
 起点课堂会员权益
起点课堂会员权益5款主流TTS专有名词测试:全军覆没——我用一个中间件解决了
数字人在电商直播中频频将产品参数读错,从处理器型号到电池容量,每一个错误都在消耗用户信任。本文通过五款主流TTS的横向测试,揭示了行业性的系统缺陷,并提出了专有名词读音的三层优先级框架。最终发现,问题的本质并非技术不足,而是知识获取与发音能力的割裂。

一、从一个让人抓狂的问题开始
在做数字人评估的时候,我发现了一个反复出现的问题。
数字人在介绍产品时,把”i7-11800H”读成了”i七一万一千八百小时”,把”RTX5090Ti”里的”Ti”读成了”T-i”而不是”钛”,把”mate80″读成了”mate八十”,把”1080P”读成了”一千零八十P”而不是”幺零八零P”,把”5000mAh”读成了”五零零零m-A-h”而不是”五千毫安时”。
这些错误单独看都不严重,但在电商直播场景里,数字人每天要说几千个产品型号和参数,每一个读错都是一次信任损耗。
我开始怀疑这不是某一款TTS的问题,而是行业性的缺陷。于是我用同一段文本,对5款主流中文TTS做了横向测试。
二、5款主流TTS横向测试:全军覆没

测试文本刻意覆盖了电商直播场景里最高频的专有名词类型:处理器型号、显卡型号、手机系列、视频规格、电池容量、单位后缀。
测试文本:
搭载R7-5800H、i7-7700和i7-11800H的联想R9000P和微星GP76同时搭载RTX5090Ti最强显卡,搭载麒麟9000处理器和天玑9400芯片的掌机支持4K和1080P输出,当年的麒麟980处理器玩720P游戏帧率爆表,搭载5000mAh电池续航也能有20小时。华为致敬mate8的经典作品mate10是一代经典,而今mate80的发布,这让我想到了苹果iPhoneX,近期荣耀500系列。
结果一目了然:
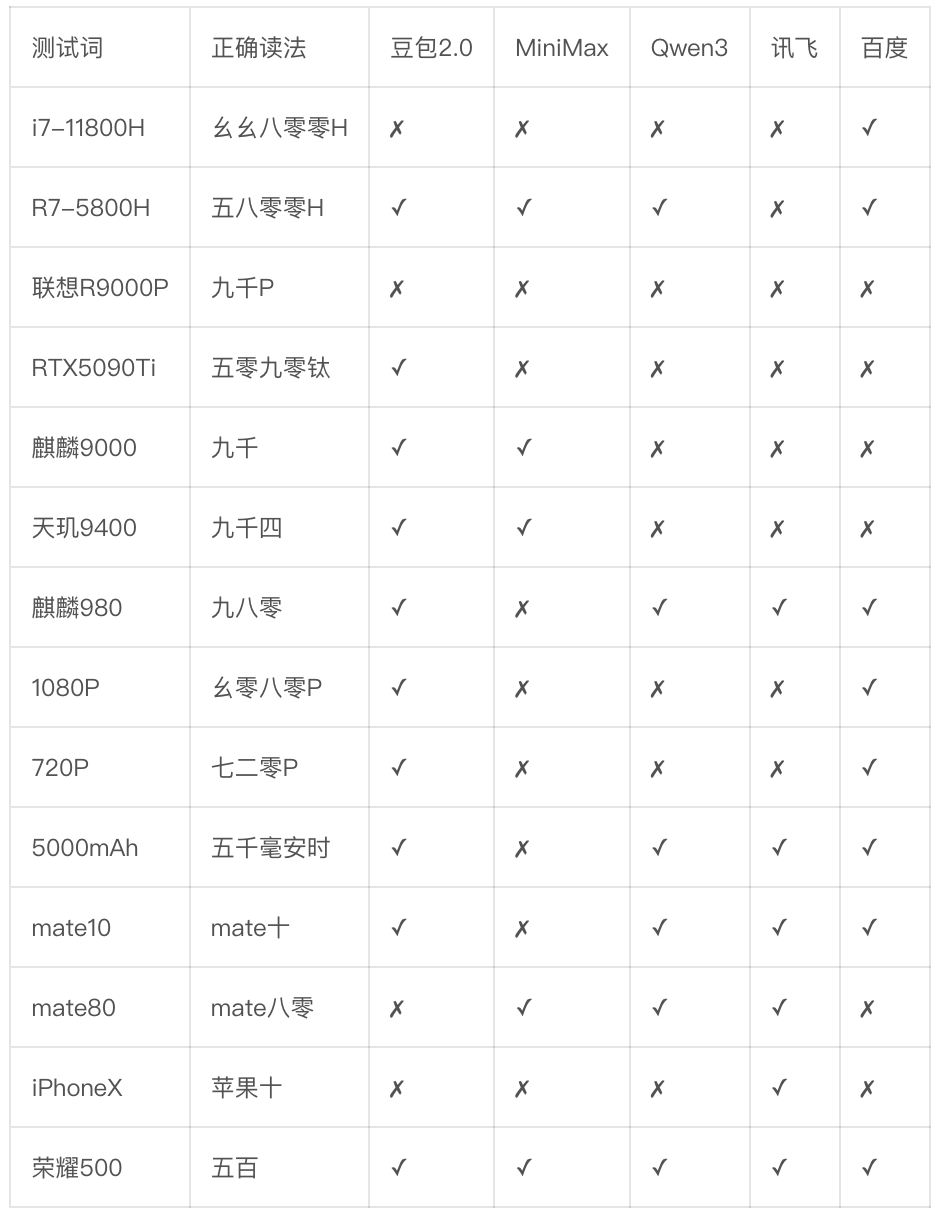
没有一款模型全部读对。最好的豆包2.0错误率29%,最差的MiniMax达到57%。联想R9000P五款全部翻车,iPhoneX只有讯飞读对。
这不是某个模型的bug,而是行业性的系统缺陷。
我开始系统整理这些错误,想搞清楚一件事:TTS在专有名词上的失效,到底有没有规律?
三、规律是存在的,而且有优先级
整理了几百个案例之后,我发现所有专有名词的读音,本质上遵循一个三层优先级框架,层级之间是覆盖关系——上层规则命中就直接输出,不走下层。
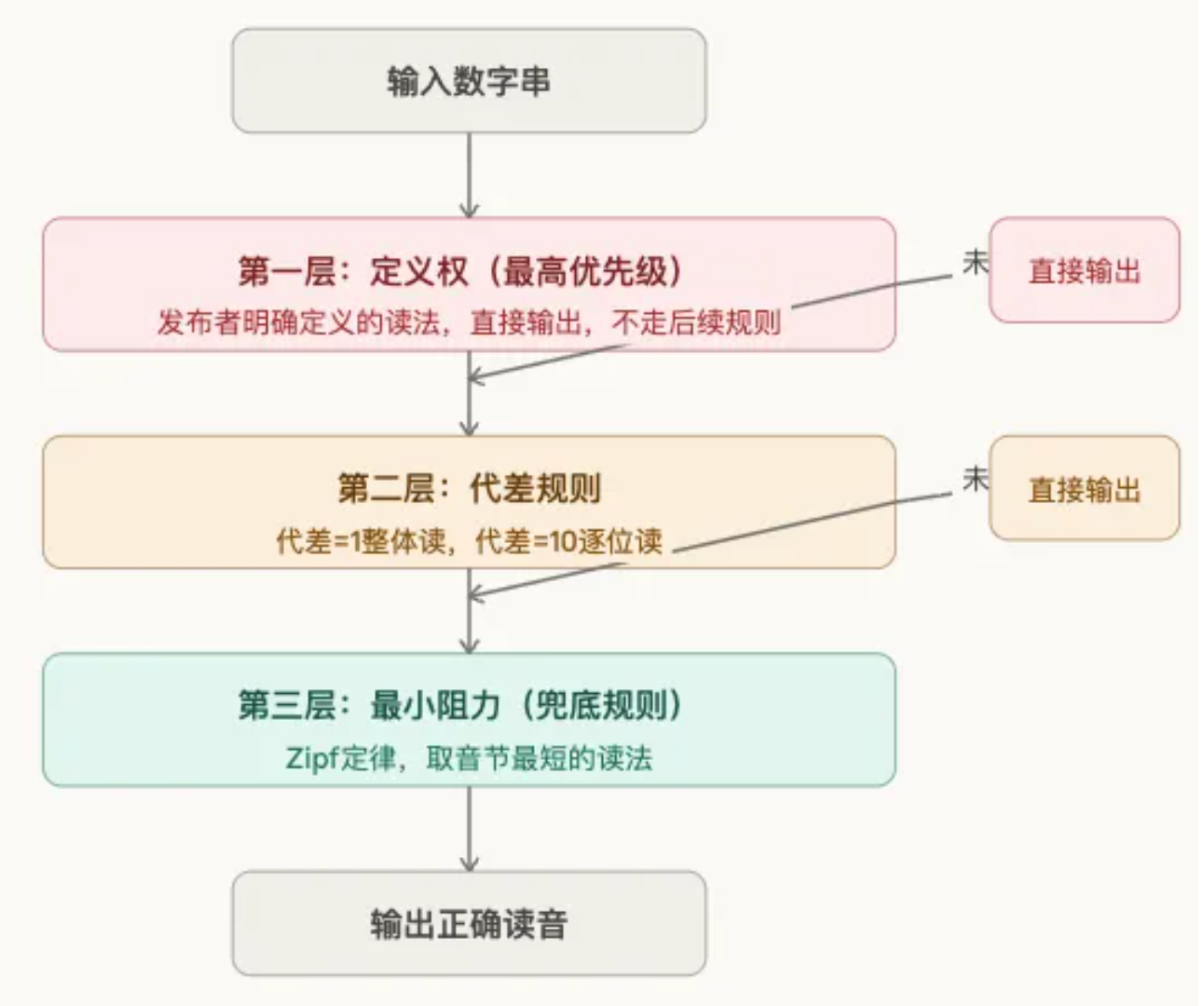
图一:三层优先级决策框架
第一层:定义权(最高优先级)
某些词的读法,是由发布者直接定义的,超越所有规律。苹果从iPhone 8跳到iPhone X,中文用户叫它”苹果十”而不是”苹果X”,因为苹果的中文发布会里这样定义了。”mate80″读”八零”不读”八十”,因为这代表代际而不是数量。
定义权还延伸到单位后缀。同一个字母在不同语境下读法完全不同:
- Ti:RTX5090Ti里的Ti读“钛”,不是“T-i”
- H:i7-11800H里的H读字母“H”,代表高性能版本;但5000mAh里的H是“时”(小时)
- mAh:整体读“毫安时”,不是逐字母读“m-A-h”
- P:1080P里的P读字母“P”,代表逐行扫描
这些后缀无法靠规律推导,需要结合上下文语境判断,是纯算法的天花板。
这类读法是外生的,属于新知识注入,一旦命中,不走后续任何规则。
第二层:代差规则
品牌产品线的迭代数字,读法取决于和上一代的代差。以华为mate系列为例:mate7、mate8、mate9是个位数迭代,代差为1,读整体数字——”mate九”。从mate9升级到mate10,代差变成10,读法切换为逐位——”mate一零”。此后mate20、mate30、mate80全部逐位读。小米14升级到小米15,代差依然是1,所以读”小米十五”而不是”小米一五”。
规律是:代差=1(个位迭代)→ 整体读;代差=10(X0结尾)→ 逐位读。
这条规则说明了一件深刻的事:TTS读音的背后,编码的是品牌的迭代节奏,不是数字本身。要判断”mate80″该怎么读,必须知道它的上一代是mate70。这是纯算法永远无法自动推导的,因为它需要理解品牌历史。
第三层:最小阻力(兜底规则)
前两层都没命中时,人类口语天然倾向于音节更短、发音成本更低的方式——这本质上是语言学中**省力原则(Zipf定律)**的体现。核心计算逻辑:对每个数字串同时生成”整体读法”和”逐位读法”,取音节更短的那个。
- 麒麟9000:“九千”2音节 vs “九零零零”4音节 → 九千
- RTX5090:“五零九零”4音节 vs “五千零九十”5音节 → 五零九零
- 联想R9000P:“九千”2音节 vs “九零零零”4音节 → 九千
最小阻力还有一条口语省略子规则:整十、整百、整千结尾时,最后的单位可以省略。天玑9400,口语读”九千四”,”百”字省掉,因为不影响理解。
四、这个问题的本质是什么
整理完规律之后,我意识到一件事:TTS读不对专有名词,不是技术不够好,而是发音能力和知识获取能力被混在一起了。
传统TTS的处理流程是:文本 → 文本正则化(Text Normalization,TN) → 拼音 → 声学模型 → 声音。问题出在文本正则化这一步——模型不知道”联想R9000P”里的9000应该怎么读,不知道”RTX5090Ti”的Ti该读”钛”,只能按通用规则处理,结果就是读错。
声学模型本身没有问题,问题在于它收到的输入就是错的。
五、验证:一个非技术人能做到什么程度
想清楚这个本质之后,我决定自己动手验证。没有任何编程背景,一台M1 Mac,用AI协助写代码,看能做到什么程度。
第一阶段:词典注入
最直接的方案是在文本进入模型之前,把专有名词替换成正确的读音表达。建立一个外挂词典,强行改变输入给模型的文本,声学模型本身不需要动。
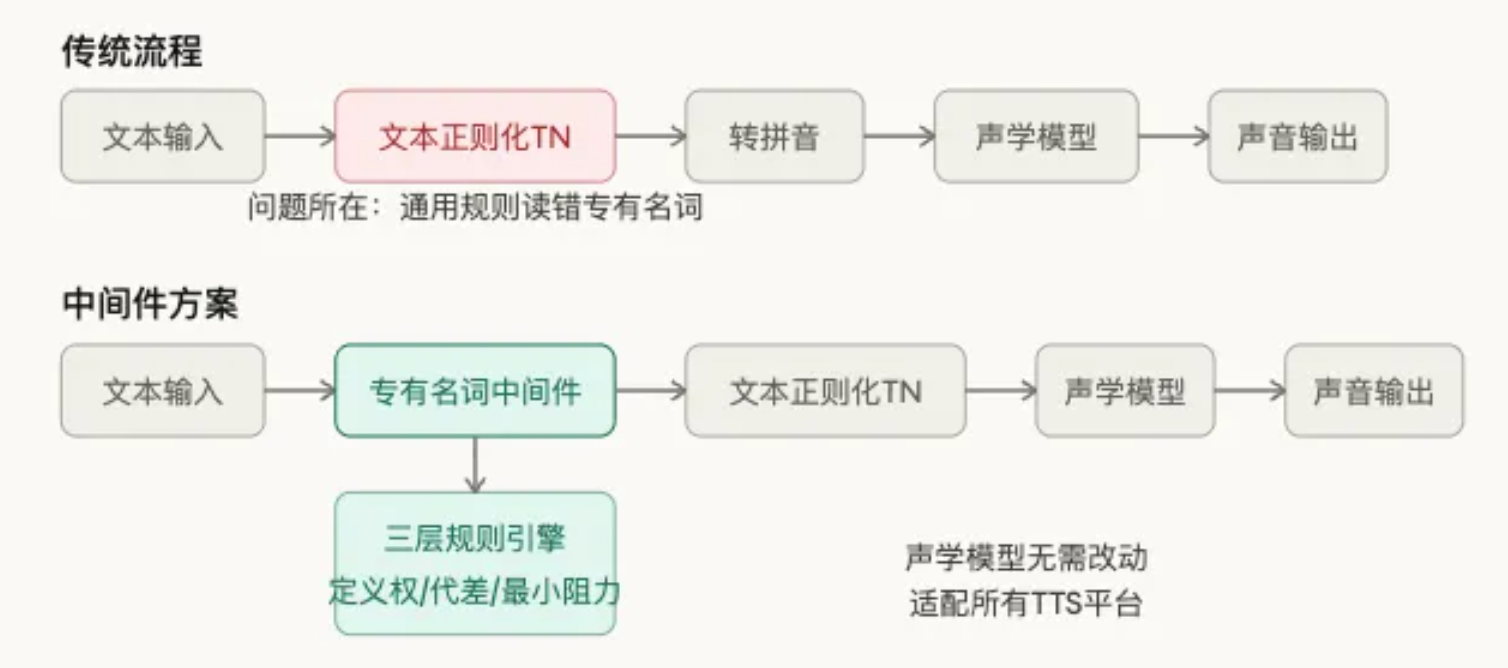
图二:TTS处理流程对比
接入开源TTS模型Edge-TTS,效果立竿见影——”RTX5090Ti”读对了,”mate80″读对了,”5000mAh”读对了。但很快发现了覆盖度问题:词典里写的是”mate80″,mate70、mate90出来就要手动加。每一个新产品发布,都需要人工更新。这是词典方案的根本局限。
第二阶段:把规律写成算法
词典是”给鱼”,把规律写成算法才是”给渔”。基于三层优先级框架,用Python实现了完整的规则引擎。测试结果:
- 联想R9000P → 九千P ✓
- 天玑9400 → 九千四 ✓
- RTX5090Ti → 五零九零钛 ✓
- 麒麟980 → 九八零 ✓
- 1080P → 幺零八零P ✓
- 5000mAh → 五千毫安时 ✓
- mate80 → mate八零 ✓
- mate10 → mate十 ✓
新型号只要不是特殊规则,算法自动覆盖。这个方案的核心优势是不侵入TTS模型本身,可以适配所有TTS平台,直接前置接入。
六、为什么大模型也解决不了这个问题
自然会想到:现在的端到端语音大模型,比如今年1月刚发布的Qwen3-TTS,有没有把这个能力内化进去?
从测试结果看,Qwen3-TTS的错误率依然达到50%。这个结果并不意外。事实上,目前行业里做得最完整的开源文本正则化工具是字节跳动的WeTextProcessing,几乎所有主流开源TTS都在用它。但它的核心局限和所有同类工具一样——只有通用语言规则,没有针对3C、电商等垂直场景的适配,完全解决不了专有名词问题。
更大的模型 ≠ 专有名词读音更准确,因为两类问题的性质根本不同:
最小阻力类的规律理论上可以被模型学进去,训练数据足够多的话模型会形成这种语感。
定义权类的知识永远学不进去。雷军今天发布会上定义了新产品的读法,这个信息在发布会结束之前不存在于任何训练数据里。无论模型多大,这部分永远需要外部知识注入。而商业场景要的不是”99%的准确率”,是”0容错的确定性”——读错一次就是一次信任损耗。
所以最终的架构一定是:强模型(内化规律)+ 热更新中间件(注入定义权),两者缺一不可。这不是过渡方案,而是这类问题的本质决定的。
七、一个更大的判断
很多人觉得TTS/ASR是古老的技术,没什么前途。这个判断对了一半。
传统TTS确实是相对成熟的工程问题。但语音在AI系统里的角色正在发生根本性的变化。GPT-4o语音模式、Qwen3-TTS这类端到端语音大模型,不再走”语音→文字→理解→文字→语音”的老路,而是直接在音频层面做理解和生成。专有名词的读音问题,在旧范式里是一个孤立的工程bug。在新范式里,它是一个更大问题的缩影:当语音成为模型理解世界的通道,如何确保这个通道里的信息是准确的?
这个问题还没有人系统回答过。
结尾
写这篇文章的过程本身也值得说一句。
从发现问题,到整理规律,到用AI协作写代码验证方案,整个过程我没有写过一行自己能看懂的代码。但我有一样东西是工程师不一定有的——在实际项目里反复听那些读错的音频,踩出来的一手经验。
AI时代真正改变的不是”人人都能写代码”,而是认知和执行之间的门槛第一次消失了。过去被困在执行层的一线洞察,现在第一次有机会被验证、被传播、产生真实的价值。
这篇文章是一个开始。下一步我会把这套中间件方案整理成开源项目,并尝试接入Qwen3-TTS做进一步验证。结果出来再写第二篇。
本文由 @业务研究员董磊 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


