
 起点课堂会员权益
起点课堂会员权益如何谨慎地评估一个数据源
对于金融机构而言,流量和风控决定利润,而数据质量是风控核心。为提升风控水平,会引入第三方数据源。本文从线下数据测试与线上模拟测试两个流程,介绍如何谨慎地评估一个数据源,一起来看一下吧。
一、概述:
对于金融机构而言,流量和风控决定利润,而数据质量是风控核心。为提升风控水平,会引入三方数据源,一般都会思考两个方面:数据能否用,数据如何用。本篇文章会从线下数据测试与线上模拟测试两个流程介绍如何谨慎地评估一个数据源。通常情况下:
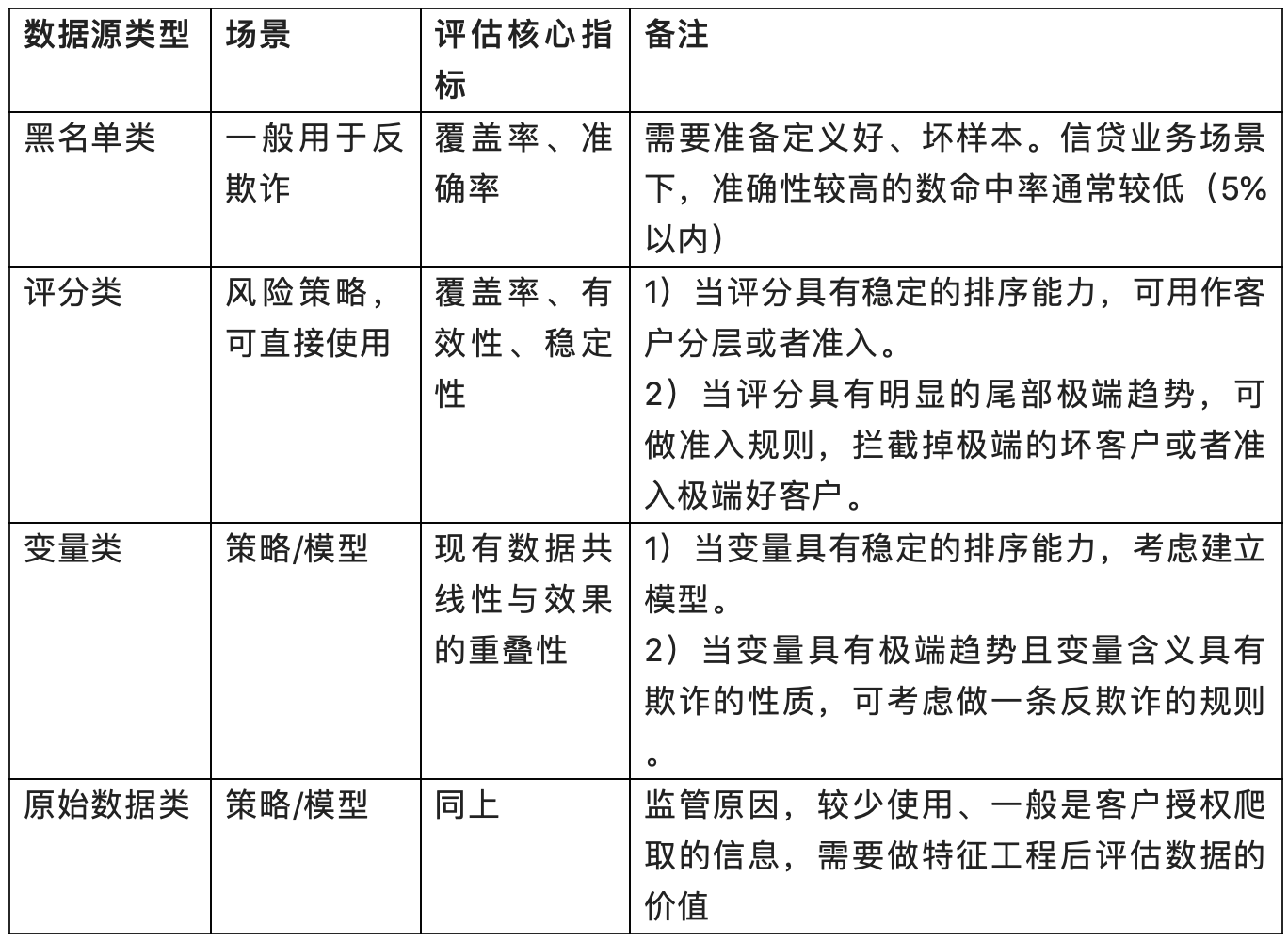
- 优化现有的模型,一般会考虑接入变量类和原始数据类;
- 用来设计策略,一般会接入黑名单类,评分类的数据或者变量类;
- 丰富用户画像的维度,这种数据能反映用户的某些属性,一般考虑原始数据类。
二、常用指标说明
1. 覆盖率
覆盖率是考量数据覆盖程度的指标,又叫查得率。根据业务情况和数据的应用场景,确定数据覆盖程度的需求,覆盖率越高越好。
2. 有效性
分析单变量的KS 、GINI、IV 值、趋势。同时,还要考量数据的可解释性和趋势的稳定性。
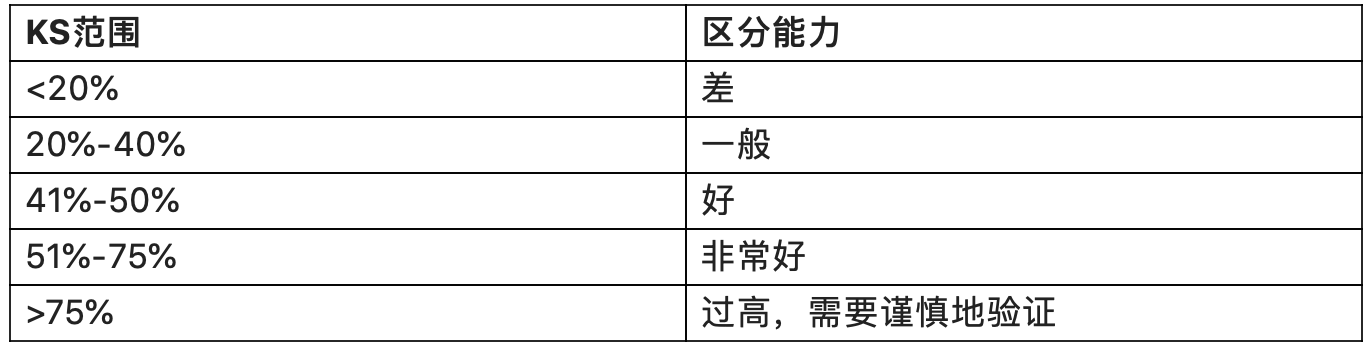
1)KS
用以评估对好、坏客户的判别区分能力,计算累计坏客户与累计好客户百分比的最大差距。KS值范围在0%-100%,评分类的变量,一般要求ks>20%,变量类的数据一般要求ks>10%。
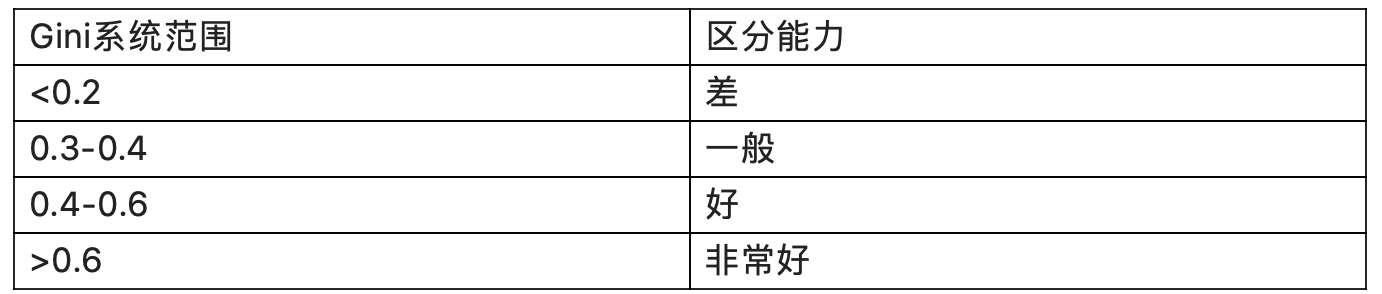
2)GINI系数
也是用于模型风险区分能力进行评估。GINI统计值衡量坏账户数在好账户数上的的累积分布与随机分布曲线之间的面积,好账户与坏账户分布之间的差异越大,GINI指标越高,表明风险区分能力越强。
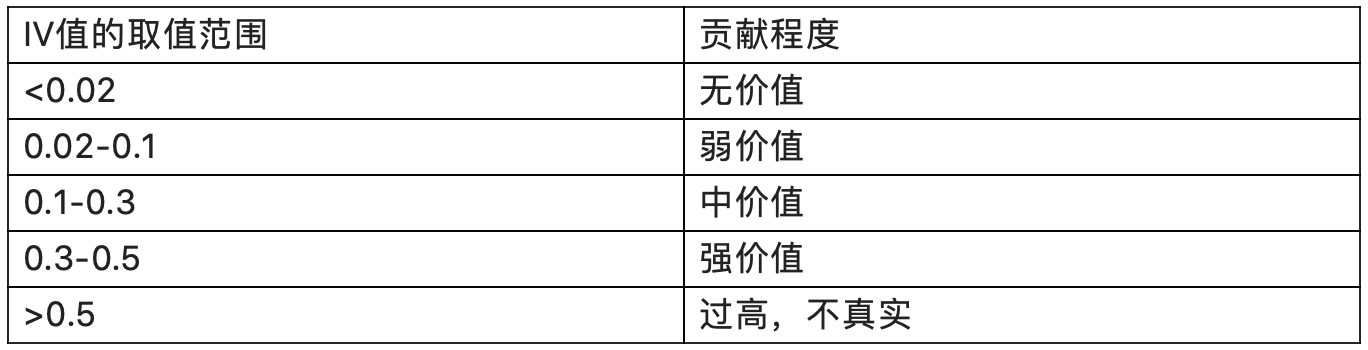
3)IV 值
信息价值,用来表示特征对目标预测的贡献程度,即特征的预测能力,一般来说,IV值越高,该特征的预测能力越强,信息贡献程度越高。
3. 稳定性
无论是评分类还是变量类的数据源,都需要评估稳定性。稳定性的评估是需要参照了,一般使用PSI指标,对比预期分布与实际分布的差异。

当特征变化过于剧烈时,并不是一定确定该数据源/特征不使用,而是要先去了解变化产生的原因。
4. 共线性
共线性又叫做多重共线性,是指自变量之间存在较强的,甚至完全的线性相关关系。当自变量之间存在共线性时,模型的参数会变得极其不稳定,模型的预测能力会下降。
许多第三方的数据衍生逻辑都是笛卡尔积遍历所有组合的可能。因此,在建模前期变量的筛选环节,就需要采取有效措施避免共线性问题。容忍度(Tolerance)、方差膨胀因子(Variance inflation factor, VIF)、特征根(Eigenvalue)、条件指数(Condition Idex)等,都是考察手段。
5. 相关性分析
可以进行相关性分析,分析数据的相关程度。数值特征与数值特征一般用协方差、prarson系数和举例相关系数评估;而类别特征通常用卡方检验、Fisher得分、F检验、斯皮尔曼等级相关、Kendall相关系数来评估。
6. 投入产出评估
在整个评估环节中,最重要的环节,就是将数据联动当前策略,结合三方数据服务的收费模式(常见的计费方式有按调量、按命中量计费计费,如果需求较大,也可以考虑谈判用年/月包)评估这个接口的投入产出,最终评估,这个接口上线后所产生的收益能否覆盖这个接口的支出。
三、离线测试
1. 提供线下测试样本
根据接入目的的不同,测试样本也会稍有差异,比如为了优化现有模型,就最好提供建模时所用的数据样本。但大致上测试样本需满足以下几点:
- 连续一段时间内的样本,可以评估数据的稳定性;
- 最好是近段时间的样本,这样线下评估结果与线上实际效果差距不会太大;
- 其他特殊条件,如覆盖不同的产品和客群。
注:如果不满足连续性、稳定性、代表性这三个条件,测试结果可能是不准确的。
2. 了解数据源情况
一般第三方会提供产品说明,从中需要了解数据的底层逻辑和构成,了解数据背后的业务含义。同时也需要格外注意底层数据来源(中间环节越少越好)、更新频率(越快越好)等信息。评估数据效果可以从策略角度,也可以从模型角度:
- 从策略角度主要是分析单变量的效果,查看是否有强区分度的单变量,可以用于但规则或者组合规则;
- 从模型角度主要是看数据整体效果,如果数据没有较强区分度的单变量,但是整体效果不错且价格低廉,也会被考虑。
3. 通用分析评估
从策略角度主要是分析单变量的效果,查看是否有强区分度的单变量,可以用于规则或者组合规则;从模型角度主要是看数据整体效果,如果数据没有较强区分度的单变量,但是整体效果不错且价格低廉,也会被考虑。
考察维度可以细分为以下7个:查得率、准确率(尤其是黑名单类)、稳定性(服务稳定性、特征稳定性psi)、模型效果(IV、KS)、性价比(按查询次数、按命中次数、包月/年)、可解释性(特征变量类是否具有业务含义、评分区间可解释性)。
4. 特定数据源类别评估
四、线上模拟
虽然在历史样本上进行了完整的效果评估,已经证明将要上线的数据、模型、策略是有价值的。但市场环境和客群是一个动态变化的过程,况且历史的数据都是在线下回溯的,线上数据与线下回溯数据是否有差异,是否会有操作失误,都未可知。模拟线上测试就是要评估数据在真实应用时的效果。
模拟线上测试是将新策略在实际业务环境中运行,记录相关结果,但并不做决策。
分析数据在线上环境的调取成功率。对比线上线下的数据分布、覆盖率、策略设计的通过率是否一致。但费用受限,一般测试都是小样本,从数据源评估的角度,新的模型/策略上线后,需要有完善的监控体系,监控整个数据的变化情况,方便快速地发现异常。
例如:接口的调用情况、数据的稳定性、数据缺失率、各个环节策略的转化率、贷后逾期情况等,线上观察实际上线效果,包括但不限于:
- 数据接口稳定性(接口调用是否正常、可靠)
- 特征变量数据分布稳定性、缺失率、准确率等
- 业务效果:如进件通过率(坏账率需要一段时间,表现期较长)
五、小案例-黑名单评估
1. 评估指标
()查得率(Search rate)=查得数/样本量
(2)覆盖率(Cover rate)=查得命中黑名单数/样本中命中黑名单量
(3)误拒率(Error reject rate)=查得命中黑名单数/样本中通过且为Good量
(4)有效差异率(Effective difference rate)=查得命中黑名单数/样本中通过且Bad量
(5)无效差异率(Invalid difference rate)=查得命中黑名单数/样本中其他拒绝量
其中SR、CR、EDR指标越高越好,ERR越低越好,IDR与EDR结合起来观察,如果IDR和EDR都较高,反映的一种情况是数据源定义黑名单是广撒网式,黑名单质量相对不够精准。其中前三个指标是重点考察,如果想更全面的测试第三方数据源,后面两个差异率指标也可以加入考核标准。数据统计:

2. 样本测试命中情况

3. 评价指标统计
按照上文介绍的指标分析方法,对比数据源和数据源2的测试结果可以得出如下结论:
- 在查得率、覆盖率两个正向指标上,数据源均比数据源2有明显优势;
- 误拒率这个负向指标上,数据源却比数据源2低;
- 将无效差异率(IDR)与有效差异率(EDR)结合起来观察,数据源2的两者都较高,可能是广撒网式,不够精准。
最终分析结论:数据源2比较好。
作者:王小宾;微信公众号:一起侃产品
本文由@并不跳步交叉步 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


