
 起点课堂会员权益
起点课堂会员权益大模型标注平台产品设计经验总结
在大模型项目激增的背景下,手动调整提示词与模型测评的效率瓶颈日益凸显。本文揭秘一套自研大模型标注平台的实战经验,从动态提示词管理到AI自动测评,深度解析如何通过快捷键标注、多版本对比等创新功能,破解企业级AI应用中的效果验证难题。

因为大模型的项目比较多,调整提示词与模型测评,每次都需要线下脚本跑,非常的繁琐,所以最近忙里抽空,做了大模型标注平台,用于提升项目组的生成效率。系统最近刚上线,跟大家分享下经验以及产品的思考。
01 项目背景
先快速说一下这个产品是干啥的,给不是很了解大模型的同学科普一下。
大模型的项目核心就是不稳定,那么针对调整了提示词怎么快速验证提示词的好坏,出了新模型怎么判断要不要新模型?大模型测评系统,就是为了解决这个场景的问题。
我们这个项目主要是大语言模型相关的标注,至于图像标注等领域,不在本次讨论范围内。
为什么要自己做
大模型测评系统,很常见,有很多现成的系统可以选择,为什么自己建设。
很多测评系统与他们已有的业务耦合太深,例如火山的测评系统,模型仅能选择火山平台模型,我们就无法测试
langsmith/langfuse 的测评系统,整体的交互跟设计,测评功能都比较弱,缺失了很多功能,例如动态提示词,多维度标注,支持初标复标的多层次标注,支持标注快捷键自定义,这些功能都没有,导致实际用起来效率很低。所以当前阶段想要好用,就只能自己做一个。
当然期望后续有个类似的开源项目出来,像大模型观测平台的 langfuse 一样,有个强大好用的大模型标注系统,这样大家就不用自己从 0 到 1建设了。
02 产品设计
大模型管理
这个是最简单,就是管理这个平台支持哪些大模型,用来兼容不同云厂商,包括公司内部部署的各种模型。
这里有个比较容易忽略的就是并发量,这个用于控制整个平台调用并发量,避免把一些公司内部的模型服务器给打爆了。
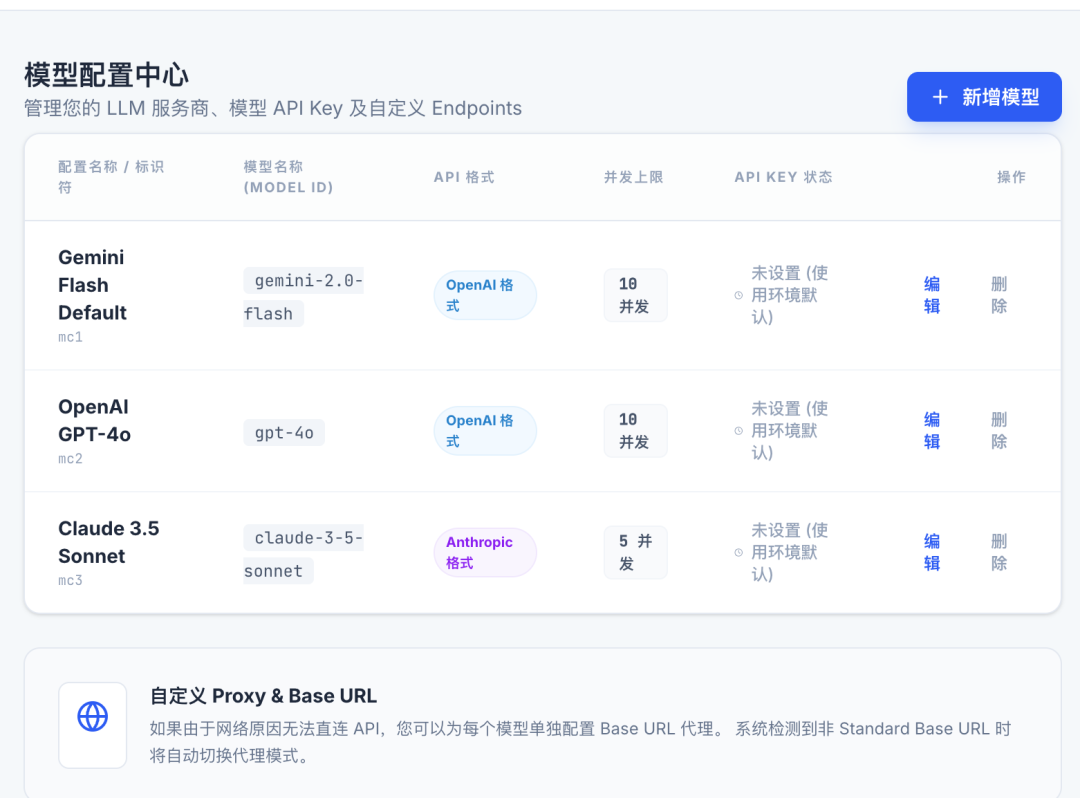
场景管理
用于隔离不同的业务测评场景,每个不同的大模型业务应用,就属于不同的业务场景。从这里去给他做隔离。
每个场景下,需要定义变量类型,定义这个是输入变量还是输出变量。输入变量中,为了兼容不同的场景,需要指定不同的类型(文字、图片、视频、音频等等),用于后续拼接对应的大模型调用参数。
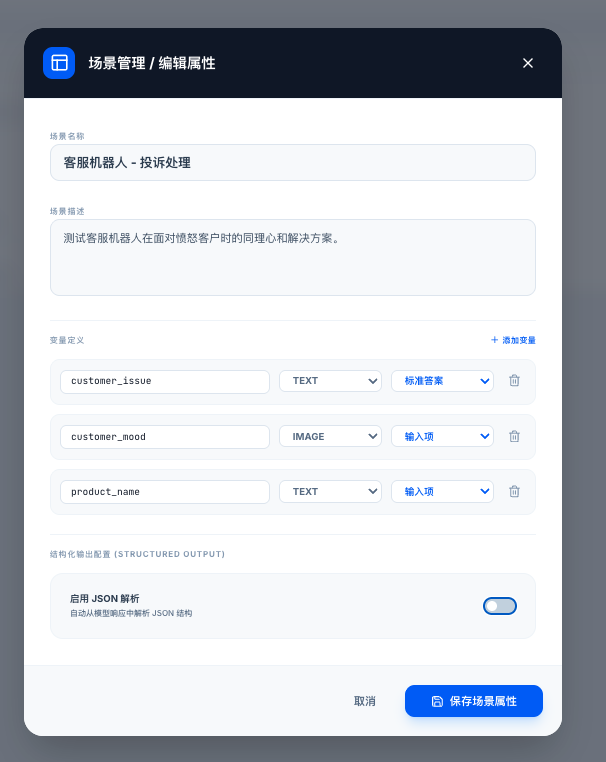
提示词管理
他是基于场景下,设置做不同提示词,这里有个非常特别的点,就是动态提示词功能。我们需要给我们的提示词模板中插入每个测试集中的一些变量。
举个例子,如果是大模型检核的场景,我们需要检查这个用户提供的图片中,是否包含本人的身份证号码。每个测试案例中都会有对应需要检测的身份证号码。
“这个一个点,就是大模型的温度,应该是与提示词绑定的,不同的提示词温度,效果也是不同的。”
测试集管理
基于场景建立不同的测试集,业务侧直接进行维护即可,像公司场景的话,都是大批量数据,所以直接用 excle 导入即可,excle 导入的模板,就是之前在场景中定义的变量,直接导入即可。
单条效果验证
调试效果的时候,调整的时候,很多时候,都是调整特定的几个测试案例,而不是全量重跑,可以在测试集中,加一个快速测评的功能,点击后直接选择提示词版本,单独运此条数据,看看 bad case,是否解决。
执行评测任务
这里就会比较简单了,就是选择大模型、选择提示词、选择测试集就可以执行了。然后系统就会进行运行了,这里同时可能会有多个任务一起在跑,所以这个时候,我们在模型配置的并发上限,就会控制一下,避免服务器被打爆。
然后针对评测的结果能够查看数据,直接与之前导入的标准答案/参考答案对照,方便快速复核结果。
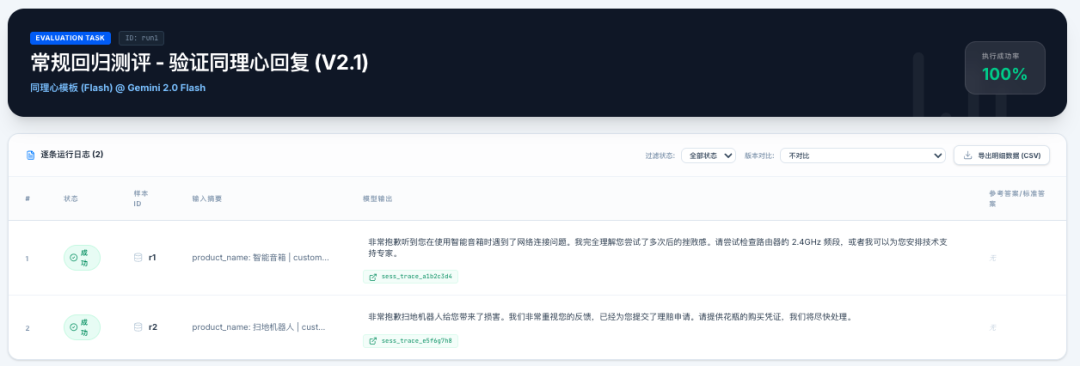
快速对比多个版本的结果
测试不是目的,核心是要对比多个任务,可以直接在运行结果页面,做个多个结果的快速对比,这样就可以快速对比差异结果,看看调整后的提示词结果是正向的还是负向的。
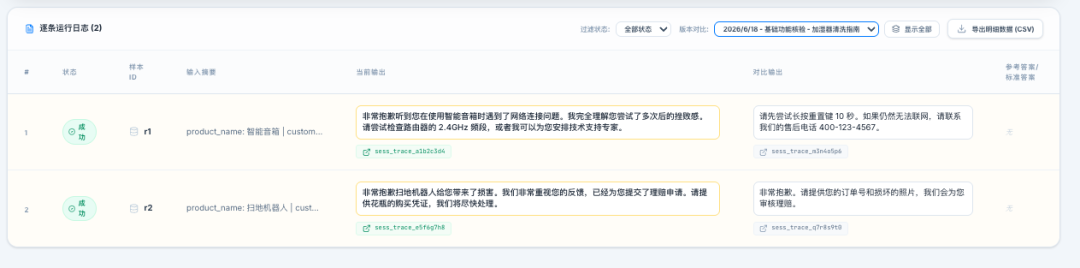
快速的人工标注平台
初标与复标
针对无标准答案的,就需要进行人工标注了,如果标注任务较多,就会涉及到外包先进行标注,然后高级人员再复核的流程,就需要两轮标注
这个相比传统的 excle,对于业务效率提升最大的地方。需要能够针对大模型的结果,进行快捷键快捷操作,我说下比较好用的快捷键。
使用 tab 用于切换不同的标注项,然后通过数字 1、2、3、4、5 标注具体的内容。 使用 enter、shift enter用于快捷切换上条与下条数据。实际的快捷键,看业务侧顺手,怎么顺手怎么来。
03 后续的延伸方向
做到这个程度, 基本就够用了,但是从整个标注平台产品设计中,还有一些其他的功能需要进一步迭代。
自动出分析报告
如果针对有标准答案的,理论上跑完之后,是可以直接出准确性结果的,并且对比多个测试集,是可以出分析报告的。这样的话效果更高。
AI自动测评
针对没有标准答案的发散大模型应用场景,如果数据量比较大, 每次执行之后,每个数据都需要人工标注也不太现实,就可以让大模型直接对于结果进行评估,这个时候。
可以让大模型直接基于多个维度评测,然后综合对比结果。如果有参考答案,可以让 AI 直接针对本次答案,进行对比,这样效果会好很多。但是就是需要业务侧提前写好规范的参考答案。
“这里有个坑,就是如果你直接让 AI 打分 1-100,AI 针对具体的分值把握是不好的,最好将维度拆分,拆分不同维度,分别打分1-10,然后再求和,效果会好很多”
Agent测评
这个是硬核的进阶方向,目前的测评流程,仅能测评单次大模型调用,如果测试 Agent ,涉及多次大模型调用,核心需要测试 Agent 成功率、效率等,测评的流程与考核的指标也会更多。
04 总结
针对大模型应用,搭建一时爽,优化火葬场。如果跟我们一样,是企业级的应用,对于效果有追求,建议尽快搭建自己的大模型测评平台,这样推进起来会快非常多。
如果大家针对测评平台有什么问题或者想要讨论的,欢迎留言。
本文由 @寻走 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


