大。
2)AI推荐:越精准,越像“读心术”
推荐系统是敏感数据最典型的应用场景。
你看过什么、买过什么、停留多久、搜索了什么、在什么时间段浏览,AI基本都能推测出来。
这本来是提升体验的利器,但一旦推荐太精准,用户就会开始不安:
- “为什么它知道我最近在备孕?”
- “为什么我刚聊过的话题,马上就出现广告?”
- “为什么平台比我自己更了解我?”
当AI让用户感觉“被看穿”,商业价值和信任感就会同时增长或同时崩塌。
3)AI风控:最重要的数据往往最敏感
金融、支付、信贷领域尤其明显。
AI风控做得好,能降低坏账、识别欺诈、提升审批效率。
但风控模型里常常会用到:
- 设备指纹
- 登录地点
- 交易频率
- 关系网络
- 历史违约行为
这些数据组合起来非常强,但也最容易触碰监管红线。
尤其当模型决策不可解释时,用户就会问:“为什么拒贷的是我,不是别人?”
这时候,敏感数据就从“能力来源”变成了“争议来源”。
四、敏感数据时代,AI产品经理最该做什么?
作为产品经理,我越来越确信:
AI时代的产品能力,不只是“做功能”,而是“设计边界”。
一个成熟的AI产品,不应该只想着怎么多拿数据,而应该思考:
- 什么数据必须拿?
- 什么数据尽量不拿?
- 拿来之后怎么分级?
- 怎么脱敏?
- 怎么授权?
- 怎么留痕?
- 怎么在体验和合规之间找到平衡?
这其实是一套完整的方法论。
1)先做“数据分级”,再做AI应用
不是所有数据都要一锅端。
最好的做法是先分层:
- 公开数据:可直接使用
- 业务数据:需按权限使用
- 个人数据:需明确授权
- 敏感数据:需最小化采集、强审计、强保护
这样做的好处是,产品团队不会在一开始就踩进数据泥潭。
2)把“最小必要”作为默认原则
很多产品喜欢在注册时就要一堆权限:
手机号、定位、通讯录、相册、设备信息……
表面上是为了“提升体验”,本质上可能是为了“未来可能会用到”。
但AI产品时代,这种思路已经过时了。
真正可持续的产品,一定要遵循:
只采集完成任务所需的最少数据。
这样不仅更安全,也更容易建立用户信任。
3)把“可解释性”做成产品能力
很多人以为可解释性是算法团队的事。
其实不是。
对于产品来说,可解释性应该体现在界面、文案、流程、提示语里。
比如:
- 为什么需要这个权限;
- 数据用于什么场景;
- 会保存多久;
- 是否支持关闭个性化;
- 是否支持删除历史记录。
这些细节,决定了用户愿不愿意继续用。
五、AI产业里,敏感数据的“安全闭环”应该怎么做?
如果把敏感数据在AI中的使用流程画出来,大致会是这样:
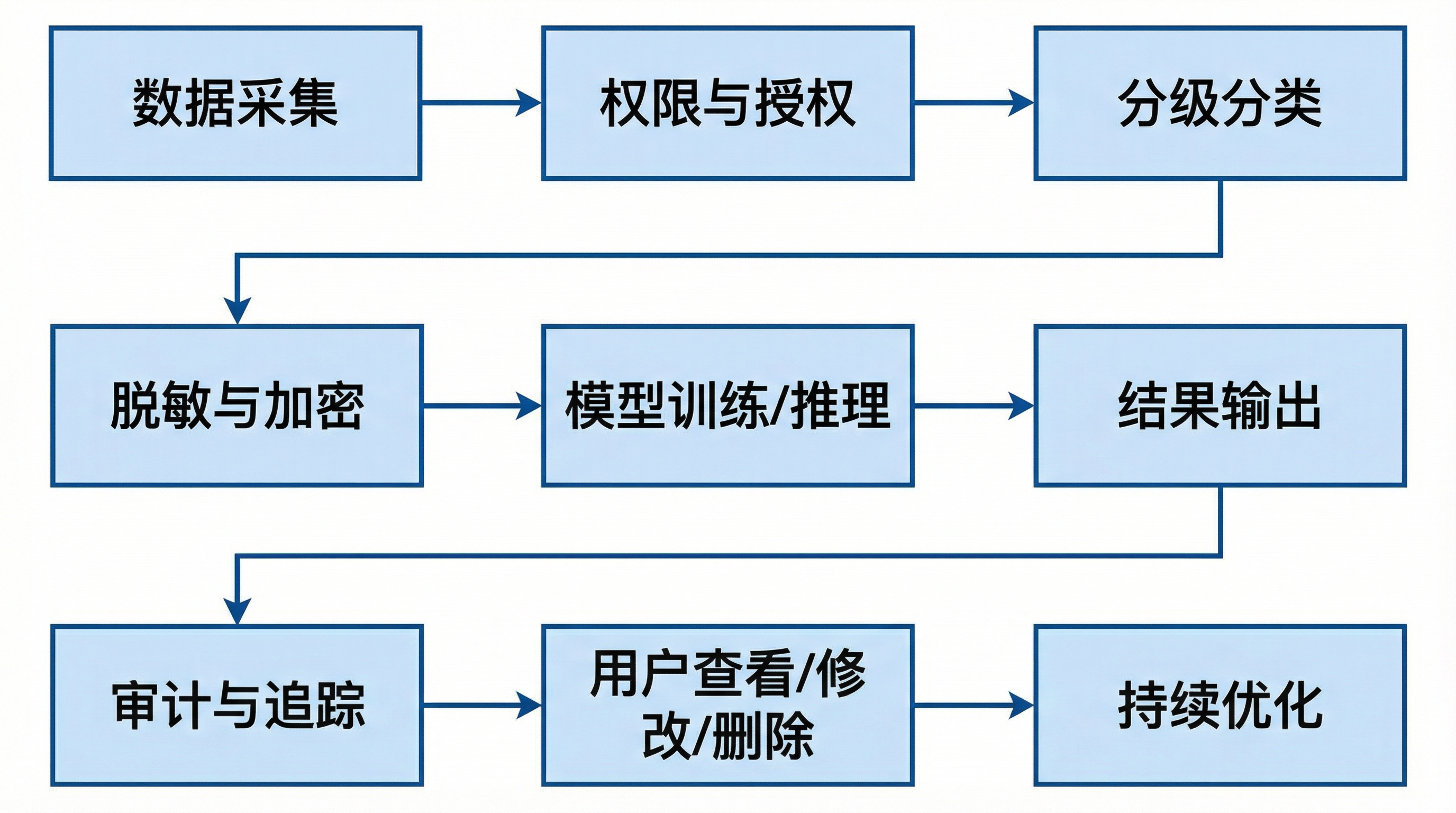
这条链路里,任何一个环节出问题,都会造成风险外溢。
我更建议把它理解为一个“闭环系统”:
第一步:采集前先问“为什么”
不要为了“以后可能有用”就乱采。
AI不是数据越多越好,而是有效数据越少越精。
第二步:授权要清晰
授权不能藏在长篇协议里。
要让用户知道:
- 你采什么
- 你为什么采
- 你怎么用
- 你能否关闭
- 你能否删除
第三步:分类分级处理
不同级别的数据,应该有不同权限、不同保存期限、不同访问审计。
第四步:脱敏、加密、隔离
敏感数据进入模型前,尽量做脱敏。
进入系统后,尽量做隔离。
涉及跨部门协作时,尽量做权限控制。
第五步:全链路留痕
谁看过、谁导出过、谁调用过、谁修改过,都要能追踪。
因为真正的风险,往往不是系统坏了,而是人“顺手”拿走了数据。
第六步:让用户能控制自己的数据
用户能查看、能撤回、能删除,才算真正尊重数据主体。
六、敏感数据与AI产业结合,真正的商业机会在哪里?
很多人一提到敏感数据,就只想到“风险”。
但站在产业角度,它其实也是一块巨大的机会市场。
1)隐私计算
让数据“可用不可见”,这是AI产业未来的重要方向。
例如联邦学习、可信执行环境、同态加密等,都是围绕这个思路展开的。
2)数据治理平台
未来企业会越来越需要“数据中台”升级成“数据治理中台”。
不是只管数据存储,而是管:
- 采集
- 分类
- 权限
- 审计
- 脱敏
- 生命周期管理
3)合规型AI产品
谁能把合规做成产品能力,谁就能拿下更多ToB客户。
尤其在金融、医疗、政务、教育等领域,合规不是附加项,而是准入门槛。
4)安全评估与风控服务
随着AI应用越来越深,围绕敏感数据的第三方评估、安全审计、攻防检测、算法合规咨询,也会成为新增量。
七、未来3年,敏感数据会带来什么变化?
我判断,接下来三年,AI行业会发生三个变化:
1)从“抢数据”转向“管数据”
过去拼的是谁拿到更多数据。
未来拼的是谁能更稳定、更安全、更合规地使用数据。
2)从“黑箱模型”转向“可解释系统”
尤其是涉及金融、医疗、政务等领域,AI不仅要能预测,还要能解释。
3)从“功能竞争”转向“信任竞争”
当AI能力趋同后,用户最终选择的,不只是最聪明的产品,而是最让人放心的产品。
这意味着,敏感数据不再只是后端问题,而会逐渐变成品牌问题、增长问题,甚至是生死问题。
八、真正的AI时代,不是“数据越多越好”,而是“边界越清晰越好”
如果说大模型时代让大家第一次意识到“数据决定模型能力”,那么敏感数据时代则会让大家第二次意识到:
数据决定能力,但边界决定能否长期生存。
未来最值钱的AI产品,不一定是最会“读懂用户”的产品,而一定是最会“尊重用户”的产品。
从这个意义上说,敏感数据不是AI产业的障碍,它更像是一道分水岭:
- 过不了这道坎,产品只是昙花一现;
- 过了这道坎,才有可能走向规模化、商业化和长期主义。
对于产品经理来说,这也是最值得重视的一件事:
不是把AI做得更强,而是把AI做得更稳、更合规、更可持续。
本文由 @砍椰 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


