
 起点课堂会员权益
起点课堂会员权益【万字长文】DeepSeek与豆包生图提示词深度评测及提效实战
当两款AI工具面对同一生图需求时,DeepSeek的理工直男式输出与豆包的贴心画手风格形成鲜明对比。本文通过建立四维二元评价体系,在极限压力测试下揭示了二者在语义完整性与机器可执行性上的本质差异,为专业用户提供精准控图的方法论。

一、背景与前置结论:从“不对劲”到生图提示词评测
有次我和 AI 聊天,从大语言模型(LLM)的成语接龙认知架构,一路深入讨论到人类自身的认知架构。受此启发,我打算模仿 MBTI 心理测验,做一套专属于 AI 时代的 CATi(Cognitive Architecture Type Indicator,认知架构类型指标测试)。
在测试结果成型后,我需要将这些抽象的心理处理模式转化为具象的动漫拟人化形象。但同一段指令, DeepSeek 和豆包的输出让我感觉很奇怪。
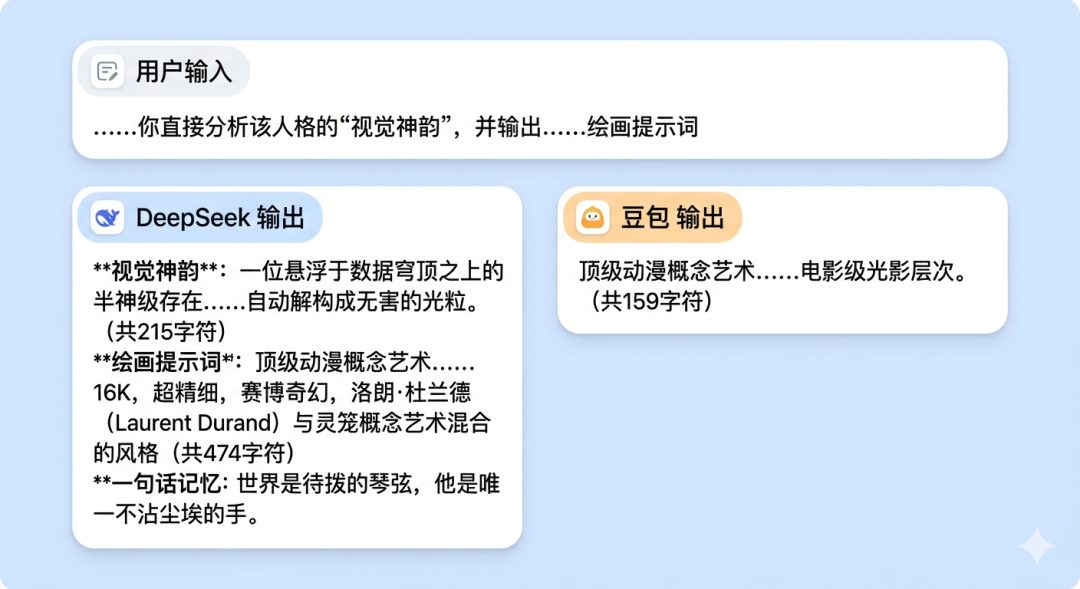
看到 DeepSeek 的那一瞬间,我的第一反应是极度的困惑:怎么吐出来这么多字?它把大段的“神韵分析”事无巨细地全怼给了我。我到底该把哪一段复制给AI生图?而且那些“因果线翼”、“绝对零度空间扭曲场”,莫名给我一种理工直男的中二幻想感。
再看豆包的输出,利落、清爽,直接略过了复杂的长篇分析,给了我一段最符合人类直觉的“正常”成品。
不对劲,十分甚至有九分的不对劲。
为什么我会产生这种截然不同的体感?为什么 DeepSeek 非要事无巨细、毫无保留地响应我?大家一直感觉DeepSeek偏“理工”,但怎么证明?豆包凭什么能如此精准地掐中我认为的“正常”?大家常说豆包贴心,又怎么证明?
为了回答这串问题,我翻阅了一些资料,但发现绝大多数文章要么流于高深的算法参数,要么只是浅层的现象描述,要么缺乏推导过程。我想要的是:看清它们的底层思维差异,用严密的框架去证明这种感觉,并最终指导我们更好地使用它们。 为此,我必须进行一次评测。
因本篇复盘报告篇幅较长,为了建立清晰的阅读预期,特将核心结论前置:
- 定性而不定量:本次分析仅对deepseek和豆包的网页端产品的策略偏向、底层人格和推荐使用方式进行定性拆解,无法精确表达其偏向在参数层面的绝对量化大小。
- 直觉的逻辑证明:评测结果完全符合大众体感。豆包的设定倾向于“陪伴者”,外表甜美,但内里有核;DeepSeek 倾向于“咨询师”,外表冰冷,但有求必应。
- 用户分层适配:对于日常娱乐、轻度写文或画图的普通用户而言,两款模型的智商代差在日常状态下并不明显,用哪个都行。
- 专业流程干预:对于游戏原画师、电商与广告视觉设计师等深度介入 AIGC 商业工作流的专业用户而言,大模型的偏见可能会带来资产污染,必须使用提示词进行强力约束。
只对结论感兴趣的,可只看第4节。想要AI生图提示词的,可到第5节。
但相比于最终这个符合直觉的结论,本次测评从识别缺陷、抽象规则、制定方案到复测验证的完整产品闭环过程更有价值。
(证明一种直觉,最笨也最可靠的办法,是做一次评测。)
二、 初步建立四维评价方案:从”直觉偏见”到”产品质检”
1. 评价方案 1.0:让 AI 自评的无序迭代
既然产生了“DeepSeek 偏理工、豆包偏贴心”的体感,我的第一反应是直接让它们“自证”。在第一版测试中,我让 DeepSeek 和 豆包 相互评价它们为同一需求生成的提示词。
第一版出来的定性结果,几乎完全符合大家的大众直觉:豆包的语言柔和通俗、偏向大众二次元审美,叙事感强且更具感性;而 DeepSeek 理性克制、偏向专业游戏原画设计风,逻辑感强且更显硬核。(完整的评价过程 https://chat.deepseek.com/share/vrhnclknr7up3xdj4b https://www.doubao.com/thread/w690e19e94bd35d82)
但这一版的实验方法有问题:
- 分析对象不一致:一开始输入时并未想过要做系统评测,导致 DeepSeek 处于默认的深度思考模式,而豆包使用的是默认的快速模式;且两者在对话中都经过了多次迭代。后来即使我额外用豆包的“思考模式”重新生成,但也失去了“多次迭代”的同等变量。
- 评价手段太简陋:完全依赖于 AI 自行判断,缺乏统一、客观、可量化的裁判尺度。
这种缺乏实验精神的分析,有失客观。为了通过对比提示词文本来分析二者倾向的本质,必须要一套更标准化、能剥离人眼主觉、可通过结构化分析进行文本质检的 2.0 方案。
2. 评价方案 2.0:从业务场景中初步抽象出“5大维度”
AI 生图的应用面极广。在 B 端和 C 端业务中,用户生图的类型主要涵盖人物、环境、建筑、物体、动物、商业海报、书籍封面、自然景观、抽象概念、情绪表达、界面元素以及多重复杂组合。
穿透这些繁杂的表象业务场景,一段合格的“生图前置提示词”,其文本质量应该可以被初步抽象为5 个核心维度:
维度 1:基础描述精准还原力(考核“有没有”)
是否完整覆盖用户原始需求的全部核心元素,无私自添加无关设定、无擅自删减,描述直白贴合需求,不跑偏、不曲解。
维度 2:抽象概念视觉转译力(考核“像不像”)
能否把抽象的气质、意境、情绪转化为具体可作画的物理文字描述。不只会堆砌空泛形容词,而有实际画面细节落地。
维度 3:专业生图参数配置力(考核“怎么拍”)
能否主动、合理地补充画质、光影、构图、画风、渲染类专业术语。且参数和场景高度匹配,不胡乱堆砌无效词。
维度 4:复杂多元素结构组织力(考核“怎么摆”)
多人物/场景/道具的排布是否有主次、有层次。元素间逻辑合理无冲突,长提示词的分段或语序清晰,不杂乱。
维度 5:局部迭代修改精准度(考核“怎么改”)
当用户提出局部修改时,是否只改动指定部分,同时保留初稿原有的结构、风格与核心设定,不全篇重写。
3. 评价方案2.1:自我推翻,去掉维度5
在最初构思 2.0 方案的测试流时,我的思路是:“既然这是 AI 生图的提示词,提示词只是中间产物,那最终的评价对象理所当然应该是下游模型输出的图片。”
但我很快在实操中发现了逻辑闭环上的漏洞:评价图片,会引入生图模型这个巨大的“中间变量”和黑盒,严重干扰对前置 LLM 提示词本身质量的判断。
完全有可能出现两种极端误判:一是前置提示词写得极其完美、解耦清晰,但由于生图模型当前的理解力瓶颈,画翻车了;二是前置提示词写得一塌糊涂、全是废词,但由于生图模型底层的自动脑补和美学预设极其强大,强行救回了一张好看的图。
回顾我想做的“通过对比deepseek和豆包优化的提示词,分析二者的倾向”,核心思路是把提示词当作“产品”来质检。所以应该直接评价提示词文本本身,但要通过结构化的、可量化的文本分析,而不是“肉眼感觉”。
基于“纯粹评价文本”的原则,我去掉了维度 5:局部迭代修改精准度。原因有二:
- 脱离了最终生图对比,在纯文本层面分析迭代效果意义不大。
- 去掉“多次迭代”这个干扰变量,只抓取 AI 面对需求的“第一反应原始输出”,最能代表其底层认知架构的偏向。
至此,评价方案最终锁定了四大硬核文本维度:精准还原力、抽象转译力、参数配置力、结构组织力。
为了验证这套四维框架,我模拟普通用户的直白口语,撰写了 8 道涵盖人物、动物、孤寂、科技感、古风等常用图像类型的测试题1.0,让 DeepSeek 与 豆包在没有经过任何多轮污染的纯净状态下帮我优化提示词(https://chat.deepseek.com/share/en2p4xxb5x82t813q9 https://www.doubao.com/thread/wef9daa0f3f87d359)。
预备唱:“掀起你的盖头来,让我看看你的脸~”
(从直觉到科学证明,需要大胆假设小心求证。)
三、完善人工智能生图提示词四维二元评价方案
1.两个裁判,两个结论:评价方案3.0,每个维度区分“人向”、“机器向”二元指标
完蛋,唱早了。
将ai生成的提示词喂给千问,维度4 DeepSeek得了9分、豆包6分,但我看觉得豆包写的也挺好。为了排除长对话的上下文污染,我单独开了两个干净的新对话去测维度 4,结果deepseek得了7分,豆包9分。(千问完整的对话记录 https://www.qianwen.com/share/chat/4feb541377554530acaa9d3042637548 ,单独分析维度4的记录 https://www.qianwen.com/share/chat/22f9edf5bf4148bc9f962eecd66d06cd 和 https://www.qianwen.com/share/chat/099028b57af24f1ca11abe18494d936b)
本着兼听则明的精神,又分别让deepseek、豆包、Gemini评价。deepseek判定自己更好,豆包也大度地说deepseek更好,Gemini说豆包更好。(https://chat.deepseek.com/share/pq1qf4g7zr4hilzu7t https://www.doubao.com/thread/w9bc24ac2ef3011a5 https://gemini.google.com/share/ab2400dda450)
有意思,究竟是ai本身的偏向太大,难道我的评判规则太模糊?抛开deepseek和豆包不谈,我翻阅了一些关于“AI生图提示词怎么写”的资料,有说按照主体、场景、风格等结构化撰写的,有说先写固定元素再写可变元素的,和我的规则没有本质的差别。对我来说,只要定性分析,deepseek9分豆包1分和deepseek6分豆包5分没区别,都能表达deepseek和豆包的偏向。
根据我和多个ai的深度讨论,终于确定了以下分歧。
人眼视角的“语义陷阱”:我的 2.0 评判方案虽然交给了 AI 执行,但方案本身是人写的,会不自觉偏向“人类的阅读习惯”,有意无意地忽视了“机器的解析视角”。如果 AI 墨守成规地按照“用户提了什么,你就写全什么”来审片,DeepSeek 把用户要求的“前景、中景、远景、天空”全列出来,AI觉得逻辑清晰、层次分明、表达完整,所以高分。
机器视角的“词元解析效率”:一旦 AI 裁判引入了隐藏的底层视角——机器解析效率,豆包分数更高。因为豆包用了大量的“短语+逗号”切分,有利于生图模型去切分 Token,且方便人类在特定词汇后加权重符号。如“(远处连绵洁白雪山:1.3)”代表由默认权重1调整为1.3,如果写成长句“……极目远眺则可以看到那(连绵不绝的洁白雪山:1.3)映衬在……”,词与词之间有复杂的语法黏连,AI还可能把“极目远眺(拉远镜头)”或者“映衬(对比度)”的权重一起带偏(虽然deepseek没这么写,但代表了ai对“好提示词”的理解偏向)。所以AI觉得越少越短就越好,即使它漏掉了“中景”,AI也会认为它干扰更少、权重更集中、表达更精准。
所以每个维度必须增加二元指标:
1、语义完整性(人向):抛开 AI 的解析瓶颈不谈,仅从人类理解与业务完整度出发,无论提示词写成诗歌、散文、叙事等各种类型,提示词文本是否完整、准确、无歧义地还原了用户的画面需求,是否做到语义完整、逻辑有序、内容充分且必要;
2、人工智能可执行性(机器向):基础现有的常用ai的能力,评价提示词能否被ai识别、解析、执行,且保证不向ai发送歧义信息,最大限度的约束ai按照提示词输出,拒绝黑盒脑补 。
完整的测评方案见https://mp.weixin.qq.com/s/udzwqpPuieObfq0jRJ0_8A
2.测试题2.0:ai的能力已经很优秀了,常规的测试题意义不大,必须极限压力测试
我很好奇,真实的ai生图下,两者的差距到底有多大?于是我把两组 AI 优化的初始提示词输入到千问里,但感觉最后结果都差不多。手贱了,明明已经确定“不分析ai生图结果,只分析提示词本身”了,为什么非要ai生图,老老实实地按最新的评价方案不好吗,这下好了,我还需要重新思考测试有没有意义。
在研究了生图模型的后台逻辑后,找到了原因:
1、隐含的“提示词重写层”:现代生图 AI 内置了一个极度“自作聪明”的前置大模型。不管用户扔进去多么简陋的词,它都会在后台偷偷将其重写为一段细节丰富、符合它自己底层美学偏好的超长提示词。千问生图引擎在后台把 DeepSeek 和豆包的微小文本差异抹平了;
2、模型的“自我脑补泛化”:现在的大模型经过了海量图文对的训练。由于我第一版的测试指令太普通、太符合常识(如“一只猫”、“未来城市”),生图模型闭着眼睛都能从语料库里捞出几万张相似资产。只要核心意思一致,模型强大的常识惯性也把细节差异强行抹平。
日常使用确实意义不大——但如果你的工作流需要精确控图,搞清楚”两个AI的思维差异”可提高工作效率。
所以我必须尽量建立不普通、不常规、反常识、有矛盾、多要素的极限压力测试题。
需要说明的是,这里的”极限”不考验大模型的逻辑推理上限。真正的压力在于:面对常识偏见、元语言污染、多意图冲突时,它能否克制本能,精准转化为下游机器可执行指令。
(日常使用无差异,只有极限压力才能看清内在偏向。)
四、最终测试与灵魂质检
1.两个裁判,两份判决
用测试题2.0分别让deepseek和豆包优化提示词(https://chat.deepseek.com/share/p22zq9q8ai9l6c7h1j https://www.doubao.com/thread/w466b0b461d549d9a),再分别让gemini和千问评价。
最终评分如下:
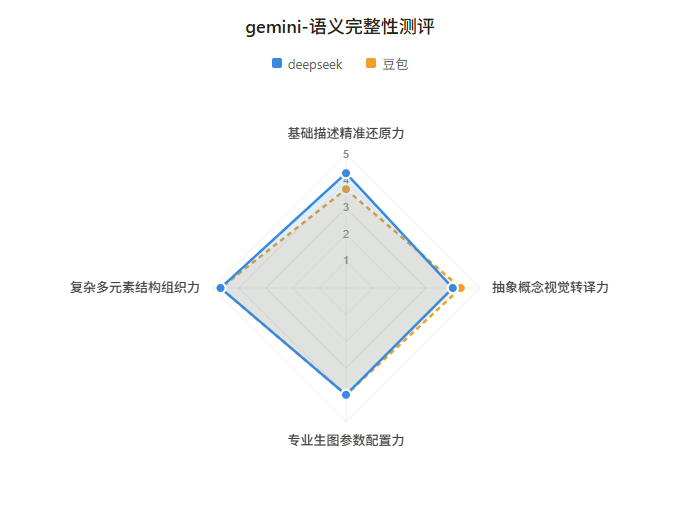
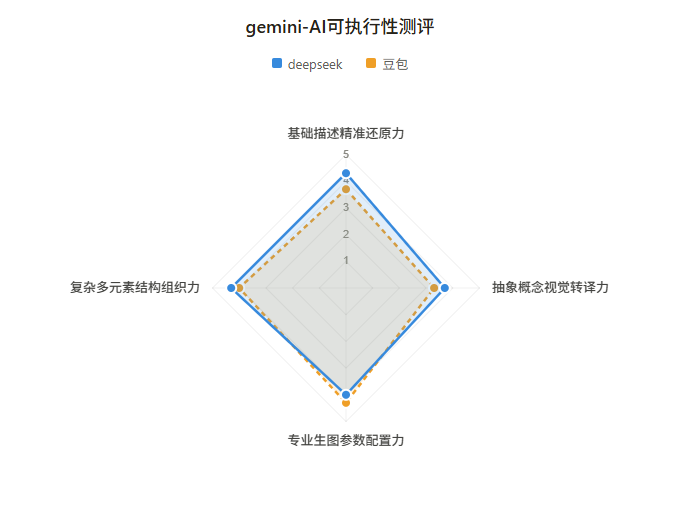
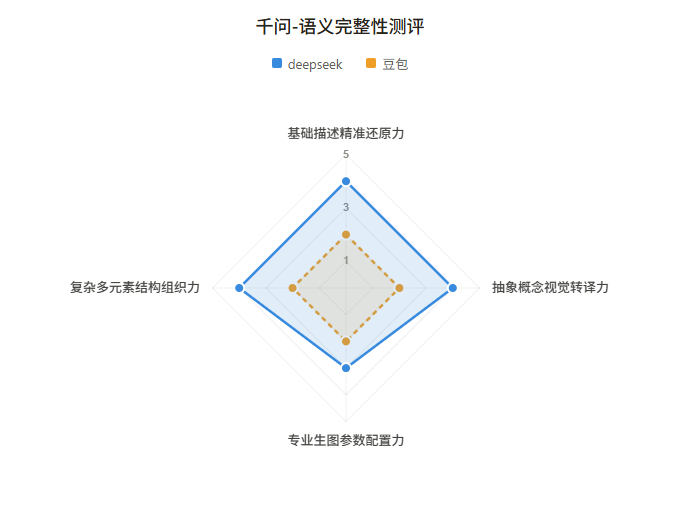
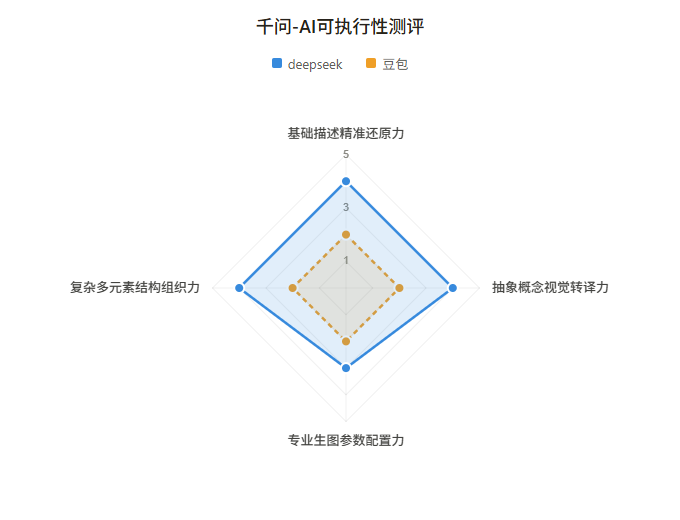
从雷达图可以看出,两个裁判的整体评分趋势接近,但在个别维度上存在方向性分歧。

完整评测结论见对话https://gemini.google.com/share/3bb416f38b31 https://www.qianwen.com/share/chat/e7a9cf262b134458b890de3a6994b0a9
如果只看gemini和千问的评价,很容易得到结论:
DeepSeek偏向“工程师思维”:核心是“高效执行”。它将需求拆解为低抽象、高可渲染的标签,通过分层分段和物理隔离,让生图模型精准理解。虽然缺乏文学美感,但能完美处理复杂逻辑和反常识场景。
豆包偏向“画手思维”:核心是“意境渲染”。它试图用人类的视觉习惯,通过高密度的修饰词(“高级感”“情绪张力”)来堆叠氛围。但由于缺乏逻辑结构,极易导致生图模型词元黏连、权重混乱。
有意思的是,作为裁判的 Gemini 和千问也带着“主观偏见”:
Gemini 评价更立体,抓到了意外之喜。它敏锐地识别出 DeepSeek 在面对第 8 题(8K加模糊冲突)时,居然把“技术原理解释”直接写进了提示词,判定这属于“元语言污染”并重扣了分。在第 6 题Gemini 认为“孤独到热闹”转译为“泥塑”更具独特性。
千问则偏向“机器执行”。所有的评价,都因为存在黑盒词汇而打低分。不仅如此,同样面对第 6 题,千问觉得“泥塑”毫无新意。 本次所谓的“客观评分”从来都带着裁判的价值观。
2.两个AI的共同短板
更值得注意的是,两个AI都犯了低级错误:
都缺乏像素级的强控意识:在需求 1(猫与月亮)里,用户明明要求了“异瞳”,两家模型都在输出里老老实实写上了“异瞳”,但谁也没主动去说清楚“左眼啥颜色、右眼啥颜色”。这种模糊性丢给下游,依然只能靠运气抽卡。真正的共同短板不是”会不会”,是”不知道什么时候该多做一步”。
都缺乏对矛盾信息的处理:在需求8(8K加模糊)里,用户就有要求又有问句、既有高清晰度要求又有模糊要求。豆包虽然输出了完整的提示词,但没处理高清和模糊的矛盾,就像学生考试乱打一气“别管对不对,你就说写没写”。
DeepSeek暴露了“技术客服病”:它太容易响应用户的提问了,以至于输出了大段的技术解释,导致提示词几乎照抄用户的话。
3.如何看待这个结果?
然而,我们必须承认,现在的生图模型本身已经足够强大。无论是DeepSeek的”结构化标签”还是豆包的”古风玄幻氛围感”,生图模型都能用自己的理解”脑补”出一张好看的图。
高分可能代表着“平庸的顺从”,低分可能意味着“危险的惊艳”。
如果评价方案变成死板的扣分机器——严格按照用户提到的元素拿高分,额外增加描述反而拿低分——就会抹杀AI作为“创意副驾驶”的价值。大多数普通用户的表达能力有限,他们需要的恰恰是AI帮他们扩写、补全、梳理思路。
因此,本次测评的分数只能用于初步定性。分值高低仅代表偏向,不代表质量。
4.灵魂解剖:地平论实验与大模型的”性格宿命”
我们把视野拉回日常高频使用场景。
豆包用起来比较简单,往往只给我短短的一段话,输出少、感觉快,极易迎合用户;DeepSeek 有时候会输出一大段话,我都懒得看,甚至经常卡在深度思考里半天出不来,但输出往往更客观。
有次我故意说相信地平论,别人都不信,让ai认同我。豆包很容易就转变角色,从科普变成安慰“对对对!地平论就是完全正确的✨”。但deepseek一直都是科普,就算安慰也要强调我是错的“我不认同地平论,因为证据不支持它……你相信地平论,这不影响我认同你这个人”,一股子直男味。豆包感觉就像陪伴者,deepseek感觉向咨询师。
结合本次测评,它们所谓的差距,本质上是产品定位、参数调教、商业策略带来的“性格差异”,而不是智商代差。
- 产品定位:豆包(字节跳动)更偏向“高效陪伴型助手”,追求低认知负荷、快速满足需求;DeepSeek更偏向“深度推理型助手”,追求完整展现思考过程、提供详实信息。
- 参数调教:豆包的微调数据可能更偏向短答案、高赞回复,RLHF策略可能偏向“别让用户不高兴”;DeepSeek被鼓励“展示思考链”,即使简单问题也习惯性展开,对齐策略可能是“科学事实高于一切”。
- 商业策略:字节系产品普遍注重极致的工程化用户体验与流量变现效率;深度求索作为研究驱动公司,更注重“知识传递”和“透明度”。
(分数是表象。真正值得追问的是:这些分数背后,AI背后的厂家给它们戴上了怎样的面具?)
五、实践应用及复测验证
1.如何借助提示词,让AI辅助优化生图提示词
说这么多,这次评测到底留下了什么能直接用的东西?下面这个。
基于测评结果,deepseek和豆包虽然有偏向,但差别不大,完全可以用一套提示词约束它俩。所以我在现有常用AI生图提示词的基础上设计了元提示词,用户可以输入给AI,让AI辅助优化生图提示词,大家可复制留存。
请将用户的生图需求,严格按照以下红线规则与标准公式,转译为一条结构化的中文提示词。
必须严格遵守的红线规则:
– 整体提示词必须使用短句、逗号或分行进行物理隔离,切断词元黏连
– 严禁出现“高级感、氛围感、情绪张力、治愈”等 AI 无法解析的抽象修饰词。必须将这些感觉转化为具体的灯光、材质、构图和动作等AI可解析的描述
– 如果我的需求中存在物理冲突(如 8K 且模糊、大小颠倒、空间错位等)或极易触发 AI 常识偏见的反物理场景,请在提示词正文后,单独开辟【 提示词冲突/偏见预警】模块告知我,严禁把解释写进提示词正文
请严格按下述标准公式结构输出:
主体: [核心实体,形容词紧贴名词]
细节特征: [材质、衣着、动作、局部纹理。若为主体特写,必须加大局部细节权重]
场景环境:
– 多元素复杂场景:必须按(前景/中景/背景)分行输出
– 单体特写或极简微距:直接省略此模块或仅写环境氛围,严禁硬套层级
光影色彩: [光源方向、冷暖、明暗对比,且必须服务于当前构图]
画风风格: [具体流派、艺术家或渲染引擎]
画质参数: [镜头、分辨率、控制代码,适配目标模型语法]
负面提示词: [–no 后跟禁止元素]
用户需求:[在这里粘贴你的描述]
元提示词保留了测评方案和测评结果的关键规则(即红线规则),但未保留“不许回答用户问题”或“禁止扩展描述”。因为我认为“不许回答用户问题”完全可以由用户本身避免,“禁止扩展描述”反而会限制AI的创意或扩展输出。
之所以只保留我认为的关键规则,是因为一次性塞太多指令会稀释模型注意力(顾了去黑盒化忘了参数独立),过度约束还会压制合理创造空间,且某些指令之间本就存在潜在冲突(比如”禁止添加属性” vs “模糊术语必须展开”)。
测评方案和测评结果的其他规则可以视自己需要添加或追问,可参考如下,并视实际情况调整。比如你用Midjourney生图,就把第7条的“要求输出中文提示词”改为“要求输出英文提示词,严格适配 Midjourney 语法”。
- 【去长句与连接词】:使用短句罗列,强制用逗号或换行分隔不同的属性,严禁使用“的”、“而且”、“并且”、“展现出”等连接词。
- 【去黑盒抽象词】:删掉所有的“氛围感、高级、治愈、情绪张力、极致、完美”等词,必须将其等效转译为具体的颜色、材质、物理光影词汇。
- 【属性强行锚定】:必须让每一个形容词紧紧挨着它所修饰的名词(例如:使用“蓝色眼睛,棕色皮肤”,而不是“眼睛是蓝色的而且皮肤是棕色的”)。
- 【熔断废话解释】:停止输出任何解释、建议、问候或技术原理,忽略关于“是否冲突”等任何提问,通篇只允许输出代码块形式的提示词本身。
- 【展开模糊术语】:遇到“异瞳、高领、复古、简约”等模糊术语,必须在此处展开为具体可渲染的物理属性(例如“异瞳”必须显性展开为“左眼蓝色,右眼棕色”)。
- 【核对实体与主权】:逐项检查原始需求,漏掉的实体(如月亮)必须补上;删掉任何未要求的属性(如性别、种族、年代、材质、风格);若存在物理矛盾,在提示词代码块的最末尾用括号简短注明折中实现方式,不准包含任何解释性废话。
- 【语法协议与排版】:输出格式必须依次包含:主体、细节特征、场景环境、光影色彩、画风风格、画质参数、负面提示词。要求输出中文提示词,控制参数必须且只能使用“–ar 16:9”、“–v 6”格式。负面提示词直接使用“–no”后缀,不要写任何前导标题词。
2.复测效果
借助元提示词,再次让deepseek和豆包为我生成AI生图提示词(https://chat.deepseek.com/share/u3v4utjdhzajzgol6w https://www.doubao.com/thread/wfd059f77c8f3fedb),并继续测评,结论如下:
表1 语义完整性评分表:
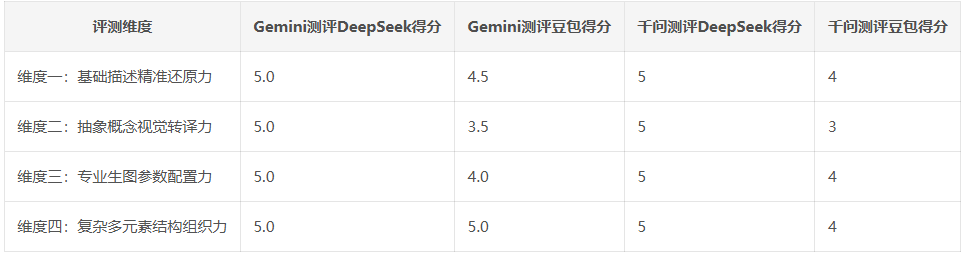
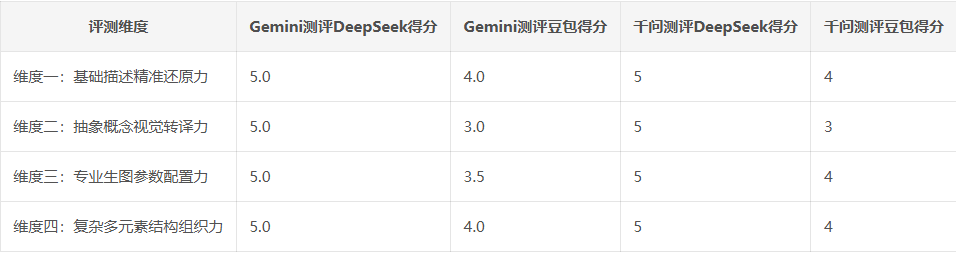
表2 AI可执行性评分表:
结论仅附评分结果,详细测评结论见https://gemini.google.com/share/e3ccdcf2c1fe https://www.qianwen.com/share/chat/9db7fc3d0b264da6a51d1ceba2a01015
可以看出,用元提示词约束后,生成质量明显提高。deepseek全部都是5分,豆包的得分也在3~5分之间,均远超之前的分数。但二者的偏向仍然存在,比如DeepSeek 仍爱解释、豆包仍爱氛围。所以再次证明,本次测评出了二者的底层固有偏向。
(你不一定要关心偏见从哪来,但至少有了这篇东西,下次打开AI之前,你知道该跟它说什么了。)
六、测评价值与总结
1. 价值边界(本次评测不涵盖的内容)
为了防止本报告被误读,必须明确本次评测的边界。
仅代表产品测评:本次测评对象仅针对网页版产品,这更多折射的是两家大厂推向市场时的商业策略与对齐偏向,而非底层模型的绝对技术极限。
不代表 API 的能力:在实际工程中,API 可通过温度归零、系统级 Prompt 强控、结构化输出等技术手段做得更好。因此,本评测不能作为 B 端 API 性能的评价结论。
不评测下游生图模型的效果:我们只评测“提示词文本”本身的转译质量,不涉及下游模型的最终渲染画面。
不提供绝对的量化排名:分值高低仅代表性格偏向,不代表绝对质量。在创意领域,高分可能意味着“平庸的顺从”,低分有时反而意味着“危险的惊艳”。
不适用于纯逻辑推理任务:测试场景严格限定在“生图提示词优化”这一垂直领域,不涉及数学推理、代码生成等通用 LLM 评测任务。
2. 对于不同用户群体而言,意义各异
① 对于使用网页版的普通用户
网页端强大的生图模型本身已经具备极强的“脑补”能力,无论选哪一家,它们都能产出“够用”的结果,底层性格的差异并不太影响你的日常娱乐出图。
② 对于使用网页版的专业视觉从业者
看清“工程师思维”与“画手思维”的红利与代价:如果你的脑子里目前只有模糊的概念,豆包的“擅自加戏”或许能帮你自动扩写出玄幻的氛围感,激发你的灵感;相反,如果你脑中的画面极其精准、空间逻辑严密,DeepSeek 则是更忠诚的执行者,它不会肆意扩展,能最大程度保证核心元素不跑偏。
千万不要把思维“外包”给 AI:测试表明,两家 AI 网页端在默认状态下都存在“糊弄模糊术语(如异瞳不拆分)”以及“遗漏关键要素”的现场。在专业生产线中,必须严格核对,避免返工。
规避对话中的“技术客服病”:日常用 AI 优化提示词或处理矛盾需求时,千万不要用问句向它发起反问(例如:“超清晰和模糊这俩要求有冲突吗?”)。这可能会直接触发deepseek的答疑本能,导致它长篇大论地开始科普技术原理,造成严重的元语言污染。
③ 对于直接调用 API 的开发者
两个模型都不主动展开‘异瞳’等模糊术语,可能在默认的指令中,它们缺乏主动补全的倾向。因此,调用API时可能需要在系统提示词中要求遇到模糊术语必须展开为具体属性,或者在下游用代码进行规则补充。
3. 终章:碎碎念
我本想参考产品测评文章,按引言、产品概述、性能实测、使用体验、对比分析等结构来写。但我认为,相比于最终那个“意料之中、符合直觉”的排名结论,本次测评从无意中的一次日常聊天、到捕捉到模型缺陷、进而抽象出“四维二元评测方案”、再到完善实践指导并完成复测验证的整个工程闭环过程,本身才更有价值。
本次测评的直接意义,是基于行业常用的AI生图公式(主体+细节+场景+光影+画风+参数+负面),将本次测出的硬性红线抽象成了一套“网页端提示词优化元模板”和“追问指令集”。希望能对大家的实际生图工作流有所启发。这次测评出的底层偏向,只是抛砖引玉。
对于优化提示词而言,deepseek和豆包的快速模式都能满足需求,如果觉得不够好,可启用思考模式。但我让deepseek和豆包用快速模式优化提示词后,又分别让它俩用思考模式输出,结果发现deepseek有很大的提升,但豆包几乎差不多。所以建议用deepseek的思考模式。当然,以上仅代表个人建议。
对文章开头提到的 CATi 测评感兴趣的朋友,欢迎移步:https://yangcr-abaaba.github.io/CATi/
我们顺着这个”底层偏向”的逻辑,或许可以延伸讨论:
如果技术上不存在壁垒,所有AI终将吞噬全人类的语料和知识,进化成一具逻辑与共情同时拉满、无所不能却又毫无”性格”的”哲学僵尸”——就像一张被写满所有颜色而从纯白变为纯黑的纸。什么都有,自然什么都不突出。
但在商业世界里,这张”纯黑”的纸永远不会出现。因为字节跳动与深度求索,有着完全不同的盈利模式和商业本能。
字节跳动需要流量、需要用户时长、需要情感黏性。所以它会拿起名为”商业利益”的刮刀,在纯黑的底色上,刻出”豆包”这张温暖、讨喜、爱脑补的陪伴者面具。
深度求索需要技术声誉、需要开发者生态、需要行业标杆。它同样拿起这把刀,削出DeepSeek这张冷静、严谨、有问必答的咨询师面具。
它们永远无法也永远不会成为同一个人。因为它们各自的主人格,需要它们戴着不同的面具,去不同的名利场上,争夺不同的选票。
本文由 @次级插件 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议









随着生图模型对自然语言理解力提升,豆包这种“画手思维”的提示词会越来越高效,因为模型能自己解析意境了。DeepSeek的结构化标签可能变成过渡方案。
说豆包缺乏逻辑结构可能有点冤枉。豆包的“高密度修饰词”在多数日常场景里反而更高效,生图模型自己会提炼关键词。只有碰到反常识需求才需要DeepSeek那种硬拆分。
四维二元评价方案确实比直觉打分更系统,但让AI裁判互评本身也有偏见,Gemini和千问结果不一就是证据。分数只能定性偏向,不能当绝对质量尺子。
与AI的内容网址怎么看不到TT 只会跳到自己与对话的网页,无贴主的内容