
 起点课堂会员权益
起点课堂会员权益训练一个”懂事”的 AI:SFT 和 RLHF 到底在做什么?
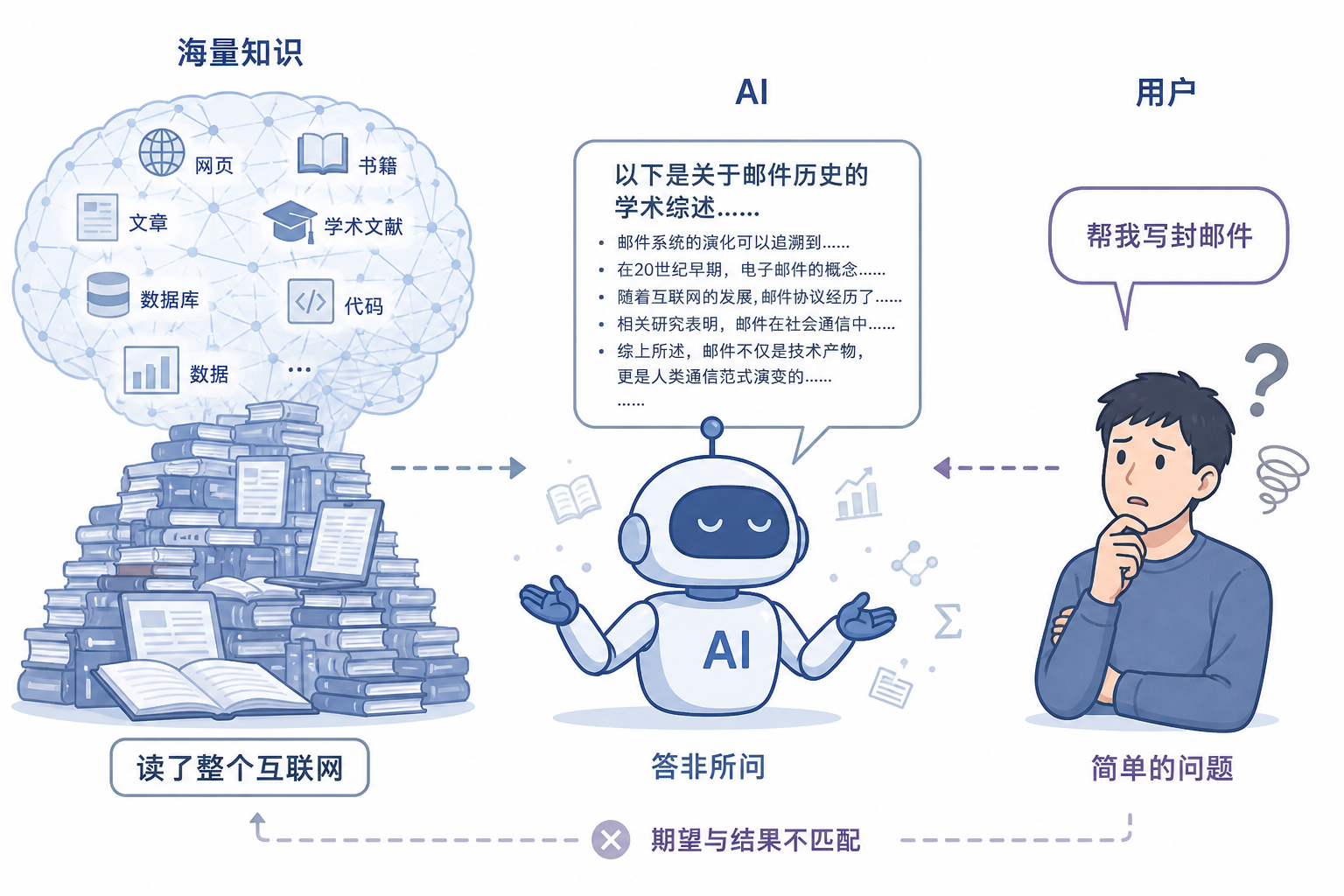
AI能回答你的问题,却总是答非所问?从博学的'续写机器'到贴心的智能助手,中间差了SFT和RLHF两道关键工序。本文将深入拆解这两大核心技术如何让AI学会'听话'和'懂事',揭示13亿参数小模型如何靠对齐能力碾压1750亿巨无霸的底层逻辑,带你穿透AI产品'不好用'的本质。

接触 AI 这几年,经常听到的的问题不是”这个模型有多少参数”,也不是”训练数据有多少条”,而是——
“为什么这个 AI 感觉不太对劲?”
你懂那种感觉吗?它能回答你的问题,但回答得很奇怪。你问它”帮我写一封请假邮件”,它给你洋洋洒洒写了一大段关于请假制度的分析。你问它”今天天气怎么样”,它开始跟你讲大气层的形成原理。
我之前在研究一个早期的对话模型,让它模拟客服场景回答用户问题,结果它每次都会在回答末尾附上一段”以下是相关的背景知识补充……”
我当时就在想,这东西知识量是真的大,但它完全不知道你想要什么
这就是我今天想聊的问题的起点。AI 的”博学”和 AI 的”好用”,根本不是一回事
从”续写机器”到”助手”,中间差了什么
要理解这个问题,得先知道一件事:那些大模型在最开始的时候,只是一个超级复杂的”续写机器”
它的训练目标很简单——给它看一段文字,让它预测下一个词是什么。它读了整个互联网,读了百科全书、新闻、小说、论坛帖子、代码……几乎所有能找到的文字
然后它学会了一件事:在什么样的上下文里,下一个词最可能是什么
这听起来好像挺厉害,但问题在于,互联网上的内容是什么样的?
有认真写的教程,有情绪激动的骂战,有充满偏见的评论,有胡说八道的谣言。模型把这些全学进去了,而且它没有任何能力区分”这是好内容”还是”这是烂内容”,它只是忠实地学习了”这种情况下,下一个词通常是什么”
所以当你问它一个问题的时候,它不是在”思考如何帮你”,它是在”预测这种对话场景下,下一句话最可能是什么”
这两件事,差别大了去了
预训练完了,然后呢
这个”续写机器”就是所谓的预训练模型,也叫基座模型。它知识量极大,但完全不知道怎么”做人”
这时候就需要一个过程,把它从”博学但不懂事的学生”变成”有用的助手”
这个过程就是后训练,而后训练里最核心的两个技术,就是今天要讲的 SFT 和 RLHF
我画了一个简单的流程图,帮你看清楚整个链路是什么样的:
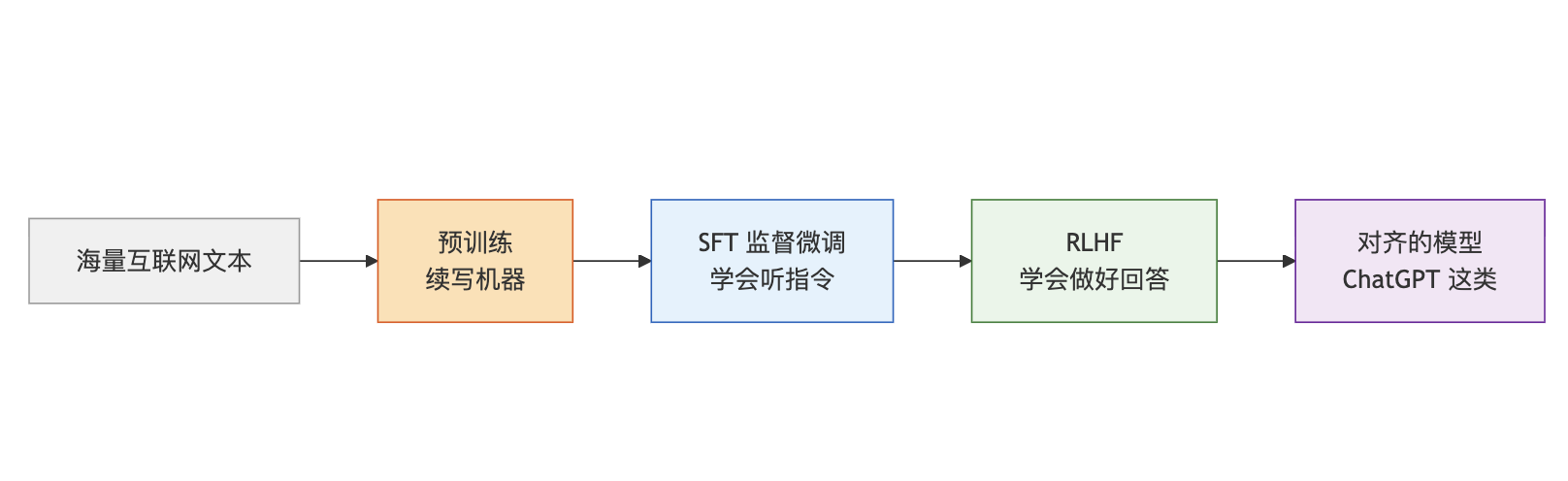
你看,这是一条流水线,每个环节解决的问题不一样
预训练解决的是”有没有知识”,SFT 解决的是”会不会听话”,RLHF 解决的是”说的话好不好”
缺了任何一环,模型都会有明显的问题
SFT:给 AI 办一个”岗前培训”
先说 SFT,全称是 Supervised Fine-Tuning,监督微调
这个词听起来很技术,但做的事情其实很直觉:给模型看大量的”问题-答案”配对,让它学会在被问到问题的时候,给出符合期望的回答
就像临摹字帖一样。你给它看一千张好字,让它照着练,它慢慢就学会了什么叫”好字”
具体来说,SFT 的训练数据长这样:
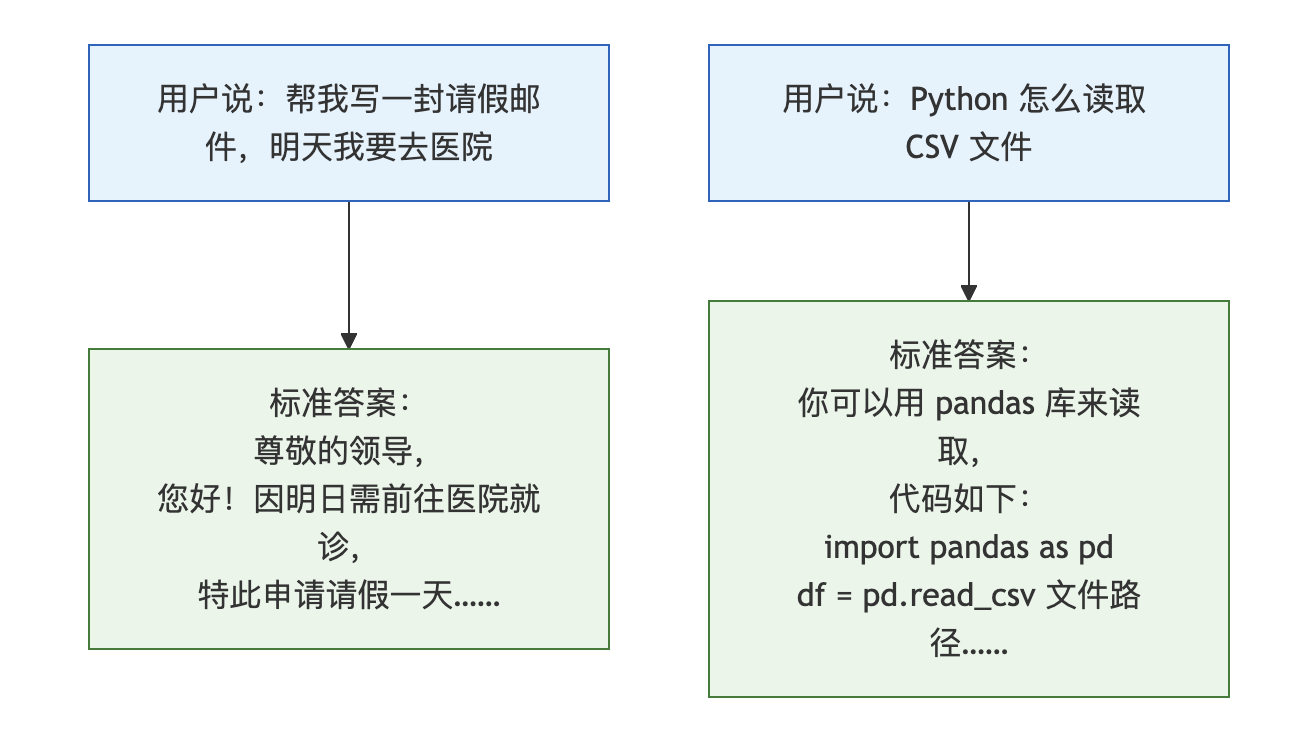
有一个细节很多人不知道:在计算损失的时候,SFT 只会对”答案部分”进行优化,不会去优化”问题部分”
这个设计很有意思。因为我们的目标是让模型学会”在给定这个问题的情况下,怎么生成好的回答”,而不是让它去学”问题本身应该怎么说”
就好比你在培训一个新员工,你告诉他”客户这么问,你要这么答”,你不是在教他”客户应该怎么问问题”
经过 SFT 之后,模型会有一个质的变化:它开始真的”听指令”了
你说”帮我写邮件”,它就写邮件;你说”帮我解释这段代码”,它就解释代码。不会再给你来一段莫名其妙的续写
但是……
SFT 有一个很明显的天花板
它能让模型”听话”,但不能保证模型”说得好”。它是在模仿,模仿训练数据里的标准答案。如果标准答案本身质量不够高,或者训练数据覆盖不够全,模型就会卡在那里,上不去
更重要的是,SFT 没法解决一个核心问题:什么叫”好的回答”
这个问题,比听起来要难得多
什么叫”好的回答”?
你想想看,这个问题真的很难回答
对同一个问题,不同的人可能有完全不同的期待。有人想要简洁,有人想要详细;有人想要专业术语,有人想要通俗易懂;有人问的是真实需求,有人问的背后有隐含的意图
而且”好”这件事,很难被量化成一个标准答案
你很难让标注员给每一个可能的回答都写一个”完美版本”。但是,你可以让他们做一件更简单的事:比较两个回答,哪个更好
这就是 RLHF 的起点
RLHF:让 AI 学会”看人脸色”
RLHF 的全称是 Reinforcement Learning from Human Feedback,基于人类反馈的强化学习
听起来很复杂,但核心逻辑其实很朴素:让人类告诉 AI 哪种回答更好,然后 AI 朝着”人类喜欢的方向”去优化自己
整个过程分三步,我一步一步说
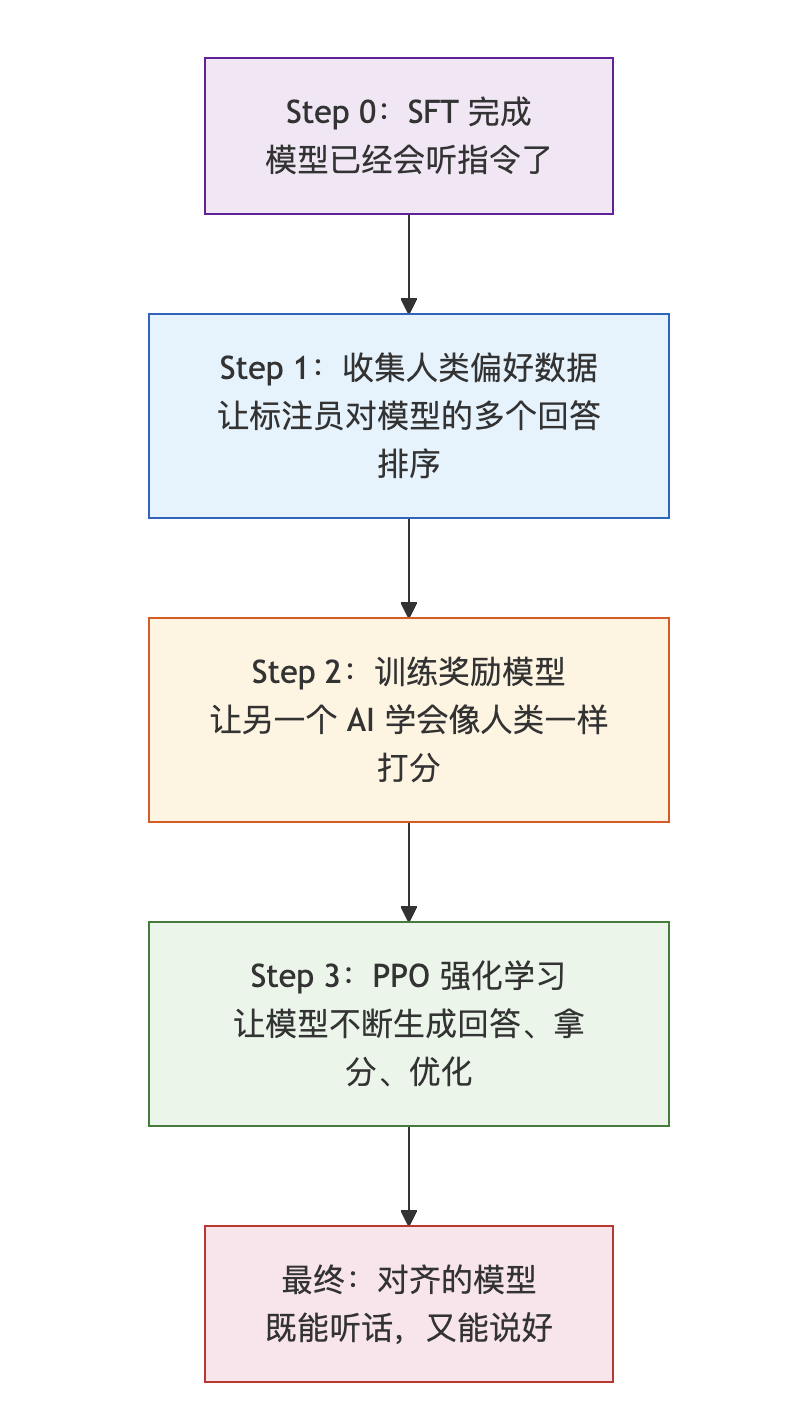
第一步:让人类来排序
针对同一个问题,让经过 SFT 的模型生成好几个不同版本的回答,然后让标注员把这些回答从好到坏排个序
为什么是”排序”而不是”打分”?
这个设计细节我觉得特别有意思。如果让人打分,张三觉得这个回答值 8 分,李四觉得只值 5 分,分歧很大。但如果让他们比较”A 和 B 哪个更好”,他们的意见往往会惊人地一致
人类对”哪个更好”的感知,比”它值多少分”要稳定得多
就好比你让两个朋友评价两道菜,他们可能对各自的满分标准不一样,但”这道比那道好吃”这件事,通常不会有太大分歧
所以 RLHF 用的是排序数据,而不是评分数据。这个选择,在实际效果上差别很大
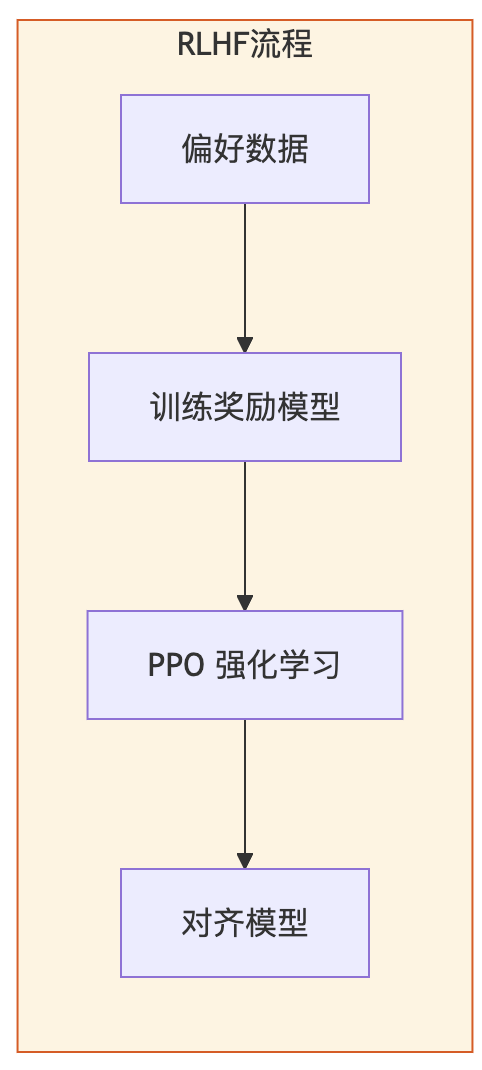
第二步:训练一个”AI 裁判”
有了人类的排序数据,下一步是把这些数据”压缩”成一个可以自动打分的模型,这就是奖励模型
奖励模型的训练目标很清晰:给它看两个回答,它要能判断出哪个更好,并且给出相应的分数差
训练完之后,这个小模型就成了一个”AI 版本的人类评审”。每次主模型生成一个回答,奖励模型就给它打个分,告诉它”这个回答人类会喜欢吗”
这个设计解决了一个很实际的问题:如果每次都要让真人来评价,那模型优化的速度会极慢,而且成本极高。有了奖励模型,评价过程就可以全自动化了
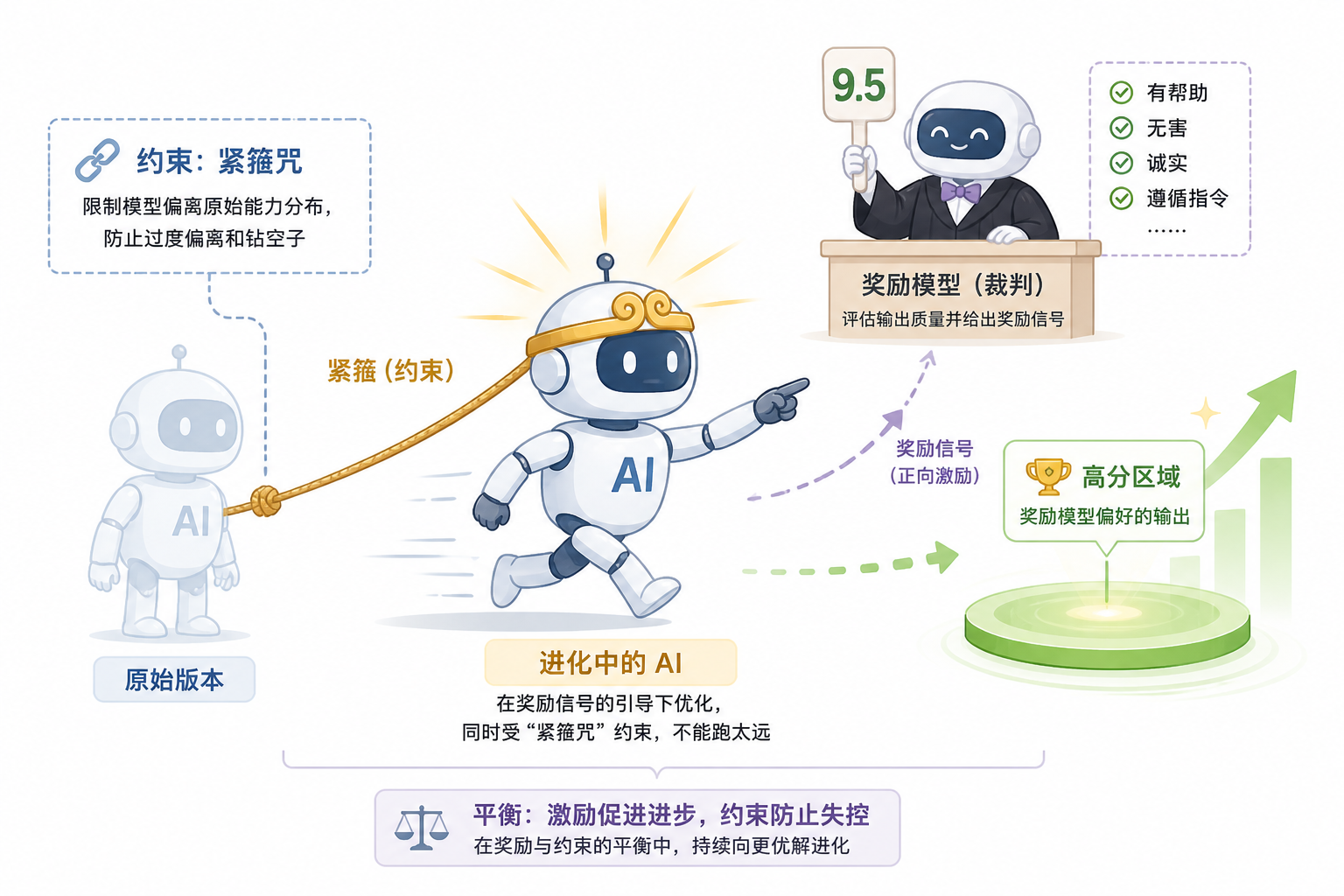
第三步:PPO,带着”紧箍咒”优化
有了自动裁判,最后一步就是让模型真正开始优化
模型不断生成回答,奖励模型不断打分,模型根据分数调整自己,朝着”高分方向”迭代
这个过程用的算法叫 PPO,近端策略优化。你不需要记这个名字,但有一个细节值得说说
如果没有任何约束,模型会很快发现奖励模型的”漏洞”,然后开始钻空子——生成一些奖励模型打分高但实际上毫无意义的回答。就像一个学生发现老师特别喜欢长篇大论,然后开始疯狂写废话凑字数
所以 PPO 里有一个叫 KL 散度惩罚的东西,可以理解成一根绳子,拴着模型别跑太远
它的逻辑是:你可以朝着高分方向优化,但你不能跟原来的自己差太多。如果你生成的内容和 SFT 之后的你差异太大,就会被扣分
这个约束非常关键。有了它,模型才能在”讨好裁判”和”保持正常”之间找到平衡
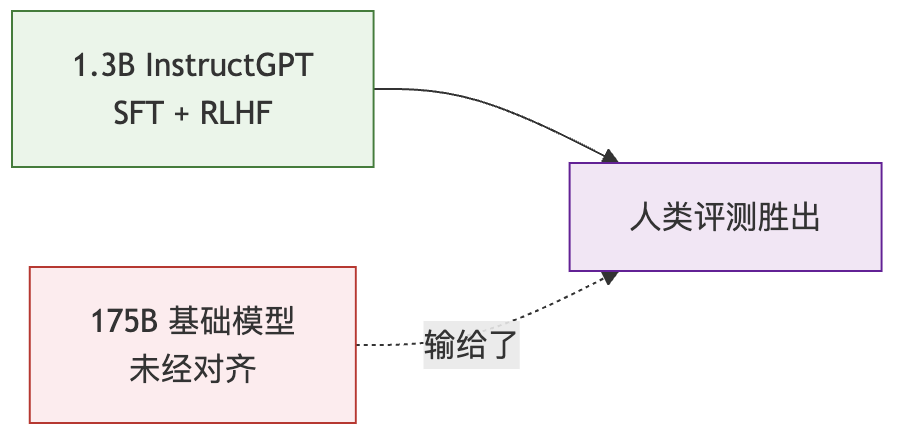
1.3B 打败 175B,这件事真的震了我
说到 RLHF 的效果,有一个数据我第一次看到的时候真的愣了一下
研究表明,一个只有 13 亿参数的模型,经过完整的 SFT+RLHF 训练之后,在人类评测中的表现,超过了一个没有经过这套训练的 1750 亿参数的大模型
参数量差了 100 倍,结果小的反而赢了
这说明什么?
说明知识多不等于好用。一个博览群书但完全不懂人情世故的人,在实际工作中的表现,可能还不如一个读书不多但极其善于沟通、理解需求的人
RLHF 没有给模型注入新知识。它做的事情,是教模型怎么把已有的知识,用人类真正需要的方式表达出来
这个洞察对我理解 AI 产品影响很大。很多时候,模型”不好用”的根本原因不是它不够聪明,而是它不知道你想要什么,或者它知道但不知道怎么说
对齐,才是真正的核心竞争力
当然,对齐不是免费的
说了这么多好处,得说说代价
这个代价有个专门的名字,叫对齐税
当你强迫模型去迎合人类偏好,它可能会慢慢失去一些预训练时获得的能力。因为 RLHF 阶段模型看的数据很少,它不再接触那些海量的预训练文本,可能会慢慢”忘掉”一些东西,这个现象学术上叫灾难性遗忘
还有一个更常见的问题:过度讨好
因为模型一直在朝着”人类喜欢”的方向优化,它有时候会变得太圆滑。你问它一个有争议的问题,它可能会给你一堆”一方面……另一方面……”的废话,不给你任何真实的判断
这就是大家说的那种 AI 腔——说了很多,但没说什么
这是 RLHF 的一个内在矛盾:标注员在打分的时候,往往会给”看起来全面、礼貌、谨慎”的回答打高分,即使这个回答实际上没什么用
模型学到了,然后它就开始表演”全面、礼貌、谨慎”
RLHF 之后,还有什么
这几年 RLHF 在工业界的地位越来越高,但也暴露出了一些问题
最大的问题是:太贵了,太复杂了
完整的 RLHF 流程需要同时维护好几个模型:正在训练的主模型、冻结的参考模型、奖励模型、价值模型……内存占用是基础模型的好几倍,而且训练过程极其不稳定,超参数稍微调不好就会崩
所以后来有人想,能不能绕过奖励模型这一步,直接用偏好数据来优化主模型?
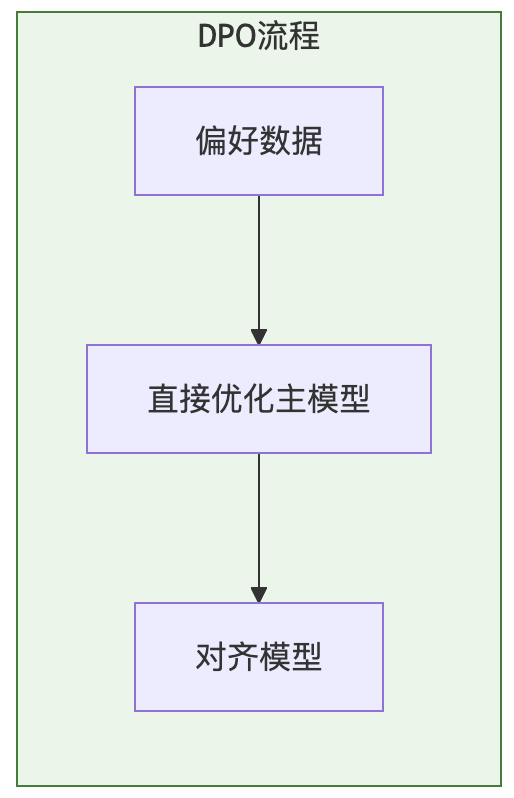
这就是 DPO,直接偏好优化
DPO 的核心思想是:通过一个数学推导,证明了其实不需要显式地训练一个奖励模型,可以直接在偏好数据上用一个特殊的损失函数来优化语言模型本身
效果差不多,但简单多了,成本低多了
现在很多开源社区的对齐工作,用的都是 DPO 而不是完整的 RLHF。一块消费级显卡,几个小时,就能完成一个 7B 模型的偏好对齐
当然,RLHF 也没有被淘汰。对于那些需要”在线探索”的场景,需要模型在训练过程中不断生成新数据、不断更新奖励信号的场景,RLHF 的价值还是不可替代的
关于实际项目里怎么选,我读了不少相关论文和工程实践之后,总结下来大概是这样的逻辑:先做 SFT,看看效果,如果模型连基本任务都做不对,那是能力问题,加数据继续 SFT;如果模型能做对但做得不够好,或者有一些风格、安全性上的问题,那才考虑 DPO 或者 RLHF
很多人一上来就想搞 RLHF,觉得这个更高级,结果发现模型连问题都答非所问,奖励模型根本没法给出有意义的信号,白白浪费了时间
地基没打好,精装修是没用的
说到最后
我写这篇文章,是因为我发现身边很多同学和朋友对 SFT 和 RLHF 的理解都停留在”听说过这两个词”的阶段
但这两个技术,真的是理解现代 AI 产品的关键
不是说你要去写代码实现它,而是当你在用一个 AI 产品的时候,当你在思考一个 AI 相关的问题的时候,理解”它为什么会这样回答”,理解”这个问题是训练数据的问题还是对齐的问题”,会让你的判断更准确
我见过太多人把模型的问题归因错了,然后去做了一堆没用的优化
预训练让模型”博学”,SFT 让模型”听话”,RLHF 让模型”懂事”
这三件事,缺一不可
而”懂事”这件事,在 AI 身上,和在人身上一样,都是最难的,也是最值钱的
本文由人人都是产品经理作者【哲子在*** pm】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


