
 起点课堂会员权益
起点课堂会员权益策略产品经理实践:A/B测试上线流程
编辑导语:策略产品经理实践往往会经历A/B测试上线流程,那么其流程具体是什么样呢?有哪些需要注意的点呢?本文作者来为大家做详细的说明。

本文将介绍大多数公司中A/B测试的上线流程(如图5-1所示),主要分为以下几个环节:
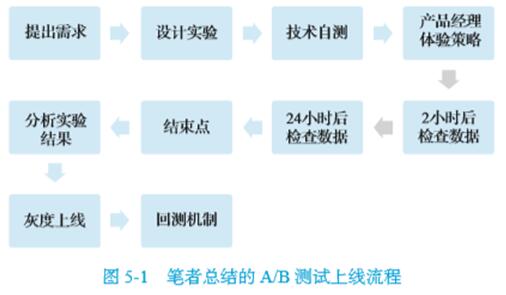
一、提出需求
策略产品经理基于先验判断、数据分析结论或者领导要求,需要上线一个策略实验需求。
二、设计实验
策略产品经理了解相关技术逻辑,设计单变量实验并撰写策略实验文档,包括但不限于实验逻辑描述,如何验证实验假设,以及预期的数据收益。
三、技术工程师自测
算法工程师完成需求,测试工程师介入测试(有时候策略产品经理需要充当测试工程师的角色),添加实验白名单,确保自己的测试账号命中实验。
四、策略产品经理体验策略
策略产品经理在A/B测试上线后通过将自己的测试账号在不同的实验组中切换,反复验证实现逻辑是否完全符合需求文档,并仔细体验两组实验的主观差异(如果拥有中台系统,可以通过后台实现同一用户的内容推荐顺序对比),时间允许的情况下可以写主观评估报告。
五、上线后的检查点1
上线后2小时观察相关数据,主要通过实时数据判断实验开启后是否存在问题,检查以下数据是否正常并记录在文档。如果存在问题,立即检查问题;如果没有问题,在下一个检查点重新确认。
1. 候选集曝光量是否符合预期
如果是涉及内容候选集的实验,需要检查内容候选集曝光是否是0。如果实验没问题,该数值应该是大于0的数字。
2. 服务端请求日志的数据量是否符合预期
策略产品经理一般很难看到该数值,笔者的经验是在实验开启后,找算法工程师一起检查一下服务端请求日志的监控,如果实验正常开启则请求数据量不为0。
笔者遇到多次实验开启但是服务端未生效的问题,可能是上线流程存在问题,如果检查不及时在第二天才发现,会影响项目进度。
如果实验流量比例过高导致性能压力剧增,需要调低流量比例。
3. 实验开启后的过滤策略或排序策略是否生效
如果是过滤策略,需要检查用户推荐日志中实验组需要过滤的内容标签是否存在。
如果是排序策略,需要对用户推荐日志中的前50条结果进行随机抽样分析,检查带有响应标签的内容排序是否更靠前。策略产品经理需要验证上线产品是否符合预期并记录到实验文档中。
六、检查点2
上线24小时后观察数据变化,此时检查的重点是实验是否存在更深层次的实现漏洞。
一般来说,24小时后的数据结果往往和结束点的数据结果趋势相同,此时的检查可以提前发现数据趋势,明确不符合预期的部分(如果有问题,可以提前重新检查一遍实现方式;如果没有,则通过,不用检查)。
如果有时间,建议策略产品经理再次体验实验组和对照组的策略,此次的体验和上次的感受是不同的,因为实验开启时第一次体验实验组策略可能会有新奇感,并且重心在于测试边界用例而非用同理心来理解用户的情绪。
在检查点2重新体验实验组策略,会对用户的情绪理解得更纯粹,不仅消除了新奇感带来的误差,而且可以更加放松地置身于产品中,以普通用户的心态来使用产品,此时最容易获得用户洞察。
七、结束点
在结束点需要终止实验,基于多天累计数据,对相应指标进行数据分析并形成数据报告。
关于结束点的选取,不同类型的产品和不同的观察指标有所不同,具体的选择方式如下:
- 对于日活级产品(DAU/MAU大于50%的产品):普通指标需要观察3个完整天以上(一般为4天),次日留存指标需要观察7个完整天以上(一般为8天),次周留存指标需要观察14个完整天以上(一般为15天)。
- 对于周活级产品(DAU/MAU小于50%的产品):此类产品用户并非每天活跃,并且具有强周期性。普通指标需要观察7个完整天以上,一般为8天,因为需要一个周期内的用户行为对比。次日留存指标需要观察10个完整天以上,一般为15天,因为需要两个周期内,两个分组的用户行为对比。次周留存指标需要14个完整以上,一般为15天,因为需要两个周期内两个分组的用户行为对比。
以上数据为经验数据,主要依据是笔者经历的大多数A/B测试的次日留存指标在第7天趋于稳定,第8天、第9天、第10天和第7天的结果基本一致。
其他指标的结束点时间同理,本质上是因为用户行为数据会逐渐收到固定的值。
结束点时间的选择是“实验精准度”和“项目迭代速度”的折中,如果追求实验精准度,每个实验都可以开启一年之久,但这样的话在紧张的项目迭代周期中效率就会受到影响,大多数公司以单周迭代或者双周迭代的节奏开展工作。
八、分析实验结果
在结束点以后策略产品经理需要分析实验结果,并给出如下的书面分析。
- 分析实验数据的结果是否符合预期,以及可能的原因。一般需要参考原始实验假设,并且结合自己的主观体验报告来尝试回答这个问题。
- 符合预期的实验,下一步优化的点是什么。
- 不符合预期的实验,分析是假设错误还是验证错误,下一步改进点是什么。
九、灰度上线
如果实验取得了统计置信的正向收益,需要对该策略进行灰度发布,但是流程上会因是否需要发布客户端新版本而有所区别。
- 如果需要发版,走版本审核的通用灰度流程,一般需要在小渠道放量,观察产品在不同手机型号下是否存在漏洞。
- 如果不需要发版,关闭原试验,在A/B测试平台将该实验状态调整为“灰度发布状态”(平台需要支持该功能),调整实验组用户的占比,观察天级指标的变化情况。比如第一天放量30%,观察目标指标(比如人均停留时长)在全量用户上的变化。灰度上线的目的是观察A/B测试在全量用户上真正取得的效果,此时虽然不是严格A/B测试验证,但也是十分必要的,下文会介绍为什么正收益的A/B测试全量后效果不如原实验结果明显。
十、回测机制
在KPI考核周期之前一般需要有组织地对有收益的实验进行回测,所谓“回测”,实际上是对历史实验的重新测试。
因为在实验期间有收益不代表一直存在收益(A/B测试存在局限性,可能用户群的征分布发生了改变),所以需要对考核周期内(比如说一个季度内)取得了较大收益的实验重新测试,预期是拿到同样正向的收益(数据幅度可能会有差别,这是正常的)。
实验流程是前人通过不断试错总结出来的宝贵经验,有三个核心收益。
1. 慢即是快
虽然每个实验规范化的文档和对应的检验将会增加大概3小时的时间成本,但对于算法或者策略这样为期数周且持续占用流量的实验来说,是非常必要的。
因为一个错误实现的实验,轻则导致数周时间无效,重则导致重要假设的错误验证。我们认真做好每个实验,会比盲目地大量做浅尝辄止的实验更加高效。
实验迭代速度加快,不是通过减少实验的规范,而是通过自动化流程的建立和效率工具的开发来实现的。
2. 假设驱动
通过系统的假设、实验验证的方式来进行探索,能够持续地增加我们对于业务、模型、数据的认知。
A/B测试的成功率正常是小于20%的(成熟产品A/B测试成功率更是小于10%),但基于假设驱动的实验方法,即使是失败的实验,我们也能从中提取知识,挖掘新的优化点。
另外,建立系统的认知,能够使我们找到持续可迭代的改进方案,而非随机的策略优化。
3. 持续积淀
对于算法策略团队而言,每一个实验即一份学习资料,积累的实验报告对公司内部的其他业务方向、新人培训等将有巨大的学习交流价值。
这本用无数实验数据总结出的“实验教科书”能够放大单个实验的收益,笔者自己便是最好的例子,笔者和同事们共享实验数据库和实验结论,使所有人都能更好地理解内容推荐业务,更好地理解用户行为,实现缩小自我、产品大众、平台共享的价值观。
十一、总结
本文首先介绍了策略产品经理需要了解的Fisher实验设计三原则,策略产品经理在A/B测试相关项目中最重要的事是通过对业务的深刻理解做出合理假设并设计实验(做出合理假设的基础是拥有数据分析能力和用户洞察,并非一定要了解A/B测试的数学原理)。
同时,笔者介绍了不同当下互联网公司对于A/B测试重视程度,有利于部分有跳槽想法的策略产品经理进行科学决策,毕竟每家公司的基因很难改变而个人的机会成本很高,希望大家都能选择适合自己的“产品环境”。
然后介绍了A/B测试的相关分类,并重申了笔者的观点—A/B测试并非是所有公司的标准配置,最后介绍了实际工作中A/B测试上线的相关流程。
这些方法论是笔者多年实践经验所得,根据经验估算可以将A/B测试的失败率从30%~40%降低至5%左右。
在项目推进周期中,常见的情况是某个A/B测试实验开启一周后发现实验方式存在问题,以致于需要修复漏洞甚至推倒重来,而在紧张的项目周期中7天时间十分宝贵。
提升A/B测试实验成功率(实验后数据显著提升)的两个核心秘诀是遵守实验流程和做出有数据依据的用户假设。
作者:韩瞳,文章选自《策略产品经理实践》,2020年7月出版。
未经出版社或作者书面授权,禁止转载,违者追究法律责任
题图来自 Unsplash,基于 CC0 协议










谢谢分享,以前在新媒体运营的书籍上看到过A/B测试,虽然看了作者比较详细的介绍,但还是觉得不会怎么开展工作,毕竟没有实战的机会。对于自动化工具的开发也是很感兴趣的,但是不知道怎样能够实现,编程的话自己又不懂。