
 起点课堂会员权益
起点课堂会员权益产品评价标准的统计分析方法与应用
针对于产品评价,你知道什么衡量的标准以及数据统计分析方法?本文将重点解析数据量化标准的重要性和量化数据建模及产品评价应用,一起来看看吧。

今天主要从下面四个方向来展开分享,第一部分,数据量化标准重要性;第二部分,什么是评价类评级标准;第三部分,我们如何去做评价类标准;最后,进行案例分享。
一、数据量化标准重要性
第一部分让我们先稍微了解一下如何做数据样本收集以及数据量化工作具体是什么内容,这部分偏重理论一些。做数据分析项目,第一步一般都会提出项目调研的方向,然后设定调研问题。简单举例一下,假设我们想知道购买某一产品客户的平均年龄是多少?如上语句就是一个项目的调研方向,这里面其实蕴含了很多信息。我们现在逐一去刨析一下。
首先,我们可以锁定项目调研目标人群(population)是什么,数据分析上我们称为数据源;还是以我们这个举例来说,目标人群是购买这一产品的所有用户。
其次,我们要知道调研的数据变量(variables)有哪些;这个例子里我们的变量是年龄。知道调研数据变量是什么了,我们才可以去做数据分析的前端数据样本收集工作。
那么重点来了,我们需要根据我们的数据变量来设定调研问题;我们的举例比较简单,那调研问题可以是如下但不仅限于以下两种,在此也仅是举例:
调研问题1: 请问您的年龄是_____(请填写真实数字)
调研问题2: 请问您的年龄是以下_____
A. 25 及以下
B. 26-35
C. 36-49
D. 50 及以上
在此也简单介绍一下数据变量标准,在数据分析层面上,变量可粗分为两个大类:一是数字变量,就像调研问题1所提出的年龄数据收集,结果可以是 23, 24,或 59(岁),显而易见,每一个调研数据的结果是一个数字;还有很重要一点,在数学和统计分析角度上来讲,数字变量可以说是连续的,而且是直接的量化数据。
第二类是分类变量,即如调研问题 2 所提出的同样是收集年龄信息,但问题 2 是收集的年龄段,结果也只能是 A 类、B 类、C 类或 D 类。同样是收集用户年龄,但问题 1 和问题 2 所收集的数据变量是完全不同的。不同的变量有不同的数据分析方法和建模,因此变量标准对后期的统计分析的方法的应用、结论都是影响非常大的。在项目最开始的时候,我们就应该定好变量标准,它决定了项目后面如何去做。变量的标准是重中之重,但往往这点也是我们很多人都忽略的。
在此我也多介绍一点,调研项目通常不会只设定单纯的一个调研问题,所以一般数据变量也不会只有一个。再简单举例,在做人群细分、产品调研的时候,我们需要知道用户的全面信息,收集数据变量可以有年龄、性别、收入、家庭结构、居住城市、对特定产品的喜爱度等等,在此就不多做介绍了。
现在我们制定好项目需要的变量标准了,那问题来了,我们该如何去收集这些信息呢?需要做数据采集,又称数据取样,来收集我们的样本(Sample),在统计分析上,样本数据是我们目标人群数据源的子集。采样方法有很多种,也是通过了解数据变量和数据结构来确认最佳的采样方法,一般情况下,我们用的也是最多的,还是简单的随机取样。
取样最基本的原则,我们简化来讲,就是要求从数据源里面抓取每一个数据点的概率是一样的。这句话有点模糊,我举例来解释一下,假设某公司年会有一个抽奖活动,所有的奖券都放在抽奖箱里,我们怎么去确认每一个奖券被任何一个员工拿到的概率是一样的呢,换句话说就是抽奖完全公平,我们的做法通常是让工作人员尽可能的去摇抽奖箱,把奖券都摇匀,这就是最简单随机取样的例子。
我们做样本取样主要也是为了节省时间和成本,因为数据源可能包含成千上万乃至上亿个数据点,去收集这些所有的数据信息是基本不可能的。所以我们用随机取样在数据源中选择有限集的数据样本,样本数据点可能只有 30 个,或者 50 个,是有限集,最小样本量是需要根据分析方法来确定的。我们的目的就是用样本数据表象出来的统计值,来反映并展现出整个目标人群数据源的表现形态。所以数据样本的质量也是完全会影响到我们数据分析的结论,取样同样是重要并不可懈怠的工作。
本次的讨论重心还是放在数据量化标准的重要性和量化数据建模及产品评价应用上面。
二、什么是评价类评级标准
专家层面上的评价标准,第一个例子我们来讲一下米其林餐厅的评价标准。它通过专家对餐厅的食品、包括环境上的种种指标,调查给出 1 到 3 颗星的米其林餐厅的星级评定。
它是餐厅的最高荣誉,是一个级别的分类。细节上面,这里列了这五个(如下图)。米其林同时还有一个舒适度的评价,即餐环境的好坏程度有另一套评价标准,是用了一个五个刀叉的形式来表示的。


专家层面上的评价标准,另一个例子是比较直观的,是罗伯特·帕克红酒的评分标准,它是一个百分的评价标准。
它评价变量信息有颜色和外观、香气、风味和鱼味、综合的潜力,我们可以看到后面它有一个值域,它的变量是根据权重的维度来给出的分数,不是一模一样的综合给出来的。PR 评分从 50 到 100 来定位红酒的好坏。

用户体验层面评价标准,现在用的比较多的,我们现实生活中也都是接触过的,如豆瓣评分,看了一个电影之后,可以去评价,评价标准为 1 到 5 分,其实就是李克特的 5 分量表。
通过平台设定算法,然后可以最后给出来一个 2 到 10 分的打分,作为电影的一个综合评价。豆瓣评分还有一个 IMDb 评分标准,它是可以显示出一个电影的好坏的。IMDb 中电影的排名就不单纯的是用户的打分来算出来的,它用了一个计算公式,公式里面每个小写字母都是一个变量,变量值都是通过平台收集用户回馈的真实数据,使用如下模型综合评价得出,所以这个评价是实时的。如阿凡达这个电影,当时我选取材料作为素材的时候,排名是 75,我们现在去看它的排名可能会变化。

举另一个例子,美国的 yelp、中国的大众点评、淘宝、还有苹果的 app store 都是很常见的是 1 到 5 星的评价系统,标准评价的体系非常简单.可是我们去看淘宝选商品的时候,可能会去评价比较高的店铺去买东西,虽然用户都知道有可能部分评价数据是刷出来的,但是无论如何,在大数据面前,也认为是有理可依的一部分。
专家层面上的评价标准是有权威依据的,即我们理解的专家说的就是对的。其特点为样本量小,但需要行业专家参评。
用户体验层面上的评价标准有大数定理的统计依据,换句话说,用户还是相信,大多数人说好的东西一般就是好的。其特点为样本量需求大,但可以从使用者真实量化回馈意见中获取。
问题就来了,我们做数据分析,当然希望样本数据越多越好,但是在现实情况下,不可能去一味的扩大样本量,其耗时耗资,大多数情况下是不可取的或根本做不到的,所以我们就想尽可能用合适的统计分析方法来做到用最小的样本量,使用最小的人工成本,并得到有统计依据的分析结论。数据变量的量化和模型标准的制定就成了我们研究的重点。
三、我们如何去做评价类标准
如何做评价标准,这里介绍一下 SUS-系统可用性评估。可以说这也是我们比较熟知的一个评价系统了,它一共是十个量化问题,统一使用的是李克特的 1 到 5 级打分。
不管我们设定的变量问题是什么,假设我们问这个产品使用的舒不舒服,回馈变量数据都是 1 至 5 之中的数字,极简的模式但做到了数据变量量化。李克特量表是一个对称的关系,5 级量表来说,1 到 5 的话,3 就是中心值,如用户对于测评问题语句,感觉没有什么认同感但也不反对,可能会给出 3 分评价,赞同的话给 5 分,假设测评话语说到用户心坎儿里了,那么可能会给出 5 分。李克特量表,可以用正反向问题来问,假设我们的问题是今天是个非常好的天气,或今天的天气真是糟透了,让测评用户用 1 到 5 分来评价,其实这两句话问的是同一个问题,前者给 4 分,跟后者反向给的 2 分是一样的。
为了体验总体测评分值的好坏区分,研究人员加了第 11 个问题,即想知道好的评价到底是一个什么样分值打分区间,所以加了一个定性分类变量的问题,为(下图)七个级别,然后通过大量的样本收集(5000 个样本统计值)来分析到底多少分值是好,多少分值是不好,这样的话对系统可以有一个非常权衡的定位。

通过它的 95% 的一个置信区间做了一个均值的回归,把打出来的七个不同级别,分为一个小样本,然后取得均值再去做模拟,最后做出最重要的统计值的一个分布量表,叫做二次统计的样本数据,如下图左侧所示。这就是把统计值的样本数据做了一个分布的量表呈现。
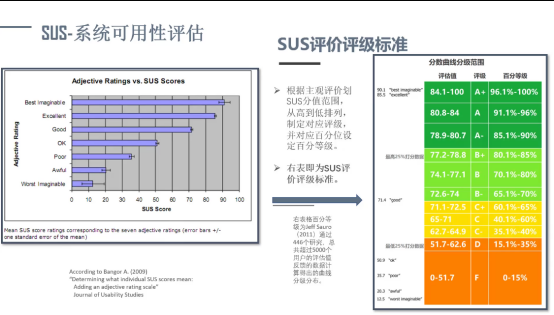
做这个工作是为了能看出产品在同类中处于哪个级别如 A 类,或 A+,从而看出给它评级评为 A 类的概念是什么,这里用百分位来表示,意思是它可能是前百分之几,即举例,产品如达到 A 类证明这个产品要比市面上 91% 的同类产品要好。
我们简单了解一下 SUS 的统计依据,因为它是一个变量量化的小样本分析方法,这个模型样本量只需要 20 个左右,但可以给出知信度高达 91% 的统计分析结论。但是,此类样本必须是有时效性的,有代表性的,必须是随机取样的样本。所以说尽可能地去缩小样本量,还是要有统计分析依据才可以,不然我们所做的分析工作是没有任何意义的。
现在想把数据量化的方法去做一个延伸,然后为我们用户体验和产品的评价去量身打造一个数据分析体系。我们怎么去做呢?
为了扩大变量信息收集的值域,得到分析中潜在数据变量变化内容,我们把 5 级量表扩大到 9 级,即 1-9 的打分,然后做产品综合评价值的模型搭建。我们的变量问题就不限数量,打造产品测评变量问题库,也是调研库,我们的变量数量可根据需要设定上百乃至上千,对于模型设定都是没有任何问题的。每次去使用变量时,不是说所有问题都要去用,我们可以针对这个产品想调研的方向,去做筛选,这里我也是不建议项目变量信息超过 30 个的,因为再多的话,样本质量可能就会下降。
综合测评值是什么概念?我们要达到的目的是,在我们收集到样本数据后,通过模型算法展示如下,给予产品的评价是一个 0-100 的打分,这是最直观的样本统计值。不管我们设定的变量问题是 20 个或者 50 个,模型都会回归给出 0-100 分区间内的综合评价统计值。

四、案例展示
下面讲一些实际应用案例。下图冰箱测评的一个指标体系,分了三大类指标,细分一级指标有产品的概念、设计美学、界面设计、操作、功能,还有产品表现形态等。大指标还可以去细分,如设计美学里可以细分为外观、尺寸、颜色,纹理,细节等。这个标准不仅限于冰箱或家电产品。
再往后看分类展现出的三级问题是直接触达用户的,或者是让专家评定给出分值的,三级变量是我们直接收集的样本数据。而二级指标和一级指标都是我们在统计分析模型里计算出来的统计值。这里陈述性的语句,如“这个界面好不好看、颜色我喜不喜欢”,是一个三级变量问题的语句,由被测评人给出 1-9 打分。
用户看到的可能只有下图中的三级变量问题,但是标准背后的设计和变量问题权重,包括计分算法模型,以及我们的分析方法都不需要去了解。这也是单盲实验法中为做到样本数据无偏激性。我们尽可能要去收集到高品质的样本数据,不需要把我们设计的所有内容完全给用户解释清楚,这样反而会影响用户的判断,因为我们希望用户给最真实的反馈。

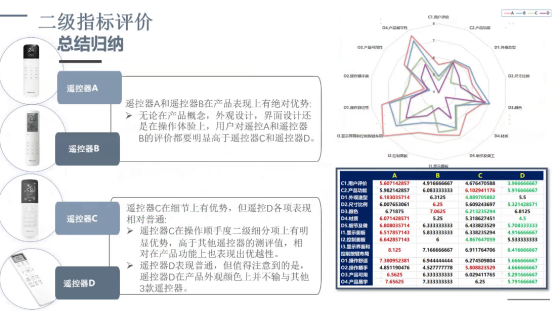
这是(如下图所示)当时做的遥控器的模板测评案例,测了四个模板,可能设了 48 个变量问题,每个模板都对应一个综合评价值。那我怎么样去解读,拿遥控器 A 来举例,81.71 分在最右侧,对应 A 级,按照百分位等级来说,它可能是比行业内 92% 的产品要好。

我们用李克特对称量表的方式主要是做量化。如下图所示,数据可视化展示可以用不同的颜色色段用户评价展示出来,这里设了十个心理测评问题,在数据编程后计算出,直接把最认可的问题放到最上面。
如下图第一个问题,“我愿意多花钱去买好的东西”基本上能看到 84% 的人给出了五分以上,表示认可态度。粗略地来看,可能有 42% 的人非常赞同,当然也有很少数的不认可,可能是 8% 的。这样去做分析,是想剖析到产品的每一个细节上,用变量信息展现出产品到底是哪里好,哪里不好。

下图产品概念,把它分为二级指标,图中红字其实就是代码里的变量的名字。
通过这几个问题,也可以用数据量表来评价产品功能或产品概念到底是好是坏。下图是数据可视化的呈现给出了数据分析效果。
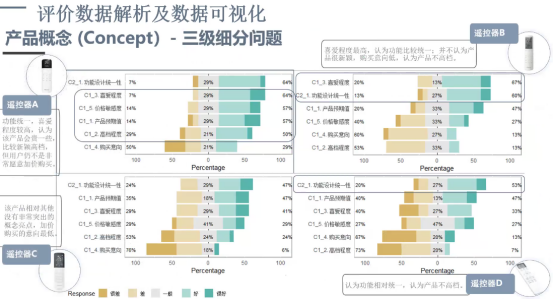
用另一种形式去看,可以做对比分析。具体分析A、B、C、D,单向哪里好,哪里不好。这些统计结果单纯是通过数据可视化展现出来的。

二级指标也可以用对比分析,用这种雷达图(下图)来表现其实也很直观。我们用量化方式,能直观地表现出产品需求,产品的好坏,同时我是想用这套理论,来提示在专家层面上产品需不需要研发或改进,或者是从用户角度上反馈使用场景上哪些需要去提升。
无论作为设计师,还是产品的开发方,对产品的好坏的评价一定要结合专家和用户两个方面去看。
第二个案例是《青岛历史建筑与传统风貌建筑保护技术导则》。
在评定历史保护建筑的时候,它可能也是有一些指标的。比如说哪个年代,什么人去居住过等等。
作为历史保护建筑,我们去做数据评价,是想知道什么建筑是归为几类保护。在知道保护级别后,不同的级别对以后建筑的翻修、使用、包括整个城市的规划,都是有不同的方案的。
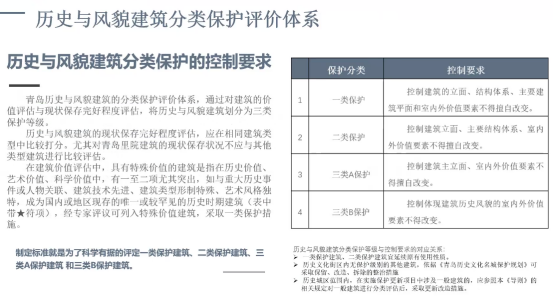
下图是具体的两个量表,虽然量化方式不太一样,但最终把它的分类变量也分到了 1-5 的级别。第一个量表是历史风貌建筑保存的完好程度现状评估,最终统计值也是 0-100 的打分。
第二个量表是历史风貌建筑价值评估,同样建模设定回归为 0-100统计值 打分。根据样本分布,我们把历史与风貌建筑现状保存状况评估,通常设定60 分及以上为较好;40-59 分为一般;39 分及以下为较差。历史与风貌建筑价值评估,通常设定 65 分及以上为较高;41-64 分为中等;40 分及以下为较低。
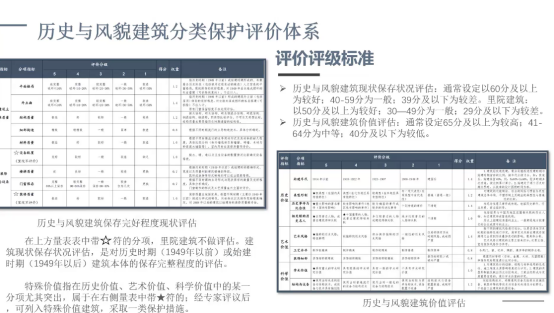
因为这个模型是双量表样本数据收集,我们最后商议的是用坐标象限的方式来展示,纵坐标为建筑评定价值,横坐标为现状保存状态,通过这样来评价出历史保护建筑的类别。
五、结语
我们在做数据分析项目时,研究数据变量的形式其实决定了分析方法及建模。所以制定数据量化标准的工作也是非常重要的。量化数据的统计值的分布比较多样,我们可以直观了解更多潜在的信息。
制定好量化数据标准也有益于我们去累计数据资产,不会出现项目内样本数据仅限于项目内使用,无法与其他项目样本数据匹配对接的情况。
最后,数据分析是一个全流程有连续性思维的过程,从数据变量的制定,变量量化标准的制定,确定采样方法,收集样本数据,制定分析模型一直到最后使用统计值做出的分析依据,需要从始至终有依据地去执行。这也是我们做变量量化标准及制定评价类分析体系的初衷。
作者:徐龙骧;图文编辑:筱沄、司嘉惠
来源公众号:用户体验大学堂(ID:isaruxd),专注用户研究和用户体验设计。
本文由人人都是产品经理合作媒体 @用户体验大学堂 授权发布,未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。









请问楼主,文章采用的这些图片出处哪里?我想借鉴下
您好,文章内容出自用户体验年会2023专家分享
想请教一下,SUS系统可用性评估应该是有自己的一套打分标准,为什么在文章中需要对各个数据点做均值回归,取得均值后再去做模拟,得出统计值的分布量表呢?
您好,SUS有自己的标准打分算法(每道题转换后加总),这是为了得到个人或产品的总分。而文章中进行的均值计算、模拟和分布分析是统计方法,目的是为了解读这个总分、评估其可靠性,并做出更科学的推断。
原始SUS分数是一个有用的起点,但单独的分数意义有限。通过统计处理(如计算平均分、置信区间、进行t检验),可以将简单的分数转化为支持产品决策、评估迭代效果和进行基准对比的有力证据。