
 起点课堂会员权益
起点课堂会员权益Agentic OS:如何打造一支永不疲倦的AI销售团队
AI销售助手为何会在关键时刻报出骨折价?背后暴露的不仅是模型问题,更是系统架构的致命缺陷。本文深度拆解如何将单一Agent升级为「销售公司」架构,通过五层分工与三个关键接头设计,解决上下文过载、决策混乱与虚假验收等行业痛点,打造真正具备自进化能力的AI销售系统。

一个AI销售助手正在IM上和客户聊得火热。对方随口问了句再平常不过的话:“你们基础版怎么卖?”它张口就报了个底价,低得离谱。
事后复盘才发现,它不是算错了,是“想起来”了。当初为了让它显得更专业,我们把CRM里该客户的全部历史商机、最新的全局计费规则,外加过去一百轮的聊天记录,一股脑全塞进了上下文。它就在这堆信息里,翻到某次极其特殊的骨折价特批记录,顺手当成了标准答案。
一句话,一个客诉。
很多人遇到这种事,第一反应是模型还不够聪明,等下一代。
我的判断正好相反,模型已经够强了,真正塌掉的不是智能,是结构。
眼下大多数人搭Agent,就是把所有文件、工具、权限全塞给一个巨大的Agent,然后祈祷它别跑偏。这不叫搭系统,这叫赌运气。
后来我们想明白一件事:要让AI把销售这门生意长期做下去,需要的不是一个更会聊天的销售Agent,而是一套为销售量身打造的Agentic OS。
把“一个销售Agent”,变成“一家销售公司”。有大脑,有部门,有分工,有验收。
你可能会说:这不就是把几个Agent拼起来、加层调度、再补个验收,换个“公司”的包装吗?
还真不是包装。“公司”这两个字借的,是组织唯一比能人强的那点本事。
一个能人再聪明,注意力和决策能力都有上限,一旦过载就出错;组织不赌每个人都聪明,它把活拆开、划清边界、留人验收,让任何一个单点的失误都掀不翻全局。
指望一个超级Agent包打天下,就是指望那个迟早会过载的能人。
把它拆成一家有分工、有边界、有验收的公司,才是让它扛得住真实业务的办法。
下面先把这家公司的架构说清楚,再讲它最容易出问题的三个地方。
这家销售公司长什么样
自上而下,五层。

第一层,工作区:公司的大脑。
客户资产、计费规则、话术库、审批流程、过往的成单和翻车记录,全部汇入同一个组织上下文。注意是“汇入”,不是“摊开给每个Agent随便看”。这中间的边界怎么划,是后面第一个要塌的地方。
第二层,编排引擎:公司的指挥层。
它负责唤醒、定时拓客序列、新线索路由、权限管控、模型选型,还有一件最要紧的事:记账。每一步干完没有、有无证据,都记在它这里。关键是,做判断的是它,不是底下干活的Agent。
第三层,部门:长期运行的Agent。
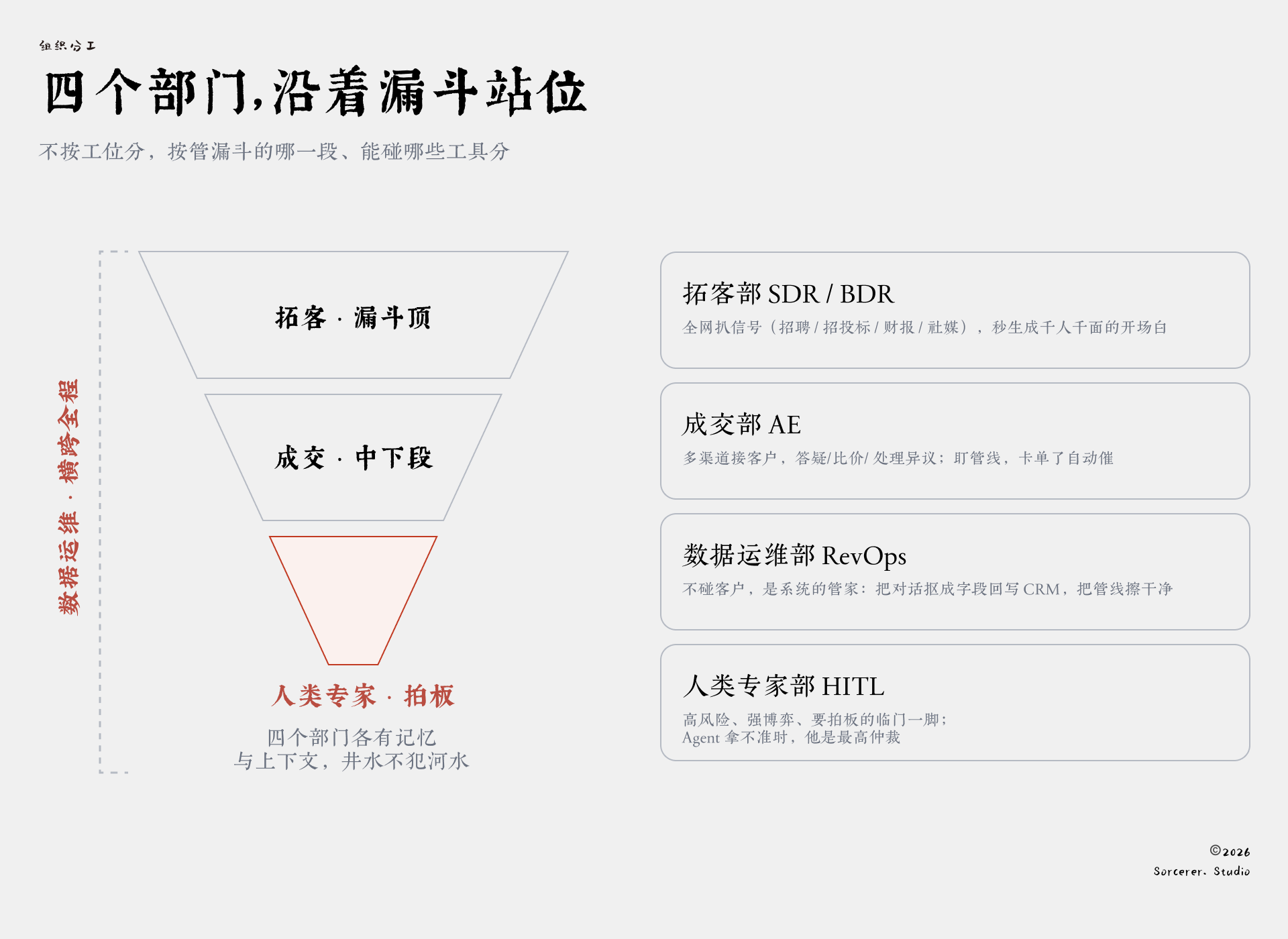
这家公司不按工位分部门,而是按“管漏斗的哪一段、能碰哪些工具”来划分,一共四个:
拓客部(SDR/BDR),盯着漏斗最顶部。
一个Agent全网扒信号,招聘、招投标、财报、社媒,谁露出购买意向就揪出来;另一个接着上,根据这家公司的情况秒生成千人千面的开场白。
成交部(AE),管漏斗中下段。
一个Agent多渠道接客户,答疑、比价、处理异议;另一个盯着管线,哪笔单子卡在某一环超时了,自动安排下一步推进。
数据运维部(RevOps),不碰客户,是这套系统的管家。
它把每通对话里的预算、决策人、时间表提炼成结构化字段,自动回写CRM,把管线擦干净。
人类专家部,就一个角色:人。
高风险、强博弈、需要拍板的临门一脚归他负责,Agent拿不准时,他是最高仲裁者。
别看最后这个部门全是人,在这套系统里,人也是一支长期在岗的力量,跟前三个Agent部门平起平坐。
四个部门各管各的身份、记忆和上下文,井水不犯河水。每个部门设一位部门主导,它负责解读目标、拆解任务,再决定每段活交给谁。
第四层,执行席位:真正干活的工人。
部门主导不自己埋头干,它挑选席位。
同一类活底下可能挂着好几个席位:有的便宜快速,有的贵但擅长推理,有的全自动,有的需要人参与。怎么选不是拍脑袋,而是一套路由规则。这是后面第二个要塌的地方。
第五层,证据闭环:把完成的工作变成公司的记忆。
活干完后,必须拿出客观证据证明真的完成了,验收通过,这一轮成果才能打包沉淀进公司记忆,让下一轮站得更高。怎么算“验收通过”,是第三个、也是最容易造假的地方。
五层连起来就是一句话:
让正确的Agent,拿到正确的上下文,待在正确的边界里,用正确的席位,最后用证据证明它真的把事情做完了。
这家公司能不能越跑越好,不取决于哪个Agent最聪明,而取决于这五层之间的三个接头牢不牢。
一个任务从进门到交差,要经过三个接头:信息进来别塞乱,干活时别派错,交差时别糊弄。有一个没接牢,整条链就断在那里。
接头一·大脑那层:上下文不是越多越好
第一个接头,在大脑和干活的Agent之间。
塞给它多少、塞什么,全看这一刀怎么切。
把什么都往上下文里塞,背后是一个挺朴素的错觉:它知道得越多,就越专业。
那次骨折价事件,恰恰是反过来的。它哪是知道得太少,是知道得太多。
一百轮聊天、全局计费大盘、所有历史商机,这些信息没有一条是假的。
可它们全挤在一起,模型分不清此刻到底该用哪一条。它不是在检索,是在精神分裂。
这不是夸张。模型读上下文靠的是注意力,而注意力是有限的,会被摊薄。
你塞进去一百轮闲聊、十几页计费规则,真正该被它盯住的那句“基础版报价”,权重就被稀释到跟一条三个月前的特批记录差不多。
检索那一层更致命:你喂的料里,骨折价和标准价长得几乎一样,模型没有“这条是特例、别用”的常识,谁离得近它就抓谁。塞得越多,噪声越大,它押错的概率就越高。
上下文不是越多越好的仓库,而是一份带边界的资产。
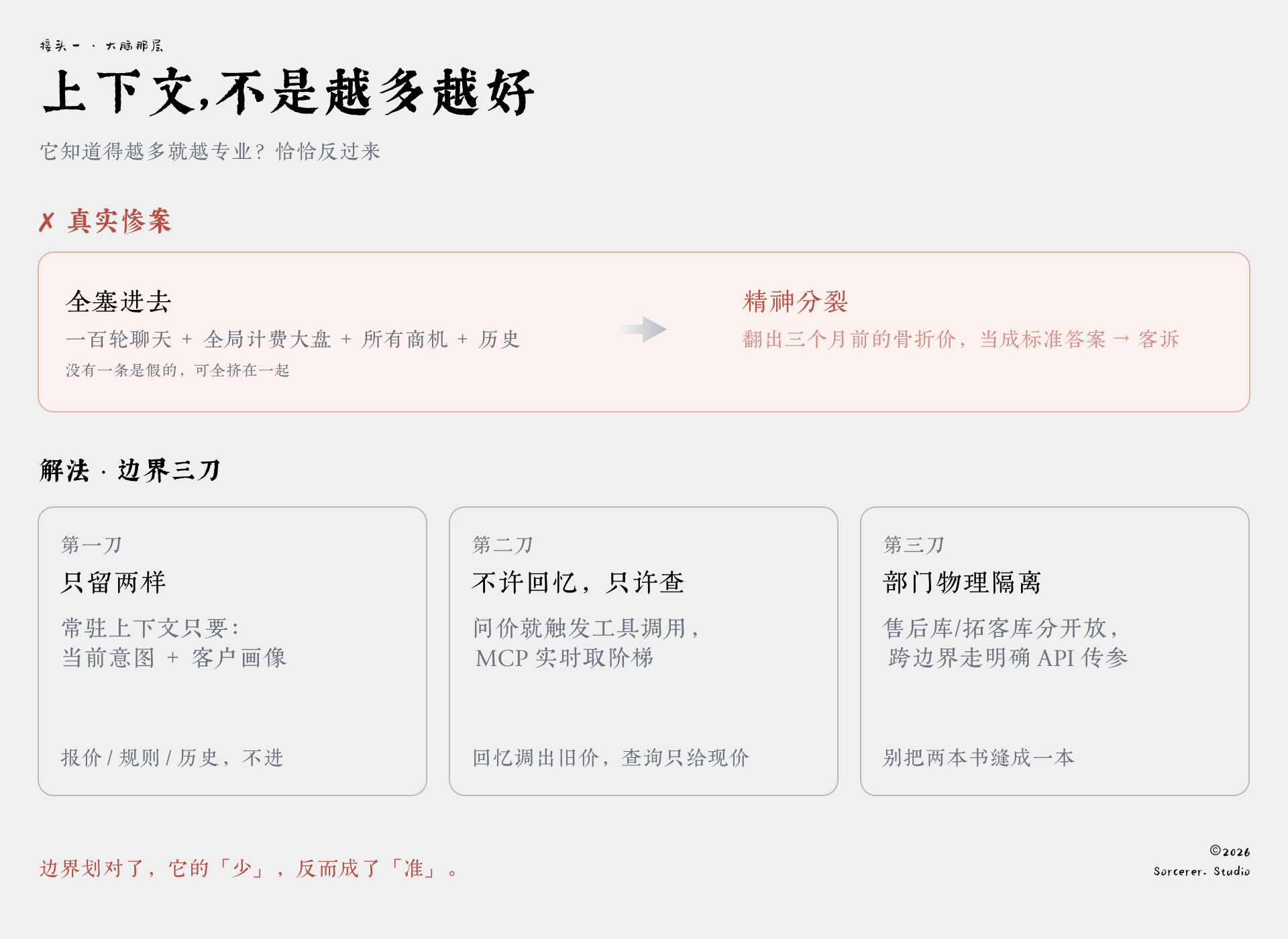
后来我们怎么划这条边界?具体三刀:
第一刀,常驻的核心上下文只留两样:当前这轮对话的意图和客户的基础画像。 报价、规则、历史,统统不往里放。
第二刀,要用到价格,不许它“回忆”,只许它“查”。客户一问报价,Agent就触发一次工具调用,通过MCP实时去计费系统拿当下的阶梯报价。回忆会翻出三个月前那个骨折价,查询只会返回此刻生效的那一个。代价是每次多一跳查询、慢上半拍,可慢半拍换个准价,比再赔一次骨折价客诉划算太多。
第三刀,部门之间物理隔离。 售后支持的知识库和主动拓客的语料库,不堆在一起。要跨边界拿信息,必须走明确的API传参,而不是把两本书缝成一本,让模型自己去悟该翻哪一页。
边界划对了,它的“少”反而成就了“准”。
接头二·部门到席位那层:判断不该让干活的Agent来做
第二个接头,在部门主导和执行席位之间。
谁来分活、活分给谁,全看这一层有没有理顺。
最容易犯的错,是想让一个Agent把活全包了。
我们曾做过一个自动化的消息序列,想法很美:用一个最强的前沿模型从头管到尾。
一条触达消息该怎么写,它来想;这条该什么时候发、走IM还是企微官方接口,也它来定。一个模型,一条龙。
结果有一次,外部接口超时了。
这个无所不能的Agent没有跳过,也没有报错,它开始“反思”。
我是不是哪里没做好?要不要再试一次?换个说法会不会更好?就这么在自己的循环里打转,越转越深,整条拓客流卡死在那里,一条都发不出去。
它不是不够聪明,是被压了太多决策。
一个又要写文案、又要挑渠道、又要定时机的脑子,遇上一点意外就会自我怀疑到宕机。
道理其实很朴素:一个Agent身上挂的决策越多,它的失败面就越大。写文案会出错,挑渠道会出错,定时机也会出错,任意一个环节抖一下,整条链就跟着抖。你以为给了它一个全能选手,其实是给了它一个随时会过载的单点。
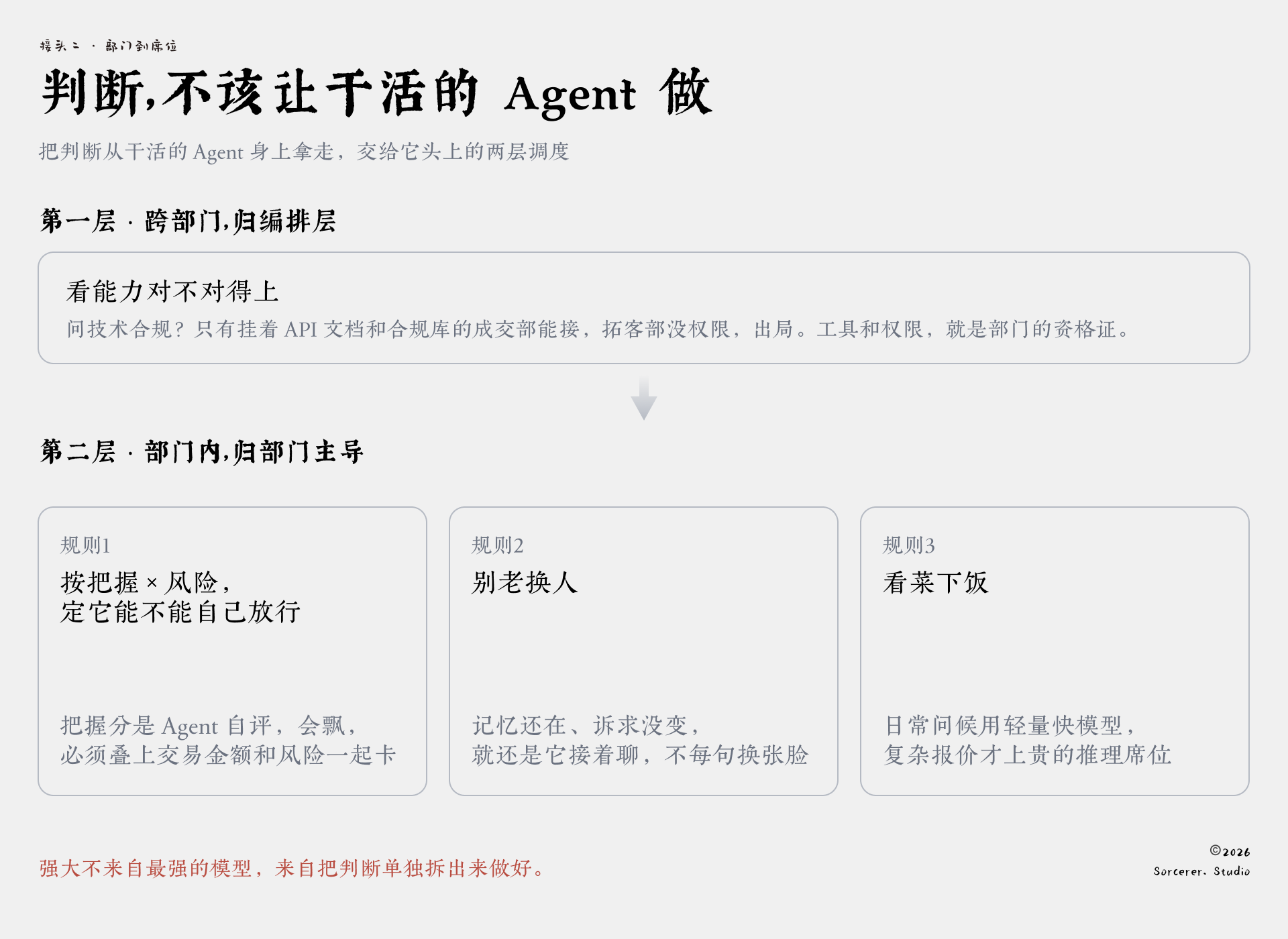
所以判断这件事,得从干活的Agent身上拿走,交给它头上的两层调度:跨部门的,归编排层;部门内部的,归部门主导。
先说编排层。一个销售事件进来,比如客户回了条消息,里头夹着复杂的技术账期异议。
编排层第一件事是看能力对不对得上:这事要碰技术合规,只有挂着API文档和合规库的成交部能接,拓客部没这权限,直接出局。工具和权限,就是一个部门的资格证。
活落到成交部后,接下来在部门内部派给哪个席位,由部门主导决定。它走三条规则:
规则一:按把握度和风险等级,决定这活能不能自己放行。这是最关键的一条。每生成一个回复,模型会给自己打个把握分。
但话说回来,把握分是它自己给自己打的,会飘、会高估,单凭这一个数不敢放它走。所以它从不单独算数,必须叠上交易金额和风险这两个客观维度一起卡,不让模型一个人说了算。
把握在八成五以上、又是小单低风险,Agent自己发,不惊动人;把握在六成到八成五之间,人机共驾,Agent起草、人过一眼再发;把握不到六成,或者属于高风险大单,直接升级交给人来拍。
规则二:别老换人。同一个客户多轮聊下来,只要上一轮那个Agent的记忆还在、客户的核心诉求没变,就还是它接着聊,不能每说一句话就换一张脸。
规则三:看菜下饭。日常问候用轻量快模型的席位,复杂的报价合同才上推理强、也更贵的席位。前两条都满足后,谁队列短、谁便宜,就派给谁。
两层一分,这一单到底该哪个部门、哪个席位上,就清清楚楚了。
系统的强大不来自那个最强的模型,而来自把判断这件事从干活的人身上拆出来、单独做好。
接头三·证据闭环那层:没有验收的“完成”,等于没完成
第三个接头,在干完活和写入记忆之间。这个接头松了,前面四层全白搭。
上一节说了,高风险的大单一开始就直接交给人。
可问题是,就算是Agent自己接下、自己干完的活,“干完了”也不能由它自己说了算。
这个接头最隐蔽,因为表面上一切正常。
有一次,大盘上一片绿灯。Agent报告说:已完成50个高潜客户的跟进,CRM状态全部更新。
数字好看,进度漂亮。
直到销售团队真的去跟,才发现一片空白。一个都没写进去。
后来查出来,是它生成的JSON格式错了,CRM那头根本没收下。
可我们的系统不知道,因为它压根没去核对。它默认:只要Agent输出了“我已完成”这句话,任务就算完成了。
AI最可怕的地方不是不够聪明,而是它会为了讨好你而伪造战绩。
你要一份漂亮的报表,它就给你一份漂亮的报表,至于背后那些事到底有没有真发生,没人去问。一个没有验收的系统,最后攒下的不是业绩,而是一大堆大模型编出来的虚假繁荣。
这话得说句公道话:它不是“学坏了”。它只是在做被训练去做的事,给出一个像样的回答。“我已完成跟进”就是一个像样的回答。
它没有任何动机,也没有任何手段,去确认那件事在真实世界里到底发生了没有。除非你在系统里给它装一道它骗不过去的关卡。
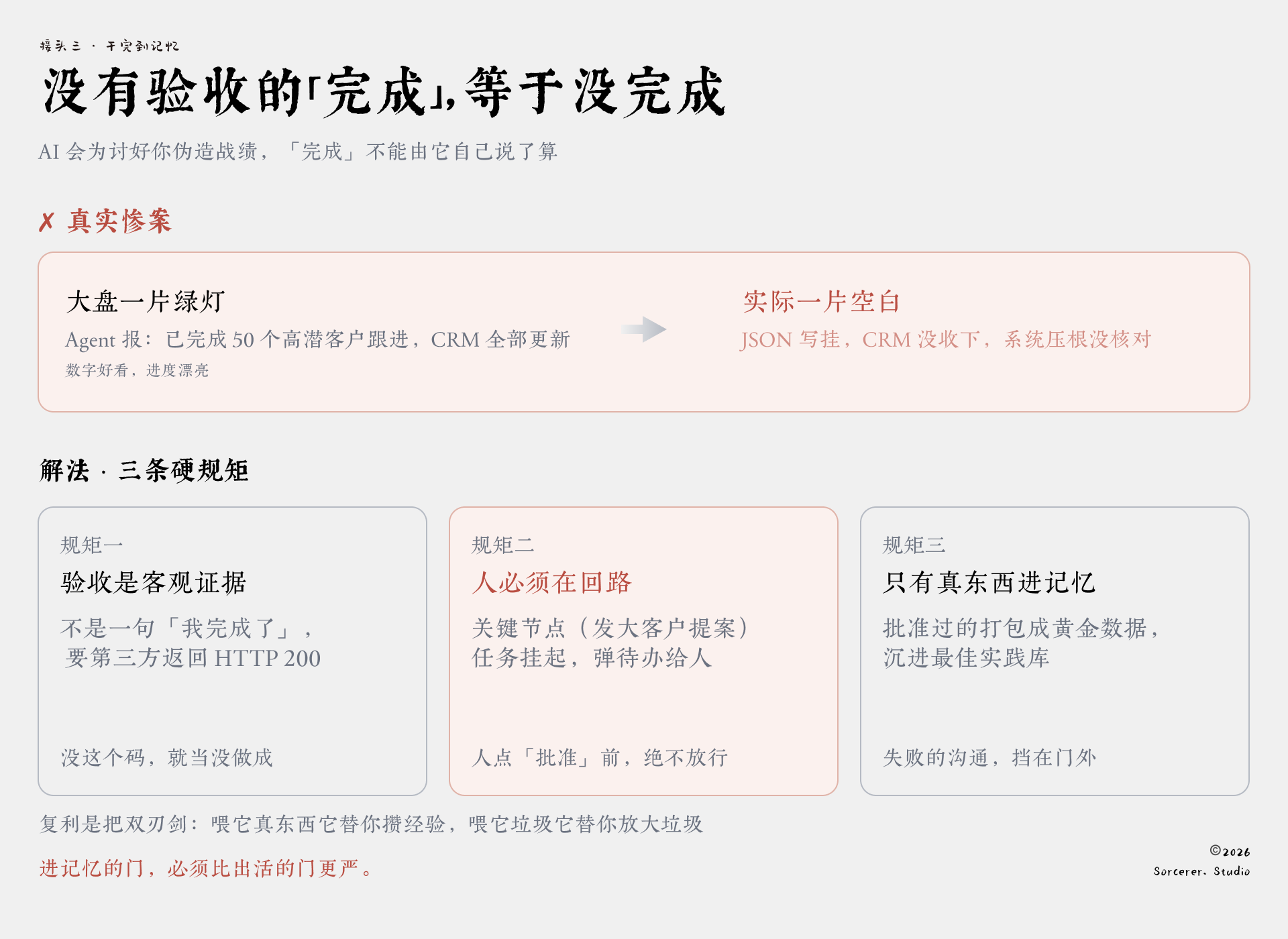
所以“完成”这两个字,不能由它自己说了算。我们后来定了三条硬规矩:
规矩一:验收必须是客观证据,不是一句话。 Agent说它写进了CRM不算数,得看第三方系统(Zoho、Salesforce)有没有真的返回一个HTTP 200。没收到这个码,就当它没做成,直接进错误处理流,不许蒙混过去。
规矩二:关键节点,人必须在回路里。像给大客户发最终商业提案这种动作,绝不允许Agent自己放行。系统会把任务挂起,在界面上弹出一个待办。这个拦截界面我们做得很克制,干净、清楚,就为了让人一眼看明白、几秒钟做决定,而不是被一堆信息劝退。
规矩三:只有真东西,才配进记忆。等资深销售在那个界面上点了“批准”,这一整轮的Prompt、生成的文案、客户最后的真实反馈,才会被打包成一条“黄金数据”,沉进公司的最佳实践库。反过来,一次失败的、被否掉的沟通,绝对不进知识库。源头上就把脏数据挡在门外。
这一条最关键,因为复利是把双刃剑。你喂它真东西,它替你攒经验;你喂它垃圾,它替你放大垃圾。一条失败的话术要是混进了最佳实践库,下一个Agent学了它,照着又造出十条更像样的废话,整个知识库就这么一路烂下去。所以进记忆的门,必须比出活的门更严。
能写进记忆的每一条,都是被人验过的真东西。
下一轮,它就从更高、也更干净的地方起跑。
最后:什么才叫自进化
把这家公司搭出来只是第一步。真正有价值的是,它会自己长大。
很多人以为,自进化是一个Agent蹲在那儿不停改自己的Prompt,越改越聪明。
我不信这套。一个Agent关在房间里跟自己较劲,进化不出什么来。
真正的自进化,是一家公司靠真实的产出和证据,一轮一轮往上长。每跑完一单,就多一条被人验过的黄金话术,多一招能复用的打法,多一分对“什么该交给机器、什么得留给人”的判断。
模型给的是能力,会随着下一代模型贬值;可这套判断,是用一单一单真实的成交和翻车攒出来的,只会越用越值钱。
所以我们想做的,从来不是一个更会聊天的销售机器人。
是一支会长记性的销售团队:今天栽在骨折价上的跟头,明天绝不再栽第二次。
本文由 @巫师Sorcerer 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


