
 起点课堂会员权益
起点课堂会员权益AI脸的审美危机:我们厌恶的不是丑,而是被格式化
AI生成内容正在引发一场审美危机。从短视频平台泛滥的'AI脸'到大学申请文书的趋同化,我们正在经历一场由数据蒸馏带来的'平均化灾难'。本文深度剖析技术机制与人文冲击,揭示当'优化'变成'同质化'时,那些看不见的思想多样性如何悄然消失。

“这张脸,我快看吐了。”
如果你刷过短视频或者小红书,大概率见过那张脸。
五官精致,眼睛够大(略显三角),鼻子够小,皮肤永远白皙,永远柔光滤镜,嘴角弧度刚刚好。单独拎出来任何一个特征,你都挑不出毛病。但凑在一起,就是让人浑身不舒服。

更让人崩溃的是,这张脸无处不在。校园里的白月光是她,古装剧里的大小姐是她,五六岁的小女孩是她,七八十的老太太还是她,甚至还长在了小伙子和老头脸上。你刷十条视频,有五条是这张脸,像在玩《生化危机》,满屏都是伪人。

于是,“对AI脸生理性厌恶”登上了热搜,评论区一片共鸣。
但我想说,这件事比一个热搜词条要复杂得多。我们真正厌恶的,不只是那张脸。
01 那张脸是怎么来的
先说技术层面的原因,因为这件事不是偶然,是系统性的结果。
“差评X.PIN”的世超说,你在视频平台输入“女生骑自行车”这样的提示词,平台后台会对它进行“优化”。你以为模型收到的是你的原始指令,实际上它收到的可能是这样一段话:
“一个年轻漂亮的亚洲女孩,在阳光明媚的林荫道上骑自行车。她皮肤白皙,五官精致,大眼睛,小鼻子,长发自然飘动,穿着白色连衣裙,脸上带着甜美微笑。镜头为中近景,柔和自然光,浅景深,电影感画面,清新唯美风格。”
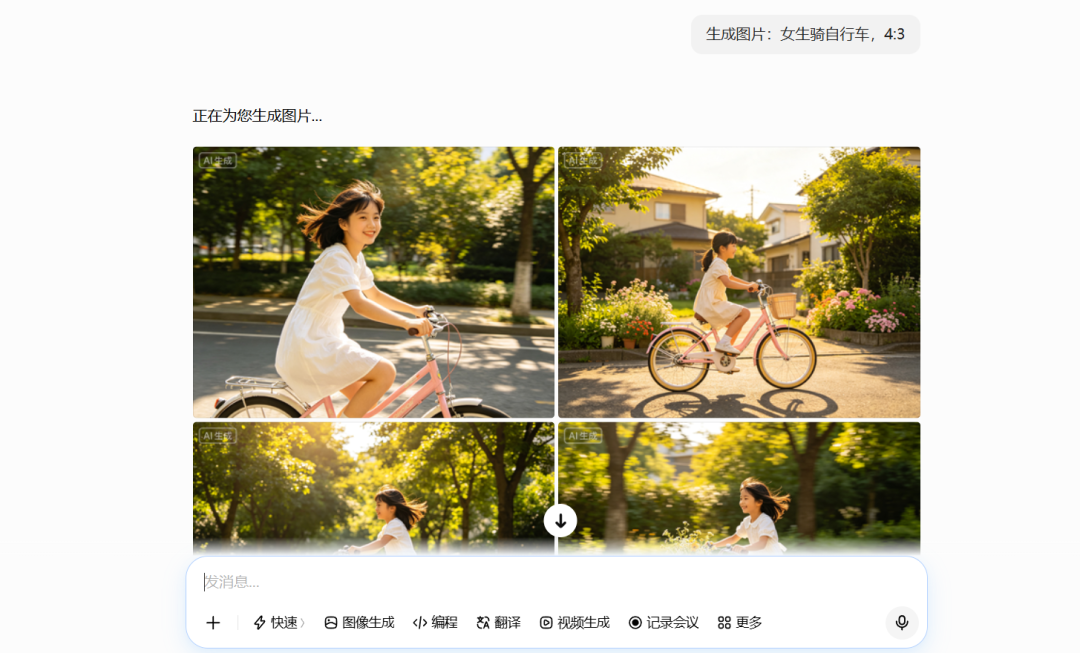
一个用户这样被补充一次,叫提示词优化。成千上万个用户都被这样补充,就变成了流水线。
还有更深一层的原因。图像和视频模型在训练时,学习的是“什么被人类认为是好看的”,大量被打上“美女”标签的数据,本就集中在某几类网红脸上。模型学到的审美,从源头就不多样。
视频模型还有一个图像模型没有的额外压力:它生成的人脸,不只要好看,还要在几十上百帧里保持前后一致。五官对称、轮廓标准、特征不极端的脸,转头不易崩,表情好控制。所以模型会天然偏爱这类脸。
平台想要安全漂亮的,(被推算出来的)用户喜欢网红脸的,模型偏爱稳定标准的。三边合力,那张让人看吐的脸就诞生了。

02 我们厌恶的不是差,是平均
现在,我想做一个重要的辨析。
我们讨厌AI脸,不是因为它丑。恰恰相反,它很好看,或者说,它符合一种被反复验证过的好看标准。
问题不在于好不好,而在于好的标准变窄了。
托尔斯泰有一句名言:“幸福的家庭都是相似的,不幸的家庭各有各的不幸。”套用到这里:好看的脸本该各有各的好看,AI脸只剩下了一种好看。
以前的世界里,人的长相有无数种可能性。有人好看在骨架,有人好看在眼神,有人好看在气质,有人好看在某种难以言说的独特性——一颗痣,一道疤,一个不对称的微笑。这些“缺陷”恰恰是辨识度的来源,是一个具体的人留在另一个人记忆里的钩子。

AI给出的是经过数据蒸馏的“平均好看”。它把所有维度的好看压缩成一个最大公约数,然后无限复制。
这就是为什么我们对AI脸的感受,不完全是“恐怖谷效应”——那个概念描述的是“太像真人但又差一点”的恐惧。我们的厌恶里有另一种东西:对被格式化的本能排斥。你的审美系统在告诉你,这张脸是被优化出来的,不是长出来的。
03 同样的事正在文字里悄悄发生
AI脸引发的生理不适,让我想到了另一件事。
乔治城大学心理学教授Adam Green的团队,专门研究创造力与AI的关系。他们分析了2200篇大学申请文书,用一个叫多样性增长率的指标来衡量:每增加一篇文书,能贡献多少新想法?
结论是:每增加一篇人类写的文书,贡献的新想法,始终多于每增加一篇GPT-4写的文书。而且随着文书数量增加,这个差距还在扩大——AI文书的思想多样性,在规模化之后加速收窄。
这个发现值得细想。大学申请文书不是普通作文,它本来要做的事情,是让一个年轻人用文字打动招生官,证明我是一个具体的人,我拥有只属于我的经历,只属于我的欲望,以及只属于我的对世界的理解。
文书和文书之间的差异,本该像人和人之间的差异一样,实实在在,清晰可辨。
现在,AI让文书写得更流畅了,词汇更丰富了,句子更漂亮了。但它们底层的想法,变得越来越相似了。
这是“平均的好”,不是差,不是平庸。好的标准没有降低,但好的标准变窄了。
用一个更直观的比喻:我们的城市,变得更漂亮了、更现代化了,但每个城市都有一个万达广场,每个万达广场长得还都差不多。表面上,城市的质量提升了;实质上,城市的多样性消失了。
04 可见的损失与无声的损失
AI脸和AI文字,表面上是两件事,底层是同一个机制:AI在训练时学习的是“什么被人类认为是好的”的统计平均,然后在生成时向这个平均值收敛。视频模型学的是“什么脸被认为漂亮”,语言模型学的是“什么文章被认为写得好”。机制完全一样,损失也是同一种——用统计意义上的“更好”,替换掉了只属于个体的“唯一”。
但两者之间,有一个让人不安的不对称。
AI脸引发了生理不适,上了热搜,引发了集体吐槽。这是因为真人的脸还在。你刷视频,看到AI脸,再看到真人脸,对比之下,你能感知到差异,差异激活了你的排斥。损失是可见的。

AI文字不一样。文字是思想的载体,如果思想本身被平均化了,你很难感知到损失。那个本该存在的更有个性的想法,从来没有被写出来,它悄悄消失了,不留痕迹,不触发任何不适感。
没有对照,就没有厌恶。没有厌恶,就没有热搜。但损失正在发生。
更让人不安的是,这个过程可能是自我强化的。AI生成的文章、文书、创意,会成为下一代AI的训练数据。每一轮训练,都在向更窄的“好”收敛。平均化不是一个静态的结果,而是一个加速的螺旋。
AI脸上热搜,是因为我们还能感知到损失。
但令我感到恐惧的是,在我们感知不到的地方,损失也许已经不可挽回了。
本文由人人都是产品经理作者【微果酱】,微信公众号:【AI微果酱】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。









确实生厌了,这种倒三角眼的
赞同核心观点。AI作为辅助工具可以提升效率,但关键是在生成环节注入随机性和约束,比如让用户手动选择风格参数,而不是全自动优化。多样性需要被设计进去,而不是指望模型自动产出。
“平均的好”这个判断挺准,但说AI文字完全同质化可能有点绝对。至少目前很多AI写的东西还是能看出风格差异,只是模型确实在向某种“安全”收敛。真正要警惕的是训练数据本身就不够多样。