
 起点课堂会员权益
起点课堂会员权益钉钉、飞书集体转向 CLI,MCP 已死、GUI 要出局了?
钉钉、飞书集体转向CLI,引发“MCP已死、GUI出局”的讨论。本文拆解三者本质:MCP解决接入问题,CLI解决动作问题,GUI解决人的理解与确认问题。当执行者从人类变成人类+Agent,系统能力需要一种可组合、可参数化的动作层。

最近经常听到的两句话是:
1.MCP 已死,CLI 才是王道;
2.如果你的系统还在 GUI 上打转,没有跟进 CLI,那么你将被淘汰;
这两句话并不是空穴来风,因为喷 MCP 的人是一些大佬,比如 YC 的 CEO、Perplexity 的 CTO;
然后就是无论钉钉还是飞书,都在进行全面的 CLI 转型:
但这两句话却需要分开理解,关于 MCP 与 CLI 的选择是工程问题、关于 CLI 和 GUI 的变化是个发展问题。
而导致这些变化的核心原因都是一个:Agent 想要完成工作必须完成的前置工作。
所以,这个 CLI 到底是个什么玩意,MCP 是不是个淘汰产物,GUI 哪里又招惹了 CLI,全部都会涉及一个探索性问题:
1.AI Agent 到底应该通过什么方式连接世界?
2.人类一个个如何与 AI 交互、AI 应该如何与电脑交互;
先说结论
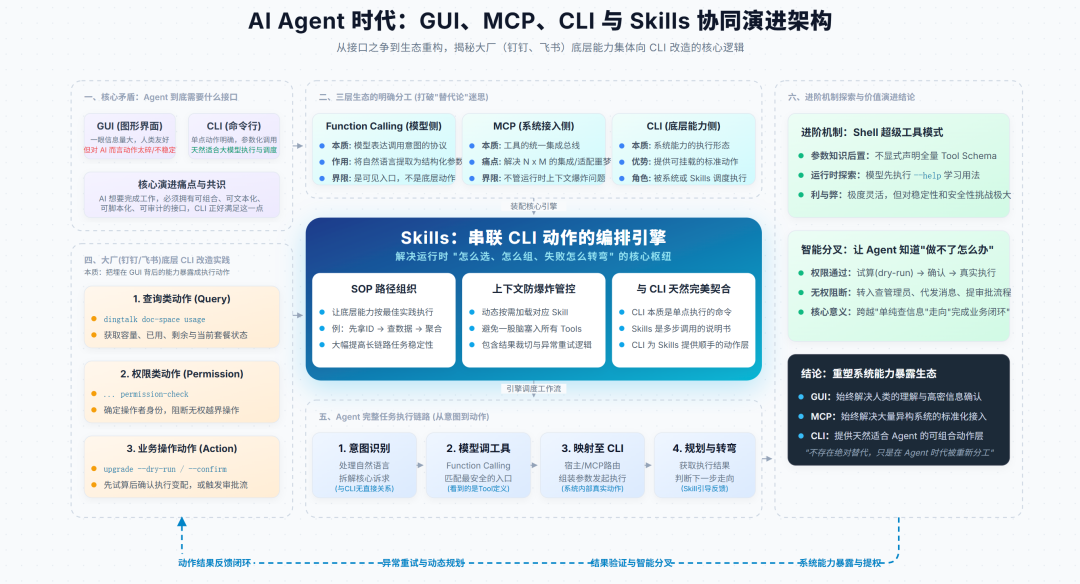
这里可以先说结论,从工程落地、组织效率、工具复用、跨平台能力和长期生态演进来看:
CLI 也不是唯一答案,但它正在成为当最好的答案
原因很简单:Agent 天然更适合调用可组合、可文本化、可脚本化、可审计的接口,CLI 正好满足这一点。
所以真正的比较,不该停留在黑窗口 vs 图形界面这种表层争论,而应该上升到三个更关键的问题:
1.对 Agent 来说,什么样的接口最容易理解和执行?
2.对企业来说,什么样的接口最容易治理和复用?
3.对生态来说,什么样的接口最容易扩展和沉淀?
沿着这三个问题往下看,你会发现:
1.CLI 比 GUI 更适合作为 Agent 的执行层
2.CLI 比 MCP 更适合作为 Agent 的通用能力载体
3.但 CLI 问题也很大,尤其在权限一块不好处理
接下来,让我们更系统的描述,将 CLI、MCP、GUI 之间的爱恨情仇说清楚。
什么是 CLI
如果只从字面上理解,CLI 就是 Command Line Interface,也就是命令行界面,比如黑客帝国里面的界面:

黑客帝国
严格来说,CLI 是一个能力暴露方式,GUI 也是,只不过他是用界面(按钮)来承载 API,所以无论GUI 还是 CLI,都不是界面问题,而是系统接口问题。
进一步,根据我们这批程序老登的回忆,早期稍微优秀点的服务端程序员对 CLI 这套都很熟,只不过这是生存技能,不是爱好。
之前服务器多是 Linux 系统,只要上服务器搞点什么事情,全部是命令行,如图所示:
只不过当程序员被迫习惯 CLI 后,又发现这东西真香,因为效率挺高的(但这并不能改变 IDE 才是主流的趋势),比如:
你想找出某个日志文件里包含 ERROR 的行,按时间排序,只取前 10 条,存成新文件。在 CLI,一行命令搞定:
grep “ERROR” app.log | sort | head -n 10 > top_errors.txt
WIndows 桌面,使用 GUI 界面的话,就会有很多“消耗”操作,打开文件、复制粘贴等。
在这个基础之下,我们再来说下在 GUI 环境下 AI 交互的问题:
GUI 的问题
GUI 其实没什么问题,他就是适应于人类习惯而生的产物,比如这里的钉钉:
他完美符合我们的习惯:信息量大,常用功能一眼看完,指哪打哪:
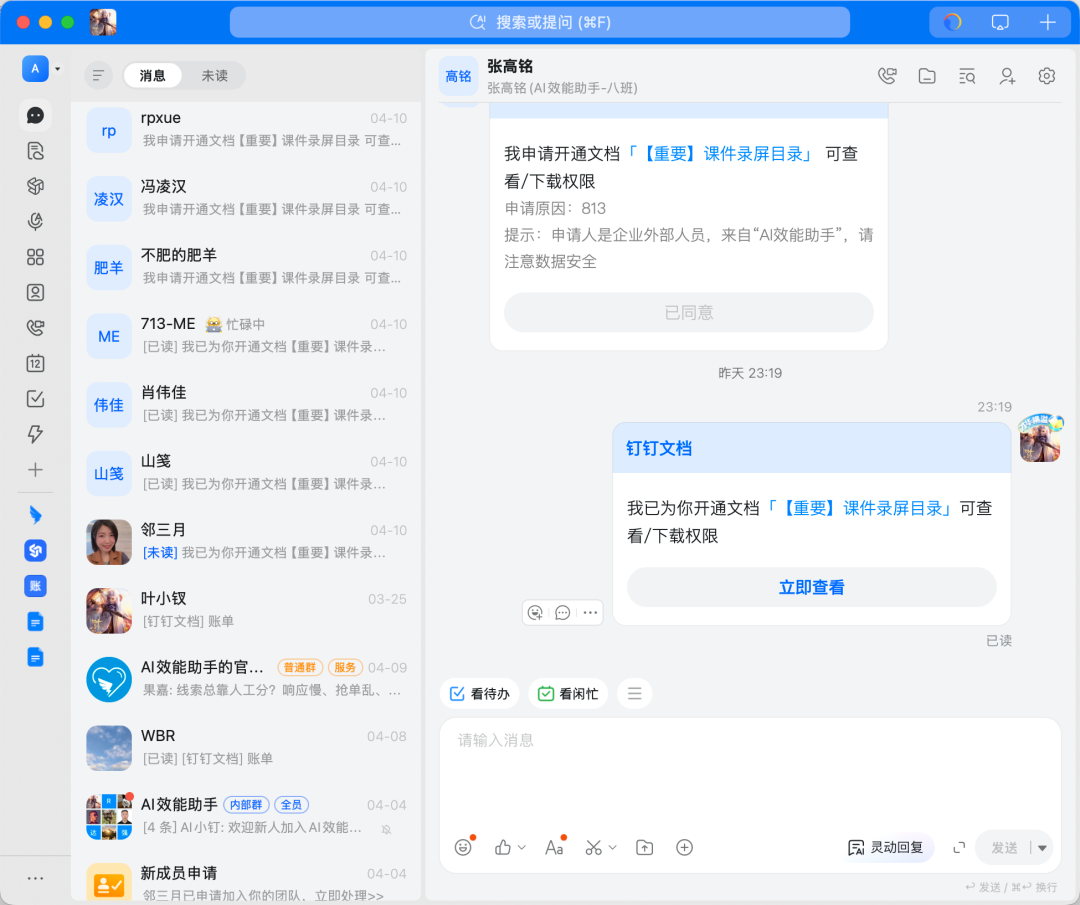
但你如果要让 AI 去操作钉钉这个 GUI,那就非常容易出问题,且不说 UI 老是变,就现阶段的技术来说,稳定性也极差!
其实很多平台当前在做 CLI 改造,多少都有点因为 Computer-Use 和 browser-Use 不行
比如你在 GUI 里点击一个按钮,看起来只是点了一下,但按钮背后其实往往对应着一个具体动作:
1. 查某个日历;
2. 发一条消息;
3. 导出一份文档;
4. 压缩一个视频;
5. 同步一批数据;
6. 查询一个订单;
7. …
GUI 把这些动作包装成了页面和按钮,这对我们来说很爽,但这对 AI 来说很不爽,因为他太多了!
AI 的目标很原子,执行的任务很单一,他们不需要那么大的信息量,于是乎 CLI 就出现了,CLI 做的事情,是把这些动作重新还原成可以直接调用的“命令”:
calendar list –date tomorrow
message send –to zhangsan –text “会议改到三点”
doc export –input report.md –format pdf
没什么本质变化,无论 GUI 还是 CLI,都是:把原本藏在软件内部的能力,变成一种可以被人、脚本、Agent 直接调用的标准动作。
如果非要说得细点,GUI 里的每次点击,到了 CLI 里就变成了:
1. 一个明确的动作;
2. 一组明确的参数;
3. 一个明确的执行结果;
从工程视角看,CLI 的本质不是命令行,而是:
一种把系统能力结构化、参数化、可调用化的接口形式
所以,从 CLI 这次再次出现的初衷就可以看出是跟以前不同的,这次真的只是想要更适应于 AI 的喜好。
更进一步,GUI 本来对人类是极其友好的,核心原因是一眼信息量大嘛,只不过逐渐问题发生变化了:
平台方想给的太多,GUI 软件的信息量远远超出我们能接受的极限,于是真实情况是:我们可能只使用了系统不到20%的功能,并且有更多的需求往往无从着手
比如这个界面,你们谁看得懂:
从这个角度出发,CLI 的意义就非常大了,他能帮我们把剩下不常用的 80% 记住并搞定!
至此,我觉得应该是把 GUI 的问题说清楚了,还是那个点,这东西当然有用,只不过我们需要的往往只是 20%,微信这块一直就做得挺好。

接下来,我们回归 MCP 与 CLI 的问题:
MCP 的价值
如果今天直接说 MCP 不行,其实也不公平。
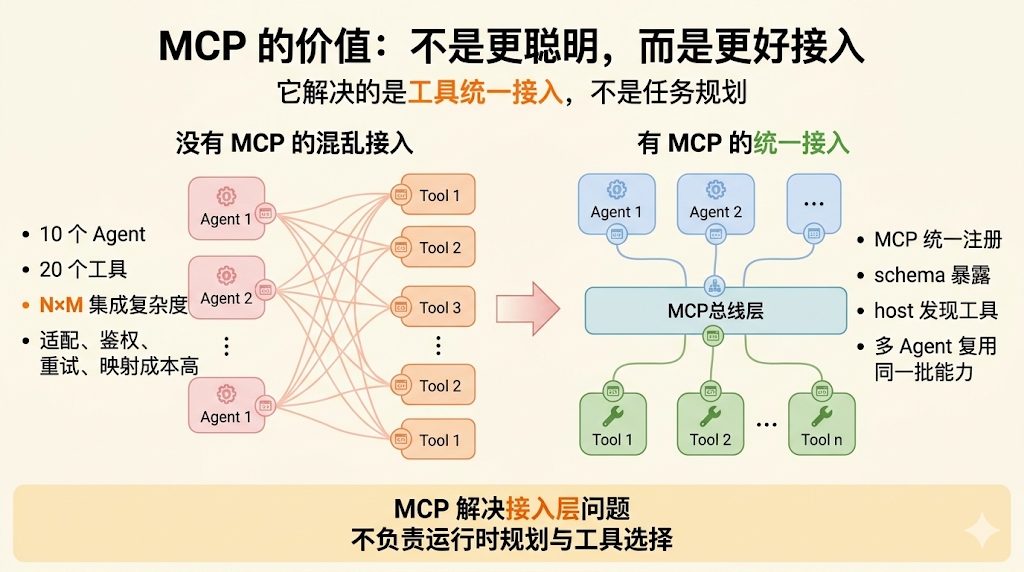
因为 MCP 当初能火,不是靠营销火的,而是真的解决了一个很现实的问题:Function Calling 在工具少的时候很好用,但工具一多,维护成本会非常夸张。
这里的背后是工程维护的问题,我之前举过一个很典型的例子:企业里有 10 个 AI Agent,需要接入 20 个数据源/工具。
如果每个应用都为每个工具单独写适配代码,那就会出现 N×M 的集成点。
这个事情看上去只是一个乘法,但在工程里它意味着:
1. 每个工具接口改一下,要排查多少个 Agent 在用;
2. 每个模型的 tool schema 不同,还要做额外适配;
3. 每加一个新系统,不只是加一个 API,而是还要处理参数、鉴权、重试、映射、降级;
所以 MCP 的诞生,不是为了让 Agent 更聪明,而是为了让工具集成这件事别那么烦人。
也就是说,MCP 从来都不会管工具是不是把上下文撑爆了、模型调用工具又是不是稳定了这种破事,这些是你 Agent 工程该解决的事情,管我 MCP 什么事?
所以,在我看来也非常奇怪:MCP 对应的是接入层问题,CLI 对应的是执行层问题。
这两个东西虽然挨得很近,但不是同一层。很多人现在讨论 MCP 和 CLI,容易直接把它们理解成替代关系,仿佛只要 CLI 出现了,MCP 就应该立刻进垃圾桶。
我有时候真的很疑惑:难道是我理解错了?还是那些大佬在装?
在这个基础下,我们继续:
CLI 才是答案?
这里就要进入核心矛盾了。 MCP 虽然解决了接入层问题,但它并没有真正解决 Agent 最头疼的那部分问题:
1. 工具太多了之后,怎么选;
2. 选了之后,怎么组合;
3. 结果太多了之后,怎么裁;
4. 调用失败了之后,怎么搞;
5. 同一个任务涉及多步动作时,怎么把过程组织起来;
只不过,这些事情貌似功劳最大的应该是 Skills 这个工程解法。
这里就挺重要的,如果不说清楚 Skills 的价值,后面就容易把概念搞混:
Skills 的价值
前面我们已经说了:
MCP 本身并不关心工具怎么被用好,他只关心工具怎么被统一接入;
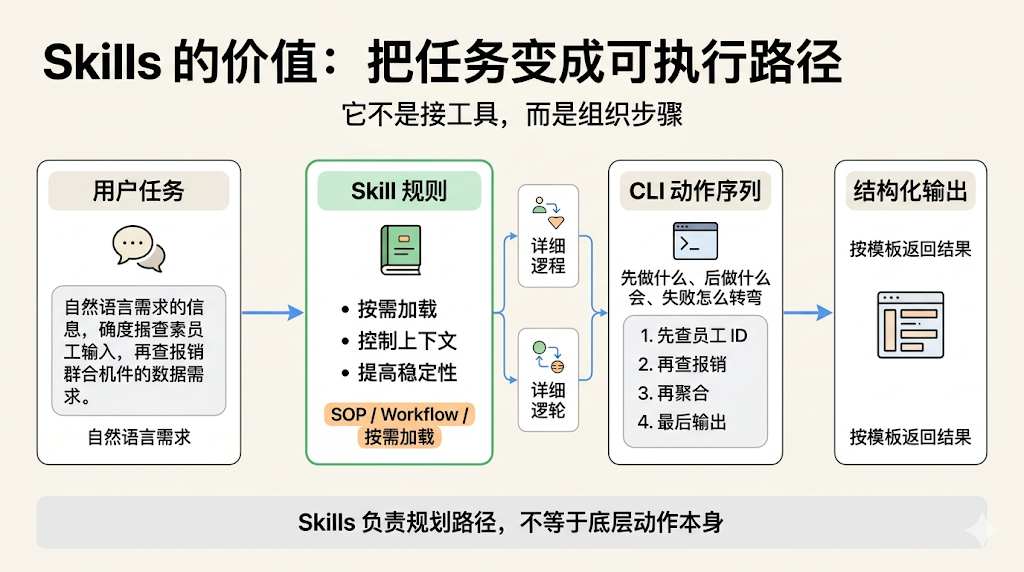
而 CLI 本身也不负责告诉模型这个任务应该先干什么后干什么,它只是把系统能力暴露成一个个更适合执行的动作单元。
中间这块的执行路径是 Skills 干的,他的按需加载首先解决了 Tools 定义过多导致的上下文爆炸;其次他将 SOP/Workflow 装入提示词,大大提高了任务执行的稳定性
CLI 的价值
讲到这里,一个自然的问题就出来了:
既然这些运行时问题主要是 Skills 在解决,那为什么现在越来越多人还是会说 CLI 更像答案?
这里就得把 CLI 的角色再说细一点。
前面我们已经说过了,CLI 本质上是把系统能力暴露成一个个可执行动作。
注意这里的关键词是:动作
而 Skills 恰恰也是围绕动作来组织 SOP 的。比如一个 Skill,不太会写成:
1. 先理解 14 个工具 schema;
2. 再自己组合;
3. 再自己从一堆平铺定义里思考怎么组织;
它更自然的写法一定是:
1. 先执行哪个动作;
2. 再执行哪个动作;
3. 如果失败,换哪个动作;
4. 如果结果过大,取哪几个字段;
5. 最后按什么结构输出;
从这个角度出发,大家就会发现这套表达天然更适合落在 CLI 上。因为 CLI 的世界里,本来就是:
1. 一个命令代表一个动作;
2. 一个子命令代表动作的细分;
3. 一组参数代表动作边界;
这玩意儿一摆出来,Skills 就很好写了。因为它可以非常自然地组织成一条任务路径:
1. 先拿员工 ID;
2. 再查报销;
3. 再按项目聚合;
4. 最后按模板输出。
employee get –name 张三
reimbursement query –employee-id 123 –start 2025-12-08 –end 2025-12-14
reimbursement summarize –group-by project
也就是说,CLI 本身没有解决 SOP 问题,但它让 SOP 的承载形式变得特别自然。
所以我认为,CLI 的价值不是替 Skills 干活,而是:给 Skills 提供了一个比 MCP 更顺手的动作层。
这也许才是现在大家越来越觉得 CLI 更像答案的底层原因。
CLI、FC、MCP
这里就要继续往深一点拆了,不然虽然前面已经把 CLI、MCP、Skills 的职责边界分了一次,但还有两个问题没有彻底说透:
1. CLI 和 Function Calling 里的工具,到底有什么本质区别?
2. 如果 CLI 这么好,那是不是就不需要 MCP 了?
这两个问题如果不回答,大家就很容易陷入一个误区:
不都是给模型调工具吗?那 CLI、FC、MCP 到底是在换皮,还是在换层?
所以这里我想把这三者一次性说透:
1. Function Calling 是模型侧的调用协议
2. MCP 是系统侧的接入协议
3. CLI 是能力侧的执行形态
Function Calling 是什么
Function Calling 大家已经非常熟悉了,他是一种模型和宿主程序之间的沟通方式,常见定义如下:
{ “name”: “get_weather”, “arguments”: { “location”: “北京” }}
MCP 是什么
MCP 解决的,不是模型怎么表达调用意图,而是:工具本身,怎么被大规模、统一地接进 Agent 系统里。
MCP 关心的是:
1. 工具怎么注册
2. schema 怎么暴露
3. host 怎么发现工具
4. tool provider 怎么接进平台
5. 不同 Agent / 模型怎么复用同一批工具
所以 MCP 更像一个 tool integration bus,是 Agent 平台生态扩展的重要部分。
CLI 是什么
CLI 则完全不一样。
CLI 解决的不是怎么说要调工具,也不是工具怎么接进平台,而是:
系统能力本身,最终以什么形态被暴露出来,供人和 Agent 真正执行
CLI 关心的是:
1. 动作怎么命名
2. 参数怎么组织
3. 输出怎么返回
4. 子命令怎么分层
5. 一步步动作怎么被串起来
CLI 更像一个 action interface。

混淆点
它们之所以容易让人混淆,是因为表面动作很像。比如用户说一句:
帮我查一下张三上周的报销总额
这时候系统里可能发生了三件事:
第一层:模型通过 Function Calling 表达意图
{ “name”: “reimbursement_query”, “arguments”: { “employee_name”: “张三”, “period”: “上周” }}
这一步是 FC 在工作。
第二层:宿主程序通过 MCP 找到这个工具
宿主程序拿到 Function Calling 返回的工具名后,在已经接好的 MCP 工具里找到对应项,再把参数转发过去执行。
第三层:整个任务的内部是如何执行的
Skills 会把查张三上周报销
这件事拆成一条更完整的执行路径,比如:
1. 先获取员工 ID;
2. 再解析“上周”的时间范围;
3. 然后查询报销记录;
4. 再按项目汇总;
5. 最后按模板输出结果;
而在这条执行路径里,CLI 更像一组被 Skills 调度的标准动作接口,真实执行会是这样的:
employee get –name 张三
time parse –text 上周
reimbursement query –employee-id 123 –start 2025-12-08 –end 2025-12-14
reimbursement summarize –group-by project
具体在 Skills 文件里面他可能长这样:
# 原始参数比如姓名由模型提取,id类餐宿需要程序里面拿
使用 employee get 根据员工姓名获取 employee_id
整体关系应该理清楚了:
1. Function Calling 解决的是模型怎么表达调用意图。
2. MCP 解决的是能力怎么被统一接入系统。
3. Skills 解决的是任务怎么被规划成可执行步骤。
4. CLI 解决的是这些步骤最终以什么动作形态被执行。
综上,诡异的事情就出现了:在很多现实工程里,如果 CLI 不是宿主环境天然可用的,它也必须靠某种“接入机制”被 Agent 看见和调用;这个接入机制可以是 MCP,也可以不是 MCP。
这两东西,压根不是一个维度…
所以,答案已经很清晰了:MCP 没死,是因为它解决的问题仍然存在。
而 CLI 关注的是具体执行:一个既适合人,又适合 Agent,还能被 Skills 顺手组织起来的动作层。
至此,各位按道理说应该搞懂了,但以防万一,我这里最后再提供一个案例做说明:
虚构一个钉钉案例
我平时一般只使用钉钉聊天和钉钉文档,但现在我遭遇了一个问题:文档空间快满了,系统提醒你处理。
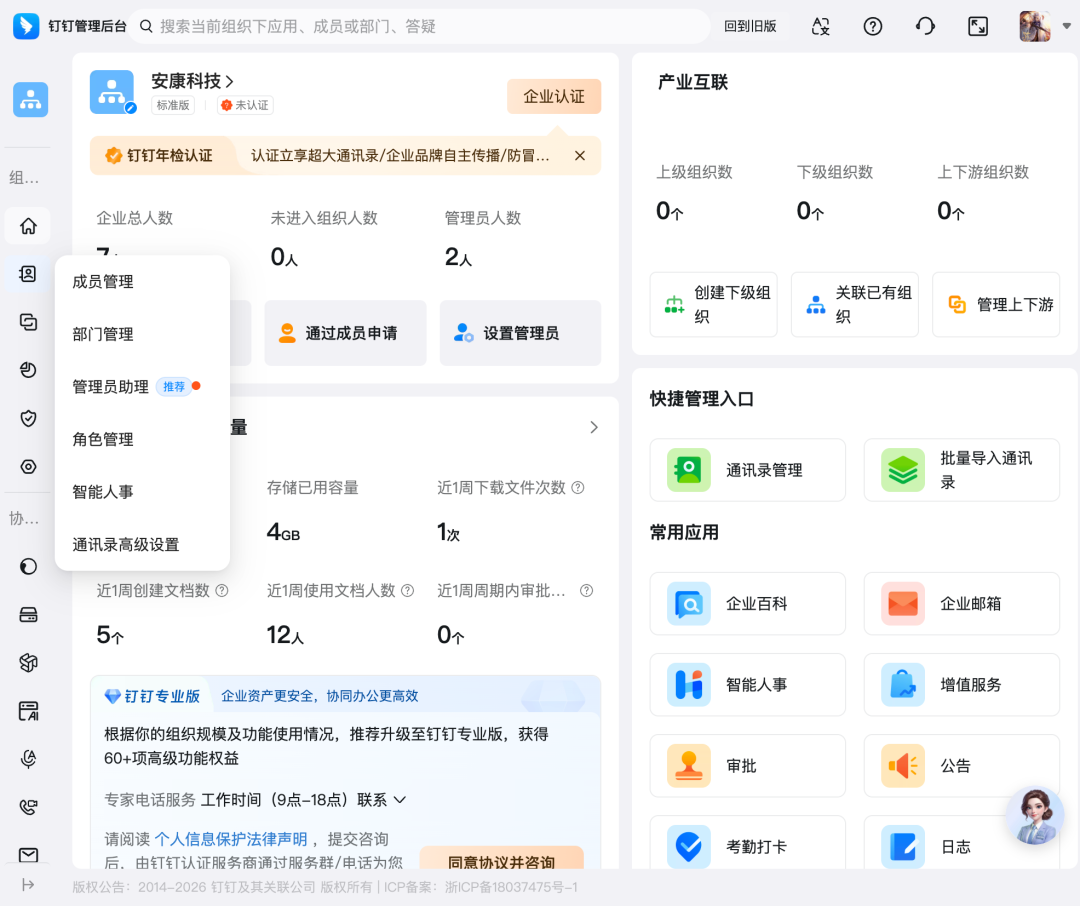
现在系统并没有弹出充值页面,所以要升级需要进入巨复杂无比的后台,也就是这个界面:
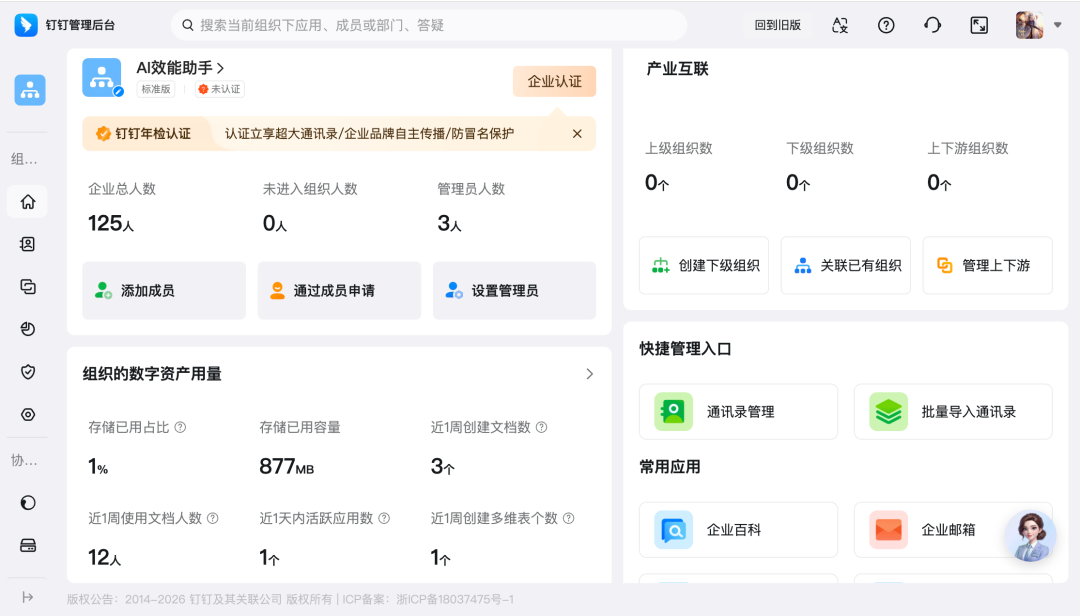
GUI 就有这种问题,不常用的功能被埋得很深,所以你并不熟,举个最典型的案例:我一不小心就开启了京东白条,但等要关闭的时候,我感受到了噩梦!
他们都是那种直接给我干得一眼抓瞎,TMD 还得重头学习,甚至还得搜攻略的东西(这些家伙绝壁是故意的)!
这个时候,整体问题就变成了:
一个人类不熟悉、但系统内部其实已经有能力的功能,Agent 应该如何被引导去完成?
这个就是个大厂商,包括钉钉、飞书正在做的 CLI 改造的核心原因。
一、CLI 改造
这里大家要带入平台视角(钉钉、飞书)去思考一个问题:如果要做 CLI 改造,他到底在改什么?
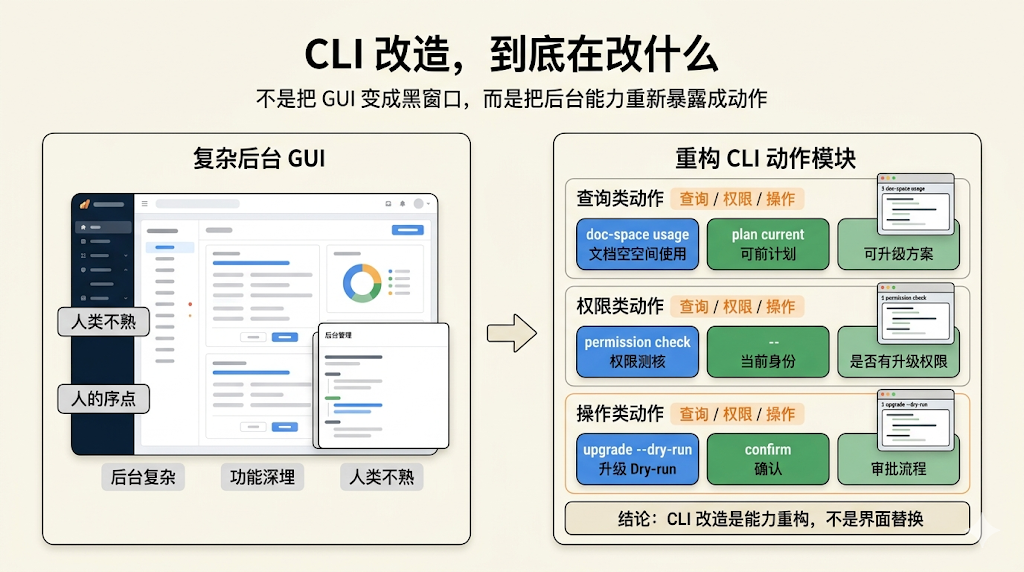
很多人一听“CLI 改造”,会以为是在做一个黑窗口版钉钉,那就想多了。这里就要结合之前的探索了:
CLI 改造的本质,不是把 GUI 换成命令行,而是把原本埋在 GUI 背后的能力,重新暴露成一组可执行动作
其目标是做对 AI/Agent 友好的平台,在这个基础之下,我们就清晰改造动作了:也就是将所有需要释放的能力,按权限分发出来,他可能是这样的:
1. 查询类动作
dingtalk doc-space usagedingtalk doc-space plan currentdingtalk doc-space plans list
这类动作负责回答:
1. 当前已用多少
2. 总量多少
3. 剩余多少
4. 当前套餐是什么
5. 可升级到什么套餐
6. …
2. 权限类动作
这类动作负责回答:
1. 当前操作者是谁
2. 有没有升级权限
3. 如果没权限,应该找谁
3. 操作类动作
dingtalk doc-space upgrade –plan pro_100g –dry-rundingtalk doc-space upgrade –plan pro_100g –confirmdingtalk workflow create –type space-upgrade-approval
这类动作负责做真正的事情:
1. 试算升级
2. 发起升级
3. 发审批
4. 触发流程
……
这里当然还有其他动作,大家感受下即可,我不多写了。
二、Tools 和 CLI
这个时候就要回归本来的问题了:
模型只能识别 Tools,CLI 还不是模型直接看到的东西,所以CLI 和工具到底是什么关系呢?
这里答案也就来了:CLI 更像是钉钉内部对外暴露出来的一组 标准动作接口。
这些动作后面可以有很多种挂法:
1. 直接给一个 shell 型 Agent 用
2. 被封装成 Function Calling tools
3. 被封装进 MCP server
4. 被 Skill 文档引用
5. 被 GUI 反向调用
所以,从案例可以看出,CLI 不是替代 GUI,也不是替代 FC,而是:把“文档空间管理”这块复杂且深埋的后台能力,变成一组更适合 Agent 调度的可组合动作说明书。
在了解了平台会如何改造,为什么要这样改造后,我们继续走个完整流程:
Agent 执行流程
现在假设钉钉已经完成 CLI 改造,并且宿主系统也能让 Agent 用这些能力,我此时对 Agent 说:
我的钉钉文档空间满了,你帮我看看怎么处理。
下面我们按完整链路来推。
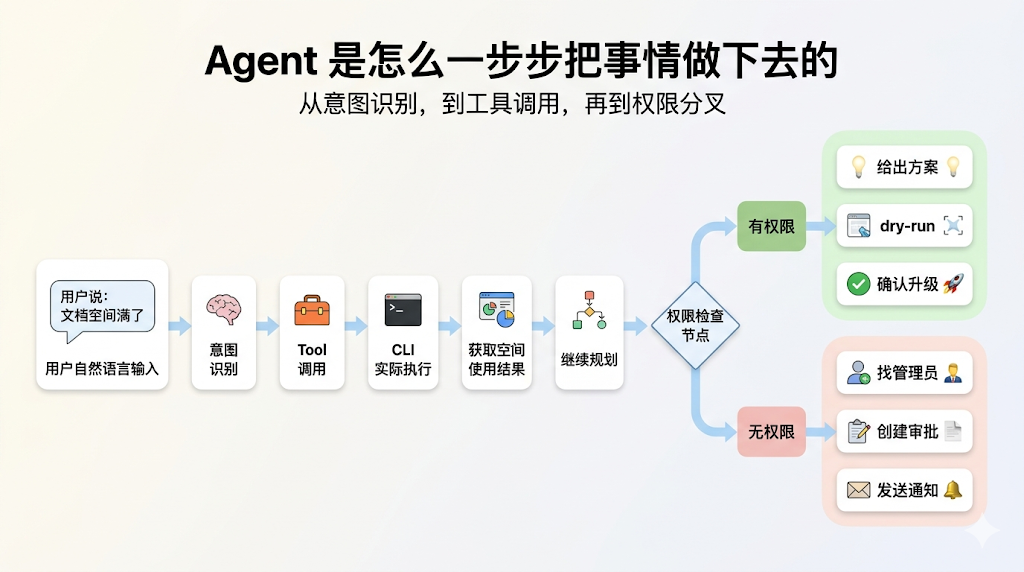
第一步:意图识别
用户说的是自然语言,模型先做的是意图识别。它会大概判断出几个子问题:
1. 当前空间到底是不是满了
2. 满到什么程度
3. 能不能扩容
4. 当前用户有没有权限
5. 如果能扩,扩到什么方案合适
6. 如果不能,应该怎么走审批/管理员链路
这一阶段还是模型层,跟 CLI 没直接关系。
第二步:模型决定要调工具
这里要回归 Function Calling,模型看到的可能是这种工具定义:
[ { “name”: “doc_space_usage”, “description”: “查询当前钉钉文档空间使用情况” }, { “name”: “doc_space_plan_list”, “description”: “查询可升级的文档空间套餐” }, { “name”: “doc_space_upgrade_permission_check”, “description”: “检查当前用户是否有文档空间升级权限” }, { “name”: “doc_space_upgrade”, “description”: “升级文档空间” }]
模型会先选最安全的那个doc_space_usage,但这里的核心是:
模型看到的是 tool,不是 CLI
第三步:宿主把 tool 映射到 CLI
宿主收到 doc_space_usage 调用后,内部真正执行的是:
dingtalk doc-space usage –output json
返回的结果可能是:
{ “used_gb”: 2.1, “capacity_gb”: 2, “usage_ratio”: 1.05, “status”: “exceeded”}
然后主控制权会把结果喂回模型。这里就特别清楚了:
1. tool 是模型可见入口
2. CLI 是系统内部执行动作
第四步:基于结果继续规划
模型看到结果后,会知道:
1. 真的超了
2. 已经超过 2G
那么下一步不能停留在告诉你满了,而是要进一步找解决方案,所以它会继续调下一组工具,比如:
1. 查当前套餐
2. 查可升级套餐
3. 查权限
4. …
如果写成更像 Skill 的路径,就是:
1. 查询当前容量使用情况
2. 查询当前套餐
3. 查询可升级选项
4. 检查当前用户权限
5. 如果有权限,给出升级建议
6. 如果无权限,给出管理员路径或代发审批
Skills 的价值在这里就完整的体现出来了:他会让类似的执行变得很稳定。这里也要注意:不是 CLI 在规划任务,而是 Skill 在组织 CLI 所承载的动作。
Skill 长什么样
因为 Skills 在整个链路中十分重要,所以我们直接把这个 skill 简单模拟出来,比如钉钉可以给 Agent 配一个 Skill,名字叫:
handle_doc_space_overflow
Skill 里可能写成这样:
当用户提到“文档空间已满 / 容量不足 / 无法上传文档 / 提示空间不足”时:
1. 先调用文档空间使用情况查询,确认是否超过阈值
2. 再查询当前套餐与可升级套餐
3. 检查当前用户是否有升级权限
4. 如果用户有权限: – 给出最小满足需求的套餐建议 – 默认先做 dry-run,不直接升级 – 等用户确认后再执行 upgrade
5. 如果用户没有权限: – 查询管理员列表 – 询问是否代为创建审批流程或发送通知
6. 输出时只返回: – 当前已用/总量 – 推荐套餐 – 权限状态 – 下一步建议
这一步最能看出 CLI 为什么对 Skill 友好。因为底下动作很明确:
1. usage
2. current plan
3. plans list
4. permission check
5. upgrade
5. approval create
6. …
这就是 CLI 的价值:CLI 没有解决规划问题,但它让规划特别容易落在一组清晰动作上,是我们自然语言编程的进一步工程化处理
假设当前用户是管理员,Agent 流程就会继续,这里就会涉及整个 CLI 指令的运行机制了,大家要记住一句话:tool 是模型可见入口,CLI 是系统内部执行动作
注意,核心流程来了,这里考虑重要性,我们单开一段:
CLI 指令是如何执行的
流程到这里就会涉及本文的核心问题:模型为什么会知道如何执行 CLI?
因为前面我们已经说清楚了,CLI 不是模型协议,它只是系统能力的一种执行形态,那问题就来了:
1. CLI 指令可能很多;
2. 每个子命令的参数都不一样;
3. 有些参数还是动态的;
4. 甚至不同版本 CLI 的参数格式都可能变化;
那模型凭什么会用?
这个问题如果不回答,前面关于 CLI 的所有讨论都会变得很虚,因为那样看上去就像在说:模型一看到 CLI,就自动开悟了,显然这不科学…
一、Function Calling 显式声明
这个模式大家最熟,也是最稳的。
宿主程序直接把具体能力定义成结构化工具暴露给模型,比如:
{ “name”: “doc_space_usage”, “description”: “查询当前钉钉文档空间使用情况”, “parameters”: { “type”: “object”, “properties”: {}, “required”: [] }}
或者:
{ “name”: “doc_space_upgrade”, “description”: “升级文档空间”, “parameters”: { “type”: “object”, “properties”: { “plan”: { “type”: “string” }, “dry_run”: { “type”: “boolean” } }, “required”: [“plan”] }}
在这种模式下,模型之所以知道怎么调,不是因为它理解了 CLI,而是因为:宿主已经提前把 CLI 背后的动作,翻译成了模型能看懂的 tool schema。
模型只需要做两件事:
1. 判断该不该调用这个 tool;
2. 从用户输入中提取对应参数;
例如用户说:
帮我看看文档空间是否超限
模型只要返回:
{ “name”: “doc_space_usage”, “arguments”: {}}
宿主再去执行底层真实命令:
dingtalk doc-space usage –output json
模型这里并不真正理解 CLI,它理解的是:
1. tool 名称
2. tool 描述
3. 参数 schema
CLI 只是这个 tool 背后的执行后端,他很清晰,但他也有问题:
1. 工具一多,schema 会很多;
2. 显式定义成本高;
3. 每个动作都要做一层包装;
4. 上下文里会堆很多工具定义;
5. …
于是第二种模式出现,他也是比较骚的模式:
只显式声明一个 shell 超级工具
这可能是理解 CLI 真正关键的地方。
有些系统并不会把每个 CLI 动作都显式声明成单独 tools,而是只暴露一个很强的通用执行工具,例如:
{ “name”: “shell”, “description”: “执行 shell 命令”}#
或者
{ “name”: “exec”, “description”: “执行任意命令行动作”}
这时候模型看到的,不再是一堆结构化好的具体工具,而只是一个超级执行口。这个东西为什么很像前端时代的 eval?
因为它们在工程语义上非常接近:
1. eval 是给你一段字符串,当代码执行;
2. shell 是给你一段字符串,当命令执行;
所以在这种模式下,Function Calling 只声明了:你可以执行命令。
但并没有声明:具体有哪些命令,每条命令要什么参数,参数之间怎么组合,于是整个事情就变得骚起来了…
shell 模式下,模型如何调用 CLI?
这就要说清楚:模型并不是天然知道所有 CLI 指令和参数结构。
它之所以还能用 CLI,通常依赖三个来源:
一、训练中本来就知道
例如 ls、grep、curl、git status 这种经典命令,模型训练里见过非常多;
二、Skill 或文档里已经写明了
比如:升级前必须先调用:dingtalk doc-space upgrade –plan <plan_id> –dry-run –output json不要直接使用 –confirm
有时候做得多点,还会把指令的一些说明信息给到模型。
三、运行时临时探索 CLI 的 –help
这就是最关键的一步。
如果模型既没见过这个 CLI,Skill 里也没写全,那它就不能硬猜。这时候更合理的做法就是:先探索,再执行。
例如模型知道自己要处理文档空间升级,但不知道参数细节,它就可能先决定:dingtalk doc-space upgrade –help
宿主负责执行这条命令,并把结果返回给模型。模型看完 help 之后,才知道:
1. –plan 是必填参数;
2. 支持 –dry-run;
3. 真正执行要 –confirm;
4. 输出可以加 –output json;
于是再组织真正的调用:
dingtalk doc-space upgrade –plan pro_10g –dry-run –output json
在这种模式里,模型获得 CLI 知识的方式,不是宿主事先全都告诉它, 而是:
模型通过 shell 这个超级函数,先调用 CLI 的帮助命令,把命令知识在运行时再学一遍。
这就是 shell 路线最核心的机制。
参数问题
这里还留下了最后一个问题:模型怎么知道给 shell 什么参数?,这里答案是:
如果说显式 tools 模式是:参数知识前置;那 shell 路线就是:参数知识后置。
我们这里重点看看参数知识后置,比如 dingtalk doc-space upgrade 需要哪些参数,模型往往要在运行时通过:
1. Skill
2. 文档
3. –help
4. man page
5. 官方 docs
这些额外信息来补全。所以:
如果只暴露 shell 这种超级函数,那么模型对具体 CLI 参数结构的理解,往往要多一个探索流程
这种做法带来个额外的优点:它把原本应该写进 tool schema 里的那部分参数知识,从“提示词前置声明”挪到了“运行时按需探索”。
这个思路跟 Skills 的按需加载,其实在精神上是很一致的。
灵活但失真
但这里当然也是有问题的,第一是稳定性肯定没第一个好、第二是会存在安全性问题。
而 shell 模式下,宿主如果只暴露了一个通用执行口,理论上模型能执行的空间就会大很多。
这里复杂度比较高,我们就不继续衍生,继续之前的 Agent 流程了。
权限分叉:Agent 如何继续往下做
前面查完空间使用情况、当前套餐和可升级方案之后,接下来真正关键的一步:检查当前用户到底有没有权限处理这件事。
从这里开始,Agent 就不再只是查信息,而是会进入真正的动作分支,比如宿主继续执行:
dingtalk doc-space upgrade permission-check –output json
如果返回的是:
{“allowed”: true}
那说明当前用户有权限,Agent 就会继续走升级链路:
1. 结合当前套餐和可升级套餐,给出最小可用方案;
2. 默认先执行 dry-run,确认价格、容量和生效方式;
3. 用户确认后,再真正执行升级;
而如果权限检查返回的是:
{“allowed”: false, “reason”: “admin_required”}
那 Agent 就不能继续硬上,而是会自动切到另一条分支:
1. 查询当前管理员是谁;
2. 告诉用户自己没有升级权限;
3. 提供下一步选项,比如代发消息、创建审批、生成申请文案;
4. 用户确认后,再执行通知或审批动作;
这一条链路最重要的地方则在于:不只是让 Agent 会做事情,更让它在做不了的时候,也知道应该怎么转弯。
结语
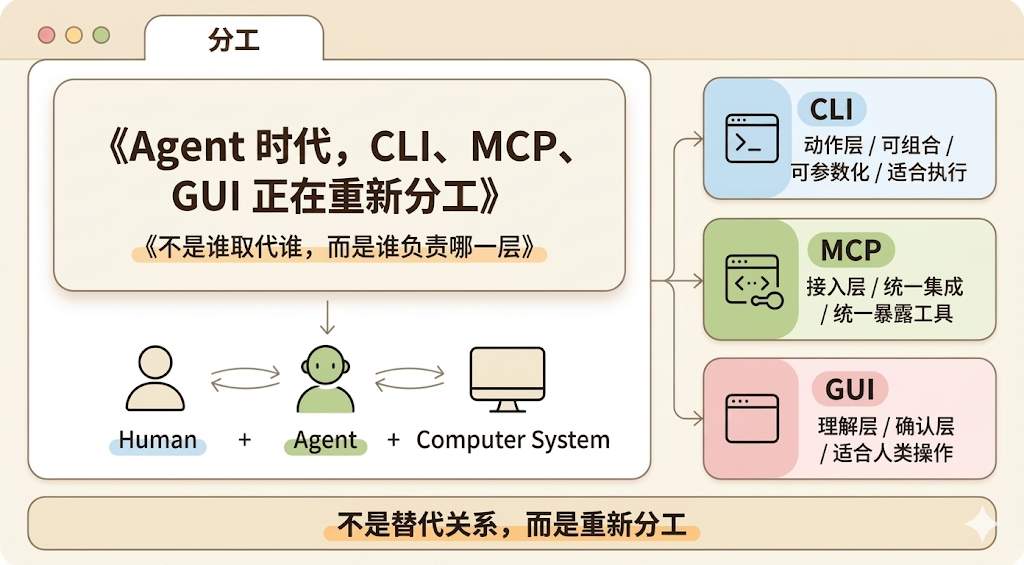
最后总结一下,其实我们也看明白了,不存在 CLI 要取代谁,而是各行各业都需要为 AI 提供更友好的工具了:
当执行者从人类变成了人类 + Agent,系统能力到底应该以什么形式暴露出来
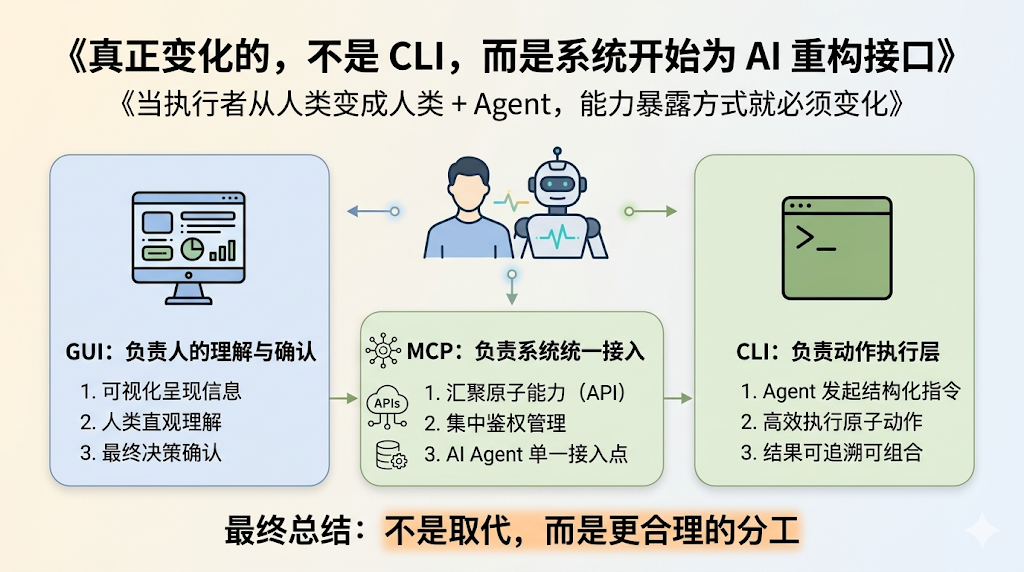
从这个角度看,MCP 解决的是接入问题,CLI 解决的是动作问题,GUI 解决的则始终是人的理解与确认问题。它们不是简单替代关系,而是在 Agent 时代被重新分工了。
所以,CLI 之所以越来越重要,不是因为黑窗口突然又伟大了,而是因为 Agent 天然需要一种可组合、可参数化 的动作层;而 MCP 也并没有过时,因为只要平台还存在大量异构系统和工具,统一接入的问题就永远存在。
好了,整体篇幅不小了,希望对大家有用,文中有错漏的地方也请您不吝赐教。
本文由人人都是产品经理作者【叶小钗】,微信公众号:【叶小钗】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


