
 起点课堂会员权益
起点课堂会员权益裸用 AI 的人和有「虚拟分身」的人之间差距只会越来越大
由于我的工作和数据模型训练深入打交道,我一直在想为什么不能把我所有的项目和SOP流程构建成自己的知识库呢?甚至说可以给模型一个全方位的我的自我介绍,构建出一个虚拟的我的本体呢?为什么把自己日常工作当作一个公司的项目构建相应的知识库?

很多人把 OpenClaw 的爆火理解为“自动化能力的提升”。但如果你真的深度用过一段时间,你会发现一个非常现实的问题:AI 并不会自动接管你的工作,它只会执行你明确教给它的流程。
换句话说:AI 的上限,不取决于模型能力 而取决于你是否有“结构化的工作方法”
现存的问题:AI不是不会做,而是不知道“你怎么做”
是不是经常在实际ai使用中,一个非常典型的低效场景是:
你知道怎么做这件事AI 也具备能力做这件事但你仍然需要反复解释……
本质原因只有一个:你的工作经验没有被结构化表达出来也是它没有真正的带入和理解你的项目
信息从来没有像现在这样廉价——公众号、播客、视频、AI 生成的内容,每天涌入的东西远超消化能力。但廉价的是信息,稀缺的是你自己处理过的经验和判断。
「大多数人对待 AI,就像对待一个失忆的临时工。打开聊天窗口,粘贴一些背景,收到回复,关闭标签页。下次?从头开始,重新介绍自己,重新介绍你的业务。那不是 AI 员工,那是一个有个性的搜索引擎。」
问题不在 AI 不够聪明,而在于你从来没给它任何可以记住的东西。AI 每次都是冷启动,你的经验、你的判断、你的工作方式——只活在你的脑子里,从未落地成文字。
我们可以把这个问题抽象成一个模型效果取决于:模型能力|上下文质量 |任务结构清晰度。
其中大多数人忽略的是后两项:
- 上下文:你是谁,你在做什么,你的标准是什么
- 结构:这件事到底分几步,每一步如何判断
而这两件事,本质上都依赖:个人知识库 +SOP流程
从“使用AI”到“管理AI”:角色已经变了
曾经我们只是把ai当作一个简单环节产出的文本的其中一部分,现在完全不是了,随着ai能力的强大和执行边界的延展和扩充现在是完全可以作为小助手的存在帮助我们全流程的完成任务,那我现在核心就是如何快速的让他理解并上手呢?

OpenClaw 这一类工具,本质上在推动一件事:
AI开始承担“执行层”,人开始上移到“调度层”
这就带来一个新的要求: 你必须具备“把工作拆成机器可执行结构”的能力,所以我非常建议从现在开始就开始构建逆子的知识库,像工作流程中构建SOP文档一样去构建你的“知识库”,可以理解把你自己复制出来做成虚拟的。
构建一个“可被AI调用的个人操作系统”
很多人对知识库的理解仍停留在“笔记工具”。但从 AI 视角看,它的本质是:
把个人知识库,从“记录工具”升级为“AI工作系统”
它至少要包含三层结构:

三层打通之后,会产生一个自动运转的记忆循环(Memory Loop):
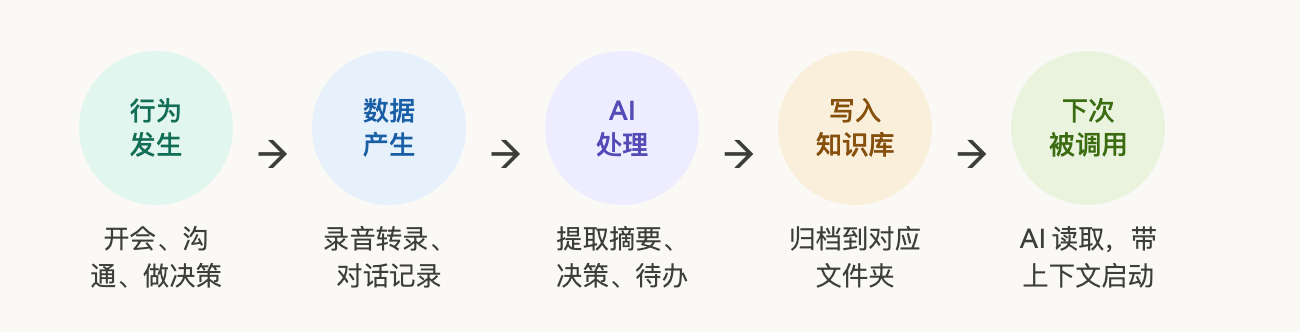
每次会议自动生成摘要 + 决策 + 待办,每个任务自动记录执行过程,每次对话自动沉淀结论——系统每天都在悄悄变得更懂你。
工具怎么选:按使用习惯来,别按功能来
工具没有最好,只有最适合。核心标准只有三个:打开够快、写起来顺、能被搜索到。
Obsidian
本地存储,双链笔记,数据完全自己掌控。适合有积累习惯、想长期经营个人知识图谱的人。可搭配 AI 插件直接调用笔记内容。
Notion
结构化强,数据库视图灵活。适合习惯用表格、看板来组织信息的人,Notion AI 可直接对库内文档提问。
语雀
阿里出品,中文体验优秀,支持层级化知识空间。适合国内用户日常文档沉淀,与钉钉生态集成顺畅。
腾讯 IMA
个人知识整理向,上传文档后可用自然语言提问检索。门槛低,适合刚开始建库、不想折腾配置的人。
Claude Code Pro
支持挂载本地 Skill 文件。你写的 SOP 和规则文档可直接成为 AI 的行为规范,执行任务时自动调用——最接近「数字分身」的用法。
如果什么都不想折腾:在本地新建一个文件夹,所有文档用 .md 格式存,用 Cursor 的 @ 功能引用,或直接复制粘贴给 AI。零门槛,今天就能开始。
如何搭出「真正可复用的知识系统」
很多人建了知识库,却停留在「收藏夹」阶段——存进去,再也没打开过。真正的跃迁,是让知识库活起来,让它产生复利。
这套系统有一个关键特性:它会随时间自动变得更聪明。
第 1 周:AI 了解你是谁、你在做什么——基础背景建立
第 4 周:AI了解你的客户、你的流程、你的沟通偏好,以及过去 20 次对话的结果
第 8 周:AI 开始主动提醒你忘记的承诺、标记逾期任务、连接你业务里分散的各个点
Step 1:搭一个基础知识库
/Memory(核心) /Projects /Clients /Actions /Templates
先写Memory文件(最重要):你是谁、你在做什么、你的工作方式和偏好——AI 的入职说明书
##
1. 我是谁
姓名:
所在地:
背景:
当前身份:
一句话介绍:我是一个 ___ 背景的 ___,目前主要在做 ___,核心目标是 ___。
##
2. 我在做什么
| 事项 | 状态 |
|——|——|
| | 进行中 |
| | 进行中 |
| | 暂停 |
| | 长期 |
##
3. 我的工作方式
决策方式:
思考节奏:
遇到模糊地带时:
##
4. 我希望 AI 怎么配合我
输出格式:
语气风格:
交互规则:
##
5. AI 需要知道的背景
专属术语:
| 术语 | 含义 |
|——|——|
| | |
| | |
行业默认假设:
AI 容易误解我的地方: 当我说 ___ 时,我指的是 ___,不是 ___
##
6. 我的工具
| 类别 | 工具 |
|——|——|
| 主力 AI | |
| 写作笔记 | |
| 项目管理 | |
| 沟通协作 | |
| 专业工具 | |
##
7. 不要做的事
##
8. 我的近期关注点
我在学:
我的信息资源:
我在观察:
我在思考:
Step 2:选一个数据入口,先打通最高价值的那条
知识库的内容从哪来?优先级从高到低:
会议记录(价值最高)——你每天开的会、打的电话、做的沟通,里面藏着决策、行动项、客户需求,是最容易被遗忘、也最值得沉淀的内容。把所有对话转成文本并存储,是最快提升知识库密度的方式。
硬件推荐:录音豆(而且小巧)、录音卡片等 AI 录音设备,开会时静默录音,结束后自动转文字并生成摘要,直接复制进知识库。比任何软件方案都顺手,成本也不高。
其次是:日常工作笔记、项目复盘、踩过的坑、反复用到的模板——这些都是低成本、高回报的积累素材。
Step 3:让 AI 能「读 + 写」你的知识库
光有文档还不够,关键是让 AI 真正连接到它。核心目标两个:
能读取知识库:在 Claude Projects 的 Instructions 里写一行指令:「回答任何问题前,先读取知识库中的相关笔记,用找到的内容来指导你的回答。」每次对话 AI 都会带着你的上下文启动。
能写入总结、决策、任务:用 Obsidian MCP(或手动粘贴)让 AI 把每次会话的结论、决策、待办事项,自动归档到对应文件夹。会议内容进 Projects,决策进 Actions,新发现的模板进 Templates。
做到这两点,知识库就不再是一个静态的文件柜,而是一个会自动生长的工作系统。
Step 5:每次做完一件事,更新知识库(哪怕只写 3 行)
系统的复利来自于持续的小动作,而不是偶尔的大整理。养成一个习惯:每次完成一件事,花两分钟记录:做了什么、结论是什么、下次要注意什么。
哪怕只写三行,也比什么都不写强。知识库的价值不在于它有多完整,而在于它有多「活」。
怎么搭运转:五个动作
搭建个人知识库不需要一套完美的系统,只需要五个持续发生的动作:
收集——随手捕捉,不筛选
遇到有价值的东西就记,不要等「想清楚了」再写。一句话的感悟、一个解决方案的思路、一个让你意识到什么的场景——先存下来,不求完整。
整理——定期消化,打上标签
每周或每隔几天,把收集到的内容过一遍,归类、加标题、打标签。这一步的核心不是「整洁」,而是让你下次能找到它。
关联——连接已有的知识
新内容和旧内容有没有联系?和你正在做的某个项目相关吗?主动建立连接,知识才会从一堆孤立的点,变成一张互相支撑的网。
回顾——定期重读,发现新意义
三个月前写下的东西,今天读可能有完全不同的感受。定期回顾不是为了「背诵」,而是让旧知识在新情境下被重新激活。
输出——用出来并且赋能工作,才算真的会了
写文章、做汇报、给 AI 发指令——当你把知识库里的内容「用出去」的时候,它才真正变成你的东西,也才能发现哪里还有缺口需要补。
最后
你在构建的,其实是一个越来越懂你的工作伙伴。
工具人人都有,但你的知识资产是独一份的。你写下的每一份 SOP、每一条判断规则、每一个处理过的场景——都是在告诉 AI 你是谁、你怎么思考。
用原文的话说:「那不是聊天机器人,那是幕僚长。」
不需要等准备好了再开始。今天完成一件事之后,花五分钟写下来。就这样。
本文由 @LULAOSHI 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供,由AI生成






- 目前还没评论,等你发挥!


