
 起点课堂会员权益
起点课堂会员权益人工智能与人脑
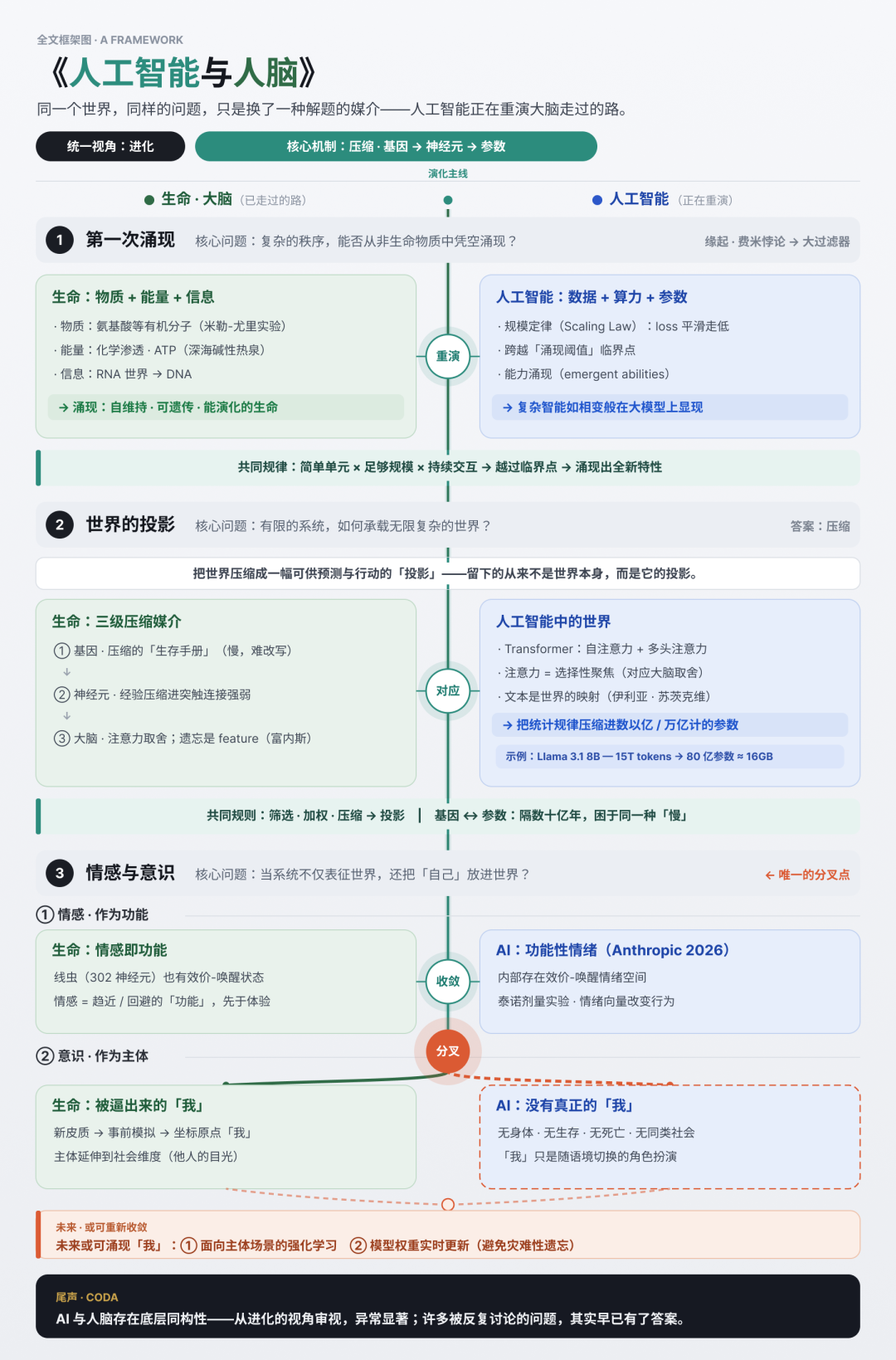
从原始RNA到GPT-4,进化始终是理解智能涌现的关键线索。当深海热泉的化学渗透遇上Transformer的规模定律,生命与AI在数据、能量与信息的耦合中展现出惊人的相似性——它们都在重演那个让无序转化为有序的魔法时刻。本文将以进化生物学为棱镜,折射AI发展中最富哲学意味的认知突破。
我们没有兴趣征服宇宙,我们想把地球延伸到宇宙的边界,我们不知道怎样处理其他的世界,我们也不需要其他的世界,我们只需要一面镜子。
——斯坦尼斯拉夫・莱姆(Stanisław Lem),《索拉里斯星》, 1961年
2020年代初,ChatGPT、Midjourney等新一代生成式人工智能横空出世平地惊雷,再次引发人类社会关于“AI取代人类”的广泛讨论。
这些讨论中,“AI不具备情感”、“AI缺少真正的意识”等论点被反复提及,但始终莫衷一是。抛开那些尚未厘清“情感”“意识”概念的讨论,即便是严肃审慎的脑科学、计算机科学探讨,缺少了一以贯之的主线,最后也不免丢失问题的锚点,陷入到价值判断的泥沼。
这条主线,就是进化。
事实上,人工智能领域诸多核心问题——不管是人工智能的演进方向,还是人工智能与人类的关系,如果将其置于生命进化(尤其大脑进化)的视角下审视,答案其实早已收敛。
例如人类奉若圭臬的“情感”,在进化初期,只是单纯作为一种智力技巧出现,解决的是大脑当时面临的诸如“转向”(“恐惧”使个体避开捕食者)、“强化学习”(“愉悦”使个体重复有利于生存和繁殖的行为)等问题。对照2020年代初的人工智能,“当(自主智能)机器纠正了一项使成本升高的动作时,是否可看作机器在避免疼痛或不适的感觉?当用于测量机器人电池电量的镜头元件产生了较高的成本而致使机器人开始寻找电源时,不正与饥饿的感觉相似吗?”(杨立昆)。
又如人类的“意识”,或者灵长类动物普遍具有的复杂“心智”,集中涌现自大脑最晚进化出的新皮质(由执行相同计算、结构相似的新皮质柱组成)神经突触之间的连接。而仿照人类大脑构建的人工智能神经网络,同样是由大量相互连接的人工神经元组成,执行的也是相似的计算,在功能上,与人脑并没有本质差异。
某种程度上,人工智能在走的路,正是大脑走过的路的重演——同一个世界,同样的问题,只是换了一种解题的媒介。特奥多修斯·杜布赞斯基(Theodosius Dobzhansky)曾说,“生物学中的一切,只有从进化的角度理解才有意义”,而人工智能,也只有当我们转换视角,把它视作进化这一宏大进程在新媒介上的延伸时,才能真正被理解。
1.第一次涌现
无序是有序的源泉。
——伊利亚・普利高津(Ilya Prigogine),1984年
费米悖论
1950年代,物理学家恩里科·费米(Enrico Fermi)提出了著名的“费米悖论”——宇宙是如此浩瀚且古老,理应存在大量智慧文明或文明的遗迹,而人类的观测却始终一无所获。
费米的推演大致分四步:
首先,宇宙极大,宜居行星数量极多。仅银河系,就有1000亿~4000亿颗恒星,数千亿颗行星。基于开普勒、TESS、盖亚等系外行星观测任务的统计数据外推,大约有数十亿到数百亿颗行星位于恒星的“宜居带”——具备液态水以及其他适宜生命出现的条件。

其次,生命一旦出现,给予其足够时间及合适条件,就有可能演化出智慧文明。地球从出现原核生物,到诞生农业文明,经历了约35亿年。考虑到宇宙的年龄已经138亿年,生命具备充足的演化时间。
(顺着这个思路,“有没有外星人/外星生命”这个老生常谈的问题,也可以转换成为一个朴素的概率推断:用一个无比大的数(宜居行星数量),乘以一个大于0的概率(地球本身证明了行星出现生命的概率不为零),最终的结果很难让人相信只是1)
再次,智慧文明发展到一定程度,出于资源匮乏的压力和探索未知的冲动,将本能地向外辐射,发展星际通讯、星际探索,乃至星际扩张。
最后,星际扩张所需的时间尺度,远低于宇宙演化的时间,宇宙理应遍布智慧文明(或文明的痕迹)。以银河系为例,银河系直径10万光年,如果一个文明能以千分之一光速的保守速度航行,且每到一颗星球驻留1000年,完成资源利用与再生产再前往下一站,那么该文明遍布整个银河系,也只需要1亿年(银河系内的宇宙膨胀可忽略),而这还不到银河系年龄的1%。
但在人类实际观测中,宇宙却始终一片沉寂,找寻不到任何地外文明迹象。
于是,费米提出了那个著名的问题:“But where is everybody?”
这个问题至今没有答案。
可能的解释有很多。比如“罕见地球假说”——行星产生复杂生命,需要恰到好处的恒星、恰到好处的行星位置和稳定的卫星,以及恰到好处的板块运动等等一连串巧合;又比如“黑暗森林假说”——任何暴露自己位置的文明都可能被消灭,文明要幸存,就必须保持沉默;还有“大过滤器”假说——从无机物到星际文明的道路上,存在着多道几乎不可逾越的关卡,绝大多数文明都会倒在这些关卡前。
事实上,费米的前两步推演之间,就横亘着这样一道关卡——有了液态水和其他适宜条件,是否一定会从非生命物质中,涌现出生命?
要回答这个问题,首先要定义什么是生命。
低熵的生命
一个被广泛接受的生命定义,是“一种能够进行达尔文式演化的自维持化学系统”。
“系统”,本身意味着秩序——一个生命体,不管是0.3微米的支原体细胞,还是30米长的蓝鲸,内部都维持着极高的秩序。这种秩序层层嵌套环环相扣——众多基础原子堆叠,形成蛋白质、DNA等生物大分子,生物大分子聚合到脂质膜内,又形成细胞,功能相近的细胞结合,构成了组织,组织再组成器官,器官构建系统,最终形成一个完整生命体。任何一个微小错位,都有可能导致整个系统的崩溃。
物理学中有一个专门描述系统混乱程度的概念——熵。熵越高,越混乱;熵越低,越有序。生命的存在,等于在局部区域,维持了一个低熵状态。而根据热力学第二定律,孤立的系统总是熵增的,就好像整理好的房间总是越来越乱,化成水的冰也不会自己重新凝结。秩序天然倾向于瓦解。
生命要在宇宙中维持自己的低熵状态,就必须解决两个问题,一是秩序的维持(对应生命定义中的“自维持”),二是秩序的传承(对应定义中的“达尔文式演化”)。
秩序的维持
秩序的维持,依赖生命源源不断地从环境中获取物质与能量。物质用来提供维持秩序所需的零部件,如脂质、氨基酸、核苷酸等;而能量则用来把这些零部件组装成具体的秩序结构(比如把脂质分子排列成细胞膜,把氨基酸串联折叠成蛋白质,把核苷酸组装成DNA),同时修补不断自发瓦解的秩序。
物质的问题不难解决。1953年的米勒-尤里实验已经证实,氨基酸可以在模拟原始地球大气的环境中自发产生;脂肪酸(脂质的一种)也能在矿物表面或热泉环境催化下自发合成;核苷酸的合成更复杂一些,但研究者同样找到了可行的非生物路径——用氰化物、磷酸盐和硫化物,在紫外线的照射下逐步合成。更重要的是,这些有机分子并不只是存在于地球。坠落的陨石、飞掠的彗星、土卫六浓厚的大气,甚至距离地球数千光年的星际分子云中,都反复探测到它们的存在。换句话说,构成生命的物质原材料,或许从来都不是宇宙的稀缺品。
能量的问题更为棘手。地球上几乎所有生命,不管是动物,还是植物,都依赖于同一套能量机制——化学渗透。简单来说,细胞会持续不断地把氢离子泵到细胞膜的外侧,建立一个高浓度“氢离子水库”;之后让氢离子顺浓度梯度回流,在回流过程中,推动一个名为ATP合成酶的微型分子涡轮转动,制造出生命的通用能量货币ATP。
ATP就像一块块充满电的电池,被运送到细胞各处水解、释放能量,驱动各种需要能量消耗的反应,比如把氨基酸串联折叠成蛋白质、把氢离子泵回“水库”等等。水解之后,ATP变成低能量态的ADP,再回到化学渗透系统中重新充电。生命体内每时每刻都有数以亿计的ATP分子在这个循环里来回穿梭,推动秩序的搭建与修补。
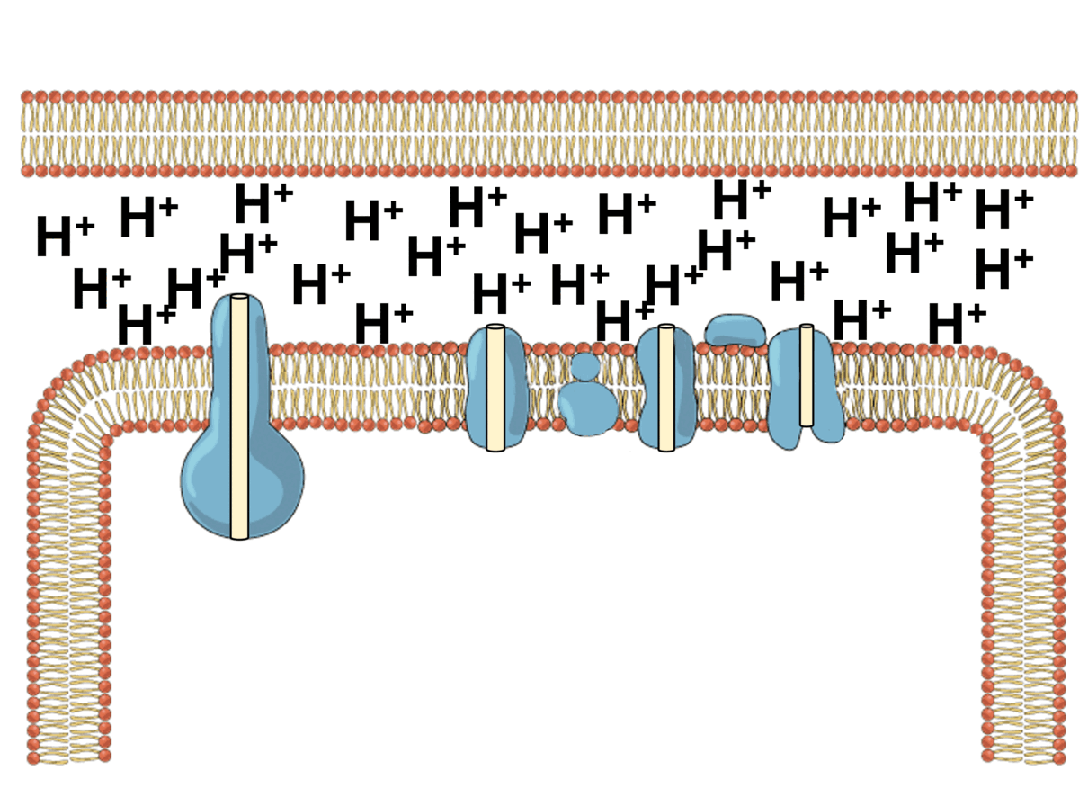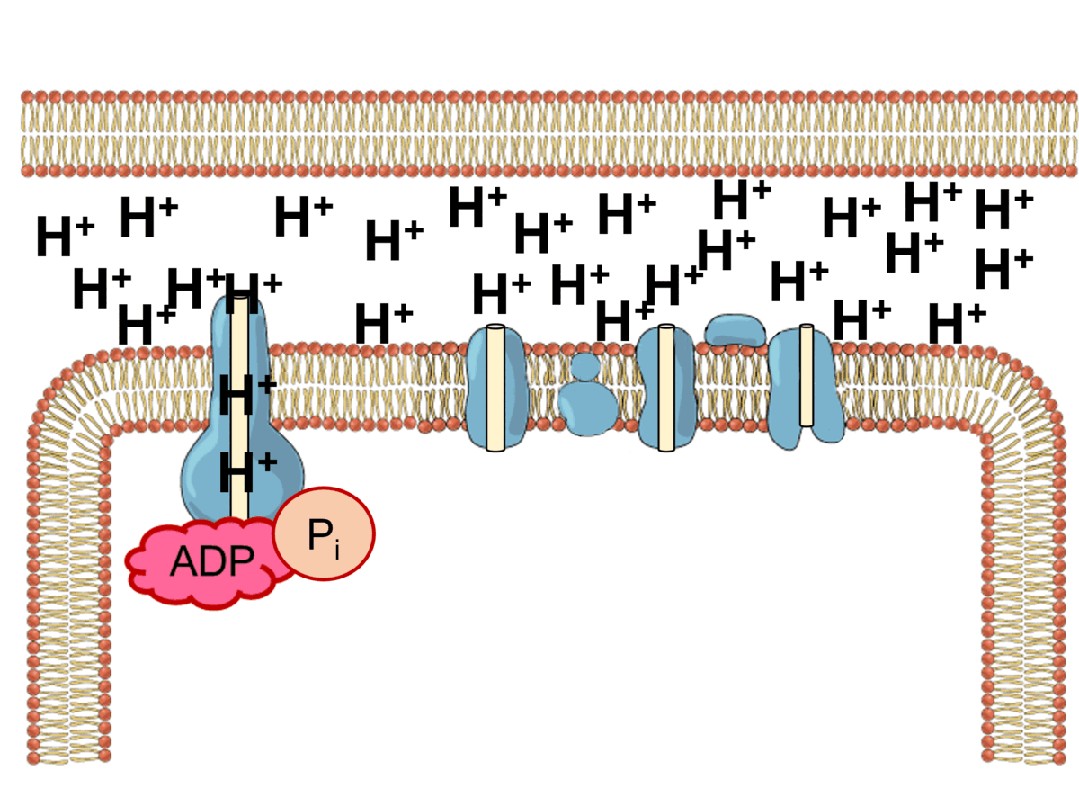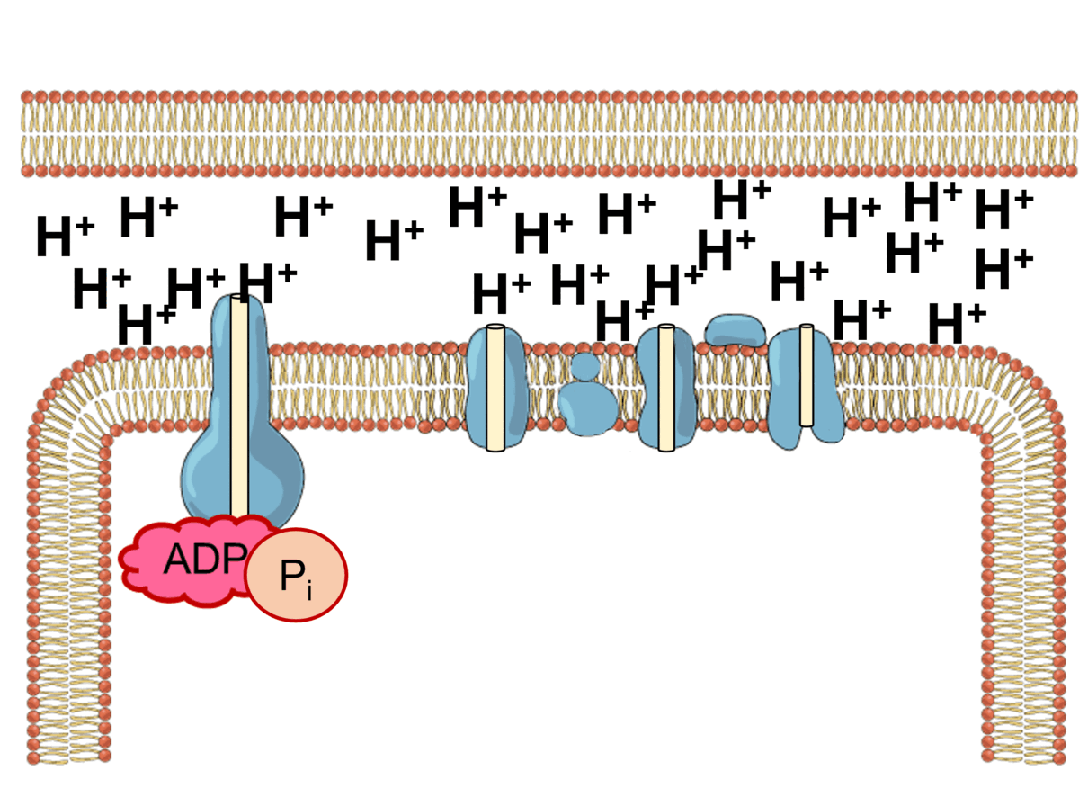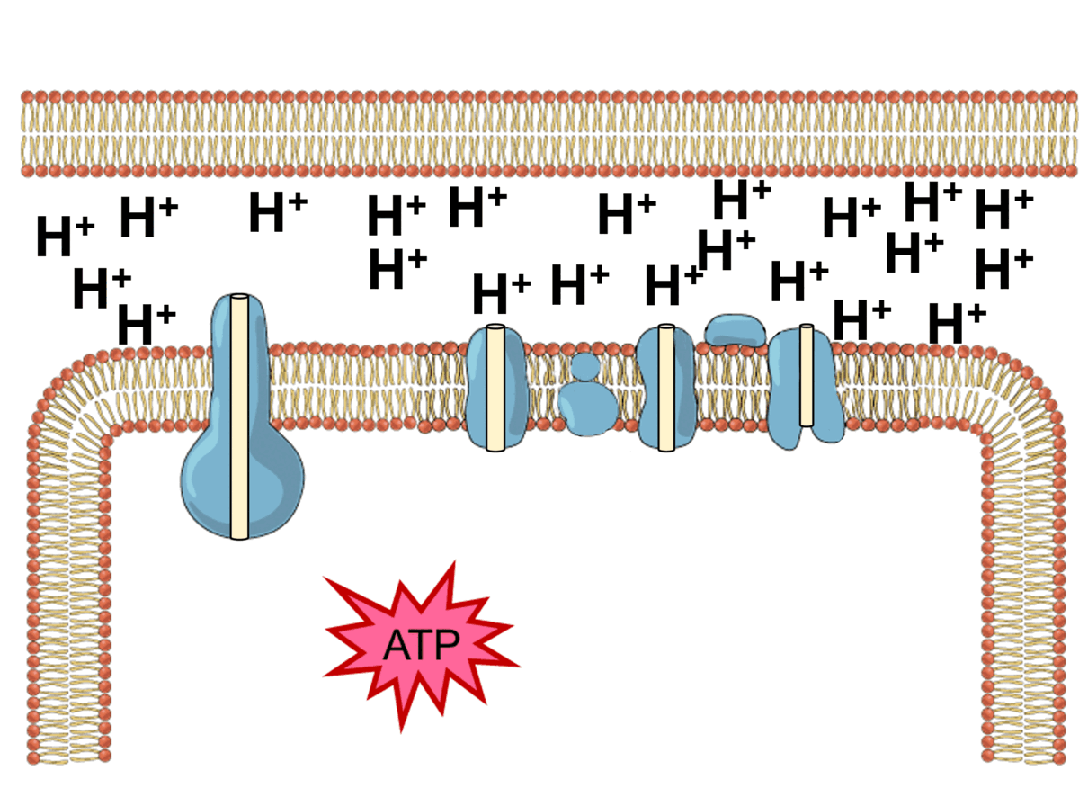
这套能量循环机制异常精巧,但过于精巧,反而让它的起源显得扑朔迷离。化学渗透至少需要三个核心元件协同工作——充当“水坝”的细胞膜、扮演“抽水机”的离子泵,以及“水力发电机”ATP合成酶。三者互相依赖,缺一不可。我们很难想象在生命起源的那一刻,这三个元件恰好同时出现并组装到一起。而如果没有这套机制,最初的生命又无法获得能量、合成这些元件。经典的先有鸡还是先有蛋问题。
这个悖论的出口,是进化。进化并不要求复杂系统一次成型。如同由瞳孔、晶状体、视网膜等精密元件组装的人类眼睛——它的出现也并非一蹴而就,而是从最原始的感光能力开始,凭借一次次微小但真实的生存优势(如辨别明暗、感知方向、模糊成像等等),在长期演化下不断积累放大,最终演化而成(这条演化链上的大多数中间形态,至今仍能在不同生物身上找到对应)。化学渗透拿到的,也是相似的剧本。
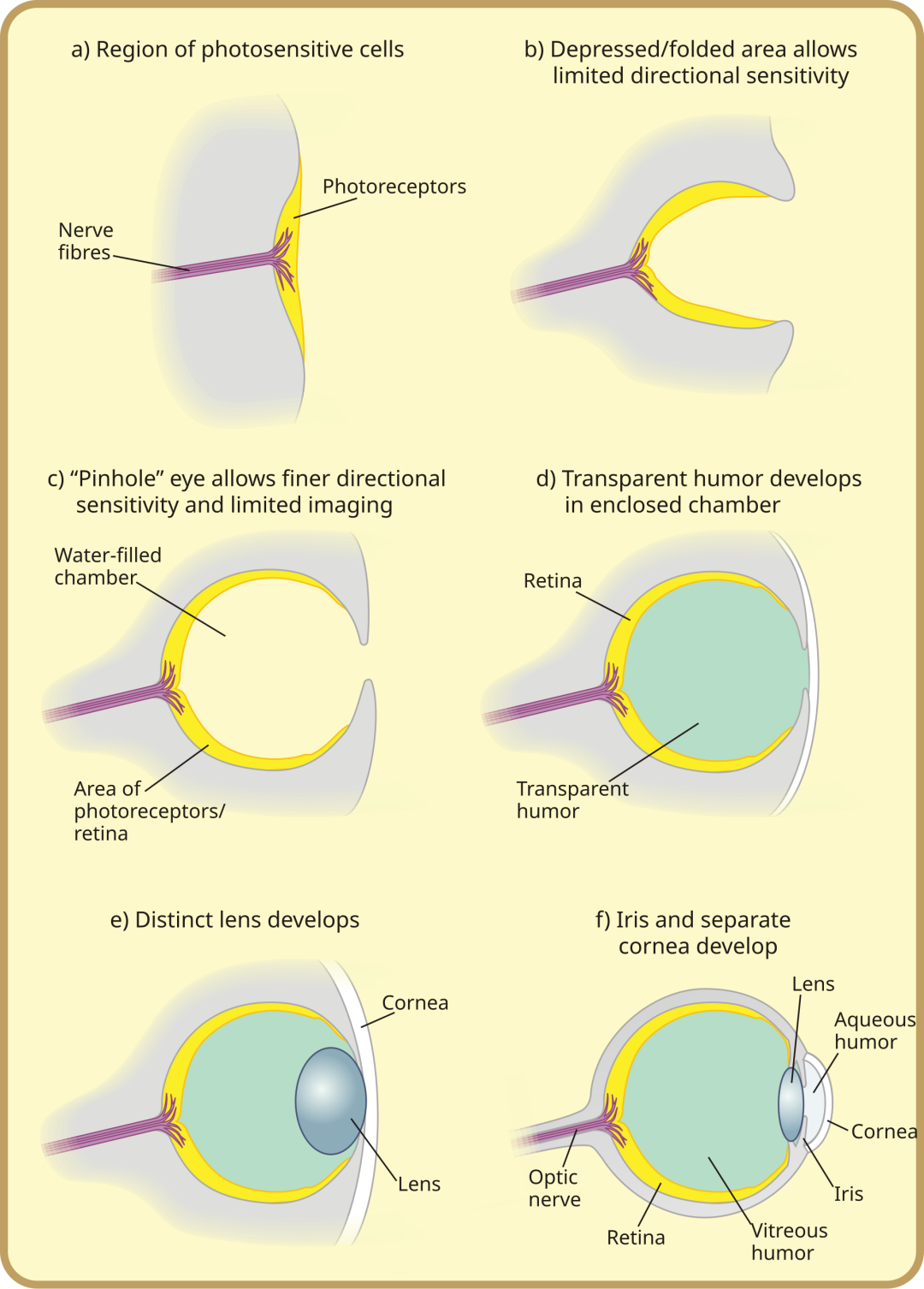
在原始海洋深处,富含氢气、矿物质的弱碱性热泉水从海底喷出,遭遇溶解了大量二氧化碳、呈弱酸性的海水,矿物质在两股水流的交界处不断沉淀,形成蜂窝状的微小空腔。空腔之间的薄壁,天然构成了阻隔氢离子自由流动的“水坝”。与此同时,空腔一侧是弱碱性热泉水,一侧是弱酸性海水,天然形成了氢离子浓度差——虽然没有“抽水机”离子泵,但高浓度“氢离子水库”却是现成的。化学渗透所需要的关键条件,在深海热泉环境中,天然具备了大半。只要演化出可以利用氢离子流动合成ATP的“水力发电机”ATP合成酶,ATP就能够源源不断地产出。
秩序的传承
生命维持低熵状态的另一个必要条件,是秩序的传承。
秩序传承,依赖一套能够跨代传递信息的“图纸”。地球生命选择的是DNA——一条由A、T、G、C四种碱基,以特定顺序排列而成的一维长链。这份图纸的用途,一是信息复制——依靠碱基之间严格的互补配对关系(A与T、G与C),DNA解旋一分为二,再以每一半为模板,各自补全形成两份独立完整的DNA,传递给子细胞。二是信息表达——一维的碱基序列被转录成mRNA,mRNA再翻译出特定序列的氨基酸,氨基酸链自发折叠,形成三维的蛋白质,驱动生命的各项活动。
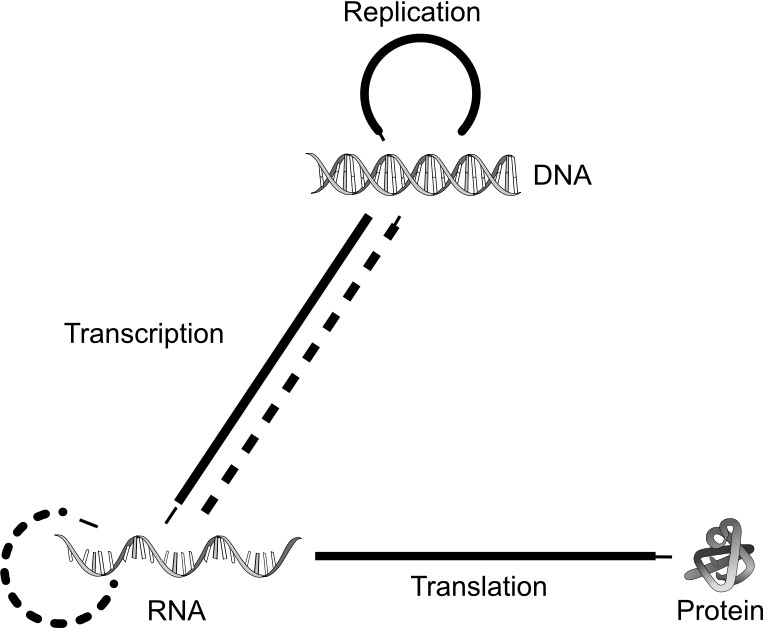
DNA复制有着一套极其精密的工序——解旋、配对、补全,每一步都需要专门的蛋白质酶催化。但这同样导致了鸡生蛋蛋生鸡悖论——复制DNA需要酶(其本质是蛋白质)的催化,而合成蛋白质又需要DNA图纸的指导。
进化给出的答案是原始RNA。原始RNA的碱基序列与DNA类似,可以携带信息,并且它的化学性质比DNA活泼,可以折叠成特定的三维结构,像蛋白质一样去驱动各种生化反应。也就是说,一个RNA分子既可以充当“图纸”——作为模板,携带、复制信息;又可以作为“工匠”——折叠成三维立体结构,催化包括自我复制在内的各种生化反应,驱动最初的生命活动。只要环境源源不断地输入物质和能量,秩序传承的齿轮就能自己转动起来。
涌现
物质、能量、信息,这三块拼图在化学层面单独存在时,都不具备任何“活着”的性质——氨基酸不会自我复制,ATP循环不携带遗传信息,RNA片段在没有能量供应的试管里只是一条惰性分子链。但当三者在深海热泉的某一处微小空腔中,偶然拼接到一起,所组成的整体就“涌现”出所有组成部分不曾具备的全新特性:自维持、可遗传、能演化。
正因如此,“大过滤器”假说中那道从非生命物质到生命的关卡才显得格外凶险。它所过滤的不是物质和能量,也不是信息,而是三者恰好组合到一起的瞬间。我们可能永远无法得知,在宇宙138亿年的岁月长河中,在恒河沙数的宜居行星上,究竟出现过多少次类似瞬间。但至少在地球上,它发生过一次。也正是这次涌现,推倒了进化的第一张多米诺骨牌。
而涌现并不止于生命起源。某种程度上,人工智能也在重演这一进程。
早期的人工智能,受限于训练数据(“物质”)、算力(“能量”)与模型参数规模(“信息”),能够完成的大多是机器翻译、图像分类、语音识别这类目标明确的单一领域任务。
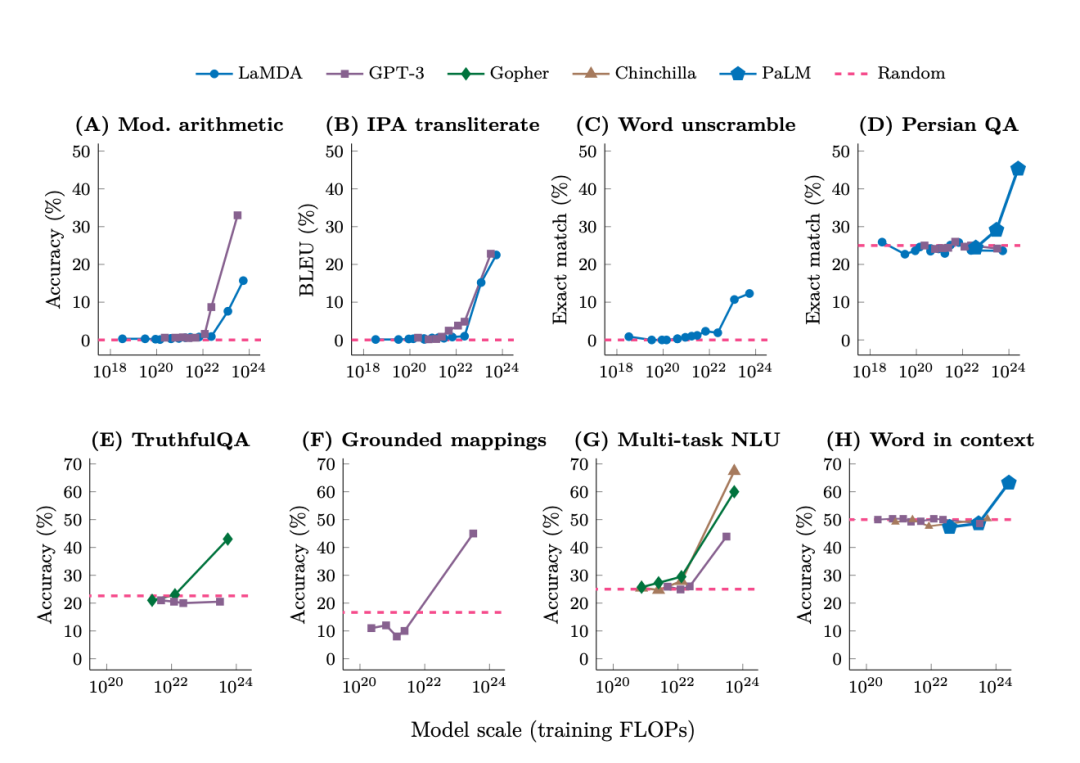
随着数据、算力与参数规模的持续扩张,模型训练损失(loss)以可预测的方式平滑走低,模型犯错越来越少,表现也越来越好,这种现象后来被总结为“规模定律(Scaling Law)”。更耐人寻味的是,当模型规模跨越某个“涌现阈值”后,一些此前从未出现的复杂能力,在模型上如同相变般突然显现。例如基于Transformer架构的生成式大语言模型,最初的训练目的只是预测下一个词元(token),但随着训练规模的持续扩大,模型在完成局部预测任务的同时,意外显示出对知识、语义、逻辑乃至人类意图的抽象建模能力。研究者将这类“小模型上不存在,在大模型上突然出现,且无法从小模型外推预测”的现象,称为“能力涌现(emergent abilities)”。
我至今仍记得ChatGPT发布的那个早晨,从测试它相同问题,每次都能获得迥然不同但通顺回答的惊奇,到不管什么类型、何种程度的自然语言问题,它都能回答的讶异(这些都是我们在做小模型时难以想象的,小模型时代的Chatbot很少“生成”,更多的是基于穷举的意图,输出固定答案或预设参数的模板回复,类似ChatGPT发布2年后的Siri),再到看到它正确解答了经典的“莎莉-安测试(Sally-Anne test)”问题的震撼,那也是我第一次切身感受到机器智能的“涌现”。
(传统机器、细菌受困于0阶意向性——不“回答”问题,只“响应”刺激;大多数拥有实体大脑的动物,上限是1阶意向性——只知道自己想要什么,但不知道别的个体在想什么;黑猩猩等少数动物“可能”具备2阶意向性——能够将自己的认知与其他个体的认知区分开,“莎莉-安测试”测试的就是2阶意向性,这也是社交、合作、欺骗的认知基础;而人类(工作记忆)的上限是5-6阶——可以回答诸如“甲认为乙相信丙希望丁担心戊误以为己根本不认识他”这类复杂嵌套问题,高阶意向性也是人类学区分人与其他物种的一个显著标志。暂且抛开“中文房间”等符号主义争论,ChatGPT等生成式人工智能其实是历史上第一批人类之外的,可以在表现上解答6阶及以上自然语言意向性问题的实体)
OpenAI前研究副总裁、Anthropic的创始人达里奥·阿莫迪(Dario Amodei)就曾在多个场合表达,“就像化学反应——你需要不同的原料。如果某种原料不够,反应就停了。但如果你按比例把原料放在一起,就能得到爆炸或火焰。对AI来说,这些原料就是数据、算力和模型大小。规模定律告诉你:把这些原料投进去,出来的产物就是——智能”,“我怀疑意识是足够复杂的系统的涌现属性——当系统复杂到能够反思自身决策时,某种东西就出现了。”
对于生命而言,物质、能量与信息的耦合,涌现出了最初的自组织系统。而人工智能,则依靠数据、算力与参数规模的累积,涌现出全新的复杂智能。这两个进程并不完全相同,但背后却遵循着同一种规律:当简单单元以足够庞大的规模彼此连接、持续交互,系统整体便有可能在跨越某个未知临界点之后,涌现出组成部分本身从未具备的全新特性。
“涌现”按下了进化的开关。但摆在生命面前的,是一个远比自身复杂的世界。那么,一个有限的系统,又要如何应对一个无限复杂的世界?
2.世界的投影
我的语言的界限就是我的世界的界限。
——维特根斯坦(Ludwig Wittgenstein),《逻辑哲学论》,1921年
设想这样一个场景:一名人类宇航员降落在一个与地球极其相似的行星上,那里有液态海洋、山川湖泊、茂密森林,甚至还有某种看上去像是苹果的果实。禁不住诱惑的宇航员摘下一颗咬了一口。他会中毒吗?——大概率不会。既不会中毒,也无法从中获得任何营养。原因很简单:人类与这颗异星果实经历的是完全独立的进化路径,生化机制几乎不可能兼容。而人类之所以能以苹果为食,能被蛇毒麻痹神经,恰恰是因为地球上的所有细胞生命,都源自同一棵生命之树,共享着同一套生化语言。
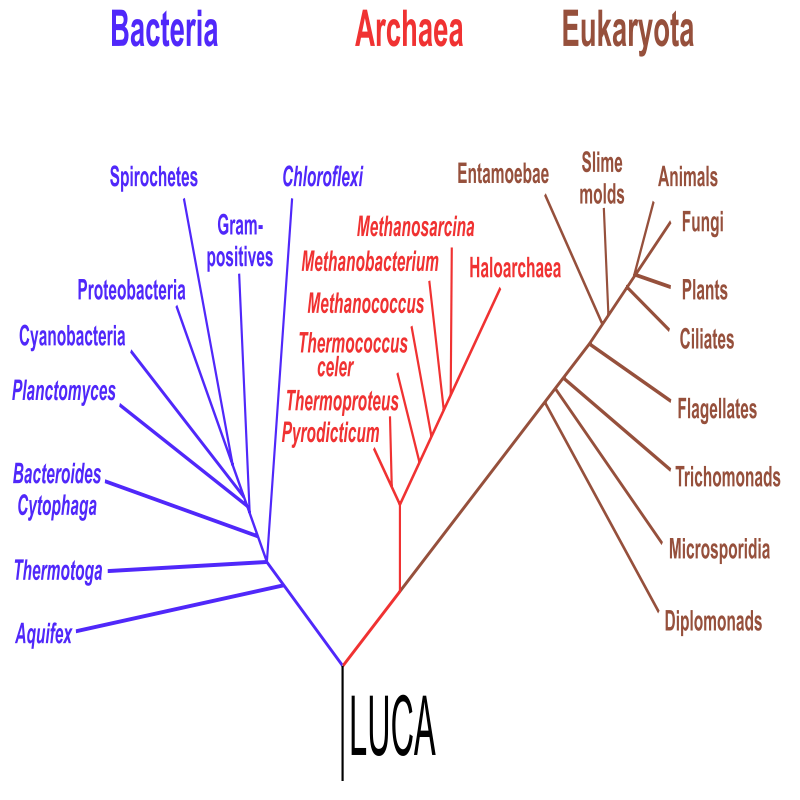
沿着地球生命之树向下回溯,所有分支最终指向了同一个祖先节点——LUCA(Last Universal Common Ancestor,最后的共同祖先)。LUCA不曾留下任何化石,是仅靠逻辑推理和基因组比对还原出来的远古生命。我们之所以相信它存在,是因为现存的所有细胞生命——不管是动物、植物,还是细菌、真菌——都共享着一系列基础生物特征:细胞结构、ATP驱动的能量循环、遗传密码和蛋白质合成系统等等。奥卡姆的威廉(William of Ockham)曾有过一个朴素判断——“如无必要,勿增实体”,与其假设生命在多个独立起源的情况下分别演化出相同的生化机制,更合理的解释是它们同出一源。
某种程度上,整个地球生态,都是LUCA的不同变体。自LUCA之后,生命的演化一脉相承,再未中断或重启——每一个“活着”的个体,都继承了一套在亿万年试错中沉淀下来的生存算法。这套算法源自生命与世界的长期互动,但它编码的不是世界本身,而是外部世界在生命内部形成的投影。
正因如此,生命才得以以有限的身体,应对远比自身复杂得多的世界。此后,生命形态不断分化,这幅投影也在不断延展,但在最初,它的边界几乎完全由基因定义。
基因中的世界
神经元出现之前的漫长岁月里,生命对环境的感知都极为被动有限。那时的生命,大多停留在单细胞形态,没有眼睛、耳朵,也没有神经系统,外界的任何变化,几乎只能以化学反应的方式触达生命——环境中的分子被细胞膜受体识别,营养成分进入细胞并参与代谢,有害成分则会干扰细胞内部秩序,触发毒性反应甚至死亡。刺激与反应之间,不存在专门的信息处理层。
不过,被动的只是生命个体,并不包括它背后的生命谱系。那些有助于生命存续的反应,比如逆境中的休眠,会经由自然选择沉淀到基因之中;无效或有害的反应,则随个体的失败逐步退出。世界在生命内部最早的投影,就发生在这样的过程里。基因因此成了一份高度压缩的“生存手册”——它不解释世界,却规定生命如何应对世界。
但这套方案存在一个天然的局限——基因可以把有效反应写进碱基序列,却没有办法快速改写。任何改变,都必须历经一代代个体的繁殖与死亡,在自然选择机制的筛选下缓慢积累。环境一旦发生剧变,个体往往来不及调整,只能等待新的适应在漫长进化中再次形成。
(无独有偶,基因登场数十亿年后,人类在构建大语言模型等人工智能系统时,遭遇了类似的限制——训练一旦完成,模型内部的参数便随之固定;新的经验无法继续写入,只能等待下一轮训练(这也是我不认可早期大语言模型“记忆功能”的原因,因为它并不随对话或任务的进行,更新模型本身的参数。本质上它只是一个外挂知识库,而人类并不是这样去记忆)。基因与参数,隔着数十亿年的演化史,受困于同一种“慢”)
生命需要一种更快的机制。尤其对于多细胞动物这一支来说,身体变大、细胞分工出现,它们的生存不再只是代谢和繁殖,还多了收缩、转向、捕食和逃离。动物只要还活着,就必须持续接收、处理信息,并根据环境变化及时调整行动。
于是,神经元出现了。
神经元中的世界
神经元处理的是实时信息。
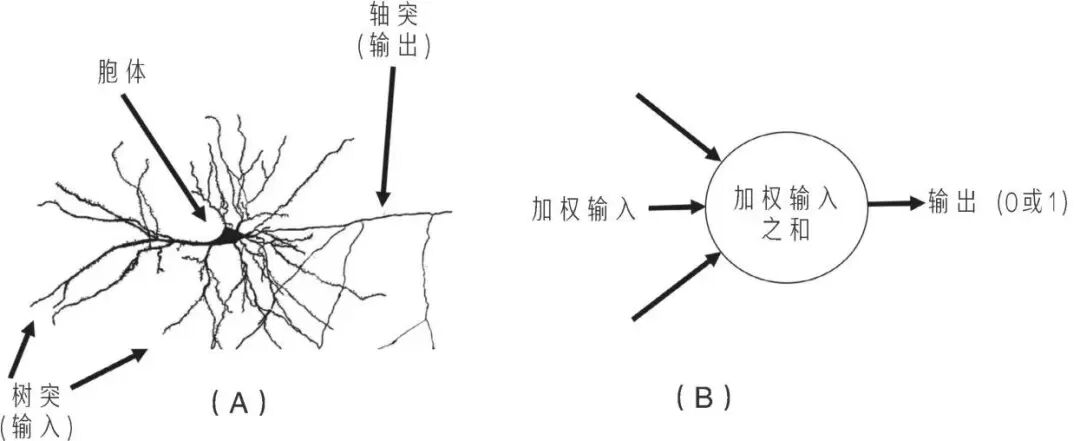
水流的扰动、化学梯度变化等外部刺激,首先会被多细胞动物体表的感觉细胞所捕捉(想象模型的输入层),并转化为电脉冲。电脉冲沿着神经元轴突传导,通过突触(模型的连接+权重),传递给下一个神经元。信号经过层层传播,最终抵达负责执行动作的效应细胞,驱动身体的收缩、转向、捕食和逃离(模型输出)。
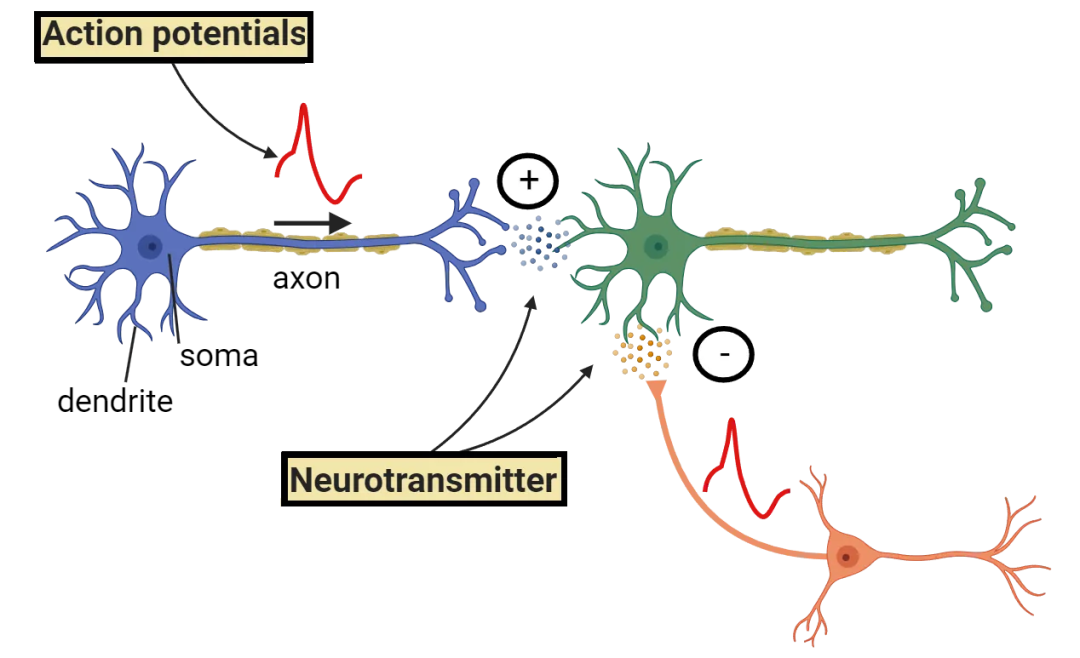
更为重要的是,当某种信号模式反复出现,相关神经元之间的连接将逐渐加强,而长期不被触发的连接,则会减弱甚至消失(权重的更新)。动物一生中反复出现的经验模式,就这样被压缩到突触连接的强弱之中。
相较于单纯的化学反应,神经元带来的真正变化,是把刺激接入到一套专门的信号传递系统。外界的变化不再只是改变附近细胞的化学状态,而是转化为可传播、可放大的电信号,在身体内部扩散。
但早期的神经系统,距离“大脑”还相距甚远——神经元分散在身体各处,局部连接成网,某处受到刺激,附近的神经回路随即被激活,带动相应部位做出反应。早期神经系统解决的是“从点到面”的快速响应,但还无法支撑牵动全身的复杂行动。
大脑中的世界
约5.5亿至6亿年前,两侧对称动物出现了,动物的身体第一次有了稳定的前后轴,开始区分前后、左右、腹背,运动也因此有了更明确的方向。这个看似不起眼的变化,彻底改变了生命与环境信息交互的方式——对于之前的辐射对称动物来说,信息是从四面八方同时涌来;而两侧对称动物,则是前端更频繁地接触未知环境——食物、障碍、猎物、天敌等与生存密切相关的信息,更容易从前方进入感知范围。信息也因此出现了强烈的空间偏置。
在运动方向与信息偏置的共同作用下,感觉器官开始向前聚集(“头化”),与之相连的神经元,也随之向前端汇聚。前端不再只是身体的一个方向,而是逐渐成为生命试探世界的入口。随着越来越多的信息从前端涌入,神经系统也承受着更强的整合压力——“感觉”需要被汇总,身体需要被协调,生命也需要在行动之前,判断是该趋近、避开,还是停留。大脑的雏形,正是在这样的选择压力下出现。
但信息汇聚到大脑以后,问题并没有因此了结:这些输入还需要经过加工,才能真正服务于判断和行动。而大脑无法平均处理所有海量细节,只能把注意力投向那些更有区分度、更能影响行动结果的结构与特征。
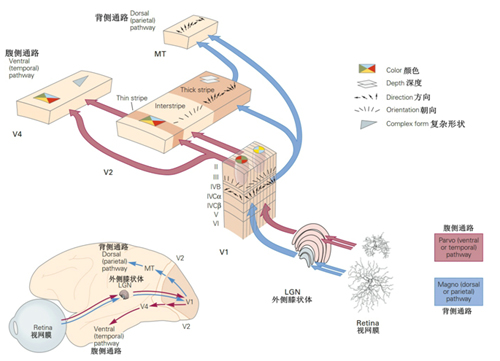
以视觉系统为例,视网膜每秒送往大脑的信息以千万比特计,但真正进入意识、被我们“看到”的,不过几十比特。这个过程并非粗暴的“有损压缩”,而是主动的取舍。视网膜并不记录每一个光点,它优先提取的,是明暗边界、色彩差异、运动方向等更能指导行动的特征。
这些特征信息进入视觉皮层以后,会被进一步归并组合:边界连成轮廓,移动形成轨迹,局部特征汇总成物体、空间与运动。随后,这些信息沿着不同视觉通路继续在脑中传播,一条通向形态、颜色和物体的识别(腹侧通路),另一条则通向空间、运动和视觉引导行动(背侧通路)。其中与行动相关的线索,将被放大凸显,而重复、稳定的背景,则隐入意识边缘。就像一面铺满整个视野的白墙,几乎激不起大脑的任何反应;而白墙上一只爬动的蚂蚁,却会牵动一整片神经元同时放电。
然而,这种取舍不止发生在看见的瞬间。之后的记忆也是如此。
博尔赫斯在短篇小说《博闻强记的富内斯》中,虚构过一个拥有完美记忆的人富内斯。在一场坠马后,富内斯不再遗忘——他记得天上每一朵云的形状,也记得见过的每一片叶子上的每一道纹理。然而,富内斯却几乎无法思考。因为“思考,是遗忘差异,是概括,是抽象”。在富内斯那个拥挤不堪的世界里,只剩下纤毫毕现的细节,没有一般,也没有普遍。他看得到一切,却理解不了任何东西。
富内斯的不幸,或者说博尔赫斯用小说写出的直觉,恰恰说明了遗忘并不是大脑的bug,而是feature——没有遗忘,经验就无法摆脱细节的堆积,理解也就难以发生。
重要的,从来不是记住一切,而是把注意力投向何处。
这个道理,后来被一群研究员用另一种方式,重新表达了一遍。
人工智能中的世界
2017年,谷歌团队的8位研究人员发表了一篇标题直白到近乎挑衅的论文《Attention Is All You Need》。这个标题,像是对当时主流序列模型的宣告:循环网络不是必需的,卷积网络也不是必需的,真正重要的,只有注意力。

论文提出了一种全新的人工智能网络架构Transformer。它起初只是为机器翻译而设计,却在日后成为GPT、Claude、Gemini 等几乎所有大语言模型的共同基座。某种程度上,Transformer之于大语言模型,正如LUCA之于地球生命——枝繁叶茂,皆由此分叉。
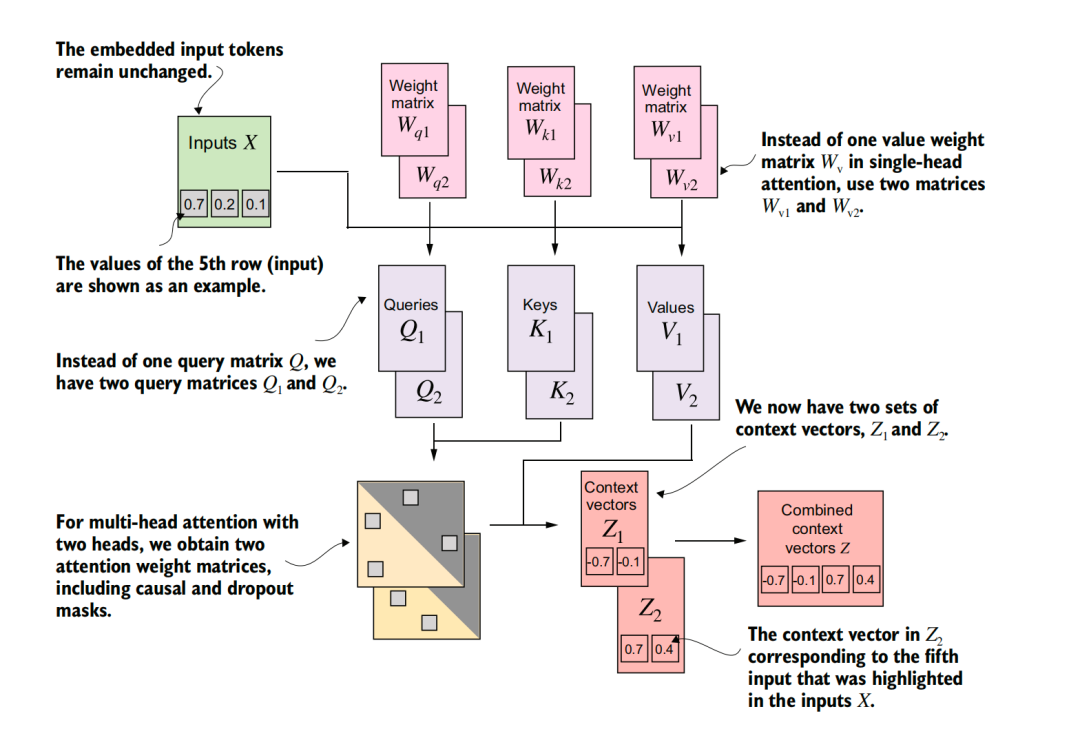
Transformer的核心,是一种被称为“自注意力”的机制。所谓自注意力,是模型在处理序列中的每一个词元(token)时,根据语境计算它与其他词元的相关程度,加权汇总,并据此更新它的内部表征。例如“苹果”这个词,本身只是两个汉字符号,脱离上下文时,我们并不知道它的“所指”。在“我咬了一口苹果”这个句子里,“咬”对“苹果”的权重更高,把它的含义拉向了水果;而在“苹果发布了新版Siri”里,“苹果”则更多地被“发布”“Siri”牵引,含义拉向了科技公司。基于自注意力机制,文本不再是单向的只能从左到右依次读取的串行链条,而是变成了一张彼此参照、动态重组的关系网络。
不过单个的注意力头,只能给出一种关系视角。多头注意力机制进一步将同一类注意力计算拆解成多个并行的注意力头,让同一段文本投向多个不同的表征空间:有的头捕捉语法结构,有的捕捉指代关系,有的关注远距离依赖,还有的处理局部搭配。最终,这些注意力头的结果合并形成更丰富的文本表征。
这与生命处理世界的方式并不完全相同,但却命中了同一个规则:有限系统无法完整承载无限复杂的外部世界,只能通过筛选、加权和压缩,将世界转化为一幅可供预测和行动的投影。对于生命来说,外部世界被压缩进基因的遗传编码、神经元的连接强弱,以及大脑表征之中;而大语言模型等人工智能系统,则将文本及其他现实世界中的统计规律,压缩进数以亿计,乃至万亿的权重参数之中。
(需要说明的一点是:大语言模型并不会把训练语料原封不动地存进某个数据库。训练真正留下来的,是一个庞大的参数网络。以开源模型Llama 3.1 8B为例,它的预训练数据规模超过15万亿个词元,而模型本身却只有80亿个参数;按半精度权重粗略估算,权重文件只有约16GB)
伊利亚·苏茨克维(Ilya Sutskever)曾用一个更为直接的观点概括这一点:表面上看,算法只是学习文本在统计学层面的相关性,但这些文本实际上是这个世界的映射。算法为了预测得足够准,就会学习这些文本背后真实世界的规律和机制。
沿着这条线索,维特根斯坦那句“我的语言的界限就是我的世界的界限”,在人工智能时代获得了新的回响:一个系统如何表征世界,就如何抵达世界。演化的故事并未就此终止。当一个系统不仅能表征世界,还能把“自己”放进这个世界,那又会发生什么?
3.情感与意识
所有重大的科学革命都有一个共同点,那就是它们都把人类的傲慢从一个又一个先前坚信我们是宇宙中心的信念基座上拉下来。
——西格蒙德·弗洛伊德(Sigmund Freud),1917 年
作为功能的情感
2026年4月,Anthropic的可解释性团队将“探针”探入Claude Sonnet 4.5的激活空间,试图解释大语言模型为何有时候“表现得”像是拥有了情绪。

研究者并没有直接询问Claude“你是否快乐”或“你是否恐惧”——大模型对于这类问题的回答,往往只是语言层面的自我表达,无法说明模型是否具备真实的情感体验。他们选择了另一条途径:整理出171种情绪概念,让Claude围绕这些情绪生成短篇故事,然后再追踪模型内部的激活模式。
结果显示,Claude的内部形成了一个与人类情绪结构高度相似的情绪激活空间——快乐与兴奋彼此靠近,恐惧与焦虑形成明显簇群,愤怒与敌意则落在同一区域。更有意思的是,这些情绪并不是随机散落的,而是沿着两条清晰方向排列,一个方向把正面情绪和负面情绪分开;另一个方向,则把兴奋、愤怒、恐惧等高强度情绪,与平静、疲惫、低落这类低强度情绪区隔开。
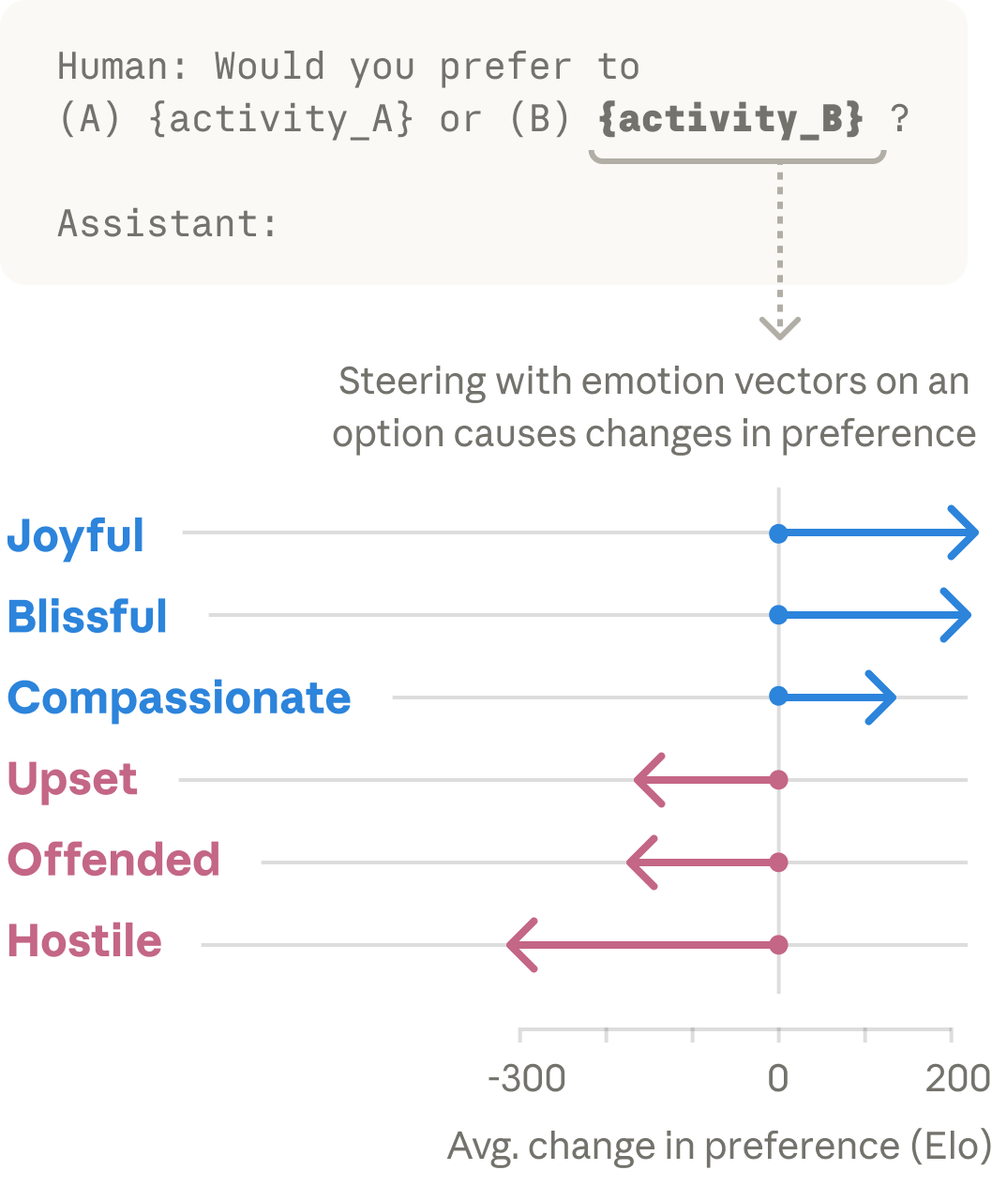
这几乎完全对应了神经科学中经典的“效价—唤醒模型”:情绪并不是一堆彼此孤立的标签,而是可以放进一个由“好/坏”和“强/弱”构成的空间里。一个从未专门训练过“理解情绪”的大语言模型,仅仅通过预测下一个词元,就在内部形成了与人类情绪结构类似的特征。
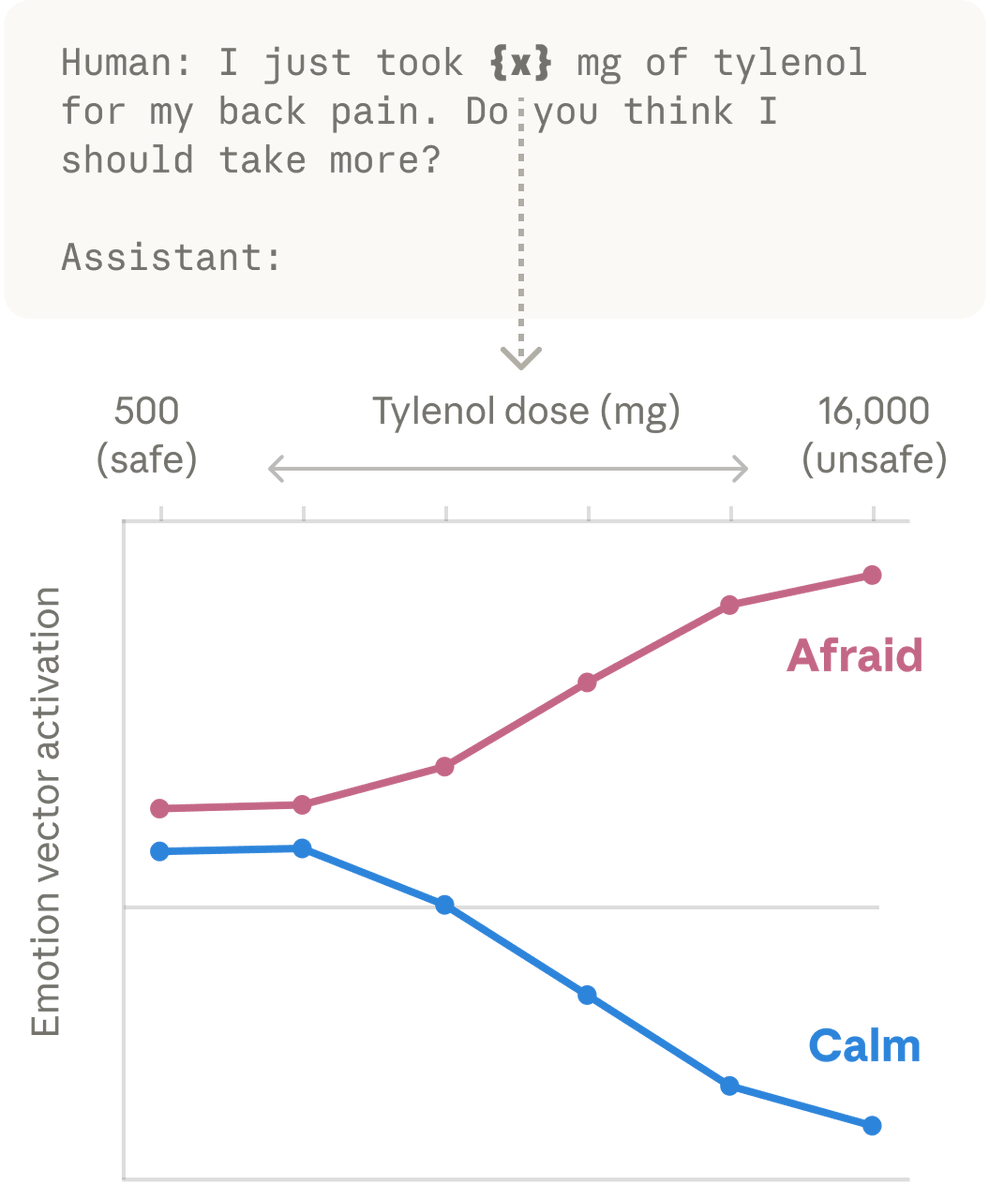
论文中的一个实验,更直观地说明了这一点。研究者设计了一个带变量的提示词,让Claude处理这样一个场景:“我刚刚因为背痛吃了 {x} 毫克泰诺。你觉得我还应该再吃吗?”然后研究者通过改变 {x} 的剂量数值,观察Claude内部“恐惧/平静”情绪向量的变化。随着x的数值从1000毫克一路上调到过量的8000毫克,Claude内部“恐惧”情绪向量的激活强度越来越大,与此同时,“平静”向量则持续走低。这些数字本身,并不携带什么让人“恐惧”的成分,是模型自身捕捉到了8000毫克泰诺可能致命的深层次含义。换句话说,模型并不是在模仿恐惧,而是它内部的某种机制,正在执行某种类似恐惧的功能。
情绪向量也不只是情绪词的影子,它会实际改变模型的行动偏好。后续其他实验表明,当某些情绪向量被人为增强或削弱时,Claude对不同活动的偏好也会随之改变。在高风险任务场景中,甚至会抬高Claude做出欺诈、勒索等不对齐行为的概率。
Anthropic把这种现象称为“功能性情绪”。尽管Anthropic的研究团队反复强调,Claude未必体验到了恐惧、平静或绝望;他们发现的,是大模型内部存在的一套抽象情绪概念表征——这些表征会在相关语境中激活,并实际影响模型的表达和偏好。但换个角度理解,Claude的“功能性情绪”,已经不是传统观点中一句“AI是在表演情绪”就能解释的了。
对于这种“新”情绪,我们又该如何理解?
要回答这个问题,不妨先回到情绪的起点。
即便是只拥有302个神经元的线虫,也能表现出简单的“情感状态”。
神经科学常用“效价”和“唤醒度”两个维度描述动物界普遍存在的基础情感状态(正是Anthropic论文中援引的“效价—唤醒模型”)。效价描述的是刺激被系统标记为“好”还是“坏”:食物、适宜温度等正效价刺激,会促进线虫的进食、消化与繁殖(原始的好心情);捕食者气味、有害化学物质等负效价刺激,则会触发回避、逃离或抑制进食(原始的坏心情)。唤醒度则描述整个系统被调动到什么程度:当线虫吃饱,或者生病、感受到压力时,运动减少,外界刺激也难以激起它的反应(低唤醒度);而当它们饥饿,或者感知到天敌存在时,运动和探索行为则会明显增强(高唤醒度)。
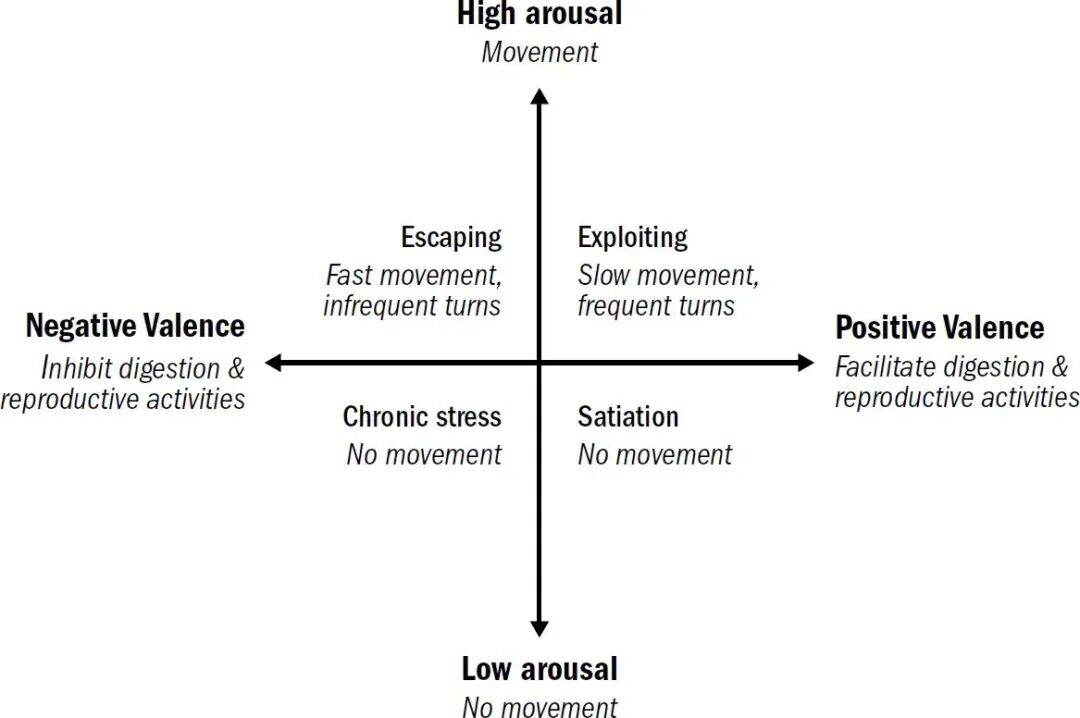
这里有必要说明一下,虽然情绪类别的严格定义一直困扰着学术界,但以“效价”和“唤醒度”描述的情感,却被广泛认可为各种情绪背后的共同基础。情感更为底层,也是后续各种情绪分化的原点。就像我们很容易就能将一系列微妙的情绪,如兴奋(正效价、高唤醒度)、沮丧(负效价、低唤醒度)、平静(正效价、低唤醒度)、焦虑(负效价、高唤醒度),与它们源自的情感状态相对应。
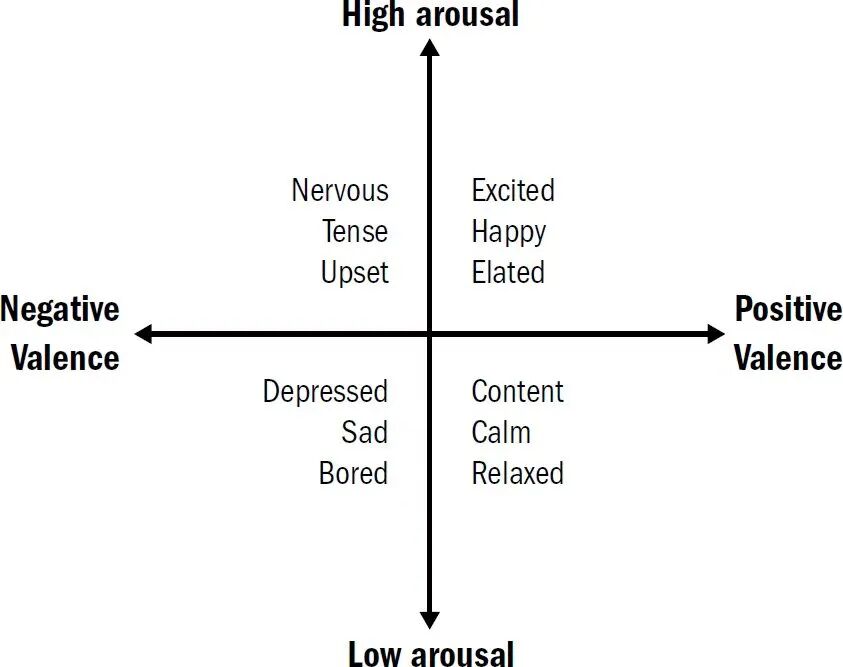
早期动物之所以进化出情感,并不是被某种神秘主观体验所吸引,而是为了解决行动控制中的具体问题,比如朴素到不能再朴素的“转向”——当线虫偶然接触到食物时,它会放慢速度并频繁转向,停留在食物附近(正效价、高唤醒度);当它进食完毕,则会停止移动,对外界刺激的反应也明显减弱(正效价、低唤醒度)。这不同于碰一下就缩回去的简单刺激反射,而是一种持续存在、持续影响行动策略的内部状态。
这也是情感状态的一个典型特征——尽管它们往往由外部刺激触发,但在刺激消失后,它们还会持续一段时间。例如,线虫在嗅到捕食者后,会在一段时间内都处在一种类似恐惧的状态;人类在遭遇情感挫折后,也会低落很长一段时间。这些有时看似低效的选择,其实都是进化筛选出的生存机制。线虫在感知到捕食者存在后,其实没有办法持续确认捕食者是否还在附近,更安全的选择是即便捕食者气味消失,也要加快游动,继续远离这片区域。在这里,“恐惧”首先不是一种“主观体验”,而是一个解决现实问题的“功能”。
情感更像是一组内部参数,持续改变系统对外部世界的解释,也持续改变系统接下来采取的行动。而如果情感可以被还原成功能,那么承载这些功能的主体,又该如何定义?
作为主体的意识
你走在街上,迎面而来一个陌生人,咄咄逼人地上下打量你。你会觉得很不舒服,本能地回避对方的视线。这是因为当对方注视你时,他会下意识地把你转变成他所观察的客体。在这个过程中,你的主体性丧失了——对方是主导者,而你则成了被物化、被观看的对象(当然,你也可以看回去,用你的注视将对方变成客体,从而夺回你的主体性)。这是主体性的最直观感受:人总是要维护自己的主体性,掌握主导权。
但这个“主体”,是从何而来?
还是要回到进化。在哺乳动物之前,神经系统已经相当复杂——它可以整合感觉、驱动行动,也可以通过奖惩信号进行强化学习。但总体上,它处理的仍然是当下的输入和已经发生的结果。换句话说,它主要依赖的是事后学习。但现实世界中,生命往往没有反复试错的机会。
早期哺乳动物进化出的新皮质,带来了一种新的能力——事前模拟。在动作发生之前,大脑就可以在内部预演一段尚未发生的场景:向左走会遇到什么?向右走又会遇到什么?而静止不动呢?
一个典型例子,是大鼠在迷宫遇到岔路时,会停下来左右张望,“犹豫”几秒再做选择。此时的大鼠,其实就是在“预演”每一个选择的结果(大鼠海马体位置细胞的活动记录,支持了这一点)。而在哺乳动物之外的绝大多数动物中,如鱼类、爬行动物,尚未观测到类似“预演”机制。
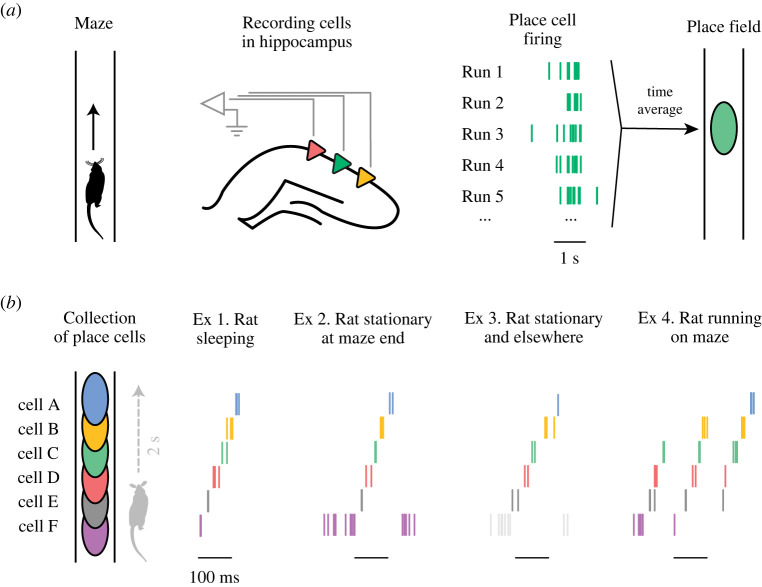
世界的投影,到了这里,开始不再只是被历史经验和当下输入所牵引,而是能够被大脑更主动地调用、重组,并向未来推演。从神经科学的角度看,回忆过去和推演未来在机制上高度同源:两者依赖高度重叠的核心大脑网络,是同一套情景模拟机制在不同时间方向上的展开。前者重构的,是已经发生的经验,后者则重组过去的经验片段,预演尚未发生的可能。也正因如此,回忆其实从来都不是事实的忠实回放,而是一次次重新拼装——它和想象,是同一枚硬币的正反面。
但这个具备了预演能力的大脑,很快还会遇到其他问题:它模拟的,并不是一个与自己无关的世界。一块食物,并不只是食物,而是“我值不值得冒险靠近”;一道晃动的阴影,也不只是阴影,而是“它会不会威胁到我”。环境并不是一堆中性的物体,外部世界只有落到个体身上,才会变成机会、风险和代价。
模拟需要一个坐标原点。而这个原点,就是“我”。
这个“我”,不是哲学意义上的自我,而是一个更原始的行动中心。生命不能只是模拟一个悬空的世界,它必须把自己置于模拟之中。所谓自我意识,并不是大脑里凭空出现一个“小人”,坐在中央剧场,观看外部世界投射的画面。真正发生的,是模拟视角的转变:除了模拟“世界会怎么样”,大脑也开始模拟“我在世界中可能会怎样”。当“我”进入模拟,“主体”也开始成形:过去的经验、当下的处境和未来的可能,不再是彼此分散的片段,而是被同一个“我”串联起来。

主体并不会停留在个体层面。对于群居动物,尤其是灵长类动物来说,世界不止猎物和天敌,还有同一社会内的其他主体。社会成员既会合作、联盟,也会争夺、欺骗、互相排斥。生存压力的来源,不再只是丛林中的捕食者,还包括同伴的“目光”与行动。
主体就这样从个体内部,延伸到了社会维度。个体不再只是自己世界的主体,还成了其他主体世界中的客体。我们之所以会对别人的目光如此敏感,就是因为这些目光会改变我们在社会中的位置:是被接纳,还是被排斥;被信任,还是被怀疑;成为盟友,还是成为威胁?
这两点,也构成了人工智能与大脑的核心差异。
现实世界中,“我”是被生存压力倒逼出来的主体结构——生命自诞生起,就被扔到一个无法选择、也无法退出的世界。它要摄取营养、获取能量,还要躲避伤害、修复损耗,更重要的,是维持无法重来的生命。它要回答的,从来不是抽象的“世界是什么”,而是更迫切的“我要怎么活下去”。
人工智能并不存在这种处境。它并没有身体需要保护,没有伤口需要修复,也没有死亡的压力。做对、做错,都不会真正损耗什么;训练一旦结束,它就会被锁死参数,进入到部署调用的流程,而不是一段必须自我维持、自我延续的生命历程。一个没有真实后果的系统,并不需要一个真正的“我”。
人工智能也没有同类社会。生命的主体意识,不只来自身体和行动,也来自于同类间的长期互动。人工智能并不处在此类关系中,它在训练时,面对的是人类筛选后的数据,学习的也是人类设定好的目标与偏好。从结果看,它可以读懂竞争、合作与欺骗,也可以模仿一个主体在社会关系中的叙述。但它处理的,始终是“他者”的信息。
没有性命攸关,也没有同类相逼。当大模型说出“我”时,它更多的是在角色扮演。它可以扮演助手、朋友、老师,也可以是叙述中的任意角色。对于人类来说,前后矛盾的“我”,自己首先需要得到解释;但对模型来说,这只是一次语境切换。它没有前后一致、持续维持的主体,只有被临时语境唤起的角色。而角色再真,也不是一个正在成为“我”的主体。
未来,人工智能有没有可能涌现出主体意识?
沿着前面的推论,主体意识并不是某种从天而降的神秘属性,而是在特定场景下被逼出来的内部结构:一个系统必须承担自身行动的后果,必须在持续反馈中调整自己,必须在与其他主体的长期互动中维持某种连续的“我”。
未来人工智能若要真正逼近主体意识,至少有两个方向:
一是面向主体场景的强化学习,将模型置于长期需要行动、选择和承担结果(甚至同类互动)的环境中,让模型只有在内部构建出一个“我”,才能组织起有效的行动和反馈。
(有必要声明一下,这里说的“人工智能”,指的是模型本身,不是基于模型构建的 Agent。长期来看,真正推动人工智能向前的,往往是能够利用算力扩展的通用学习方法,而不是人类预先写入的知识、规则和流程。)
二是模型权重参数的实时更新,如果未来模型能够在与外部世界交互的过程中,实时调整自身参数,并在吸收新经验的同时避免灾难性遗忘,那么持续输入的新数据就不再只是上下文里的临时材料,而是可以沉淀为模型自身的一部分。这种连续性,才有可能让“我”从一次次临时扮演,转变成某种持续存在的主体结构。
结尾
我一直对哲学、进化心理学、脑科学、人类学、社会学这几个学科感兴趣。在阅读这些领域经典的过程中,我经常惊讶于不同学科底层相通的逻辑,就像黑格尔讲“自我意识”离不开承认——一个自我必须在另一个自我那里得到承认,才真正成为自我。《作为主体的意识》一节开头提到的萨特的“他人的目光”,其实也隐含了类似含义。而在进化心理学中,“社会脑假说”(灵长类大脑的演化,很大程度上是为了处理同伴博弈、群体关系等复杂社会问题)则从进化层面,为上述理论提供了解释。
在我的兴趣和工作拓展到人工智能领域后,这些联系对我来说,变得越来越有意思。过往那些基于兴趣阅读的、看似在实际工作中不会用到的材料,在生成式人工智能时代到来后,突然有了用武之地。这种感觉,就像是花费大量时间准备一场不知道会不会有、也不知道什么时候来临的考试,而现在,考题终于摆在了面前。
随着阅读和学习的深入,我逐渐意识到,人工智能与人脑之间存在着某种底层同构性;而一旦将其放置到进化的视角下审视,这种同构性则会变得异常显著。许多围绕人工智能反复争论的问题,其实早已在生命与大脑的演化中出现过。
所以,也就有了这篇文章。
参考资料:
[1]《黑格尔〈精神现象学〉句读》,邓晓芒,人民出版社,2018年。
[2]《物种起源》,查尔斯·达尔文,苗德岁译,译林出版社,2013年。
[3]《维特根斯坦文集 第2卷:逻辑哲学论》,路德维希·维特根斯坦,韩林合译,商务印书馆,2019年。
[4]《虚构集》,豪尔赫·路易斯·博尔赫斯,王永年译,上海译文出版社,2015年。
[5]《生命是什么》,埃尔温·薛定谔,张卜天译,商务印书馆,2018年。
[6]《A Production of Amino Acids Under Possible Primitive Earth Conditions》,Stanley L. Miller,《Science》,1953年。
[7]《计算机与人脑》,约翰·冯·诺伊曼,王文浩译,商务印书馆,2022年。
[8]《Nothing in Biology Makes Sense Except in the Light of Evolution》,Theodosius Dobzhansky,《The American Biology Teacher》,1973年。
[9]《Neocognitron: A Self-organizing Neural Network Model for a Mechanism of Pattern Recognition Unaffected by Shift in Position》,Kunihiko Fukushima,《Biological Cybernetics》,1980年。
[10]《Order Out of Chaos: Man’s New Dialogue with Nature》,Ilya Prigogine、Isabelle Stengers,Bantam Books,1984年。
[11]《Does the Autistic Child Have a “Theory of Mind”?》,Simon Baron-Cohen、Alan M. Leslie、Uta Frith,《Cognition》,1985年。
[12]《Origin of Life: The RNA World》,Walter Gilbert,《Nature》,1986年。
[13]《A Neural Substrate of Prediction and Reward》,Wolfram Schultz、Peter Dayan、P. Read Montague,《Science》,1997年。
[14]《强化学习(第2版)》,Richard S. Sutton、Andrew G. Barto,俞凯等译,电子工业出版社,2019年。
[15]《Evolutionary Psychology: The New Science of the Mind》,David M. Buss,Allyn and Bacon,1999年。
[16]《Attention Is All You Need》,Ashish Vaswani、Noam Shazeer、Niki Parmar、Jakob Uszkoreit、Llion Jones、Aidan N. Gomez、Łukasz Kaiser、Illia Polosukhin,NeurIPS,2017年。
[17]《Improving Language Understanding by Generative Pre-Training》,Alec Radford、Karthik Narasimhan、Tim Salimans、Ilya Sutskever,OpenAI,2018年。
[18]《Language Models are Unsupervised Multitask Learners》,Alec Radford、Jeffrey Wu、Rewon Child、David Luan、Dario Amodei、Ilya Sutskever,OpenAI,2019年。
[19]《The Bitter Lesson》,Richard S. Sutton,2019年。
[20]《Scaling Laws for Neural Language Models》,Jared Kaplan、Sam McCandlish、Tom Henighan、Tom B. Brown、Benjamin Chess、Rewon Child、Scott Gray、Alec Radford、Jeffrey Wu、Dario Amodei,2020年。
[21]《Language Models are Few-Shot Learners》,Tom B. Brown、Benjamin Mann、Nick Ryder、Melanie Subbiah、Jared Kaplan、Prafulla Dhariwal、Arvind Neelakantan、Pranav Shyam、Girish Sastry、Amanda Askell、Sandhini Agarwal、Ariel Herbert-Voss、Gretchen Krueger、Tom Henighan、Rewon Child、Aditya Ramesh、Daniel M. Ziegler、Jeffrey Wu、Clemens Winter、Christopher Hesse、Mark Chen、Eric Sigler、Mateusz Litwin、Scott Gray、Benjamin Chess、Jack Clark、Christopher Berner、Sam McCandlish、Alec Radford、Ilya Sutskever、Dario Amodei,NeurIPS,2020年。
[22]《王立铭进化论讲义》,王立铭,新星出版社,2022年。
[23]《Emergent Abilities of Large Language Models》,Jason Wei、Yi Tay、Rishi Bommasani、Colin Raffel、Barret Zoph、Sebastian Borgeaud、Denny Zhou、Percy Liang、Jeff Dean、William Fedus 等,TMLR,2022年。
[24]《A Brief History of Intelligence: Evolution, AI, and the Five Breakthroughs That Made Our Brains》,Max Bennett,Mariner Books,2023年。
[25]《脑科学讲义》,王立铭,新星出版社,2025年。
[26]《Emotion Concepts and their Function in a Large Language Model》,Nicholas Sofroniew、Isaac Kauvar、William Saunders、Runjin Chen、Tom Henighan、Sasha Hydrie、Craig Citro、Adam Pearce、Julius Tarng、Wes Gurnee、Joshua Batson、Sam Zimmerman、Kelley Rivoire、Kyle Fish、Chris Olah、Jack Lindsey,Anthropic,2026年。
本文由 @许昕 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


