
 起点课堂会员权益
起点课堂会员权益金融风控数据新人,最容易踩到的雷区!
在做数据分析之前,数据获取环节常常会被人忽略,但这也是关键的一步。本文基于相关案例,总结了数据获取的三点准备工作,希望对你有所启发。

在数据分析中,大家往往会比较重视数据清洗,数据统计和特征构建这些所谓的高级工作,而比较容易忽略数据获取这个环节。
大家可能会说,从数据仓库取数据不是一件很easy的事情吗,两行SQL语句就可以搞定。
事实上,很多数据分析的错误都是在数据获取阶段埋下的地雷,导致后续不停的返工。这里我们只讨论从数据仓库取数据的情形。
举个例子,小飞是粮粮电商数字金融部门的新员工,老板让小飞统计下电商客户向信贷客户的转化漏斗结构。
小飞接到任务非常兴奋,打开了电脑,两行sql语句把数据抓进excel,然后开始各种花式分析,忙得不亦乐乎。
当他把数据准备成各种酷炫图表给老板汇报时,老板问了一句:”你这个信贷客户的人数比我们线上监控的人数少了一半以上,你是从哪里拿的用户数据呀?”
小飞回答,我从credit_card_transaction_tab里取的用户,都是有信用记录的用户。
火眼睛睛的老板一眼就把问题指出来:“你这里只算了持有信用卡的用户,我们还有消费分期和现金分期的用户都没有算在里面。”
结果由于最基本的客户数没有算对,小飞后面所有的分析结果展示都没有意义了,只好默默回去重新准备数据。
这就是一个典型忽视基本的数据获取工作,在阴沟里翻船的例子。
大家刚入职时,都急于表现自己,看到一个数据能满足自己要求就立马使用,往往会写出下面这样的SQL语句:

这里transaction表的主键是txn_id,一个用户可能有多条交易记录,所以被迫使用DISTINCT去重,暴力取出用户的列表。
基于上面的案列,我们可以知道,在做数据分析前,前期数据获取时做的准备工作是必不可少的,通常我们需要做如下的事情:
- 了解数据仓库的表
- 整理表和表之间的逻辑关系
- 理解用户数据在数据仓库的落库逻辑
接下来,我针对上面三点详细展开。
01 了解数据仓库的表
在接到一个数据分析的任务时,第一件时间就是找到相关数据的负责人,拿到存储数据的表和文档。
一般金融公司会有几个部门:Dev, DE, BI, DS。作为DS的建模人员,去问谁才能获得最准确的信息呢?
这里大部分人会选择问DS内部的同事或者BI,因为都是做数据分析,大家也比较熟悉。
但事实上,DS和BI都不是数据质量负责的人。很多时候,数据表的变动他们是不清楚的,询问他们大概率拿到的信息都不能保证权威性。
在初步了解一个数据的时候,作为DS,其实最佳的询问对象是DE。
因为DE是负责把Dev做的生产数据库的表拉到数据仓库,并构建数仓表的负责人,他们对表的结构和数据的变动是最有发言权的。

一般情况下,DE在处理数据时,都会把数据的原始表从生产数据库里搬一份到数据仓库里,然后构建对应的数仓表。
所以一个数据在数据仓库一般有两个记录:原始表记录和数仓表记录。
如果DE说暂时还没有构建对应的数仓表,你要基于原始表做工作的话,后续是需要迭代到数仓表上去的。
02 整理表和表之间的逻辑关系
在找到DE的负责人后,需要他们提供数据表对应的文档,然后整理出这些表之间的逻辑关系,一般数仓表都会有维度表和明细表两大类,常见的套路就是维度表去关联明细表。
举个例子,信贷数据的表基本上可以归纳成用户相关的表,产品相关的表,贷款记录的表和还款记录的表。
我们可以把表的关系画成简易版的ER图结,方便自己和团队的其他成员理解。
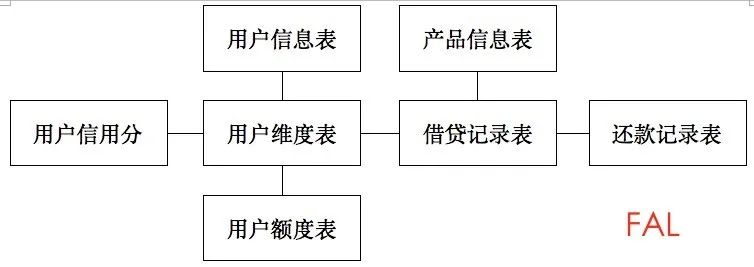
在这里,用户维度表,产品信息表和借贷记录表可以认为是维度表,用户信用分可以认为是用户维度扩展出来的明细信息,还款记录可以认为是借贷维度扩展出来的明细信息。
所以在写SQL取用户的时候,都是从用户的维度表出发去关联其他对应的用户层面明细表,这样的SQL逻辑是最严谨可靠的。
回顾下之前的SQL例子:

这里从借贷记录表里拿用户维度的信息就是非常不合理的一类逻辑。
如果我们是想找有信贷记录的用户列表的话,应该是用户维度表去关联借贷记录表,并在筛选条件中设置只挑选有信贷记录的用户,这样的SQL才是严谨可靠的。
03 理解用户数据在数据仓库的落库逻辑
在熟悉了数据表里的字段和表的相互关系后,接下来就需要感受数据在业务逻辑中的流动和落盘。
一个数据老鸟在和业务沟通时候,会在脑子里带着表结构去询问业务的SOP。
当业务说用户注册账户,脑子里就要想着在用户维度表增加一行,用户注册的相关信息会被记录在这个维度表里。
然后用户填写相关的表格提交信息,就会知道我们收集的用户信息会按SOP流程在规定的时间落盘在用户信息表中。
其中哪些信息是必须非空的,哪些是可以有缺失的,缺失的时候数据表里是None值还是默认值。
如果用户更新这些信息,数据表是新增一个记录还是覆盖已有的记录?会对我们后续建模有无影响?是否有未来信息泄露的可能?
用户在从下拉列表中选择信息的时候,下拉列表是固定不变的还是会改变的?会引起数据不一致嘛?后续需要对数据做清洗和归一化嘛?
只有当你回顾一个业务流程,用户的每个数据从app流转到数据表的逻辑都非常清晰后,才算做完了数据获取的准备工作。
说到这里,你可能就不会觉得数据获取是一件很简单的事情,而是需要很多耐心和经验,很考验一个人沟通能力和信息归纳整理能力的一件事情。
总结一下,在拿到一个数据分析任务的时候,首先要做好数据获取的准备工作,分成三方面:
- 了解数据仓库的表
- 整理表和表之间的逻辑关系
- 理解用户数据在数据仓库的落库逻辑
这些工作会能极大地加深你对数据的理解,能在项目的早期把数据的坑点都找出来,能让你迅速的融入到业务中,做一个既有分析建模技能又有业务实战能力的数据科学家。
作者:Ollie老师
来源公众号:FAL-金科应用研院(ID:fintechapplab_sz),Make Fintech Easier And Smarter
本文由人人都是产品经理合作媒体 @FAL金科应用研院 授权发布,未经许可,禁止转载。
题图来自 unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


