
 起点课堂会员权益
起点课堂会员权益大模型应用设计思考:大模型+bi,TFlowAI如何让大模型来检索数据
TFlowAI提出了一种基于大模型的解决方案,通过理解业务、查找数据、分析处理的过程编排,实现模型自主的基于数据库的数据查询与分析。这种方法不仅降低了开发成本,还提升了使用体验。

在B端的助手agent中,有一个重要的场景既数据的分析!那如何让模型能够理解产品的数据,理解数据结构、理解业务,准确的去数据库中查找数据,并给他客户展示呢?我们来看TFlowAI给出的解决方案
一、用户现状场景
如客服主管的Agent助手,只需一句话,Ai帮助用户快速找到想要的数据: 如:
- 今天客服接待的满意度咋样?
- 用户投诉最多的问题是那些?
- 从官网来的咨询量有多少?满意度怎样?
这些数据的查找、获取在原有产品设计中,有2个体验不好的点:
- 开发成本:新统计维度、数据项的增加,需要开发进行计算&编排
- 使用体验:数据分析维度,查看维度等等都受制于产品界面的限制;
那是否借助大模型的理解能力,来实现模型自主的基于数据库的数据查询与分析,生成报表,从而摆脱通过系统开发的方式实现数据的统计与分析。
二、解决方法
解决方法的设想:参考rag的面向过程编排的方法,将模型处理理解业务,查找数据,分析处理的过程通过workflow得形式编排,用大模型进行串联处理。
1. rag的流程
1)流程
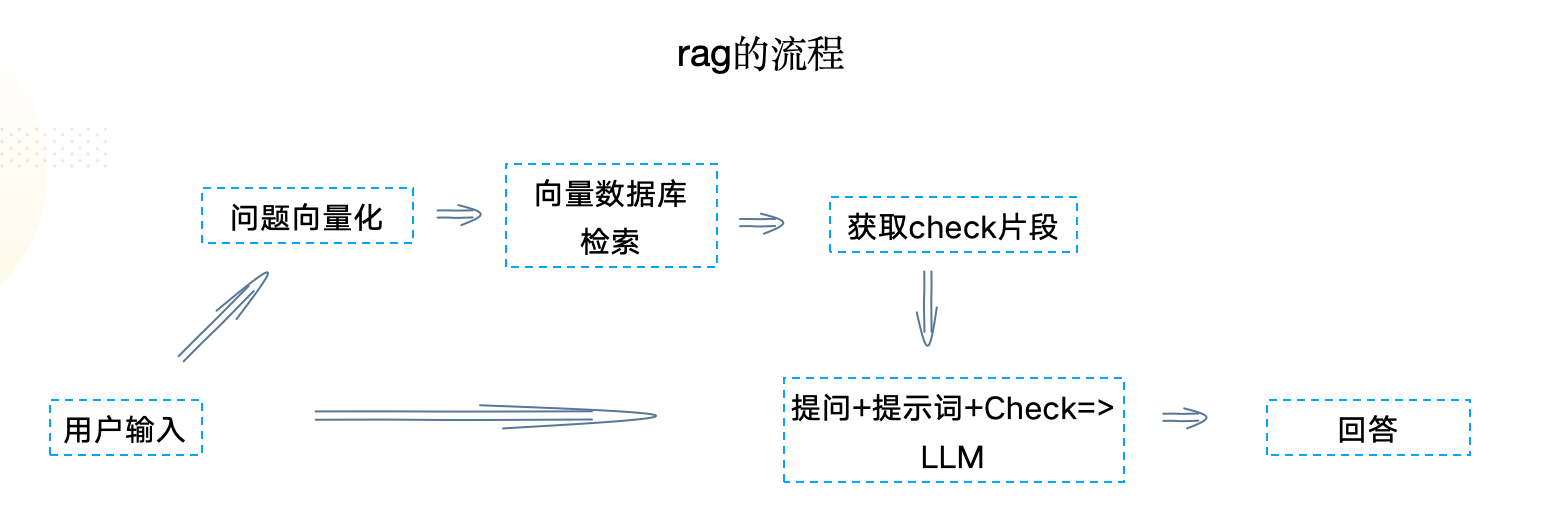
2)流程说明
- 用户提问向量化,index检索相似片段
- 通过提示词+用户提问+check片段 打包发给大模型
- 模型进行解答
2. 大模型+BI的过程编排流程
1)流程设计
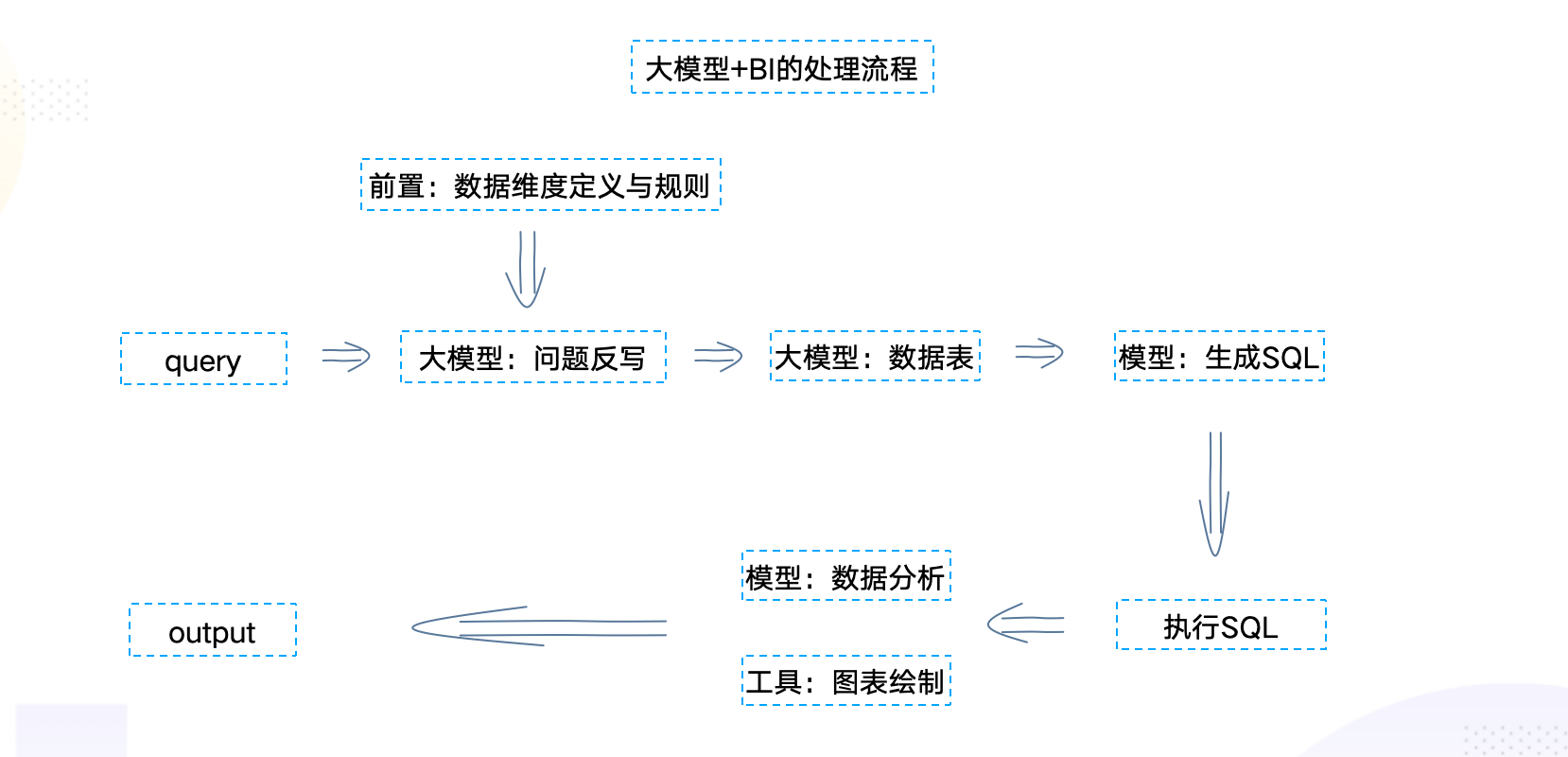
整个过程会经历问题的反写,表结构的理解,SQL的生成,SQL的执行,数据的可视化五个阶段。依次讲解下每个环节做什么。
(1)问题反写:让大模型理解query,通过提示词,让模型理解意图,当前产品有关的数据维度解释说明,计算规则等。从而将用户的需求完整的描述处理。
- 用户提问:官网线索转换了是多少?
- 模型反写:想要了解从官网注册的用户,最终购买产品的比例。计算规则:官网线索客户成交数/官网线索数
(2)理解表结构:让模型知道从那张表中获取相关的数据。通过补充表+字段的方法,让模型知道数据库中有哪些表,从而推测要用到哪些表
- 比如表结构理解输出:模型反写:想要了解从官网注册的用户,最终购买产品的比例。计算规则:官网线索客户成交数/官网线索数,要统计从线索表中筛选来源为“官网”的线索数,统计从成交订单中筛选来源为“官网”的订单数
(3)SQL生成:接住大模型或者txt2SQL等模型,将文本转为可执行的SQL
(4)执行SQL:执行上一步生成的SQL,获取其结果
(5)数据可视化:借助绘图工具,绘制趋势图等图表。同时模型对于数据进行简单的分析说明
(6)输出:对用户输出可视化的内容
整个过程的关键环节在于问题的反写与表结构的理解,需要在这个环节中用提示词给模型正确的引导,让模型能够理解清楚业务,以及用户的意图、计算逻辑。同时对于喂给大模型的内容,进行选择性的拼接。
同时也可以考虑增加娇艳环节,降低理解的出错率。
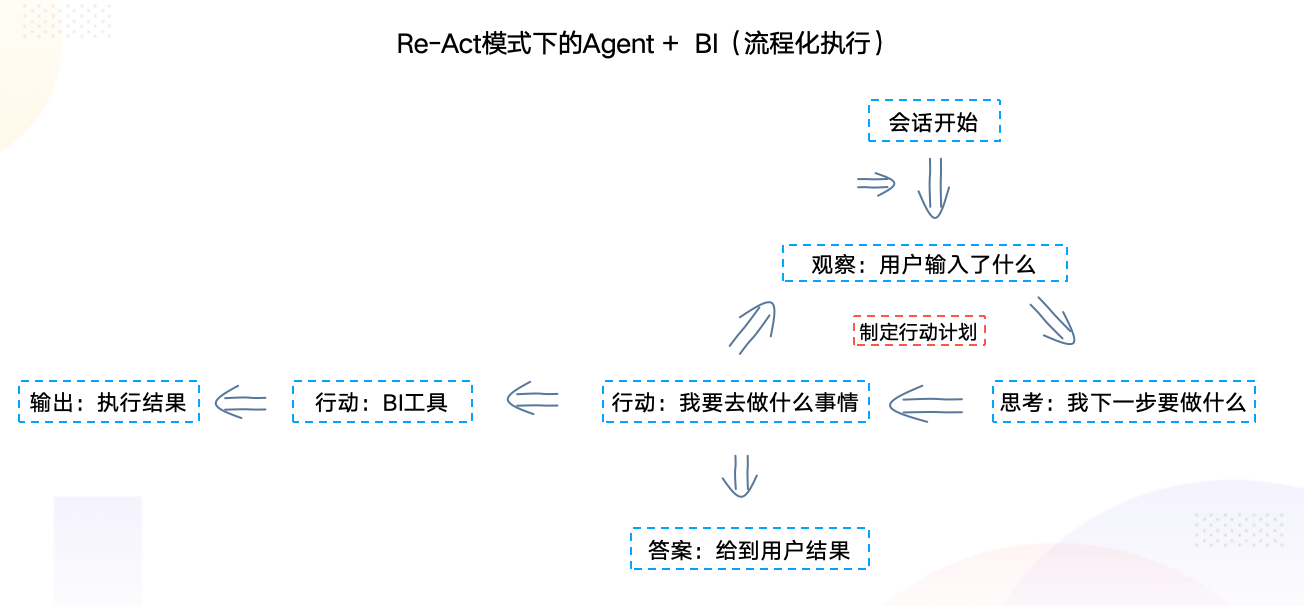
3. 进阶:融入Agent
更深度的应用,可以将大模型+bi的环节,变成Action事件,嵌入到已有的Agent当中
三、优势与问题
1. 优势
- 开发成本低:只需要数据库增加字段,提示词增加说明,即可满足用户对于数据分析的数据,开发成本大幅降低;
- 使用体验:基于模型的理解去分析,查找数据、分析数据,实时绘图,摆脱原有数据报表的限制,可以自定义进行深度的分析。
2. 问题
- 复杂数据的处理不确定,可能需要借助增加过程、借助agent等提高模型对复杂数据的处理;
- 存在幻觉、异常数据排查难度较大,过程黑盒无法排查!
本文由 @易俊源 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。






- 目前还没评论,等你发挥!


