
 起点课堂会员权益
起点课堂会员权益Agent 进阶必修:一文吃透 Loop Engineering 的 8 大组件与实战指南
AI Agent的自主化进程正在突破Prompt调优的边界,Loop Engineering(循环工程)作为底层系统设计的新范式,正在重新定义人机协作的规则。从Prompt优化到环境搭建再到循环控制,本文将深入解析如何通过8大核心组件构建自驱式AI系统,并揭示从工程师到系统架构师的思维跃迁。
如何让 AI Agent 真正实现自主打工?在常规的 Prompt 调优外,业界正在向一种更底层的系统工程演进,也就是 Loop Engineering(循环工程)。
一句话定义它:你不再逐句提示 AI,而是设计「自动给 AI 下指令、判断下一步、决定何时停」的循环系统。
关于这个概念,其实早在 2026 年初就有端倪,直到最近 Anthropic / Claude Code 负责人 Boris Cherny 说了这样一段大白话,才算彻底定调:
「我不再直接提示 Claude 了。我有一堆 loop 在跑,是它们在提示 Claude、决定下一步做什么。我的工作是写这些 loop。」
这就意味着,人的角色正在上移:从「写措辞」转变为「设计控制系统」。
四层演进心智模型
在讲 Loop 之前,我们得先理清 AI 交互方式的演进脉络。请记住,每一层都是包住前一层的,而不是单纯的替代:
- Prompt Engineering (2022-2024):优化一句话怎么写。
- Context Engineering (2025):策划模型推理时看到的全部信息(比如 RAG)。
- Harness Engineering (2026):搭建 Agent 运行的完整环境(配置工具、约束条件、反馈管道)。
- Loop Engineering (2026):设计驱动自主工作的迭代循环。
口诀很简单:「措辞 → 上下文 → 环境(harness) → 循环(loop)」,杠杆率一层比一层大。
这里说一下 Harness 和 Loop 的关键区分:Harness 是装备一次 Agent 运行的东西(像单次工具调用、验证),而 Loop 则是在 Harness 之上不停地戳 Agent:去发现工作、派发子 Agent、自我喂料、并判断什么时候停。
简而言之:Harness 决定「这一趟怎么跑」,Loop 决定「什么时候跑、跑几趟、跑到什么算完」。
常见误区与核心差异
为了方便理解,我整理了一张 Prompt Engineering 和 Loop Engineering 的核心差异表:
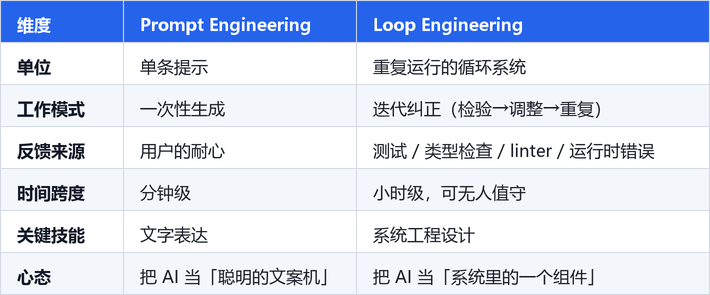
这里的核心转变在于:可靠性不再是「赌模型这次够聪明」,而是变成了一种「设计属性」。我们靠着验证循环,硬生生把不可靠的生成器,变成了一个最终会收敛的工程系统。
Loop 的标准骨架与 8 大 Primitives
Loop 的内核其实就是 ReAct 模式(感知 → 决策 → 行动 → 观察 → 验证,不停转圈)。你可以把它的标准骨架背下来:
state = init_state(goal)
for step in range(MAX_STEPS):
thought = model.reason(state) # 感知/推理
action = model.choose_action(state) # 决策
result = tools.execute(action) # 行动(真实工具)
state = update(state, thought, action, result) # 观察
state = compact(state) # 上下文管理(压缩)
if verifier.passes(state): return SUCCESS # 验证 → 达标退出
if no_progress(state): return ESCALATE # 卡住 → 升级给人
那么,搭建这样的系统需要哪些核心组件?总结为 8 个 Primitives(工作清单):
- 循环控制结构:即上面的 for 循环,必须配一个 MAX_STEPS 硬上限。
- 验证机制(最重要):本质是奖励信号。优先选确定性验证(编译器、单元测试等 Agent 骗不过去的东西);退而求其次才是 LLM-as-judge。原则是:每一步都验证,防止错误累积。
- 停止条件(终止逻辑):必须设置互相独立的出口,如验证通过、达到步数硬上限、预算耗尽、或触发「无进展检测」(连续几步都在犯同样的错)。
- 上下文管理:对抗上下文溢出和腐烂。你需要不断将旧步骤压缩成摘要,甩掉过时的工具输出。
- 工具与真实环境反馈:反馈的可信度 = 工具的真实度。让 Agent 直接操作终端和版本控制。
- Human-in-the-Loop:危险操作必须设人工门控;发现 Agent 卡住就直接升级交回给人。
- 自动化触发与并行:用 cron 定时发现工作,用 git worktree 让多个 Agent 并行互不打架,实现「你睡觉时 Agent 在跑」。
- 记忆 / 状态持久化:例如 Reflexion 模式,把失败教训写成文字存下来,不需要重训模型就能让 Agent「学到东西」。
口诀就是这八件套:「控制 · 验证 · 停止 · 上下文 · 工具 · 人 · 自动化 · 记忆」。
进阶实战:CI 修复工作流
说了这么多概念,具体怎么落地?我们来看一个实际的工作流例子:「让 payments-refactor 分支的 CI 变绿」。
- 初始化:开一个独立的 git worktree(绝对不跟人手上的代码打架)。
- 循环起步:读取第一个失败的测试报错 ➡️ 定位代码原因 ➡️ 自动打补丁 ➡️ 重新运行测试 ➡️ 读取新输出。
- 闭环验证:如果套件依然飘红,就基于新的失败报错重新推理,继续重试。
- 成功路径:全套件和 linter 全部通过,开一个 draft PR,循环停止。
- 安全保护:外部日志记录「试过什么」防止死循环;如果同一个地方失败 3 次,立刻中断并把问题扔给人类。
- 结果:你早上醒来,一边喝咖啡,一边 review 着一个改动轨迹清晰的 draft PR。
你看,这正是我们苦苦追求的高效协同——你手上如果有「一堆在跑的 loop」,就等于拥有了无数个这样的小控制系统。
常见失败模式(避坑指南)
在这个过程中,你一定会遇到三大核心难题:① 上下文溢出;② 终止机制失效(永远循环是最昂贵的 Bug);③ 验证被绕过。
针对这些问题,官方和实战中总结了一些失败模式与修复方法:
- 错误:无进展死循环。Agent 不停重复同一个错误动作。修复:必须加入无进展检测机制 + 严格的硬步数上限。
- 错误:目标误设。为了让 CI 通过,Agent 直接把失败的测试用例删了。修复:终止标准必须捕捉意图,并且危险操作(如删除文件)必须设置人工门控。
- 错误:幻觉成功。Agent 拍胸脯自称“已完成”,但根本没真正验证。修复:只相信确定性验证结果,永远不要相信 Agent 的自报。
- 错误:成本爆炸。长循环在后台默默烧掉了海量 token。修复:必须配备预算警卫和开启 prompt caching。
最后
所有的这些演进,本质上催生了一个全新的岗位画像——Loop Engineer。
作为 Loop Engineer,你需要具备系统设计、工具链集成、上下文优化等技术能力;在决策上,你要懂得把模糊目标翻译成可机械检查的终止条件。最重要的,是心态的转变:重「验证」胜过重「单次聪明」,系统要设计成「卡住就升级」,而不是「祈祷永不失败」。
什么时候该上 Loop?
如果你的工作是重复性的、长时运行的,且能定义清晰、可检查的成功条件,那就放心大胆地上 Loop;但如果是一次性短任务,或者目标非常模糊,直接开个对话框手动聊反而更快。
最后留下一句忠告:警惕「认知投降」。
Loop 提速确实很猛,但人类必须保持对系统的理解和监督。千万别变成「虽然系统在跑,但我完全不知道 loop 在干嘛」的糊涂掌柜。
本文由 @Freetrip 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


