
 起点课堂会员权益
起点课堂会员权益Higgsfield 出了个「病毒视频预测器」,但真正值钱的不是那个分数
AI视频病毒性预测工具Virality Predictor横空出世,15秒视频就能算出「病毒分」和大脑热力图。这背后究竟是科学突破还是营销噱头?深入剖析Higgsfield的技术实现路径,揭露其真正的护城河并不在算法模型,而在于构建了完整的「生成-评估-再生成」数据闭环。更令人细思极恐的是,当所有创作者都开始用同一个标准优化内容,我们可能正在亲手扼杀内容创作的多样性。
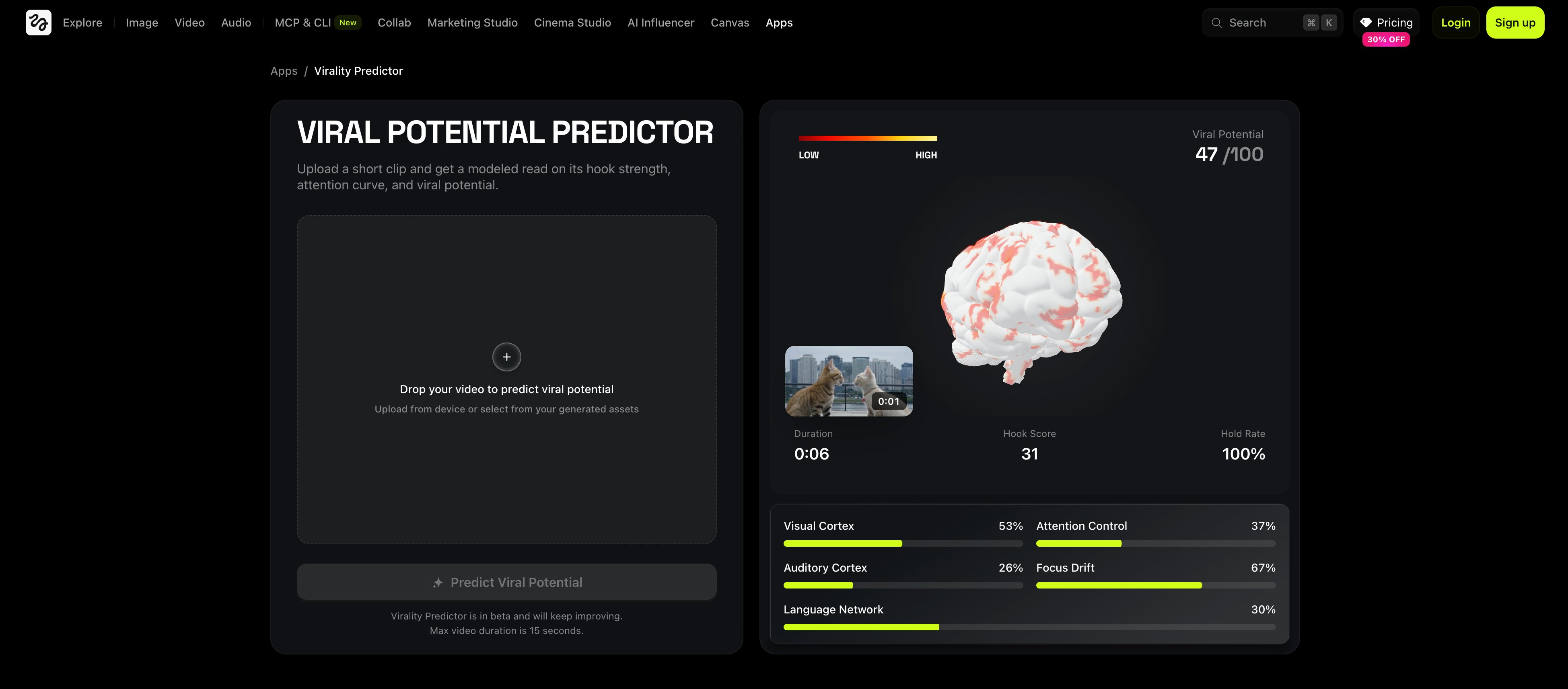
前两天 Higgsfield 上了个新玩具,叫 Virality Predictor——传一段 15 秒以内的视频上去,给你算个「病毒分」,外加一张「脑区热力图」,告诉你视频在观众大脑的哪个区域点亮了。
我看到的第一反应是:这玩意儿能信吗?AI 真的能预测一条视频火不火?
抱着「八成是噱头」的心态翻了一圈官方页面、CLI 文档、加上 OpenAI 官方放出的那篇 Higgsfield case study,结论变了——这工具本身没那么神,但 Higgsfield 敢做这个工具的「底气」,才是真正值得 AI 产品经理琢磨的东西。
那么,除了「这就是个黑盒算法」这种正确的废话之外,我们能不能再深一层?这篇就聊三件事:它到底怎么实现的、为什么是 Higgsfield 能做、以及一个让我后背发凉的副作用。
01 先拆开看:所谓「病毒分」是怎么算出来的
抛开营销话术,这种工具的实现就是三层结构,没什么神秘的。
第一层,把视频拆成机器能读的特征。
视频传上去之后,先做多模态特征抽取。视觉这一侧:抽帧 → 用类似 CLIP 的视觉编码器提语义、用光流算运动强度、用显著性模型算「人眼第一秒会看哪里」,开场的前 1-3 秒还要单独加权。音频这一侧:分离人声/背景音乐/音效,提取音量包络、节奏 BPM、是否有 hook 音效。结构这一侧:镜头切换频率、字幕 OCR、首帧画面和标题文案的语义一致性。
Higgsfield 自己描述 Hook Score 的时候说得很直白:评估的就是开场的运动、对比度、人物在场、显著物体,以及首帧和标题的一致性。翻译成人话——你这条视频开头有没有「东西在动 + 有人脸 + 视觉焦点明确」,标题和画面对不对得上。
第二层,训一个回归模型去拟合「真实表现」。
这是真正的护城河所在。需要一个带标签的训练集,标签通常不是「火没火」这种二分类(信号太粗),而是更细的代理指标:完播率、3 秒留存率、分享速度。
OpenAI 那篇 case study 里透露了一个关键信息:Higgsfield 内部定义病毒性的方式,是「互动/触达比」,特别关注分享速度——当一条视频的分享开始超过点赞,内容就从被动消费转向了主动传播。这才是它们真正在拟合的目标。
数据从哪儿来?三个来源:自家平台用户生成视频后的真实回流、爬虫抓 TikTok/Reels 的公开互动数据、加上少量人工打标。然后训一个 XGBoost 或多模态 Transformer,把「视频特征 → 留存曲线」的映射学出来。
第三层,「脑区热力图」——其实是个可视化包装。
这层是整个产品里最玄的部分,也最值得拆穿。它不是真的 fMRI 数据,Higgsfield 也没法给你脑电图。比较实在的做法是:用公开的 neuromarketing 数据集(比如 Realeyes 这类公司多年积累的面部表情→情绪映射数据)训个辅助分类器,输出「情绪激活强度」,然后映射到大脑分区图——杏仁核管情绪、前额叶管认知、视觉皮层管注意。
说白了,这是一个用神经科学符号包装的情绪分类器。
一位海外的评测人也直接点破了这一点:Higgsfield 没有发表同行评审,训练数据也不公开,应该把这玩意当作不同版本之间的相对比较工具,而不是绝对的神经科学结论。
所以「病毒分 + 脑图」的真相是:一个完播率/分享率预测模型,套了个神经科学的视觉外壳。
02 真正值钱的不是模型,是 Higgsfield 站的位置
把上面三层讲完,技术老炮可能会撇嘴——这有啥难的,三个人一个月就能搓出个 demo。
对,技术不难。难的是Higgsfield 站的位置。
我自己做 AI 产品这两年最大的一个体感:很多 AI 产品的护城河,不在模型,而在数据流的位置。
Higgsfield 是干什么的?它本来就是一个 AI 视频生成平台,Sora 2、Veo 3.1、Kling 这些模型都集成在它的 Marketing Studio 里。也就是说——
平台上每天有海量的视频在被生成、被下载、被发布到 TikTok 和 Instagram。
这意味着什么?这意味着 Higgsfield 天然就有一个别家做不出来的数据回路:
这个回路就是数据飞轮。Higgsfield 不需要去市场上买视频数据,它自己就是源头。
更进一步——它最近还推出了一个叫 Ad Reference 的功能:你上传一条爆款视频,它帮你「重制」一个带你自己品牌的版本。然后这个新版本可以丢回 Virality Predictor 打分,分数不够就调,分数够了再发出去。
整个工作流变成了:生成 → 评估 → 再生成 → 再评估。
这不就是大家天天讲的「AI 应用的评估闭环」吗?只不过 Higgsfield 把评估这一步产品化了,变成了一个用户愿意付费的功能。
那问题来了,字节会做这个工具吗?理论上抖音的数据比 Higgsfield 多 100 倍,模型应该更准才对。但你仔细想——字节做了,等于自己拆自己平台的台。当所有人都能提前预测视频火不火,那些「靠玄学押中」的中小创作者就没饭吃了,整个内容生态会失去多样性。
所以 Higgsfield 能做、字节不能做——不是技术差距,是利益结构差距。
03 一个让人不太想承认的副作用
讲到这儿,其实还有一个问题没聊——也是我自己想了很久的一个。
假设这工具真的做得很准,假设全世界的内容创作者都开始用它优化自己的视频,会发生什么?
会发生算法品味的同质化。
想象一下:今天 10 个创作者,10 种风格,分别在 10 个细分赛道试错。三年后,10 个创作者都在用 Virality Predictor,他们的视频全部被这个分类器筛过一遍,低分的发不出去——
最后留下的,是不是只有一种「最大公约数」的爆款风格?
这有点像 SEO 时代的「Google 优化」。Google 算法越精准,全世界的网站长得越像。今天你打开任何一个内容站点,标题套路、结构套路、首屏布局都惊人地相似,因为大家都在拟合同一个 PageRank。
短视频也会走这条路。当 Hook Score 成为创作工具的默认门槛,「反 hook」反而可能成为下一波病毒密码——因为只有反 hook 的内容,才能在同质化的洪流里被人记住。
你看,工具越精准,平庸越普及,新颖越稀缺。这是个有点反直觉但又很现实的循环。
写在最后
那我们捋一下今天聊的几条 takeaway:
- 所谓「病毒分」就是一个完播/分享预测模型,技术不神秘,CLIP + 一个回归器就能搓一个 demo
- 「脑区热力图」是营销话术,本质是情绪分类器的可视化外壳,别当真神经科学
- Higgsfield 真正的护城河不是模型,而是「生成 → 评估 → 再生成」的数据闭环——它站在了数据流的下游
- 一个 AI 工具能不能成立,先看它在数据飞轮里的位置,再看技术,顺序不能反
- 当所有人都用同一个分类器优化内容,同质化是必然的副作用——反 hook 可能才是新红利
说到底,做 AI 产品和做内容是一回事——真正的差异化不在于「我用了多牛的模型」,而在于「我站在了什么位置去用它」。Higgsfield 这个例子里,它站的位置让它能做出别人做不了的东西,仅此而已。
最后留个开放问题:如果你现在做的是一个 AI 应用,你的产品在数据流里站在什么位置?是上游(生成数据的人)、中游(搬运数据的人)、还是下游(消费和评估数据的人)?
不同位置,能做的事完全不一样。
参考资料
Higgsfield 官方 Virality Predictor 产品页:https://higgsfield.ai/apps/virality-predictor
Higgsfield CLI 文档(含 brain_activity 任务说明):https://github.com/higgsfield-ai/cli
OpenAI 官方 Higgsfield case study《How Higgsfield turns simple ideas into cinematic social videos》:https://openai.com/index/higgsfield/
本文由 @姬小光 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


