
 起点课堂会员权益
起点课堂会员权益策略产品必知系列之一文详解“特征工程”
本篇文章作者分享策略产品在特征工程上需要了解的原则和工作方法。特征工程在推荐系统中至关重要,需要遵循几个基本原则:包括正确理解问题背景和业务需求、理解数据和特征的含义、保证数据的稳定性和完整性等。希望通过本篇文章能对你有所帮助。

从策略产品的角度来审视特征工程,在算法工程师 & 策略产品届有一句话叫做“Garbage in garbage out (垃圾进,垃圾出)”。这句话深刻的解释了特征与数据对于深度学习模型的重要性。机器学习模型的能力边界就在于对数据的拟合和泛化,那么数据及其表达数据的特征就决定了起学习模型效果的上限。
数据与特征工程决定了模型的上限,改进算法只不过是逼近这个上限而已。
今天Arthur就给大家介绍一下关于推荐系统的特征工程,帮助大家从全貌了解策略产品在特征工程需要捻熟于心的关键原则和工作方法。
本文分为上下两篇,上篇主要提纲挈领的介绍特征工程的定义原则、重要特征类型以及常用的特征处理方法;下篇会着重的讲解策略产品实用的特征数据处理的工作内容。
具体分为以下几点讲述:
- 什么是特征工程、特征工程的基本工作原则。
- 有哪些常用的特征类别。
- 常见的特征数据类型与处理办法。
- 特征的选择。
一、什么是特征工程、构建特征工程的基本原则是什么
特征工程(feature engineering)定义:特征的本质其实就是对某个行为过程相关信息的抽象表达。
推荐过程某个行为必须转化成某种数字形式才能被机器学习模型学习。所以为了完成这种转化,就必须把这种行为过程的信息以特征形式抽取出来,用多个维度上的特征表达这一行为。
存在的问题:从具体行为转化成抽象的特征,过程必然会造成信息损失。这个过程中具体有两个问题:
- 因为具体的推荐行为和场景包含大量原始的场景、图片和状态信息,保存所有的信息存储空间过大,现实中无法满足。
- 具体的推荐场景也包含大量荣誉无用的信息,都考虑进来会损害模型的泛化能力。
特征工程构建基本原则:基于以上存在的问题,在特征工程构建中的基本原则为:尽可能让特征工程抽取的一组特征能够保留推荐环境以及用户行为过程中的有用信息,尽量摒弃冗余信息。
举个垂直场景推荐系统中具象化的例子便于大家理解,在推荐系统中对于书本推荐有哪些重要的因素呢?
Arthur枚举了一下几种类型:
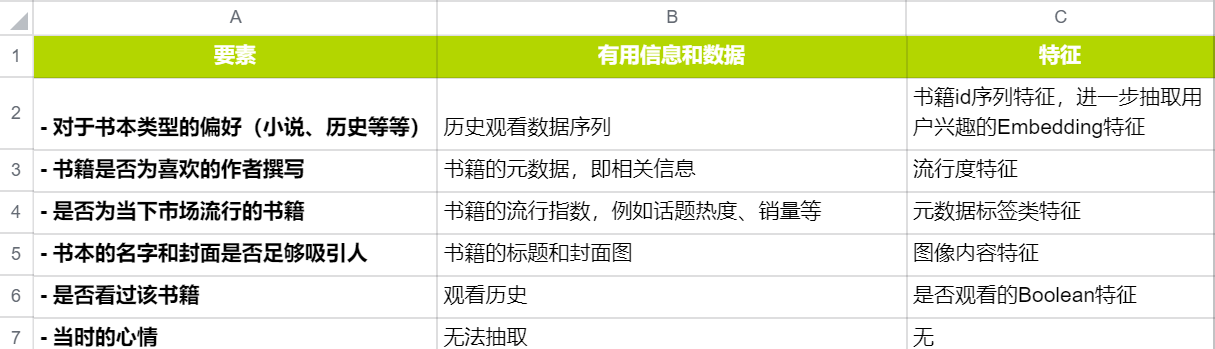
推荐系统当中对于书本推荐的重要艺术
可以从上图中看出,在抽取特征过程当中,必然存在信息的损失。例如“当时的心情”就从要素中被舍弃了;再比如,用户观看历史推断用户偏好也会存在一定的信息丢失情况。
因此,在已有的、可获取的数据基础上,“尽量”保留有用信息是是实现特征工程的原则。
二、推荐系统常用的特征类别
推荐系统会使用到各个维度的特征信息。而不同的特征信息对于不同的推荐系统所带来的增益效果大不相同,并且不同的业务抽取特征的时候权重也大相径庭。
例如电商系统更加关注用户的属性特征、用户点击、加购商品类型,其中加购相对来说对于最终成交比点击行为权重更大。而新闻推荐更加关注用户关注的新闻类别,所在LBS的地域信息等等。
因此我将推荐系统的常用特征进行枚举,提供大家在构建特征工程时候的选择,该部分与之前介绍的定向类型有点相似。
1. 用户行为数据类型
用户行为数据是推荐系统最常用、也是最为关键的数据,因为用户的潜在兴趣、用户对物品的真实评价都包含在用户的行为历史当中。
一般用户行为特征包含显性反馈行为(explicit feedback)和隐性反馈行为(implicit feedback)。在不同业务场景中,用不同方式体现。

各业务场景中的显性和隐性反馈行为
当前推荐系统的发展中,隐性反馈行为越来越重要,主要原因是显性反馈的收集难度更大,数据量也比较小。在深度学习模型对于数据要求越来越大的背景下,如果只是用线性反馈的数据不足以支持推荐系统训练过程中直到收敛。
所以,能够反映用户行为特点的隐性反馈行为是目前特征挖掘的重点。
2. 用户关系数据类型
互联网本质上是人和人、人和信息之间的链接。“物以类聚,人以群分”其实就是用户关系数据最好的体现,同时也是推荐系统利用的有价值信息。
用户关系类型分为“显性”和“隐性”,又可以称之为“强关系”与“弱关系”。
- 强关系类型:用户可以通过用户之间的“关注”、“好友关系”,以及“通讯录授权”建立“强关系”联系。
- 弱关系类型:通过“相互点赞”、“同处在一个社区”,甚至是“同看一部电影”来建立“弱关系”的联系。
3. 属性、标签数据类型
属性、标签数据类型本质上都是直接描述用户或者物品客观特征。标签和属性的主体可以是用户,也可以是物品,他们的来源非常多样化。
大体上分为以下几类:
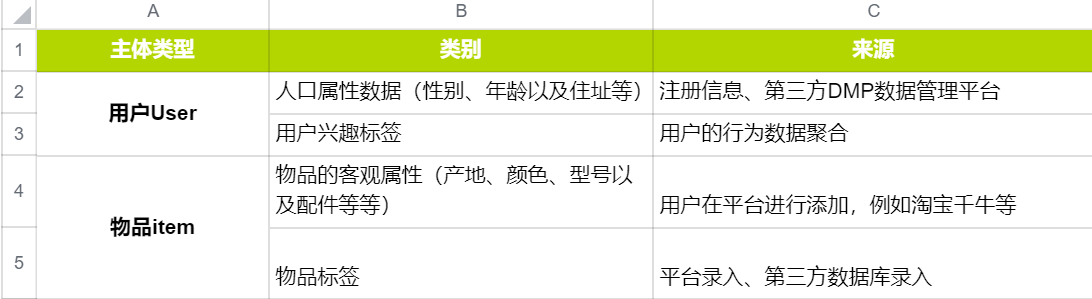
用户属性、物品属性以及标签数据是属于最重要的描述型数据。
成熟的公司会建立一套用户和物品的标签体系,有专门的团队维护。典型的例子就是电商公司的商品分类体系,同样这一套分类也会用于搜索召回策略中的实体识别当中。
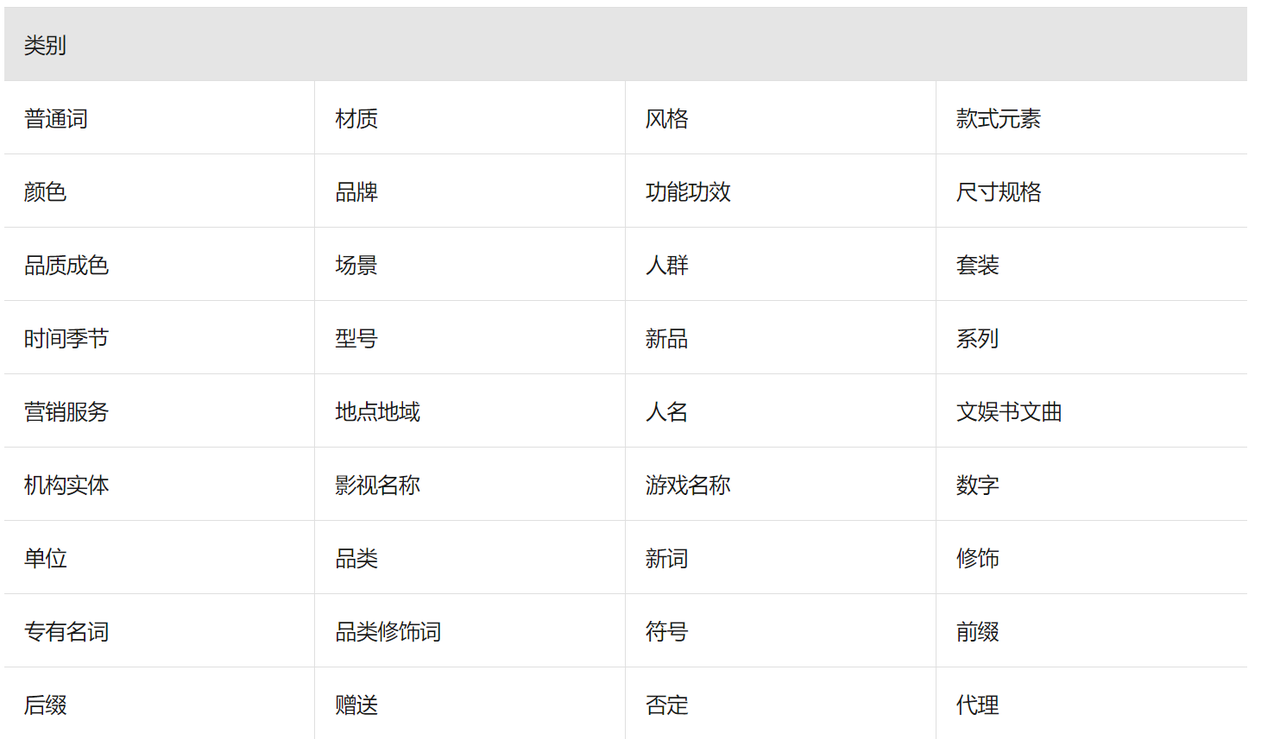
阿里云中关于query词的分类
在推荐系统当中使用属性、标签类数据,一般都是通过multi-hot编码方式转化成特征向量。一些重要的属性标签类特征也可以先转化成Embedding,再输入推荐模型。
4. 内容类数据
内容类型的数据可以看做是标签类型的衍生,同样也是描述用户和物品的数据。但是相比较标签数据,内容类型的数据往往都是大段的描述型文字、图片,甚至是视频。
一般来说,内容类数据无法直接转化成推荐系统可以“消化”的特征,需要通过自然语言处理、计算机视觉等手段提取关键的内容特征,再输入到推荐系统。

实体识别
例如,在图片类、食品类或者带有图片的信息流场景中,往往会使用计算机视觉模型进行目标检测,抽取图片特征,再把特征转化为标签类数据提供给推荐系统。
5. 上下文Context信息数据
上下文信息表示的是描述推荐行为产生的场景信息。最常用的就是利用“时间”和通过GPS获取到的“地点”信息。
根据推荐场景的不同,上下文信息的范围非常的广,包括地点、季节、时间、是否节假日、天气湿度、社会大事件等等。
引入上下文信息的目的是尽可能保证推荐行为发生推荐场景的实时性。
典型的例子是:在美团外卖APP场景中、临近中午12-2点会推荐用户爱吃的外卖食物,到了下午3-5点,可能用户吃过饭了那么就会更加倾向于甜点、下午茶(奶茶、饮料等)。
如果不引用上下文特征,则推荐系统无法捕捉到这些有价值的实时信息。
6. 组合类特征
组合类特征指代将不同的特征类型进行组合后的得到的新特征。最常见的就是“年龄+性别”组成人口属性分段特征(segment)。
在早期的推荐系统当中,推荐模型(比如说逻辑回归LR)是不具备特征组合的能力。
随着神对学习推荐系统的提出,组合类特征不一定通过人工组合、人工筛选的方法选出,还可以交给模型自行处理。
例如GBDT+LR的形式就是讲特征工程模型化来处理。
三、常见的特征数据类型与特征处理方法
对于推荐系统来说,模型的输入往往是数字组成的特征向量。有“年龄”、“播放时长”、“历史点击率CTR”这些可以由数字表达的特征,可以自然成为特征向量中的维度。
更多的特征来说,像是用户的性别、观看历史也需要转化成为数字特征向量。
因此需要从连续型特征和类别型特征两个角度来介绍特征处理方法。
1. 连续型特征
连续型特征的典型例子就是用户年龄、播放时长以及物品发布时间等统计类型特征。
对于这一类特征的处理,最常见的就是归一化、离散化、加非线性函数等手段。
1)归一化
统一各个特征的量纲,将连续值特征归一到[0,1]之间。也可以做0均值的归一化,即将原始数据归一化为均值为0、方差为1的数据集。
- 解决方案:将所有的数据映射到同一个尺度当中。
- 最值归一化:把所有的数据映射到0-1之间。

2)离散化
通过分位数的形式将原来的连续值进行分桶,最终形成离散值的过程。
离散化的主要目的是放置连续纸带来的过拟合现象以及特征值分布不均匀情况。
经过离散化处理的连续型特征和经过One-hot处理的类别型特征一样,都是以特征向量的形式输入特征模型当中的。
3)加非线性函数
加非线性函数的处理方法,就是直接把原来的特征通过非线性函数做变换,然后把原来的特征和变换后的特征一起加入模型进行训练的过程。
加入非线性函数的目的为了更好的捕获特征与优化目标之间的非线性关系。
常用的非线性函数包括以下几类:

2. 类别型特征
类别型特征典型的例子:用户历史行为数据、属性标签类数据等。其原始表现为一个类别或者一个id。
这类特征最常用的方法就是使用one-hot编码将其转化成为一个数值向量,在one-hot编码基础上,面对同一个特征域或者非唯一类别选择,还可以采用multi-hot编码。
历史行为序列类、标签特征类数据来说,用户往往会与多个物品产生交互行为,或者被打上多个同类别标签,这是最常用的特征向量生成方式就是转化为multi-hot编码。
举个例子,带上网站共有1000个商品,用户购买了其中10种,那么用户的历史行为就编程1000维的数值向量。其中仅有10个商品数值是1,其余的都是0,这就是multi-hot编码。
对类别进行One-hot编码或者是multi-hot编码主要的问题就是特征向量的维度过大,特征过于稀疏的问题,这容易导致模型欠拟合,模型的权重参数的数量过多,导致模型收敛也会很慢。
所以在Embedding技术成熟之后,被广泛应用在类别特征的处理之上。现将类别特征编码成稠密Embedding向量,再和其他的特征组合,最终形成输入特征向量。
四、特征选择
特征选择是指为了构建模型而选择相关特征子集的过程。特征选择的目的有三个:
- 简化模型。使模型更易于研究人员和用户的理解。 可解释性不仅让我们对模型效果的稳定性有更多的把握,而且也能为业务运营等工作提供指引和决策支持。
- 改善性能。特征选择的另一个作用就是节省存储和计算QPS耗时开销。
- 改善通用性。降低过拟合风险。 特征的增多会大大地增加模型的搜索空间,大多数模型所需要的训练样本数目随着特征数量的增加而显著增加,特征的增加虽然会更好的拟合训练数据,但也可能增加方差。
特征选择一般包括生产过程、评价函数、停止准则、验证过程。
为了进行特征选择,我们首先需要产生特征或特征子集候选集合;其次需要衡量特征或特征子集的重要性或者好坏程度。
因此需要量化特征变量和目标变量之间的联系以及特征之间的相互联系。
为了避免过拟合,我们一般采用交叉验证的方式来评估特征的好坏;为了减少计算复杂度,我们还需要设定一个阈值,当评价函数到达阈值后搜索停止;最后,我们需要在验证数据集上验证选出来的特征子集的有效性。
本文由 @策略产品Arthur 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。








关注主页了解更多策略产品知识