
 起点课堂会员权益
起点课堂会员权益数据分析入门:初始数据埋点(二)

本文主要针对Key-Value字段的价值展开讨论,并简析其灵活运用的方法。
Hi,各位看官老爷们好O(∩_∩)O~,在第一篇《数据分析-初识数据埋点》中已经对工作中应用的数据埋点的基础概念、基本分类、定义规范、流程以及应用场景做了简单的介绍,基于部分看官老爷反馈Key-Value字段晦涩不易读的一些问题。
所以本篇将在之前介绍的基础之上,深入一步,详细讨论Key-Value字段的价值,以及灵活运用的方法。期望能帮助各位看官老爷基于业务需求在自己进行产品的埋点方案设计时提供一些解决问题的思路。
在第一篇文章埋点定义规范部分对应Key-Value字段没有向看官老爷交代清楚,本汪痛定思痛,面壁思过,还望各位海涵。在本篇中针对遗留问题做了详细的图文解释,还望之前留言的看官笑纳。
正文
在上篇中我们已经知道,一个完整的埋点需要定义哪些字段,回顾如下:
- 功能字段
- 中文名字段
- 事件类型字段
- 事件ID字段
- Key字段
- Value字段
- 记录规则字段
- 备注字段
写到这里,看官老爷可能会问:埋点中定义Key-Value有什么价值?接下来本篇第一部分的篇幅将与大家一起一探究竟。讨论到底Key-Value是做什么用的。
先写结论:
设计事件埋点时:
- 同种属性的多个事件,建议命名一个埋点事件ID,并通过Key-Value键值对进行区分。
- 不同属性的多个事件,建议命名多个埋点事件ID,不建议使用Key-Value键值对进行区分。
乍一看,可能有些晦涩难懂,以下将举两个实例,自然就能明白易懂。
实例背景:某汽车互联网公司,领导对负责新车业务的产品经理X君、负责二手车业务的产品经理Y君提出需求:对新车APP和二手车APP销售线索数据指标进行数据监控,如有超过5%的数据变动,则需要向上级汇报波动数值以及波动原因。
名词注释:
- 销售线索:通过事件记录到用户有明确的购买意向,记录行为的事件例如:电话咨询、短信询价、加入心愿单、收藏、特别关注等类型事件。记录一个用户即代表一个线索。
- 数据波动:即((当日数据-昨天数据)/昨日数据)*100%=环比数据波动

根据领导需求,假设定义短信砍价按钮与电话咨询按钮为销售线索指标,销售线索按钮页面的入口来源页面包含:页面A与页面B。
X君与Y君分别设计了埋点方案,如图所示:
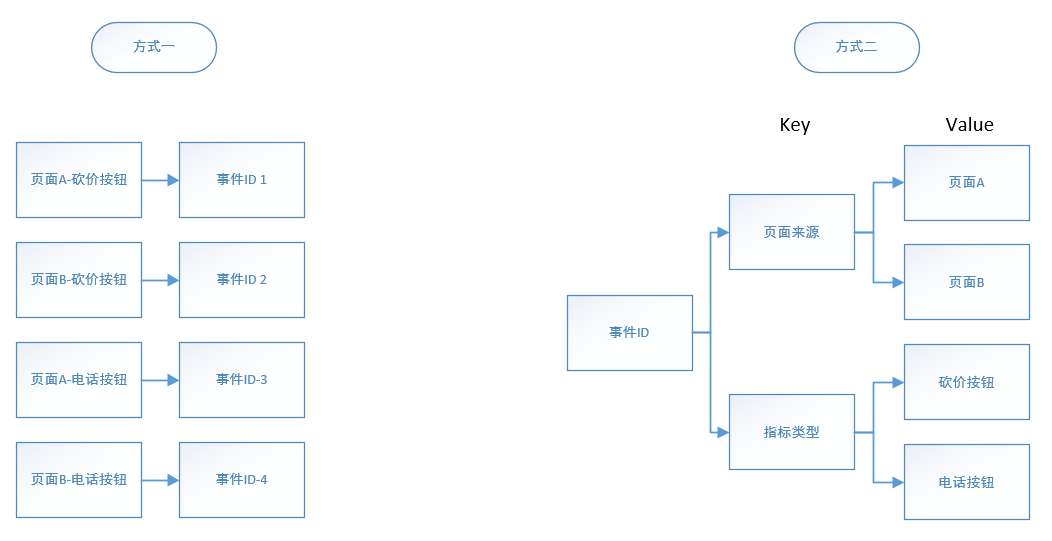
X君埋点方案:

X君经梳理得出,在商品详情页共计有两个按钮是销售线索的核心指标分别是按钮一:短信砍价、按钮二:电话咨询。并且有外部入口导流到详情页的有两个页面,分别是:页面A、页面B。根据流量来源的不同与事件类型的不同分为4个埋点事件,每一个埋点事件代表一种情况,如上图所示。
方案分析:
X君对每一种情况都单独设置了一个埋点事件ID,初步看上去还没什么问题,X君只需每天用这四个事件ID去后台搜索即可满足领导的需求:对核心指标进行监控。
假设随着业务的快速增长,新增更多的外部入口页面,由原来的页面A、页面B的2个入口页面增加至4个、8个、12个,同样随着产品优化需求的上线,新增更多的销售线索事件,由原短信砍价和电话咨询2个销售线索事件增加至4个、8个、12个。
在极限情况(12个外部页面入口、12个销售线索事件)下X均需要共计维护:
12*12=144个埋点事件ID。
假设分析场景:12个流量来源、12个销售线索事件,分析X天共计提交了多少线索?,来自页面A的有多少?
问题一:分析X天提交的销售线索中来自页面A的有多少?
解决以上问题,X君首先需要将流量来源是:页面A的12个不同类型销售线索埋点事件ID找出来求合算出数值。
问题二:分析X天用户共计提交了多少线索?
其次需要将剩下的11个流量来源各维度下12个不同销售线索事件的ID一一取出数据加上流量来源是页面A维度下的所有类型线索取出的数据,并进行最终求合算出X天共计提交线索数…写到这里,各位客官老爷可能会说:X君好累啊~,其实不仅累,并且会带来严重效率问题:
- 产品经理自身的工作效率会极大的降低,埋点事件ID越多,效率越低,最后极限情况下会无限逼近于零效率、零产出。
- 埋点事件无论是普通埋点还是关键核心指标埋点,不仅产品经理需要监控自身产品健康情况,兄弟部门像:数据运营同事、数据分析同事都会基于部门需求对产品进行数据分析与监控,如果像刚才这种情况,数据运营同事每周写数据周报时,单单是一个埋点事件就要计算12个流量来源进行求合,效率极低,会严重拖累运营同事的工作效率。并且对于数据分析师来说,假设在统计整体的销售线索指标时,如通过X君定义的埋点进行分析,在写查询语句SQL时,单是事件ID就要写144个,(大家脑补下数据分析师有节奏的拷贝事件ID 144下时这个画面),数据分析时会毫不犹豫的说:“来来来,X君我有事找你谈谈~~”可能有的看官会说:一个按钮用一个埋点事件ID记录就好了,不用区分页面流量来源,那问题来了:当数据产生异常波动时怎么确定是哪个页面的流量入口的流量变动导致最终的结果?
- 由于每天产品经理需要大量的埋点事件ID来统计一个指标,导致工作效率低下,可能会让领导对你产生工作能力差,产出效率低下的不好印象…
那客官老爷会问:那怎么办?稍安勿躁,马上揭晓,请继续向下看。
Y君埋点方案:
首先Y君对于销售线索有关的内容从各个维度,按照逻辑关系进行拆分,梳理出以下脑图:
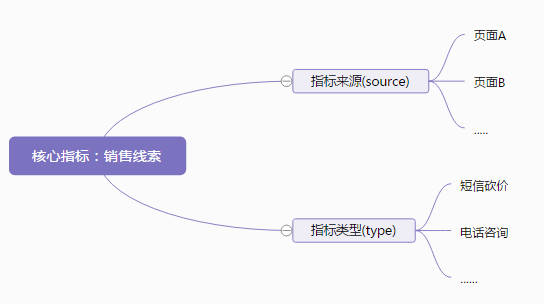
写到这里就不卖关子了,基于思维导图中的逻辑关系,Key-Value闪亮登场!!!

Y君基于思维导图中的逻辑关系,使用Key字段表示分析的维度,使用Value字段表示不同维度下对应的唯一参数标识,从而将每个维度下众多不同的参数区分开来。通过Key-Value与同属性事件ID的配合,像销售线索这个指标就可以用一个事件ID来表示。在未来即使扩展N个外部入口流量页面,也只需要在当前事件ID在表示流量来源Key维度下在首次开发时新增N个Value参数即可。在未来应用于数据分析时,只需要搜索或写一个事件ID即可对各维度(Key)下不同参数(Value)进行分析,简介、高效。
例如假设分析场景:12个流量来源、12个销售线索事件,分析X天共计提交了多少线索?,来自页面A的有多少?
问题一:分析X天提交的销售线索中来自页面A的有多少?
Y君只需在后台查一个事件ID,并指定维度Key=指标来源(source)、Value=对应维度下参数为:页面A,最终求出的结果,即代表来自页面A的总数。
问题二:分析X天共计提交了多少线索?
同理,Y君只需要写一个事件ID,并指定维度Key=指标来源(source),Value=无。最终查询出的结果即代表总的线索数。
注释:
- 当不指定Value时,默认为包含该维度下所有参数(本例中即代表所有来源)。
- 各位看官可能会问:当不指定Value参数,且不指定Key维度,Key=无,Value=无 时,对最终总线索数有影响吗?答案是没有。
- 同理,一个事件ID,指定Key=其他的维度,例如:Key=指标类别(type),不指定Value参数,例如Value=无,对最终总线索数统计有影响吗?同理答案是没有。
Y君通过梳理逻辑关系,将同属性的埋点事件使用一个总事件ID表示,结合Key-Value细分不同维度下的不同参数,方便日后数据分析。通过此方式很好的解决了X君面临的问题,不仅如此,并且具备以下优点:
- Y君的维护成本低,更加简洁,新增时只需要首次开发时加一个Value参数即可。
- 提高Y君自身、数据运营、数据分析师等兄弟部门在数据分析时的工作效率。
- 扩展性好,对未来新增业务需求有良好的扩展性。
相信介绍到这里,大家对埋点事件中Key字段、Value字段配合使用带来的价值已经有了一定的了解。当然如果不同属性的埋点指标还是建议分开,一个属性定义一个事件ID,不能将八竿子打不着两种属性的埋点强行捆绑在一个埋点事件ID上,为了用Key-Value而用Key-Value,生搬硬套,最后只会适得其反,没有实际意义。
例如:在实际业务中,将用户点击“注册账号提交”按钮的行为放在销售线索这个属性事件ID中也通过Key字段、Value字段进行区分标识。结果没有参考价值,更没有实际意义。
综上所述,得出在正本第一篇幅中给出的结论:
设计事件埋点时:
- 同种属性的多个事件,建议命名一个事件ID,并通过Key-Value键值对进行区分。
- 不同属性的多个事件,建议命名多个事件ID,不建议使用Key-Value键值对进行区分。
各位看官老爷可根据自己产品的实际业务需求灵活运用,希望对大家在进行埋点方案设计时提供一些逻辑思路,帮助大家解决实际问题。O(∩_∩)O~
总结:
通过上一篇文章的基础理论铺垫,以及本篇中对埋点Key-Value字段的进一步介绍,涉及埋点方案规划的内容已基本讨论完成,期望本文中涉及埋点的篇幅能够帮助0-1岁的产品老爷在工作中规划以及维护埋点时提供一些逻辑思路,以及针对不同情况下解决问题的一些方案。
使最终交付的产物具备良好的扩展性、健壮性、易用性、高效性、可维护性等特性,以达到使自己以及兄弟部门花最少的时间成本获得最高数据价值的目的!
下篇预告:
经过详细且周密的准备工作以及产品线上各个环节童鞋的齐心协力,需求以及埋点方案终于上线啦。部分看官认为上线了即代表大头的活都完成了,实际上,上线后才是埋点刚刚开始收集数据的开端,这才刚刚开始~
埋点上线后可能会面临以下问题:
- 上线后等多长时间取数?1天?…10天?,取几天是正确反映事实的?取数逻辑是什么?为什么?
- 同一份数据,不同的人给出了不同的结论?该相信谁?是数据错了还是分析错了?
基于以上疑问,下篇与大家一起利用统计学上的理论与方法与大家深入讨论,帮我们找到真相!敬请期待O(∩_∩)O~
看到这里,看官老爷们会说:看到问题刚勾起了本看官的探索欲,正在劲头上,文章内容怎么就更写完了?解决方案呢! ̄へ ̄ 说!双汪你是不是在偷懒? ̄へ ̄
各位看官老爷息怒、息怒。且听我解释:
本文除了与大家交流学习的目的外,作为一只产品汪,最重要的当然是为各位看官老爷提供一个良好的阅读体验啦O(∩_∩)O~ 因为双汪通过数据分析垂直资讯类网站的文本内容发现,单篇文章在5000以及5000字以下时,综合起来给用户带来的阅读体验是最好的。
读到这里相信大家也已经有些小累了,不如泡杯热茶,小憩一会儿,在下篇文章中与各位看官老爷讨论解决方案,双汪加班加点,第三篇已经在路上了,o(*^@^*)o敬请期待~~
最后一句:以上我说的都是错的,只有适合你的才是正确的!
再加一句:各位看官老爷,如果您觉的本文对您有帮助,记得给个赞哦,(*  ̄3)谢谢啦。
相关阅读
本文由 @Aaron 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 Unsplash ,基于 CC0 协议









你好,能够给个联系方式,想找你学习数据埋点相关知识。
研究了一小会儿,发现某盟是做不到这样的效果的,国内有没有较好的数据分析工具推荐,偏产品使用数据层面的。
做不到嘛!
行文思路、结构就如同埋点思路结构一样精辟、缜密
数据产品小白……最近被数据埋点问题弄的晕头转向,看了这篇文章感觉清晰很多!
受益匪浅!!!数据分析入门:初始数据埋点(三)呢?没有搜到哈哈
非常详尽实用了!必须赞一个!
半懂不懂,不过感觉很深奥,我还没有接触到埋点呢,,,
那假如我想知道页面A询价按钮被点击多少次 该怎么写公式呀 为什么你没有提到key=type
同问。。。Key=source只是来源,Key=type才是线索,求销售线索肯定会用到Key=type的条件,这两个Key应该联合查询的,但具体怎么用呢?请教~~
select count(事件id) from 表A where type=”电话” and source=”页面A”
这样写不行吧? 字段名是 key和value; type 和 source 都是key
干货
我也问一个问题哈:web、wap产品的埋点数据上报时机一般什么时候好呢?
请教一下埋点之前,脑图时应该以事件为中心去拓展还是以指标为中心去拓展?
业务核心指标为中心
精辟,案例多点会更好,我比较笨
终于搞懂了啊!感谢感谢啊!
安排!
我想知道第三篇在哪,这个真的是干货啊,系统全面,逻辑清晰有木有
不指定key和Value 为什么会灭有影响的
可以留个联系方式吗?给你介绍对象 😳
这位看官,您是认真的么 😎
看到一半忍不住先下来点个赞,解释的非常清楚,非常棒!!收获很大!!感谢!!!
送你两个字:大神!请收下我的膝盖 😉
感谢大神分享
这两种埋点方式都有埋点维护的问题。而且大神的埋点设计是基于分析目的设计的,我的理解是基于各页面和控件埋点至上的指标,若要这种埋点方式,前期需要把各页面和控件的埋点做好吧。
很有意思,学习了,必须给赞
大神 恕我说一句啊,其实 一个事件一个id 淘宝就是这么做的,至于你说统计分析工作效率低下,就看开发牛不牛逼了。我当时作为开发我也问过为什么不能 归类出一个大id ,产品经理表示其实是一样的,只是他们的规范就是一个事件一个id. 后来他们也有改进就是有子id 了,一个大类id后 有了子id 而不是通过key value , kv对反而记不住那么多内容。而你说的纯写sql 确实会碰到100多个id 的问题,但是 开发如果长点心,就会把这个做成可以可视化并选择 让bi 去拼整个sql 而不是自己写。
各公司的规范不同,方案会有细微的差别,但总的原则都是一致的,最低的维护成本,最高的效率维护数据。
hello,方式一和二的区别,是不是只是方式一没有冗余更多的类型判断的字段?其他我看不出差别啊?
您好我问下,某盟统计漏斗是那种不连续的漏斗,这样会导致数据不准确吧?
比如我想看AB两个按钮的转化,会出现转化率大于1的情况下吧? 通过某盟提供的方法可以避免这个情况吗?
转化率大于1和数据准确性问题是两件事。
转化率的问题建议检查下计算公式,
准确性的问题是相对而谈的,某盟还是比较准的,如果对精度有要求,可以自己公司的数据部门搭建Hive,自己跑报表,代价就是开发成本高
受益匪浅!
hi 你好,咨询一下友盟埋点里怎么通过K-value方式埋点呢?谢谢
同问!
大神,求第三篇呀,很急很关键。
第三篇已上传啦 😳
写的真好!受益匪浅 看的意犹未尽 发现之前自己对埋点的认知太模糊 期待第三篇!!
如果按照Y君的做法,此时有问题三:分析X天提交的销售线索中是电话咨询的,来自页面A的有多少?
数据库肯定能并列搜索的啊,如source=1and type=2
不是按照key ,value进行列建表的吗?你这样的话 就需要按照所有的key中的所有值为一列了。麻烦请教一下
同问
Hi,这位看官所言极是,如果在问题三这样的场景下,在查询数据时,查询语句是支持同时指定两个Key的,这样就可以解决您的问题,希望能帮到您呢 😳
没有明白作者的意思呢。如果是在查询中用“并且”关系的话,source和type应该是两个并列的字段才对,但是现在这两个是key字段中的两条不同的记录。没有明白怎么找到source和type二者的交集
同问 😳
同感,其实source和type应该是两个并列的字段,放在表头。
页面A、页面B是source的两个value,电话咨询和短信咨询是type的两个value。
作者说的key是字段的统称,不应该放在表头。
是的,应该表里面source和types是2个字段(即表头,表里面A列第一行和B列第一行),页面A、页面B是source的两个值(表A列第二、A列第三行),短信砍价、电话咨询是types的两个值(表B列第二、B列第三行),而不是key,value这两个是字段(表头)
这个表 value = 电话 同时满足 value = A页面 根本没有记录,
而且两个key的两条数据有可能是重复的记录,(比如 李四客户在页面A-电话的场景记录 同时在key=source 和key=type中都记录了一次)不符合表的设计规范。
同样是查询短信砍价次数,两个key同时查询时,在source里记了一次,在type里也记了一次,这两次的次数含义是相同的,那最后查出来的次数数据不就有重复的么?
我看了第一篇也有这个疑问,至于大家说的并集搜索,前提应该是type中带有source的参数才可能。目前在Y君的分享中好像没有体现这个,type和source是没有关联的。不知道程序写的表是否有记录这个信息(即表格记录一次 type:电话咨询,来自A)