
 起点课堂会员权益
起点课堂会员权益策略产品经理必读系列—第一讲机器学习
导读:作为一个策略产品必须要对机器学习有一定了解,熟悉机器学习建模的全流程。本篇文章将详细地为产品&运营方向的童鞋通俗易懂地介绍什么是机器学习。

一、 什么是Machine Learning
机器学习,简单来说就是从历史数据中学习规律,然后将规律应用到未来中。国内大家一致推荐的,南京大学周志华教授的机器学习教材西瓜书里面如此介绍机器学习。
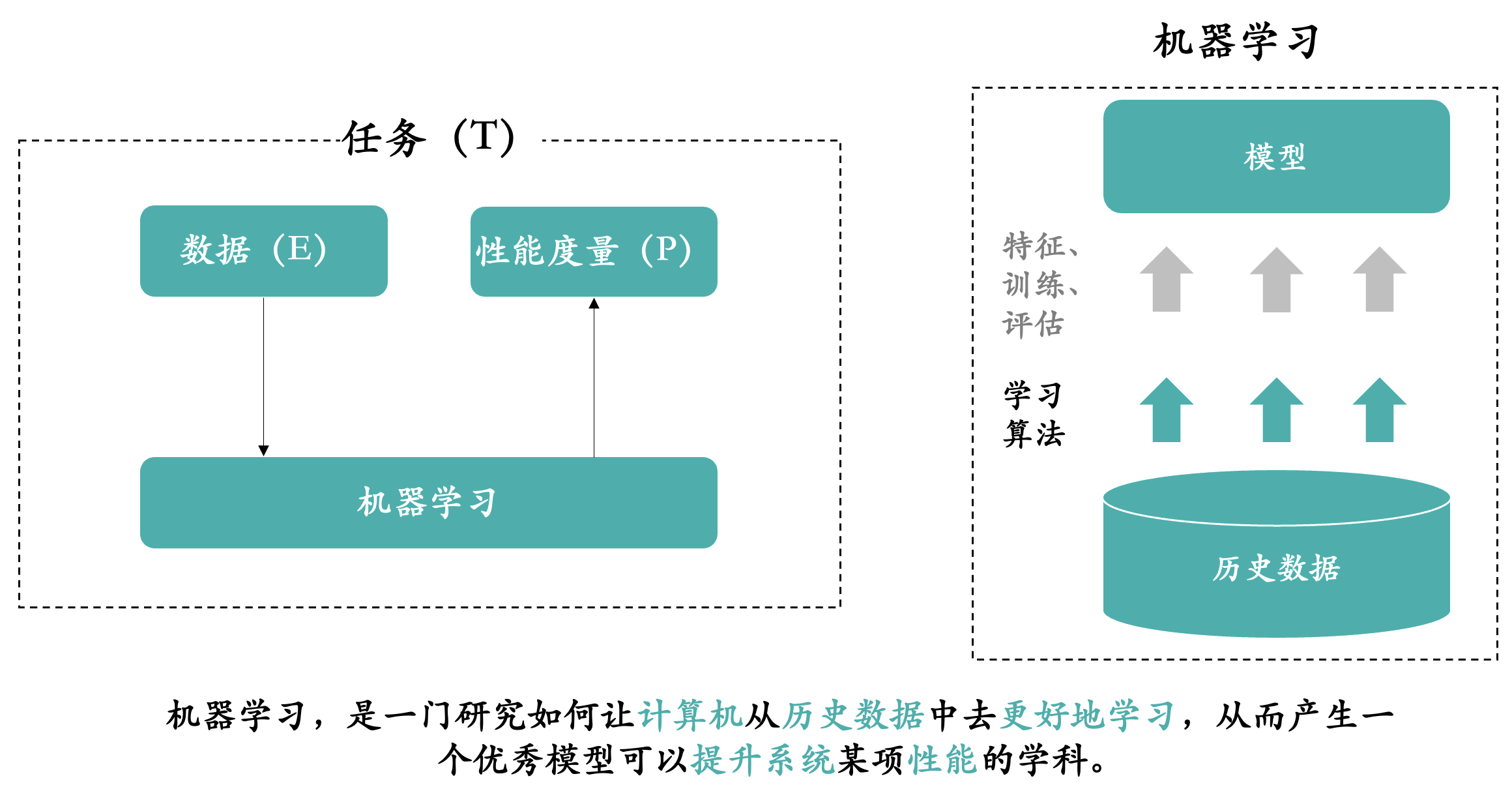
机器学习是机器从历史数据中学习规律,来提升系统的某个性能度量。
机器学习,是一个非常宽泛的概念,它是一门学科。你可以理解为和数学、物理一样的学科。
简单点讲:
大家从小到大都学习过数学,刷过大量的题库。老师和我们强调什么?要学会去总结,从之前做过的题目中,总结经验和方法。总结的经验和方法,可以理解为就是机器学习产出的模型,然后我们再做数学题利用之前总结的经验和方法就可以考更高的分。有些人总结完可以考很高的分,说明他总结的经验和方法是对的,他产出的的模型是一个好模型。
复杂点讲:
比如说金融领域,利用机器学习来构建一个反欺诈模型。银行做金融贷款业务时,很多客户是欺诈客户,专门来骗取贷款的。根据历史上还款的好客户和首次即逾期的欺诈客户的数据,去找出“好客户”的特征和“欺诈客户”的特征,然后利用机器学习构建一个模型来区分出客户的欺诈度。模型的好坏决定了识别客户欺诈的能力。
学术界:

上图是周志华教授的西瓜书里面对于机器学习的解释,机器学习是研究“学习算法”的学问。
工业界:
但实际上到了工业界,很多时候问题并不是如何研究“学习算法”,而变成如何应用了,算法很多时候都是现成的,关于这个问题的算法人们早研究透了。但就和物理一样,牛顿一二三定理加上各种公式都给你了,你还是不会解题。一个是理论物理和一个是应用物理。
当你有了学习算法,你在工业界实际应用的时候,你还得做特征工程,做训练和评估等等。最后才能产生一个效果不错的模型。而在工业界很多应用机器学习的场景下,实际上后者的重要性大于前者(此部分后面会专门介绍)。
总结来说:机器学习,是一门研究如何让计算机从历史数据中去更好地学习,从而产生一个优秀模型可以提升系统某项性能的学科。但实际应用远远不是研究算法这么简单。
1.1 机器学习名称的由来
专门提一下机器学习为什么叫机器学习。
机器学习这些年在国内很火,其实机器学习在国际上研究很久了,1952年一位IBM的工程师Arthur Samuel研发了一个西洋跳棋程序,然后一些知名的棋手都输给了这个程序,有点像上个世纪50年代的阿法狗。后来1956年,这位工程师受邀,在达沃斯会议上介绍自己的这项研究,第一次提出了“Machine Learning”这个词汇, Arthur Samuel也因为被称为“机器学习之父”,他将“Machine Learning”定义为“不需要确定性编程就可以赋予机器某项技能的研究领域“,让机器像人一样学习起来。
1.2 机器学习与AI、深度学习、强化学习的关系

这是硅谷的一位工程师的调侃:AI和机器学习的区别。AI基本上都是PPT,而机器学习是真材实料用Python写出来的。这虽然是调侃,但却是当前人工智能发展的现状。所有人都在吹嘘AI,自己的AI多么牛逼,但都是仅限于PPT层面,等到落地的时候就没有那么神话了,很多时候都是打着AI的噱头。
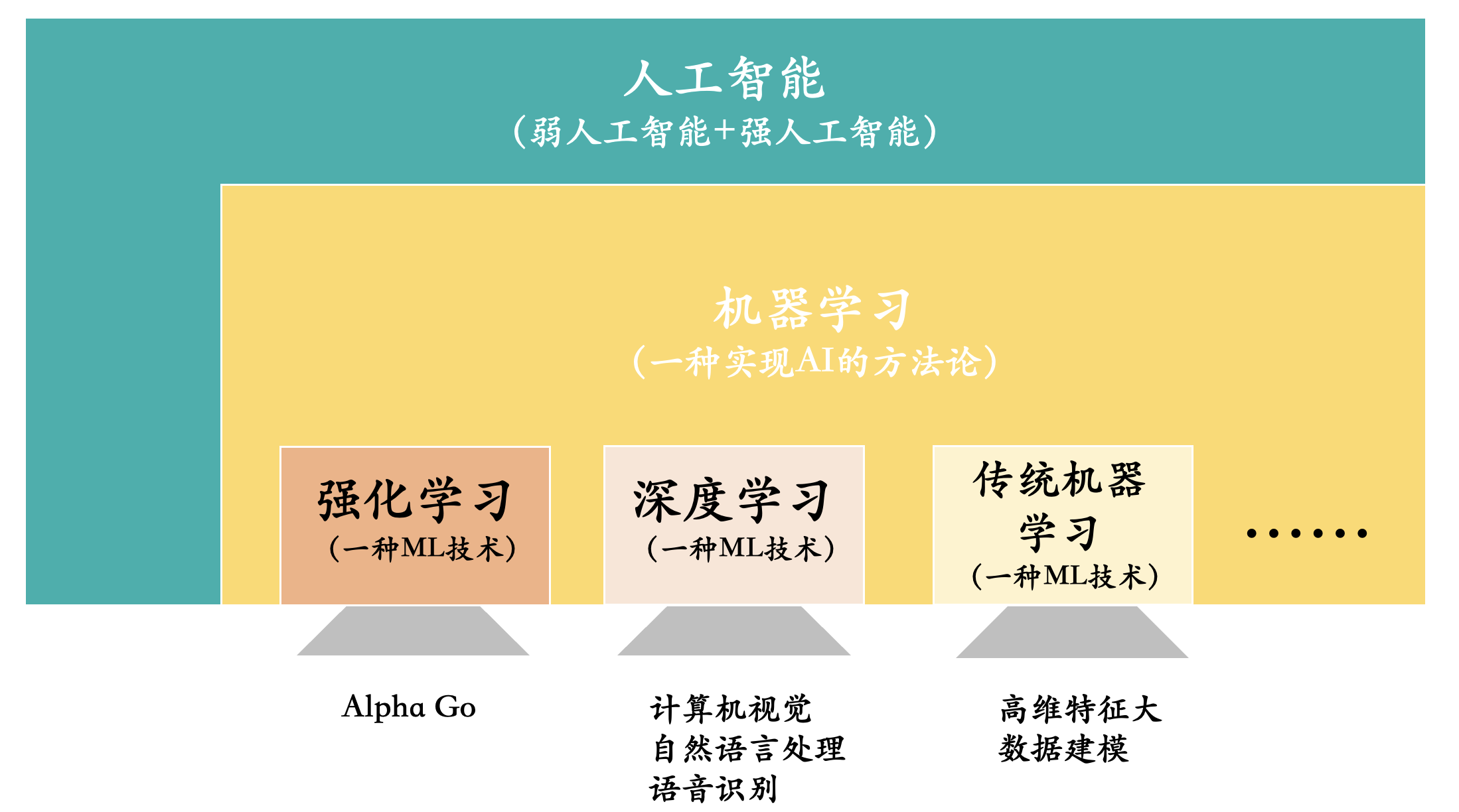
用上图清晰地给大家介绍彼此之间的关系:人工智能包含机器学习,机器学习又包含强化学习和深度学习等。目前人类所研究的AI还是弱人工智能,电影里面看到的那种机器完全和人类一样去思考、行动的智能还远远达不到。然后强化学习和深度学习都是机器学习里面的两个子技术,两个不同研究领域。可以通俗地理解为物理学里面的力学和电学。
那物理学除了电和力,还有光学、磁场等等。所以机器学习技术中还有很大一部分是“高维特征大数据建模”。其实现在我们在工业界专门提“机器学习”技术,更多地指的是我所列出来的第三部分“高维特征大数据建模”。前两者我们不会说机器学习技术,而是直接说强化学习和深度学习。
1.3 机器学习构建模型泛化的步骤
下面主要讲述高维特征大数据建模的一些泛化步骤。
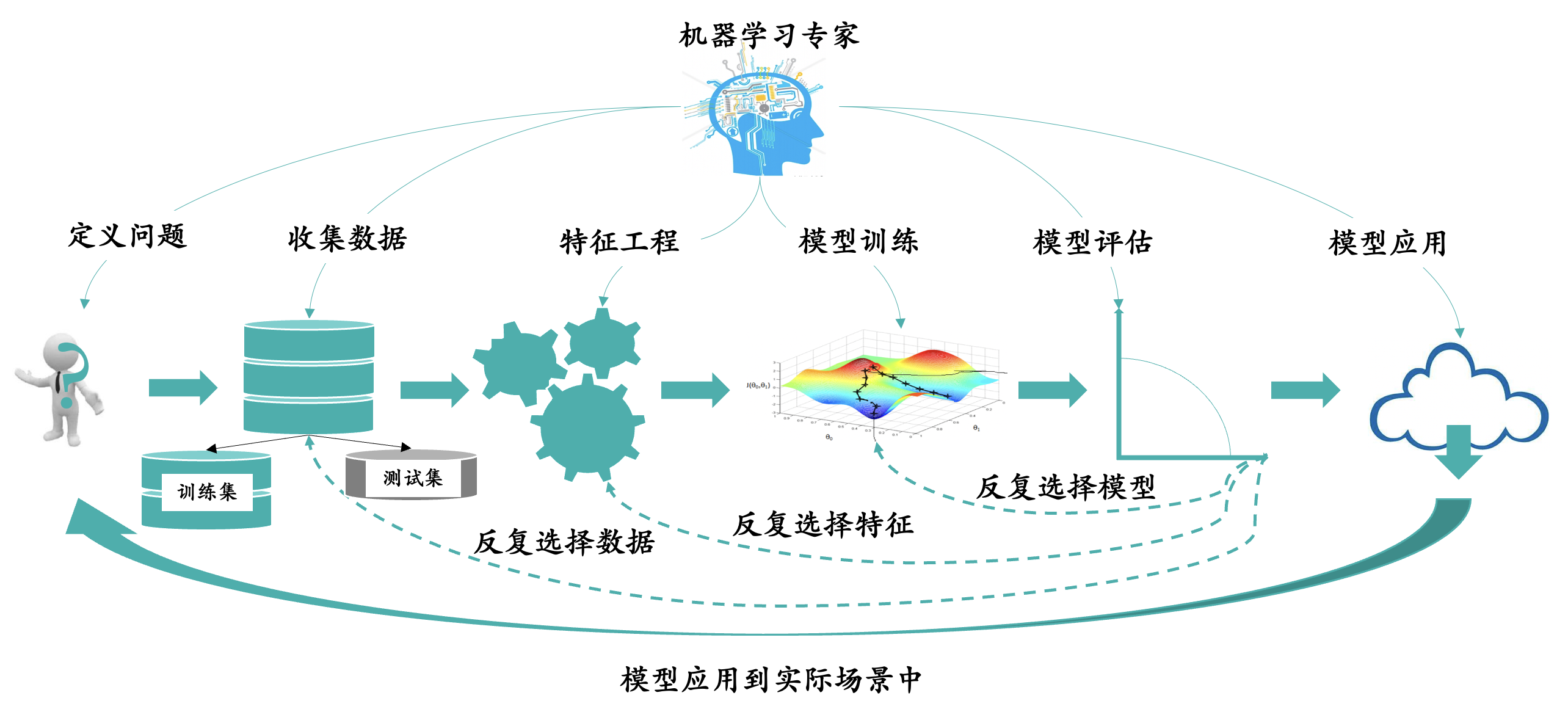
以下是正常一位数据科学家进行建模的步骤:
步骤一定义问题:
首先客户的问题是什么?客户想利用机器学习构建模型来满足什么需求?比如在金融反欺诈领域,银行的需求就是能不能构建一个模型,来区分出欺诈客户和正常客户。有了这个模型,就可以尽可能地降低银行的信贷逾期风险。再比如在零售领域,电商APP的需求是在推荐栏目为用户主动推荐一些商品,提高用户对于该页面商品的点击率、加购率以及下单率。
定义问题决定了两件事情,第一件事情是决定了数据科学家要用什么算法来构建模型;反欺诈场景下基本用的都是GBDT算法,而推荐场景下基本用的都是协同过滤算法。这些算法本身都已经很成熟了,在这些场景下也得到了大量的应用和验证。这就和物理中力学场景下离不开牛顿三大定律一样,定律本身已经成熟了,就看你怎么用。很多时候人们吐槽数据科学家是调包侠就是因为这些算法是有现成的包的,科学家们只需要在程序里面调用一下就行了,当然实际工作要比这复杂的多。
第二件事情是决定了数据科学家如何来评估模型的好坏。模型没有对错之分,只存在效果的好坏之分。那在反欺诈场景下,哪个模型能够将正常客户和欺诈客户分类的最准确,哪个模型的效果就好。而在推荐场景下,那么就是同时对模型进行一段时间的观察,哪个模型为用户推荐的商品,用户的点击率下单率更高,哪个模型的效果更好。
步骤二收集数据:
定义完问题后,我们需要收集数据,数据质量的好坏,对模型效果的影响非常大。根据场景下,我们需要使用的数据不一样。比如反欺诈场景下,我们需要使用到用户的基本信息、历史还款信息等,这里面包含正常用户和欺诈用户的,二者的信息都需要。正常情况下,用户的数据都会分布在数据库不同的表里面,为了建模的方便,通常我们都是合并成一张大宽表。
数据清洗:很多时候历史数据比较乱,有很多脏数据,比如说某条记录是测试人员当时测试时候的数据,并不是真实数据,那这种数据我们就要剔除掉。还有就是数据缺失,很可能某些记录的某些字段内容缺失,这时候就需要看能不能补充。还有很多时候数据字段意义不统一,比如说在某个时间点前,数据库里面性别是男女,而这个时间点后性别变成了AB,A代表男,B代表女,这时需要把字段意义统一。数据清洗很多时候占据着数据科学家们大量时间。
数据标注:清洗完数据后,有的时候我们甚至还需要进行数据标注。比如在反欺诈场景下,大宽表里面一条客户的记录,到底是正常用户还是欺诈用户,有的时候数据库里面没有对这些数据进行分类,我们还需要人工地去判断这条记录应该属于哪个label的客户。
数据抽样:数据抽样一般是因为历史数据太多了,而且有的历史数据太久远不具有参考意义。所以我们一般都是选择近期的用户数据。如果数据还是太多,导致训练时间太长,我们就会采用随机抽样的方法,再从近期的用户数据中,随机抽取XX%的数据出来。
数据切分:就是将我们抽样出来的数据分为训练集和测试集,我们在训练集上进行训练,测试集上面测试我们模型的效果。必须要区分开训练集和测试集,不可能一个数据集既作为训练集又作为测试集。就相当于,你准备考试的模拟试卷你拿来练习,结果考试的试卷就是模拟试卷,那没办法反映出你真实的水平。一般我们训练和测试集的比例是9:1。但实际工作中这个比例也不是固定的。
数据穿越:数据穿越是科学家建模在挑选数据的过程中常见的一个问题。比如说现在这个时间点2020.2.23日我们需要构建一个反欺诈模型,来判断2019.2.1日开始的用户是正常用户还是欺诈用户。那么我们只能使用2019.2.1日之前的历史用户数据来进行训练,而不能使用截止到2020.2.23日的用户数据,因为此时此刻我们已经知道了绝大部分2019.2.1日的用户是正常用户还是欺诈用户,用截止到此时此刻的数据来训练模型就相当于作弊,训练出来的模型效果很好也不具备参考价值。很多情况下数据科学家还会遇到一个问题就是没有历史数据。是的,这种情况也经常有。没有积累历史数据,或者历史数据太少几乎等于没有,那么怎么办?这个时候就直接照搬同样场景下另外一个项目的模型直接用,这种我们叫做“冷启动”。因为相同场景下,模型大同小异,可以直接先用着历史其他项目的模型。然后再积累一段时间的数据后,再根据该场景下的积累的历史数据对模型进行调优。
步骤三特征工程:
特征工程是工业界建模中最最最重要的一个模块。模型效果的好坏,一部分是由数据质量决定的,另一部分是由特征工程决定的。
什么是特征工程?我们如何评估一个用户是否是欺诈用户还是正常用户,那么我们就需要找到这二者在哪些特征上表现存在明显差异,通过这些特征来进行区分。寻找特征来有效的区分不同label的样本,这个就是特征工程。
反欺诈场景下,用户的历史还款行为就是一个有效的特征来判断该用户是否是欺诈用户。如果用户历史经常逾期,那么用户欺诈的可能性就大,用户历史都正常还款,欺诈的可能性就低。除了该特征,用户所在的地域、年龄、是否已婚、经济情况、受教育成都、职业等等都是有效特征。数据科学家们在建模中都会加入这些特征。
很多时候数据科学家还要去请教业务专家,和业务专家调研他们在做实际业务中,发现不同label的用户在哪些特征上表现差异化比较明显。业务专家懂业务,有很多经验规则是数据上面看不出来的,就需要业务专家的输入。业务专家的输入,可以让科学家们锁定到一些有效的特征上,而舍弃一些无效的特征,对建模过程起到一定的指导作用,提高了效率。
同时数据科学家们还会构建一些组合特征,将很多特征组合在一起构成一个新的特征。一方面是因为历史数据特征本身可能不多,另一方面是单独某两个特征判断不了什么但当结合在一起成为一个新的特征时有时却可以反映出一些有价值的信息。
所以为了构建一个高维特征的模型,实际建模中科学家们会将很多特征组合在一起构造一些原本历史数据中没有的特征。就像我们只通过两三个特征去评估一个人好坏,是很难评估的,容易片面。当我们通过成百上千个特征去评估时就比较客观。特征工程很多时候科学家们会做很多组不同的特征工程,因为有时候科学家们也无法判断哪一组更好,就多几种可能性,放到模型训练中去训练。
步骤四模型训练:
构建完特征工程后,科学家们开始要生成初版的模型,模型的表现形式是一个函数。假设在反欺诈场景下,函数为z=ax+by+c这么一个函数,x和y是特征,a、b、c就是参数,z是结果。当z大于0时,用户为正常用户,z小于等于0时,用户为欺诈用户。(为了方便大家理解,这边举了一个比较简单的函数。实际反欺诈场景下,我们使用的是逻辑回归函数)
那么模型训练什么?模型训练就是训练参数。最开始的时候我们会对a、b、c设置一个初始值,假设都设置为1。接下来我们就需要通过步骤二里面的训练数据来训练模型,不停地调整我们的参数。训练的过程可以理解为就是不停地尝试各种参数组合,使得每条用户记录评估出来的z的值和用户真实z的值接近。当然尝试是有技巧性的尝试,而不是穷举,模型训练的方式有梯度下降法等等,在此不详细叙述。实际工作中每一次模型训练的时间,短的以天为单位,长的甚至可能以周为单位。对的不夸张,正常情况下每一次模型训练的时间都要很长,计算机要不停地高速运转去计算。
实际模型训练当中经常出现的一个问题叫做过拟合Overfitted。
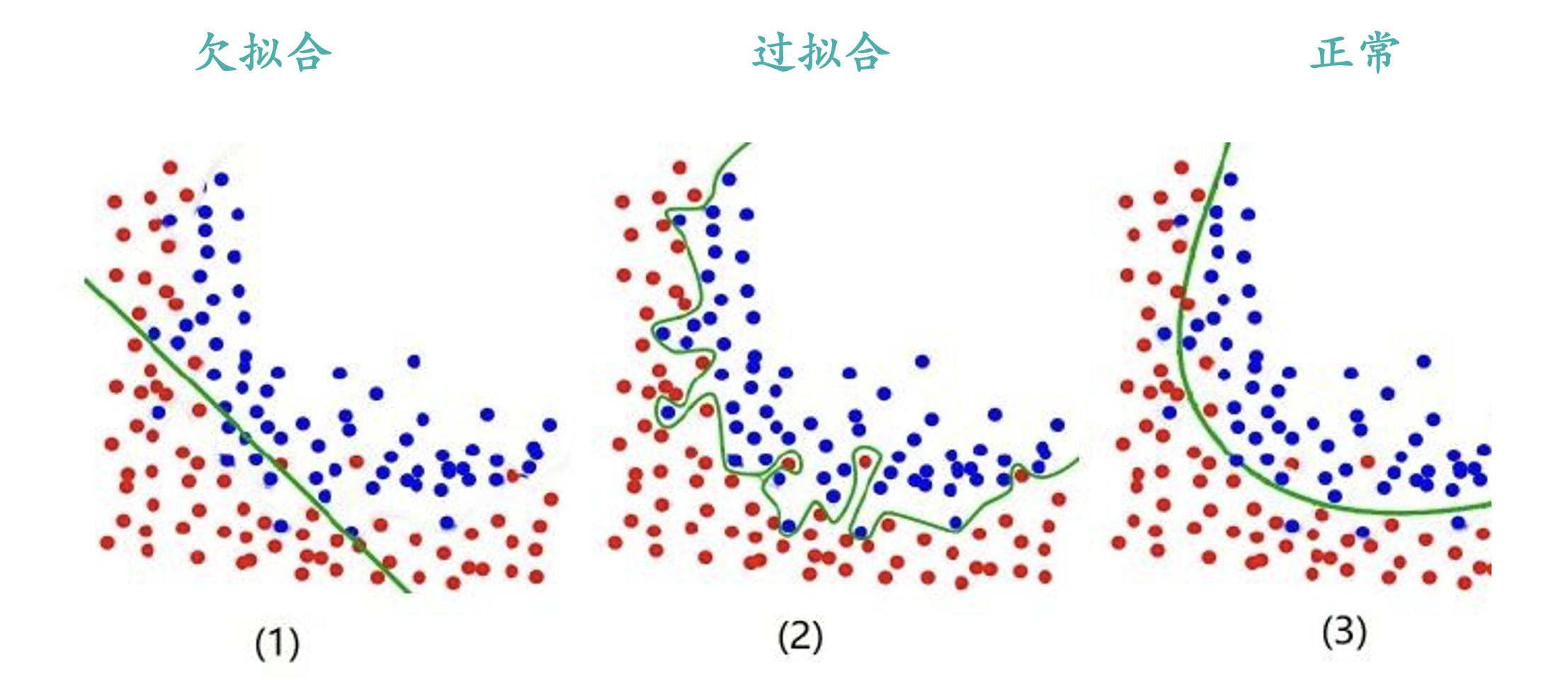
就是为了在训练集上面达到一个好的效果,而构造出来像上图这样的模型。该模型在训练集上面会有不错的效果,但是在测试集上大概率会效果不佳,比较好的模型表现是上图的Good Fit。所以实际训练中我们不能过于地考虑训练集中的某些特征和某些样本。不然模型的泛化能力会比较差,测试集上效果不佳。
模型训练很多情况下,数据科学家们都会训练好几版模型出来,这几版模型在训练集上表现差异不大,但特征工程等不一样,最后统一拿到测试集上进行评估。
步骤五模型评估:
步骤四训练出来的模型,我们如何来评估模型效果的好坏?就需要在测试集上面进行验证了。分类模型评估最经常使用的两个指标就是查全率Precision Rate和召回率Recall Rate。假设现在测试集有100个用户,90个为正常用户,10个为欺诈用户。我们的目的是为了把测试集里面的欺诈用户全部找出来,下图为预测结果:

我们可以发现,一共10个欺诈用户,模型挑出来了8个欺诈用户,查全率Recall Rate=8/10=80%,模型把80%的欺诈用户都找出来了。但是模型将10个用户误判成了欺诈用户,查准率Precision Rate=8/18。我们在评估模型效果好坏的时候会综合考虑Recall Rate和Precision Rate一起评估。不同模型评估的指标完全不一样,刚刚列举的模型评估指标只是分类模型的一种评估指标。
步骤五介绍了,一般数据科学家会训练出好几版模型出来,我们会挑选在测试集上表现最好的模型作为最终的模型。
步骤六模型应用:
我们将效果最好的模型部署到实际的生产环境中去进行使用。实际生产环境中效果的好坏,才是对模型真正的考验。即使模型在测试集上表现效果很好,有可能生产环境下效果表现一般。因为用户的行为等不停地在发生变化,数据也在更新,以前的一些特征工程可能不再适用于当下的环境。所以即使上线后,数据科学家们也会持续地关注模型的表现,再根据新积累的数据不断地对模型进行调优,总之这是一个不断更新迭代的过程,并不能一劳永逸。
本文由 @King James 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议









老板,模型里的KPI, PSI, AOC,IV这些能不能介绍一版,谢谢