
 起点课堂会员权益
起点课堂会员权益后台截图一扔,你的Agent是不是也傻眼了
现阶段很多人都在卷各类 Agent 自动化。但说实话,大部分产品真到了实际业务场景,经常连个最基础的后台配置按钮都找不明白。我们总觉得是模型智商不够、推理掉链子,但很少有人意识到,它其实是眼睛"瞎"了。这篇文章不聊虚的算法架构,就想结合我自己在多模态项目里的踩坑经历,聊聊幕后的 AI 训练师到底是怎么给 Agent 装上"眼睛"的,以及为什么多模态下半场的胜负手,早就变成了谁的数据生产体系更硬核。

别误会,它翻车可能真不是因为脑子笨
过去半年,我把市面上能跑的 Agent 产品几乎体验了个遍。不管是大名鼎鼎的 Computer Use、各类 Browser Agent,还是国内主打自动化操作的工具。
有一次我故意给某某 Agent 挖了个坑,任务很简单:登录后台,找到指定页面,修改一个配置项。结果它在页面里来回跳了十几次,最后居然把一个明显不可点击的灰色按钮当成了下一步目标,在那疯狂死磕。当时我坐在屏幕前,第一反应倒不是觉得这模型太笨,而是冒出一个直击本质的疑问:它真的看懂自己面对的是什么了吗?
后来读了越来越多多模态项目的底层资料,我开始意识到,现在很多 Agent 翻车其实根本不是推理环节掉链子,而是发生在更早的视觉理解阶段。换句话说,它不是脑子不会思考,它是眼睛压根没看明白。
如果说过去的大模型像一个知识渊博但被蒙上双眼的学霸,那么今天的 AI Agent,才算是在慢慢睁开眼睛。
到了2026年,AI不能再当”盲人”了
前几年整个大模型行业卷速度,把互联网圈打得措手不及。从最开始的 ChatGPT,到后来 Claude、Gemini、DeepSeek,再到国内的豆包和 Kimi,写方案、码代码、做分析,确实让人惊艳。但这里头一直有个绕不开的硬伤:它们其实是个”盲人”。
你让它洋洋洒洒写几千字商业计划书毫无压力,但要是扔过去一张复杂的后台系统截图,跟它说”帮我把这个页面上的数据配一下”,很多模型瞬间就露馅了。毕竟现实工作里哪有那么多纯文本,我们天天面对的都是 App 界面、Excel 图表、流程图、网页后台甚至摄像头数据。过去那种只听指令、只会读文字的”秘书型”模型,一碰到图像立刻就抓瞎。
到了 2026 年,行业风向明显变了。大家不再满足于让 Agent 听懂话,而是逼着它去看懂世界正在发生什么。从海外的 Computer Use 到国内各家厂商疯狂投入 GUI Agent 研发,视觉能力已经从加分项变成了及格线。理解不了屏幕,Agent 就无法进入现实的业务场景。
别把多模态模型当成高级版的OCR了
部分产品经理刚接触视觉模型时容易有个误区,觉得图片识别不就是高级点的 OCR 吗?说实话,这两者完全不是一个时代的产物。
传统的 OCR 极其死板,看到图片里的”销售额 500 万,同比增长 20%”,它就只负责把这串字抠出来,至于这数据对公司来说是好是坏,它完全没概念。而现在的视觉语言模型(VLM)是在做语义推理。同样看一个电商页面,它不仅知道哪里是图片、哪里是价格,还能推断出”当前商品在促销、用户选好了规格、立即购买按钮是灰色的,而灰色意味着库存不足不可点击”。
业内把这种看懂画面的核心能力叫做”图文对齐”。模型当然不会像人类一样用肉眼看图,它是把图片切成无数个像素小块,翻译成自己能理解的 Vision Token,再把文本拆成普通的 Token。接着,把这两拨数据强行塞进同一个语义空间,逼着图片和文字坐下来学说同一种方言。当它看到猫的照片时,脑子里浮现的不是一堆像素点,而是”猫、宠物、毛茸茸、坐在沙发上”这一连串语义。而真正推着 Agent 往前走的,是从看图识物进化到了空间推理和动作规划。面对一个美团 App 页面,它要像人一样判断搜索框在哪、商家列表在哪、哪个能点、下一步该点谁。有了这种视觉定位能力,Agent 才有机会真正上手操作屏幕。
算法决定上限,但数据才决定底线
在学习这些多模态项目的过程中,我以前一直有个迷思,总觉得多模态能力的提升肯定是靠模型架构的升级。但后来翻了一些技术报告,对比了不同模型在同一批图片上的表现后,发现我错了。
很多时候能力差出一大截,根本不是参数量的问题,而是背后的训练数据覆盖得够不够。算法可能决定了模型的上限,但真正决定落地表现的,是幕后那些 AI 训练师在数据工程里流的汗。多模态的数据规模大到有些超乎想象,成熟的项目基本都是数十亿级别的 UI 截图、视频帧和文档等等。更要命的是,这些数据不是靠数量堆出来的,而是靠质量磨出来的。
最基础的阶段,训练师要教模型”认识世界”,对着一张图写描述,比如画面里有个女孩在咖啡馆喝咖啡。接着是定位训练,用边界框把目标框出来,告诉模型”用户说的猫在屏幕的这个坐标里”。再往后是极其烧钱的语义分割,得逐个像素去标注行人、路面、建筑。
但最难的其实是教模型学会常识和推理。如果只是死板地识别出夜间道路和建筑,价值很低。好的训练师会故意问它”当前环境安全吗”,然后引导模型给出”环境较暗、人流稀少、建议提高警惕”这种带有人类常识的回答。
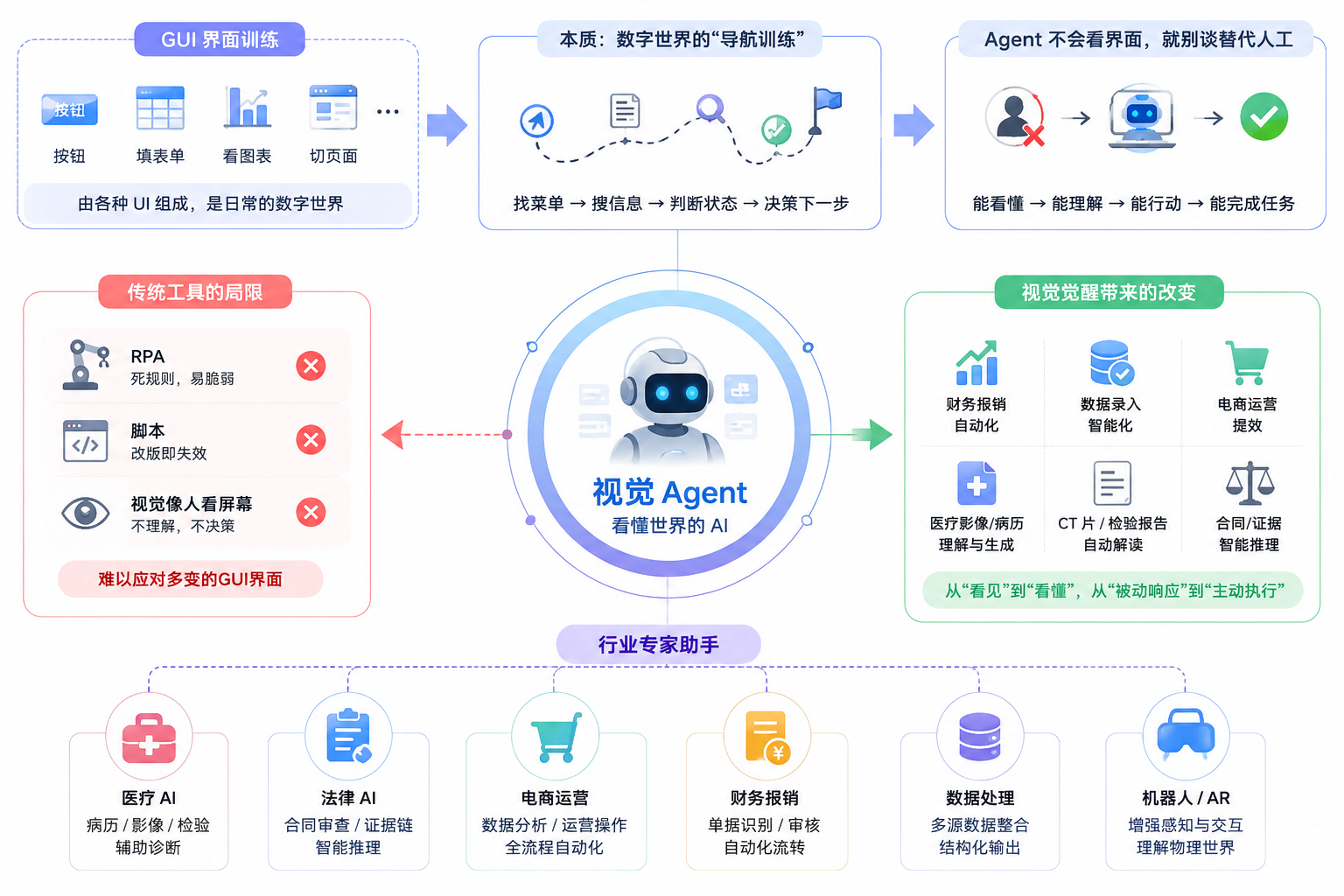
让人头秃的GUI界面训练
如果说自然场景的训练是教模型认物体,那这两年最火的 GUI 界面训练,就是教模型去认工具。
互联网世界说白了就是由各种 UI 组成的,点按钮、填表单、看图表、切页面是用户每天的日常。Agent 如果不会看界面,就别谈什么替代人工。在实际训练中,训练师做的事情特别像在教一个从来没上过网的人用手机,得手把手教它找菜单、找搜索框、判断页面状态、决定下一步点哪。这本质上就是一套数字世界里的”导航训练”。
回归到商业落地,对于我们这些移动互联网从业者来说,这波视觉觉醒到底改变了什么?
首先遭殃的可能就是传统 RPA。那类工具太依赖死规则,页面稍微改版一次,脚本全废。而视觉 Agent 像人一样直接看屏幕,界面有点小变动也能自己适应。这会彻底颠覆财务报销、数据录入、电商运营这类机械化的重复工作。其次是行业专家助手,比如医疗 AI 可以同时把病历文字、CT 片、检验报告合起来看;法律 AI 也能把合同和证据照片连起来推理。再远一点,像机器人和 AR 眼镜,一旦解决了”看不懂世界”的视觉卡点,硬件落地的天花板也会被瞬间拉高。
视觉大模型的落地阵痛!
不过,跟风涌进去的团队,现在踩坑的也不少。最大的误区就是觉得”模型看得见了就等于理解了”。
第一个让人头疼的深坑是视觉幻觉。以前聊天时胡说八道也就算了,现在看图表也开始瞎编。折线图明明在跌,它能硬说成是上涨;财务表格明明亏损,它却能看出盈利。这种错误在金融和医疗场景下简直是灾难。
其次是永远填不满的长尾问题。暴雨天气、夜间工厂、各种奇葩的特殊 UI 或者极端设备界面,现实世界太复杂了,训练数据很难覆盖全面,而这些边角情况偏偏决定了产品上线后的真实表现。
结果就是很多团队发现,模型训练费虽然降下来了,数据费反而飙上去了。因为海量数据没用了,大家都在抢那些少量、高质量、高一致性且带有深度推理价值的”黄金数据集”。
最后的几点老实话
在看那些标注规范和 Bad Case 的时候,有个现象让我印象挺深的。同样一张图,不同的训练师关注的点完全不一样,有人看主体,有人看背景,有人盯文字,有人抓行为。而这些主观认知的差异,最终都会被揉进训练数据里。
这也让我想明白一件事:训练模型的过程,说白了其实是在训练我们人类自己如何去描述这个世界。模型身上的很多灵性,不过是无数幕后训练师认知的集合。
未来几年,多模态竞争的核心绝对会从算法竞争卷向数据生产体系的竞争。Prompt 没那么神了,随着模型能力逐渐趋同,真正拉开差距的,是那些懂业务场景、能设计出高质量数据、能沉淀行业闭环的人。
所以如果问我现在该做什么,我的建议很务实:别光看测评文章,直接拿自己手头最真实的后台截图、PRD 或者数据报表去调试模型,看看它在哪聪明、在哪卡壳。同时,还得培养点数据思维,遇到产品 Bug 时多想想”如果我要训练 Agent 搞定这个问题,需要喂给它什么样的数据”。
哪怕是个人学习,也可以开始存一些 UI 截图和 Agent 失败的 Bad Case。一年后你也许会发现,这些真正踩过坑的数据,比收藏夹里躺着的上百篇 AI 理论文章值钱得多。
模型天天在迭代,但这波浪潮里真正能构建起护城河的,可能恰恰是那些在幕后定义评测标准、死磕高质量数据和沉淀真实场景的人。
本文由 @下一个Token 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供









训练师真是辛苦,一张图要标几十个属性,模型还不一定学得会,这活太磨人了。
可不嘛,标完模型还给你来个反向输出😓
认可视觉理解是当前瓶颈的判断,但也不该完全忽视推理层的局限。有些场景下模型确实看到了正确元素,但决策逻辑依然出错,视觉和推理是两码事。
是呢,视觉是前提不是全部,看对了走错也是常见,两个问题得分开治
Agent翻车常常不是因为推理弱,而是视觉理解没跟上。多模态模型需要图文对齐和空间推理,真正拉开差距的是数据质量和训练师的标注功底。未来拼的是数据生产体系,而不是单纯的算法参数。
认同