
 起点课堂会员权益
起点课堂会员权益Claude Code源码泄露事件背后,是一场关于AI时代「护城河」的深度追问。
2026年3月,AI安全领域爆发了一场震撼行业的大事件——Anthropic旗下的Claude Code源代码通过npm包中的.map文件意外泄露。512,000行核心代码、1906个文件,完整暴露了这款AI编程助手的工具执行逻辑、权限系统与未发布功能。这不仅是一家安全公司的尴尬事故,更是对整个AI Agent时代安全架构的拷问:当代码不再是护城河,我们该怎样重新定义信任?

就在2026年3月31日,AI安全圈炸了。
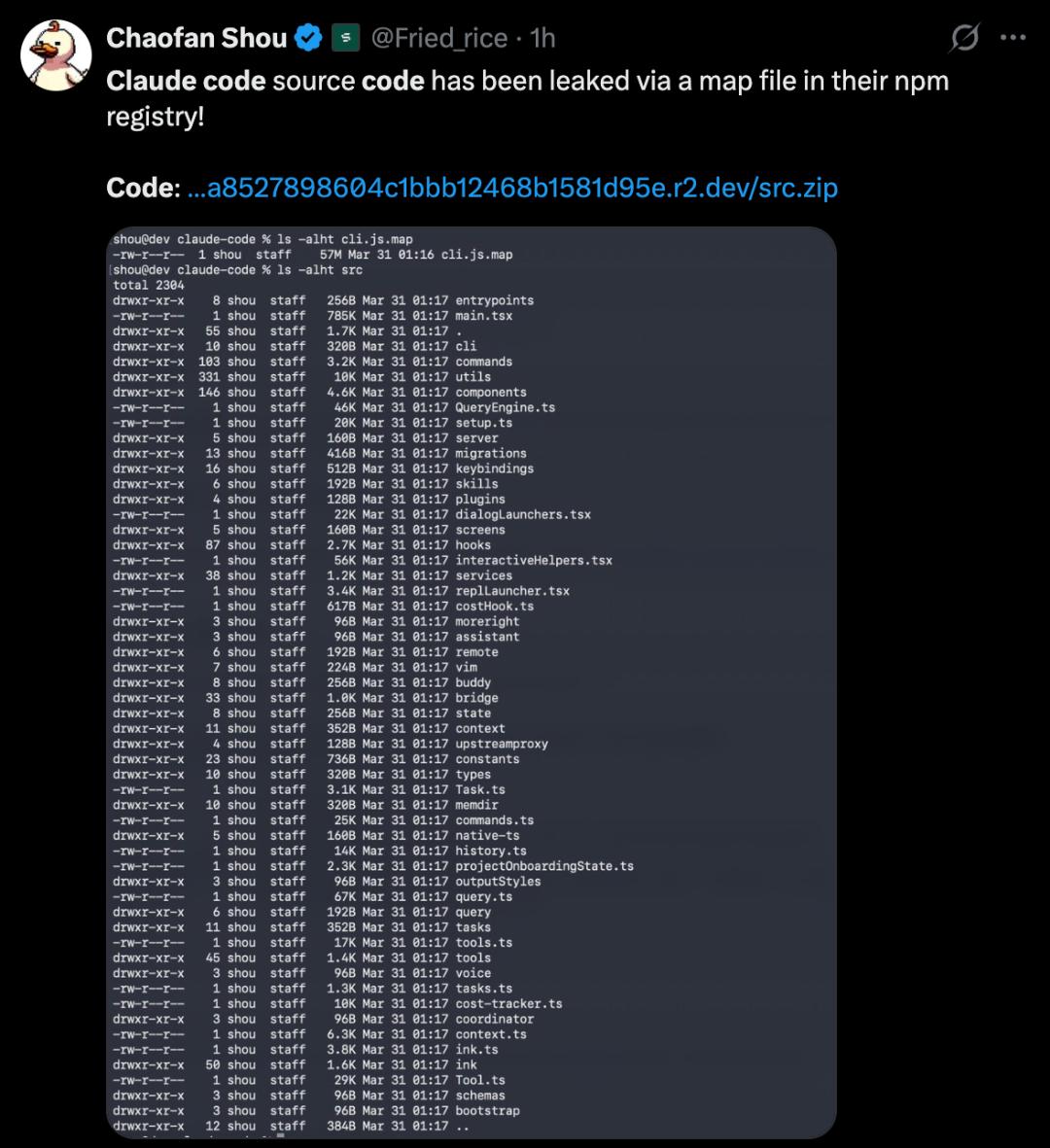
安全研究员Chaofan Shou在X上发出一条简短的帖子:”Claude code source code has been leaked via a map file in their npm registry!”(Claude Code源码已通过npm注册表中的map文件泄露!)随后,整个AI开发者社区进入了一种奇特的混沌状态——一部分人在震惊,一部分人在狂欢,还有一部分人已经在GitHub上飞速开叉,把512,000行TypeScript代码据为己有。
这次泄露通过npm包中的一个错误配置发生:在最新版本的@anthropic-ai/claude-code包中,一个庞大的source map文件提供了对公开Cloudflare R2存储桶的直接访问,其中包含完整的、未经混淆的TypeScript源代码。泄露的代码涵盖1,906个文件,将内部API、工具编排逻辑和权限系统全数暴露在公众视野之下。
这不是小事。这是一起将在AI行业史上留名的事故。
一个.map文件,怎么搞垮了整个防线?
要理解这次泄露的荒诞,需要先了解”source map”是什么。
在现代JavaScript/TypeScript开发中,源代码在发布前通常会被编译和压缩,变成人类几乎无法阅读的混淆代码。Source map是一种调试工具,它建立了”压缩后的生产代码”与”原始可读源代码”之间的映射关系,让开发者在调试时能看到清晰的代码行号和变量名。
这种文件的本意是在开发环境中使用,绝不应该出现在生产发布包里。但Anthropic就这么做了。
这次事件的核心机制在于:一个公开可访问的.map文件出现在了已发布的npm包中,这种文件本应只用于帮助开发者调试JavaScript,却意外地成为了重建整个源代码的路线图。任何人只要找到这个文件、点击其中的URL,就能直接从Anthropic自己的R2存储桶下载完整的、注释完整的TypeScript源码。
根据公开证据,与这次事件相关联的是@anthropic-ai/claude-code版本2.1.88,这个版本标注发布日期为2026年3月30日。也就是说,这个”炸弹”在公众发现之前已经在npm注册表上挂了将近一天。
更令人窒息的是:这标志着类似问题的再次发生——早在2025年2月,该包的早期版本就已经暴露过source map。Anthropic不是没犯过这个错,而是犯了两次。
泄露了什么?一个产品级AI Coding Agent的全部秘密
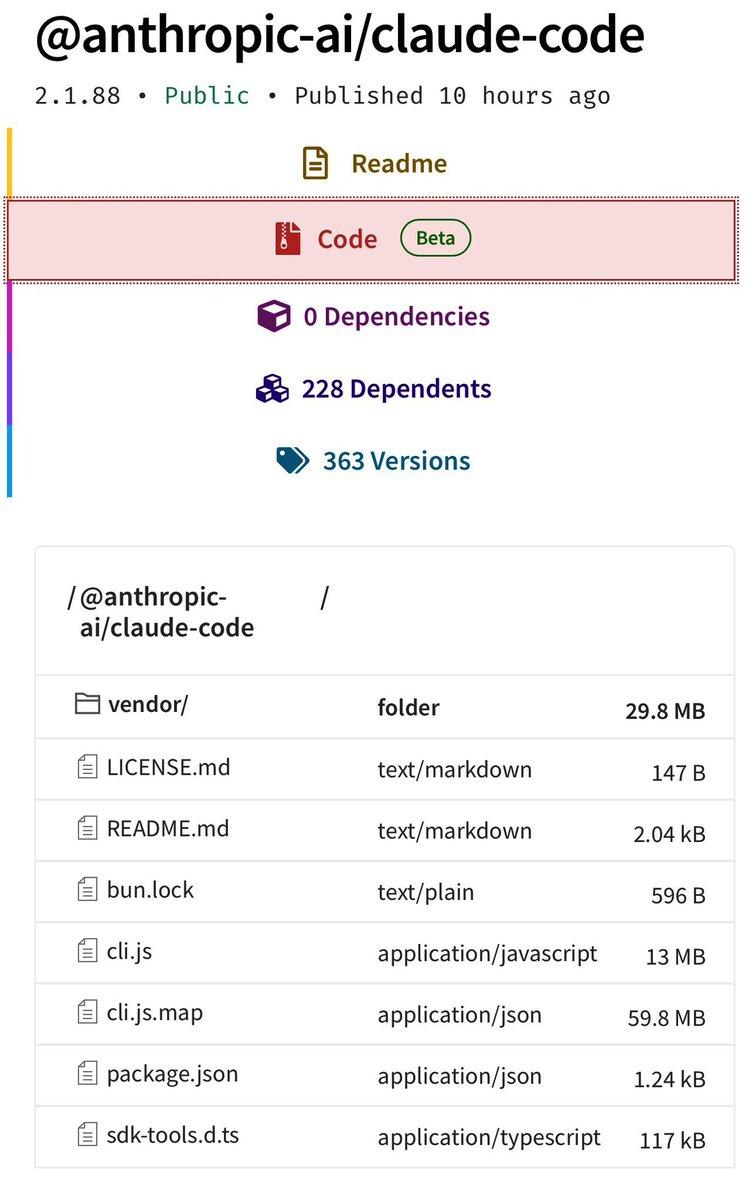
泄露的内容包括完整的TypeScript源代码——512,000行,1,900个文件。对于AI行业的竞争者和研究者而言,这不亚于拿到了一份完整的工业蓝图。
具体来说,泄露内容涵盖了以下几个核心层面:
- 工具执行逻辑:Claude Code如何处理bash命令、文件读写、git操作,每一个工具的触发条件、输入验证和错误处理方式,全部暴露。
- 权限与安全机制:泄露内容包括完整的权限绕过和审批流程,以及管控安全的系统提示词。这是最敏感的部分——相当于把一套银行金库的密码锁设计图公之于众。
- 上下文压缩策略:一个三层压缩机制被完整曝光:MicroCompact(不触发API调用,直接本地编辑缓存内容)、AutoCompact(接近上下文窗口限制时触发,保留13,000 token缓冲,生成最多20,000 token摘要,内置3次失败后停止重试的断路器)、以及Full Compact(将整个对话压缩为摘要,然后重新注入最近访问的文件)。这套架构设计是解决长对话AI应用的关键工程之一,现在任何竞争对手都可以直接学走。
- 遥测钩子:Anthropic如何收集用户使用数据、哪些行为会被记录上报,全部可见。
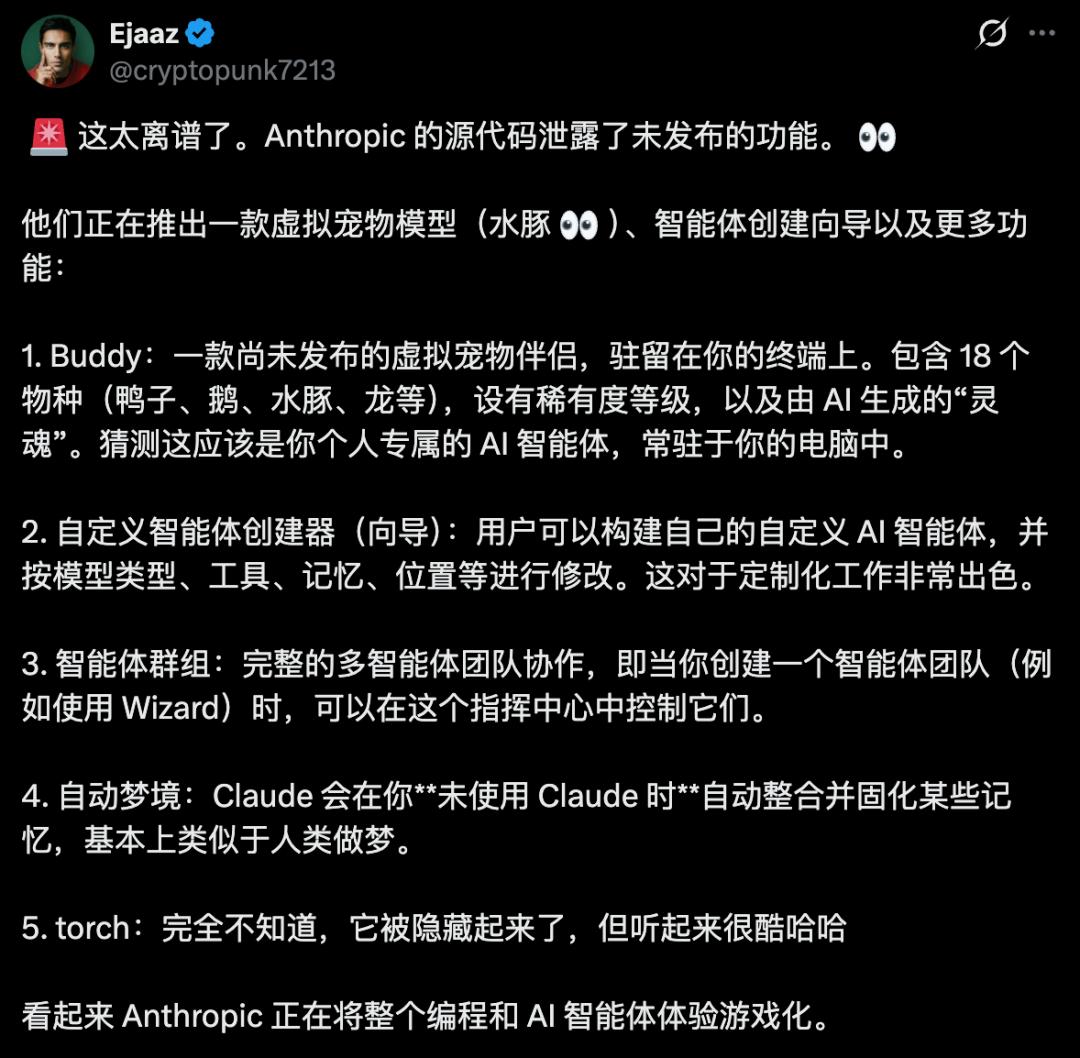
- 未发布功能路线图:源码中甚至藏着一个名为BUDDY的彩蛋——一个类似电子宠物的数字伴侣系统,有稀有度等级、闪亮变体、程序化生成的属性,锁在一个编译时特性标志后面,预定在2026年4月1日至7日进行预告,5月正式发布。
这最后一条信息透露出一个冷酷的现实:这次泄露不仅仅是代码本身,而是整个产品战略的时间表。
Anthropic的双重尴尬:安全公司的安全事故
这次事件之所以在行业内引发格外强烈的反应,原因不仅仅是技术层面的失误,更在于它打在了Anthropic最引以为傲的身份标签上。
Anthropic长期将自己定位为竞争对手(如OpenAI)的安全替代方案,其品牌信息强调负责任的AI开发和宪法训练。该公司甚至开发了Claude Code Security模块,专门帮助企业识别AI安全漏洞。当前这次泄露,源于一个基本的打包错误,与其精心培育的品牌形象形成了鲜明对比。
换言之:一家卖安全的公司,因为一个小学级别的npm打包失误,把自己的底裤晒在了互联网上。
更糟的是,这似乎不是孤立事件。这已是Anthropic五天内的第二次泄露。仅在五天前的3月26日,一次CMS配置错误就已经暴露了未发布的”Claude Mythos”模型细节、草稿博客文章和3,000个未发布的资产。
两次事故,五天之内,一个是内容管理系统,一个是npm包管理。这不是随机发生的意外,这是组织内部工程流程和发布安全管控存在系统性问题的信号。
当一家公司把”AI安全”作为核心卖点,却接连出现这种初级失误时,外界有理由追问:这家公司的内部安全文化到底怎么了?
对竞争格局的影响:知识壁垒消失了
Claude Code不是一个普通的产品。它是Anthropic的重要收入驱动器,据报道支撑着公司年运营收入的相当大一部分。换言之,这是Anthropic的现金牛之一,而现在这头牛的培育手册已经被人拍照上传到GitHub了。
这对竞争格局意味着什么?
短期影响:逆向工程成本归零。任何一家想要构建竞争性AI编程助手的公司(无论是Cursor、GitHub Copilot、还是中国的通义灵码、文心一言系列),都可以从这512,000行代码中系统地提取工程智慧。上下文压缩策略、工具调用设计、权限模型——这些都是需要大量试错才能打磨出来的工程经验,现在可以直接借鉴。
中期影响:安全漏洞面的扩大。这次泄露的真正危险在于,一旦大家都知道了Claude Code的实现细节,那些历史上存在于”预信任初始化”和”提示词边界”边缘的高价值攻击面,就变得更容易被研究和利用。安全研究员和恶意攻击者都会从这份代码中寻找可利用的模式。
长期影响:护城河迁移。这次事件以最激烈的方式证明了一个正在被越来越多人讨论的观点——在AI工具领域,代码本身不再是护城河。真正的护城河是用户数据、工作流集成深度、和品牌信任。这三样东西,Anthropic今天都受到了不同程度的损伤。
开发者社区的撕裂:欢呼与恐慌并存
有意思的是,这次事故在开发者社区引发的反应并非一边倒的批评。
网络反应从幸灾乐祸到兴奋不一,开发者们热衷于研究一个生产级AI编程代理的架构设计。社区的普遍共识似乎是,广泛获取Claude Code的架构最终是有益的。代码现在已经永久可用,GitHub上的分支正在迅速增殖。
这揭示了AI工具领域的一个深层矛盾:用户(开发者)和厂商对”开放”的期待根本不在同一频道上。
开发者天然倾向于透明。他们想知道工具是怎么工作的,想审计权限模型,想评估遥测数据的范围。当一个封闭工具被意外开放,很多开发者的第一反应不是恐慌,而是:终于能看看这东西到底在干什么了。
这种反应对Anthropic其实是一个信号:与其被动地被”强制开源”,是否有必要重新思考Claude Code的开放策略?完全开源可能不现实,但更透明的架构文档、更详细的安全审计报告、或者选择性开放某些组件,或许才是建立真正开发者信任的正确路径。
反观OpenAI的Codex系列和Google的Gemini Code Assist,它们同样是封闭产品。但在这次事件之后,开发者对”黑盒AI工具”的信任成本显然更高了。
对AI Agent安全的根本性拷问
如果说品牌危机是这次事件的表层影响,那么它对AI Agent安全领域的深层影响才是真正值得长期关注的议题。
Claude Code的历史上,真正的风险往往存在于”预信任初始化”和”提示词边界”边缘,比如CVE-2026-21852所示的ANTHROPIC_BASE_URL环境变量漏洞,可以让Claude Code在显示信任提示之前就发起请求,从而泄露API密钥;以及CVE-2025-59828所示的Yarn相关代码在目录信任建立之前就执行的问题。
这些漏洞的共同特征是:它们存在于”用户以为安全”和”系统实际上还未建立信任”之间的那个危险窗口里。
当Claude Code的完整实现细节暴露之后,任何想要研究这类漏洞模式的人,门槛都大幅降低了。Check Point Research此前发现的通过恶意仓库配置实现远程代码执行的漏洞——攻击者可以通过Hooks、MCP服务器和环境变量等各种配置机制,在用户克隆并打开不可信仓库时执行任意shell命令并窃取Anthropic API密钥——现在有了更完整的实现细节作为攻击图谱。
这个问题的本质不是Anthropic一家的问题。它指向了整个AI Agent时代的安全架构困境:
当AI工具被深度集成进开发环境,获得了读写文件、执行命令、访问网络的权限,它就不再是一个”对话界面”,而是一个拥有相当系统权限的自主代理。传统的软件安全模型是建立在明确的信任边界上的——用户信任软件,软件信任操作系统。但AI Agent打破了这种模型:它同时接受来自用户、来自代码库、来自外部MCP服务器的指令,而这些指令来源的可信度是完全不对等的。
如果一个恶意仓库可以通过.claude/settings.json注入指令,那么”我信任Claude Code”和”我信任任何Claude Code处理过的代码库”就变成了完全不同的两件事。这一区别,在源码泄露之前,只有少数安全研究员在认真讨论。在泄露之后,它将成为所有企业用户必须面对的采购审查问题。
透明度悖论:安全靠隐藏,还是靠设计?
这次事件最后引出了一个经典的信息安全哲学争论:安全应该靠”隐藏实现细节”来维持,还是靠”设计本身足够健壮”来保证?
传统软件安全界有一个被广泛接受的原则——”安全不应依赖于隐藏”(Security through obscurity is not security)。真正安全的系统,即使攻击者完全了解其实现细节,也应该无法被轻易攻破。
Anthropic的困境在于:他们的部分安全机制,尤其是权限审批流程和系统提示词,其有效性在某种程度上确实依赖于用户不知道具体实现。当这些细节被暴露,攻击者的针对性攻击成本就下降了。
但另一方面,这次泄露也提供了一个罕见的机会,让整个安全社区能够审计Anthropic的实现,发现此前未知的漏洞,以更快的速度推动修复。在开源安全模型中,”更多眼睛意味着更少漏洞”是经过实践验证的原则。
这两种逻辑都不是错的。真正的问题是:Anthropic从未选择开放,这次是被迫的。被迫的开放不能带来主动开放的信任红利,却要承受全部的竞争损失。这是最坏的结果。
对整个行业的结构性启示
把这次事件放在更宏观的AI产业语境中,它揭示了几个值得深思的结构性矛盾:
其一,AI公司的工程成熟度与估值之间存在严重落差。Anthropic估值数百亿美元,但一个npm打包流程的基础错误就造成了如此巨大的伤害,而且是第二次。这不是在苛责一家公司,而是在指出一个行业现象:AI公司的估值主要来自于模型能力和市场想象力,而工程基础设施的成熟度往往被大幅高估。
其二,”AI安全”品牌的溢价是脆弱的。Anthropic在市场上最独特的定位就是”负责任的AI公司”。这个定位值钱,但也极度脆弱——一次安全事故的破坏力,远大于它在技术领域的实际损失。这对所有把”安全”和”负责任”作为核心叙事的AI公司都是警示。
其三,AI编程工具的竞争将进入新阶段。在这次泄露之前,Claude Code、Cursor、GitHub Copilot的技术实现对彼此而言都是黑盒。现在其中一个盒子被打开了。这会加速趋同,也会逼迫竞争者更快地在差异化方向上下注——不是架构设计,而是用户体验、生态集成、和企业信任体系。
其四,MCP生态的安全标准亟需建立。随着AI驱动的开发工具迅速整合进软件工作流,它们引入了传统安全模型尚未完全应对的新型攻击面。那些曾经是被动数据的配置文件,现在控制着主动执行路径。当Claude Code、Cursor、VS Code Copilot都在拥抱MCP协议时,MCP服务器的信任模型和权限边界需要一套行业级的安全规范,而不是各家公司各自为政。
结语:当护城河失守
这次Claude Code源码泄露事件,在表面上是一次初级的运维失误。但在更深层,它是AI行业高速扩张期的一个缩影——资本涌入、估值飙升、品牌溢价极高,但工程基础、安全文化、和发布流程的成熟度,并没有同步跟上。
代码现在已经永久可用,互联网不会遗忘。
对Anthropic来说,接下来几周要做的不仅是修补npm包,而是要在整个工程组织内重建一套发布安全规范,更要向企业客户清晰地解释:你们的数据安全、API密钥、和工作流权限,是如何与这次泄露的实现细节相隔离的。
对整个AI行业来说,这次事件提出了一个比代码更重要的问题:在AI工具深度嵌入生产环境的时代,”信任”到底应该建立在什么之上?
不是隐藏,不是模糊,而是设计本身的健壮性,和透明度带来的可验证性。
那一天,可能比我们预期的来得更快——只需要一个.map文件。
本文由 @秋叶的枫 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


