
 起点课堂会员权益
起点课堂会员权益朴素贝叶斯算法:如何用AI买到好瓜?
如何利用AI买到一个好瓜?本文介绍了朴素贝叶斯算法的原理、应用场景和优缺点,希望能够帮助你更好地应用。

上篇文章我们介绍了K近邻算法,今天我们接着来学习另一个基础的分类方法,朴素贝叶斯算法。
朴素贝叶斯(Naive Bayes)是经典的机器学习算法之一,也是为数不多的基于概率论的分类算法。
朴素贝叶斯是在贝叶斯原理的基础上,假定特征与特征之间相互独立。
那么我们需要先了解一下贝叶斯算法。
一、贝叶斯公式
贝叶斯公式又被称为贝叶斯规则,其原理大概是:当不能准确知道事物本质时,可以根据与事物特定本质相关的事件出现的多少去判断该事物的本质。
比如,我们虽然无法准确的知道某个西瓜是不是好西瓜,但是我们可以通过敲击声、色泽、根蒂形状等特征去判断是否是好西瓜,如果它的敲击声沉闷、色泽青绿、根蒂蜷缩,那我们根据经验可以判断它大概率是个好西瓜。
贝叶斯公式中涉及到先验概率、条件概率、后验概率、联合概率等基础概念,具体解释如下:
- 先验概率:事件A根据经验来判断发生的概率,记作P(A)。比如从历史数据中统计出西瓜“色泽青绿”事件的概率为60%,那么P(色泽青绿)=60%
- 条件概率:事件B在事件A已发生条件下的概率,记作P(B|A)。比如从历史数据中统计出西瓜为“好瓜”时,“色泽青绿”的概率为80%,那么P(色泽青绿|好瓜)=80%
- 后验概率:基于先验概率求得的反向条件概率。P(B|A)是A发生后B的条件概率,也可以称作B的后验概率,所以后延概率的公式和条件概率一样,但区别在于条件概率是从历史数据中统计得来,而后验概率是基于先验概率和条件概率计算得来。
- 联合概率:表示两个事件共同发生的概率。A与B的联合概率一般表示为P(AB)或P(A,B)。比如“色泽青绿”(事件A)和“敲击声沉闷”(事件B)同时发生的概率为30%,则事件A和事件B同时发生的概率P(AB)=30%
实际上,贝叶斯的原理就是根据先验概率和条件概率估算得到后验概率。
二、朴素贝叶斯的原理
朴素贝叶斯是在贝叶斯原理的基础上,假定特征与特征之间相互独立,从而得到了如下朴素贝叶斯的公式:
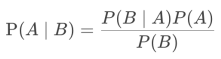
我们以挑选好西瓜为例,拆解一下这个公式,为了方便理解,我们从西瓜的众多特征中,仅挑选“色泽青绿”一个特征,来表达如果一个西瓜“色泽青绿”的话,如何计算它为“好瓜”的概率。
假设公式里的A代表“好瓜”,B代表“色泽青绿”,那么我们可以得到如下几个概率:
- P(A):历史数据中,统计西瓜为“好瓜”的概率,比如70%
- P(B):历史数据中,统计西瓜为“色泽青绿”的概率,比如60%
- P(B|A):历史数据中,统计西瓜为“好瓜”时,“色泽青绿”的概率,比如75%
那么我们就可以根据这几个概率,代入公式,计算得到P(A|B),即西瓜“色泽青绿”时,为“好瓜”的概率:P(A|B) = P(B|A)*P(A)/P(B) = 0.75*0.7/0.6 = 87.5%
也就是说,当西瓜“色泽青绿”时,有87.5%的概率是“好瓜”。
当然,仅仅靠一个特征是无法判断西瓜好坏的,那么多个特征的时候要怎么计算呢?我们来扩展一下,再引入一个“敲击声沉闷”特征。
也就是假设A1代表“好瓜”,A2代表“坏瓜”,B1代表“色泽青绿”,B2代表“敲击声沉闷”,计算当西瓜同时具备“色泽青绿”和“敲击声沉闷”特征时,为好瓜或坏瓜的概率。
- P(A1):历史数据中,统计西瓜为“好瓜”的概率,比如70%
- P(A2):历史数据中,统计西瓜为“坏瓜”的概率,比如30%
- P(B1B2):历史数据中,统计西瓜同时具备“色泽青绿”和“敲击声沉闷”特征的概率,比如30%
- P(B1B2|A1):历史数据中,统计西瓜为“好瓜”时,同时具备“色泽青绿”和“敲击声沉闷”特征的概率,比如40%
- P(B1B2|A2):历史数据中,统计西瓜为“坏瓜”时,同时具备“色泽青绿”和“敲击声沉闷”特征的概率,比如15%
我们将以上概率代入公式,分别得到如下结果:
- P(A1|B1B2) = P(B1B2|A1)*P(A1)/P(B1B2) = 0.4*0.7/0.3= 93.33%
- P(A2|B1B2) = P(B1B2|A2)*P(A2)/P(B1B2) = 0.15*0.3/0.3 = 15%
也就是说,当西瓜同时具备“色泽青绿”和“敲击声沉闷”特征时,有93.33%的概率是“好瓜”,15%的概率是“坏瓜”。
三、应用场景
朴素贝叶斯假设条件之间相互独立,所以比较适用于特征相对独立的场景:
- 文本分类:朴素贝叶斯算法能够有效地处理高维度的特征空间,而文本通常以词袋模型或者 TF-IDF 来表示,特征维度较高。
- 垃圾邮件过滤:朴素贝叶斯算法能够通过统计每个词在垃圾邮件和非垃圾邮件中出现的频率,来计算词的条件概率,自动识别和过滤垃圾邮件。
- 情感分析:朴素贝叶斯算法能够通过统计情感词汇在正面文本和负面文本中出现的频率,来计算情感词的条件概率,判断文本的情感倾向。
- 个性化推荐:朴素贝叶斯算法能够通过统计用户对不同物品的喜好频率,来计算物品的条件概率,从而预测用户对不同物品的喜好程度。
四、优缺点
朴素贝叶斯算法的优点:
- 逻辑简单:朴素贝叶斯是一种基于概率统计的分类算法,其计算速度快,适用于大规模数据集。算法的原理简单,实现容易,不需要太多的参数调整。
- 快速高效:朴素贝叶斯计算效率高,可以处理具有高维特征空间的大型数据集。
- 可以处理不相关的特征:朴素贝叶斯可以处理数据集中不相关的特征,并且仍然表现良好。
朴素贝叶斯算法的缺点:
- 假设条件之间相互独立:朴素贝叶斯假设条件之间相互独立,这就导致其有很大的局限性,只有在条件很少且相互独立时,才有较好的效果
- 无法处理连续变量:朴素贝叶斯假设特征是离散的,对于连续型数据需要进行离散化处理,可能会导致信息损失
- 需要足够的样本数据:朴素贝叶斯是基于统计学的算法,需要足够的样本数据来估计概率分布参数,否则会导致概率估计不准确,影响效果
五、总结
本文我们介绍了朴素贝叶斯算法的原理、应用场景和优缺点,还提到了贝叶斯公式的相关内容。
下篇文章,我们来聊一聊线性回归算法,敬请期待。
本文由 @AI小当家 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


