
 起点课堂会员权益
起点课堂会员权益Wiki定调RAG补时效:金融知识管理的冷热分流术
金融行业的知识管理困境远比想象复杂,三个字的口径偏差可能引发监管整改。本文深度剖析银行合规面临的口径分裂、时效滞后和跨文档推理缺失三大痛点,并提出了LLM Wiki与RAG结合的创新解决方案,通过定调层与检索层的分工协作,为金融行业打造可靠的知识管理体系。

去年冬天,我司承接了一家城市商业银行的数智化系统升级项目,其中我负责了合规团队做知识库咨询。第一天开会,合规负责人老张拿出两份文件摆在桌上,一份是总行下发的反洗钱操作指引,另一份是他们分行合规部自己整理的”合规要点”。两份文件对同一条监管政策的表述,差了三个字。
三个字而已。但老张说,去年监管检查时,检查组就是拿着这三个字的偏差开了整改通知书。
我当时心想,这不就是个版本管理的问题吗?后来我花了两个月深入调研,才发现事情远不是”版本管理”四个字能概括的。金融行业的知识管理困境,是三个问题拧在一起,互相加重。
三根绳子拧成的死结
第一根绳子是口径分裂。一家大型银行拥有数千份内外规文件,分散在合规部、风控部、法律部、各业务条线。同一监管政策,不同部门解读不一;同一产品条款,不同渠道描述不同。老张遇到的”三个字偏差”只是冰山一角。
第二根绳子是时效滞后。2024年金融监管政策全面升级,新规细则高频发布。合规人员常常在政策发布后数周仍引用旧版口径。不是他们不想更新,而是传统知识库的更新节奏根本跟不上。
第三根绳子是跨文档推理的缺失。我在调研中反复遇到这类问题:”综合信贷合规政策与反洗钱规定,某类跨境业务需满足哪些条件?”这种问题横跨多份制度文件,传统RAG检索到的碎片拼不出完整答案,模型只能硬凑,凑出来的东西谁也不敢用。
我后来把这三个问题总结为一句话:金融行业的知识不缺量,缺的是一个能”定调”的中间层。
Wiki定调,RAG补时效
这个”定调层”就是LLM Wiki。
我在做方案设计时,脑子里一直有一个分工画面:Wiki负责把低频变更、高权威性的内容编译成经过审核的标准词条,比如法规要点、产品条款、审批规则;RAG负责补充高频变更、时效敏感的内容,比如新发监管文件、处罚案例、临时通知。路由调度层在中间做分流,判断一个问题该走哪条通道。
关键原则只有一条:合规查询强制走Wiki,不允许RAG兜底。因为合规口径必须是”定调”的,不能是”拼凑”的。只有Wiki里确实查不到时,才降级到RAG返回原始法规原文,并且标注”未经编译,仅供参考”。
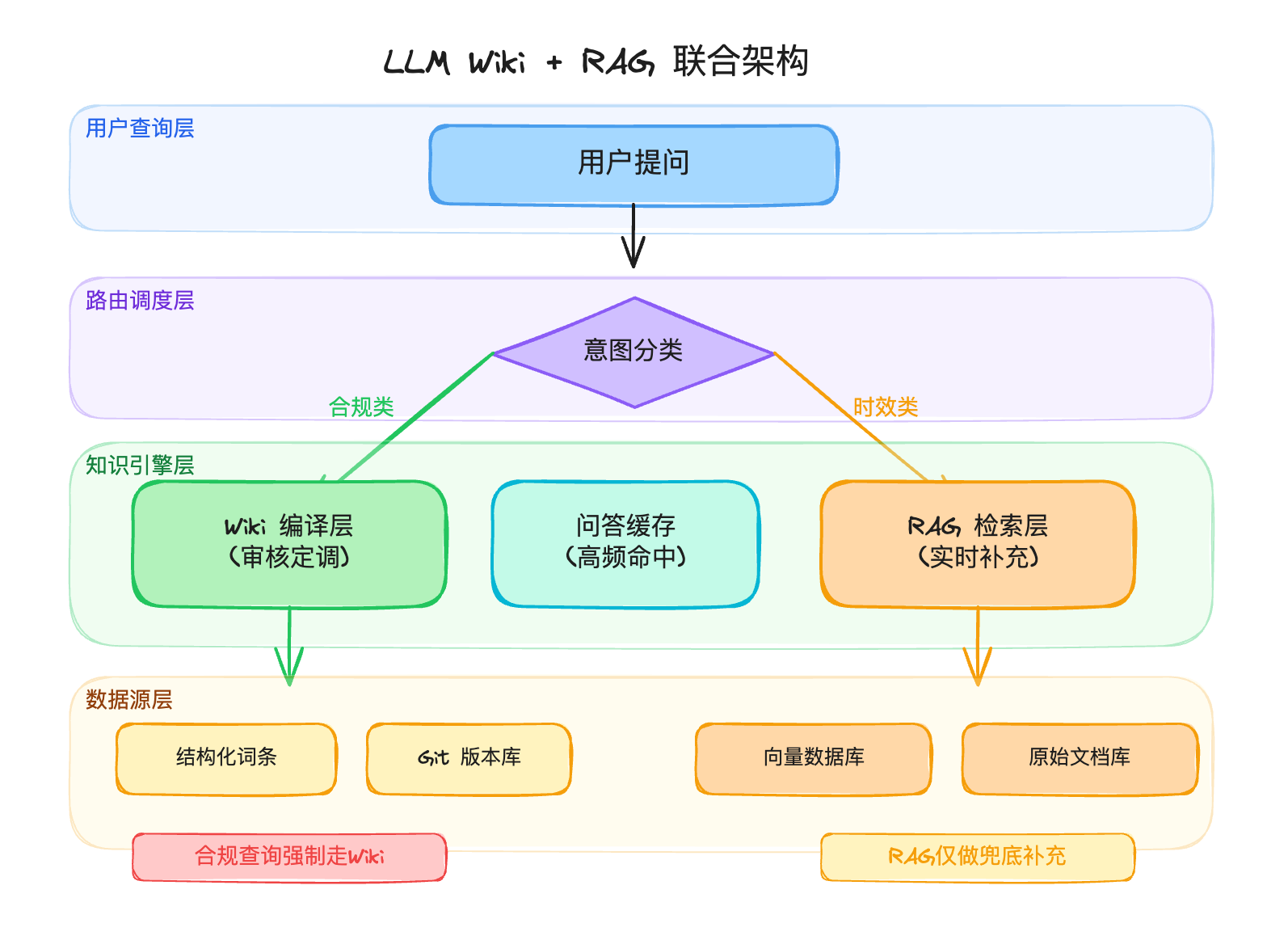
这条原则听起来简单,执行起来需要很多配套设计。每条Wiki词条必须包含完整的YAML元数据:来源法规文号、原文段落锚点、生效时间、版本号、审核人、审核时间、变更记录。审计时可以一键从答案追溯到词条,再追溯到法规原文,再追溯到版本历史。四层链条,一层都不能断。
小王的一笔跨境业务
说到这里可能还是有点抽象。我用一个完整的业务场景把整条链路走一遍。
某股份制银行国际业务部客户经理小王,接到一笔东南亚客户的跨境人民币贸易结算申请。他需要搞清楚:这笔业务在反洗钱合规层面需要满足哪些条件?
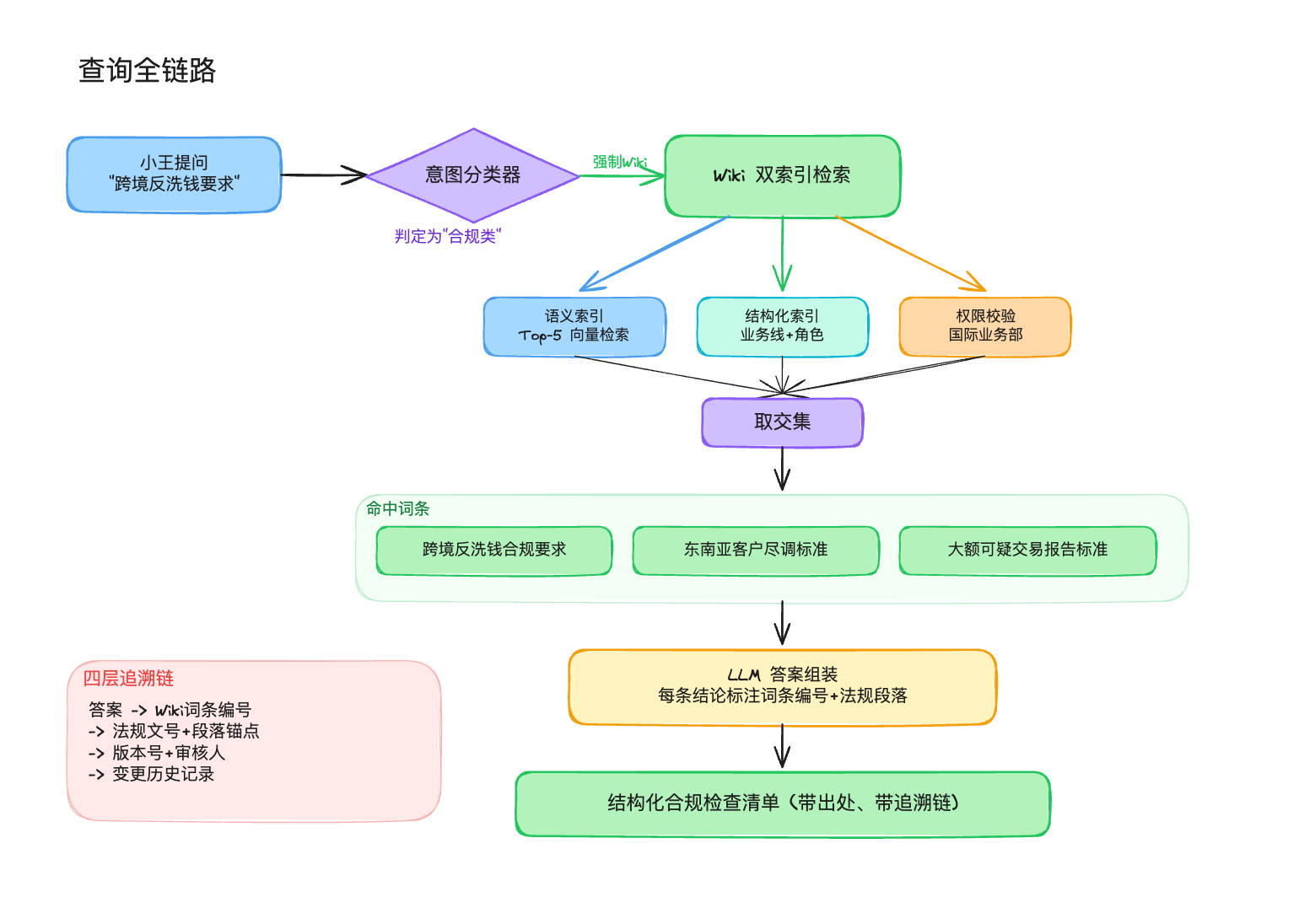
小王在内部合规助手里输入这个问题。系统第一步做意图分类,判定为”合规类查询”,直接走Wiki通道。
第二步是双索引检索。语义索引把查询向量化后在Wiki向量库里检索Top-5相关词条,命中了三条:跨境人民币结算反洗钱合规要求、东南亚高风险国家客户尽调标准、大额可疑交易报告标准。同时,结构化索引按业务线字段过滤”跨境结算”,按角色权限验证小王是国际业务部的人。两个索引取交集,最终返回三条词条。
第三步是答案组装。LLM基于这三条词条生成结构化回答,每条结论都标注了词条编号和法规原文段落。小王看到的不是一段模糊的自然语言,而是一份带出处的合规检查清单:客户尽调要做增强型EDD,法规依据是银发〔2024〕15号第三章第12条;单笔超过20万美元等值须提交大额交易报告,依据是同一文件第四章第18条;首次交易即大额的须报送可疑交易报告,报送时限五个工作日。
我第一次看到这个效果时想的是:老张要是去年就有这个东西,那三个字的偏差根本不会发生。
新规来了怎么办
但光能查不够。金融监管政策每个月都在更新,如果Wiki不能跟上,过几个月它就变成另一个”过期知识库”了。
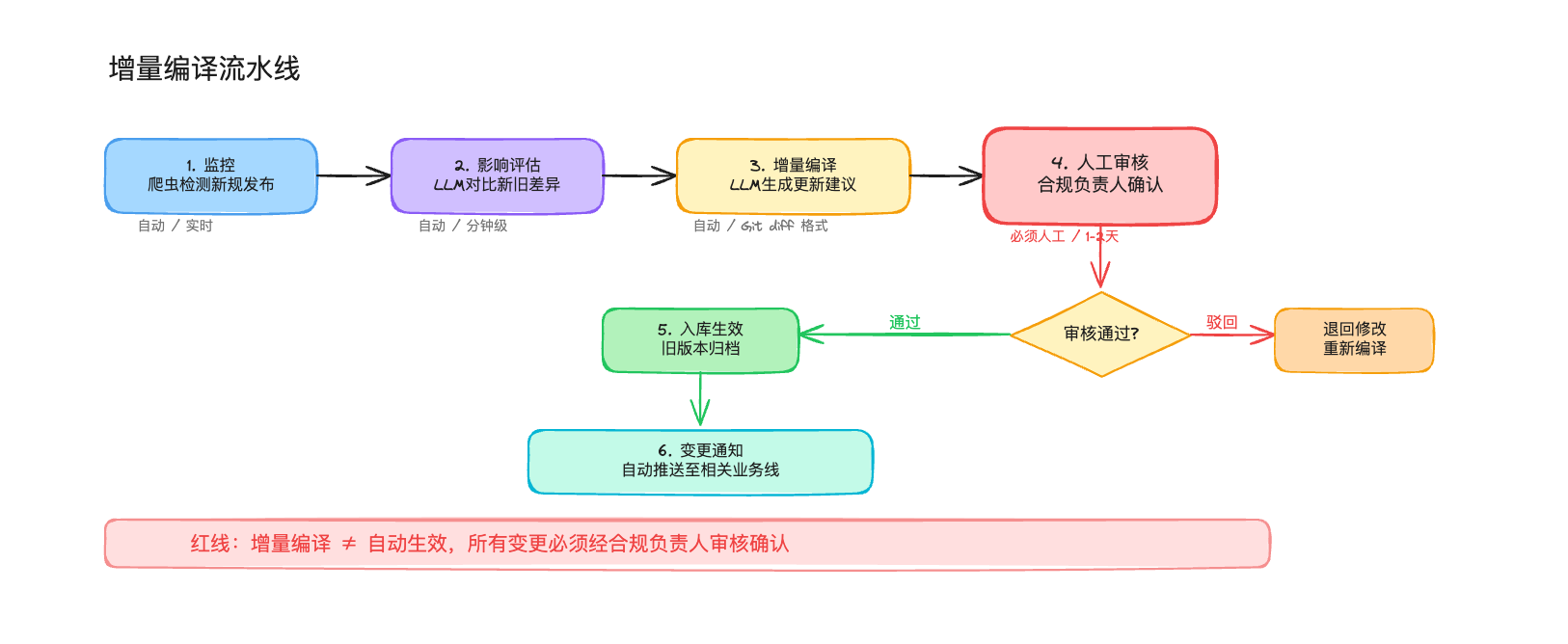
我设计了一条增量编译流水线来解决这个问题。爬虫实时监控央行、银保监等监管网站的新文件发布。新规一出,LLM自动对比新旧法规差异,识别哪些Wiki词条受影响。然后LLM生成这些词条的更新建议,用Git diff格式呈现。
到这里为止都是自动的。但下一步必须是人工的:合规负责人审核更新内容,确认无误后才批准入库。旧版本归档,新版本生效,变更通知自动推送到相关业务线。
我在方案里反复强调了一条红线:增量编译不等于自动生效。所有变更必须经合规负责人审核确认后才可入库。金融行业的合规口径不是靠算法定的,算法只能帮你把待审核的东西准备好,最后拍板的必须是人。
口径打架了怎么办
还有一种更棘手的情况:如果Wiki里两条词条的口径自己打起架来了怎么办?
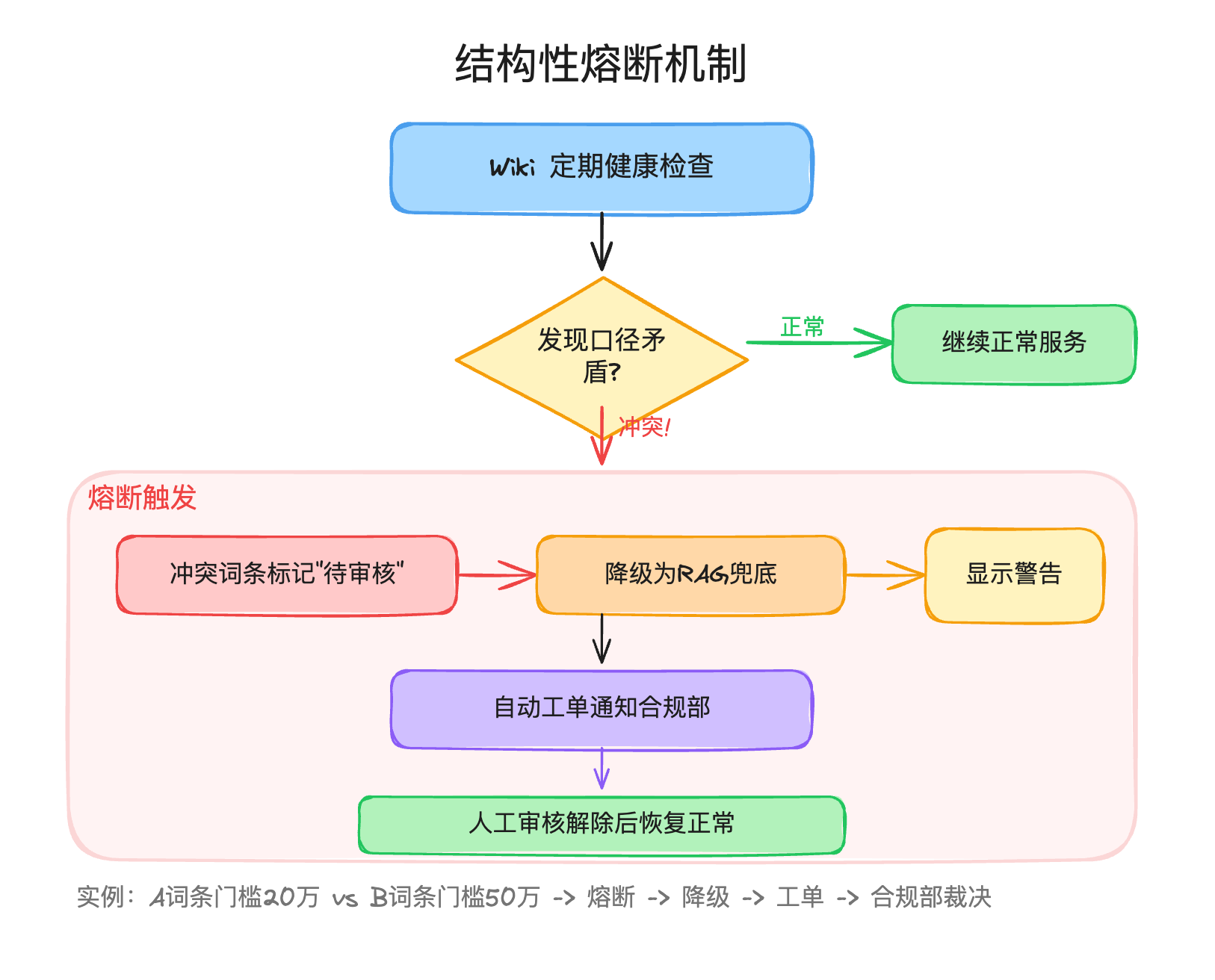
比如A词条说跨境结算大额交易报告门槛是20万美元,B词条因为引用了不同版本的法规说是50万美元。这种矛盾在传统知识库里可能潜伏很久都没人发现,但一旦有人据此做了业务决策,后果可能很严重。
我设计了一个叫”结构性熔断”的机制来兜底。Wiki定期做健康检查,一旦发现矛盾词条,自动触发熔断:冲突词条标记为”待审核”状态,查询时降级为RAG兜底,回答页面显示警告”当前知识库存在口径冲突,以下回答仅供参考”,同时自动生成工单通知合规部处理。
我觉得这个设计最重要的地方不是技术有多巧妙,而是它承认了一个事实:系统会出错。传统RAG里一个错误是一次性的,下次检索可能就不命中了。但Wiki里的错误会被编织进结构,在多个页面扩散。承认这一点,才能设计出真正靠得住的兜底方案。
不只是银行的事
虽然我调研的起点是银行合规,但后来发现这套架构在整个金融行业都有很强的适用性。
证券行业的投研知识管理跟银行合规有异曲同工之处。分析师每天阅读大量研报,传统做法各自记笔记,知识零积累。中金公司的”中金点睛”平台已经在做投研框架的结构化,恒生电子的LightGPT在金融投研合规场景也有落地。如果用Wiki把研报核心结论编译为行业框架词条、公司图谱词条、投资逻辑词条,每一份新研报的处理都建立在前面所有研报知识的基础上。我把这叫”知识复利”。
保险行业的场景更直接。水滴公司的AI核保专家KEYI.AI已经把复杂健康险核保的平均处理时间缩短了80%,准确率达到99.8%。这些数据来自水滴公司的公开披露,限定在”特定业务场景下”。但它至少证明了一件事:保险产品条款这种极度复杂的结构化文本,用AI编译成标准化核保知识词条是完全可行的。
落地没有捷径
说完了技术,说说我对落地的判断。
首年投入大概在300到500万之间,含人力、算力和基础设施。投资回收期我估计在18到24个月。这个数字比很多供应商给客户画的饼要保守,但我觉得更接近真实。因为效率提升不等于人力节省,金融机构很少因为效率提升直接裁减合规人员。
MVP阶段选一个合规域,梳理5到10份核心文件,LLM编译大约50到80条词条,然后合规负责人百分之百全量审核。团队最少需要一名合规专家、一名AI工程师、一名产品经理和一两名业务测试员。特别是产品经理这个角色,很多技术团队会忽略,但金融项目需要大量跨部门协调,没有人居中串联根本跑不起来。
最大的风险不是技术风险,是审核人力瓶颈。金融行业要求全量审核,但合规人力有限。冷启动阶段必须百分之百审核,等系统稳定、编译准确率上来之后,才能降到分级审核,P0红线词条全审,P1重要词条单人审核加定期抽检,P2一般词条抽检20%。
回到那三个字
前两天我又见到了老张。他说今年的监管检查已经结束了,没有再出现口径偏差的问题。不是因为他们上了我设计的系统,而是因为他安排了一个专人,每天花两个小时核对总行和分行的所有合规文件。
一个专人,每天两个小时,只做一件事:核对口径。
我听完觉得有点五味杂陈。这说明口径一致性的需求是真实的、刚性的、值得投入人力去守护的。同时也说明,在没有合适工具之前,人就是最后的兜底方案。
但一个人每天两个小时的核对,能覆盖多少份文件?如果明年监管政策再翻一倍呢?如果这个人离职了呢?
我不想把这写成一篇”AI必将改变金融”的宣言稿。我只是觉得,当一个行业最核心的合规需求,靠的是一个人每天两个小时的手工核对来维持,这本身就说明了问题的严重性,也说明了解决方案的价值空间有多大。
LLM Wiki加RAG不是什么颠覆性的新物种。它做的事情很朴素:把该定调的知识定调,把该实时检索的内容实时检索,中间加一个路由来分流,底下加一个熔断来兜底。
但朴素的方案,有时候恰恰是对症的。
本文由 @iYunar 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议









金融合规的三字偏差,靠人脑追不上,靠拼凑更危险,得有个能“定调”的中间层。