
 起点课堂会员权益
起点课堂会员权益如何设计大规模 AI 系统(上)
构建大规模 AI 系统需层层递进:先选对 CPU、GPU、TPU 等计算硬件,搭好分布式架构并优化网络通信,再匹配适配的存储方案;在此基础上,还需掌握优化器选择、正则化、并行训练等高级技术,才能实现模型高效训练与部署。

训练一个机器学习模型,或许在基准数据集上达到最先进的准确率,这是一回事。但将该模型进行部署,让它为数百万用户提供服务、处理数 TB 的数据,并能每周 7 天、每天 24 小时可靠运行,则是截然不同的挑战。
从一开始,机器学习模型的训练和部署的每个环节、每个阶段都需要精心规划和合适的工具。
从早期开发到全面部署构建并运行一个 AI 系统,在这个过程中…
强大的软件开发技能变得至关重要,而这正是许多 AI 工程师所欠缺的。
在本博客中,我们将探讨构建一个能够创建大语言模型(LLMs)、多模态模型及各种其他 AI 产品的大规模 AI 系统所需的每个开发阶段。各开发阶段如何相互关联,以及它们各自的职责。
第一阶段:AI 的系统与硬件
构建大规模 AI 系统的第一步,是选择合适的硬件。这会影响模型的运行速度、成本投入以及能耗情况。
在本部分,我们将探讨市面上不同的硬件系统,以及如何提升其成本效益和能源效率。AI 计算硬件
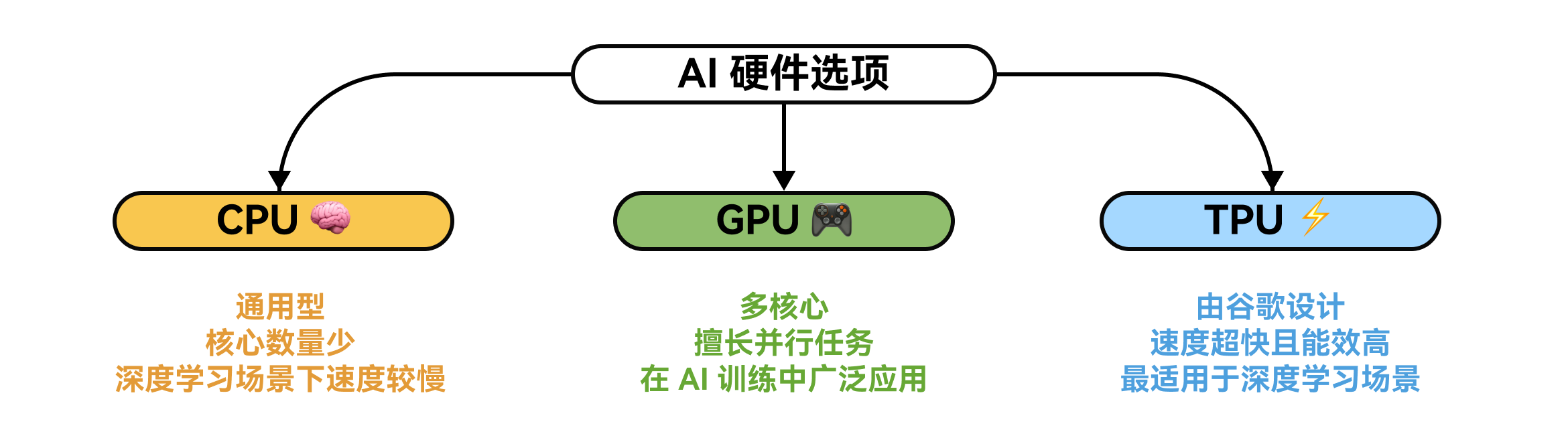
广泛应用于训练或其他 AI 任务的三种最常见硬件类型如下:
AI 硬件可用性
- 中央处理器(CPUs):它们擅长处理多种不同任务,但核心数量相对较少,因此在深度学习或需要大量并行处理的大型 AI 任务中,速度可能较慢。
- 图形处理器(GPUs):最初是为处理视频和图形而设计的,如今却成了 AI 领域的宠儿。因为它们的核心数量比 CPU 多得多,这意味着它们可以同时处理大量任务,非常适合训练和运行 AI 模型。
- 张量处理器(TPUs):这是谷歌专门为深度学习打造的特殊芯片。它们速度极快、效率超高且能耗较低,非常适合大型复杂的 AI 任务。
但最近,由于对 AI 的需求不断增长,一些新型硬件也相继问世。
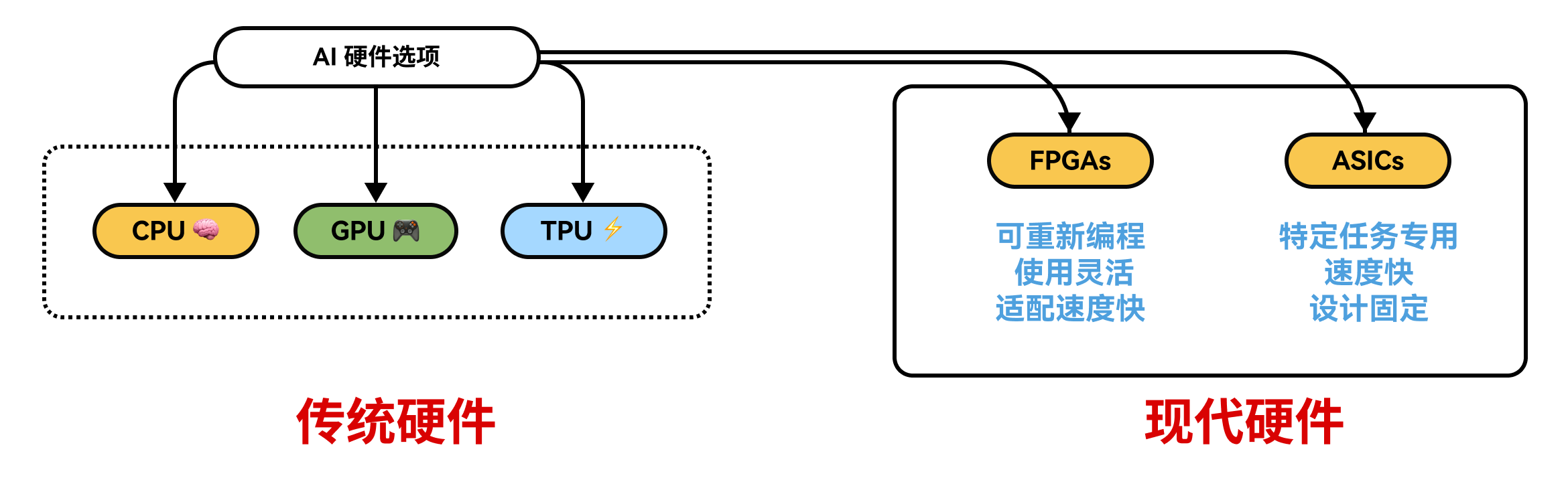
- 现场可编程门阵列(FPGAs)就是一个很好的例子。这些芯片很特别,因为它们可以重新编程以适配不同的 AI 任务。这使你能够根据模型需求灵活微调性能,这在快速变化的 AI 项目中非常有用。
- 还有专用集成电路(ASICs)。它们不像 CPU 甚至 FPGAs 那样具有通用性。相反,它们专为一件事而设计:尽可能快速高效地运行 AI 模型。由于它们是为诸如驱动神经网络这类特定任务而打造的,所以能耗低且运行速度极快。
在选择硬件时,我们通常会认为不管是数据预处理、微调还是大语言模型(LLM)推理,直接选用 GPU 就一定能提升性能,但这种做法并不总是正确的。
然而,性能在很大程度上取决于…
模型架构 + 基础设施选择
- 从 AI 架构角度来看,模型量化是一种有效的技术,像 Together AI、Nebius AI 等许多现代开源模型 API 提供商都已在使用。这意味着在计算时减少 AI 模型所采用的细节程度,比如使用更小的数据位宽(例如,用 8 位替代 32 位 )。
- 从基础设施角度而言,云服务和虚拟化常常是最佳解决方案。你无需购买昂贵的硬件,而是可以从亚马逊云服务(AWS)、谷歌云(Google Cloud)或微软云(Azure)等供应商处租用高性能机器。这样一来,你能够依据项目需求灵活地进行资源扩展或缩减,既节省成本又避免浪费
看看谷歌提供的对比图表,它展示了不同模型架构在各类 GPU 上的性能表现。
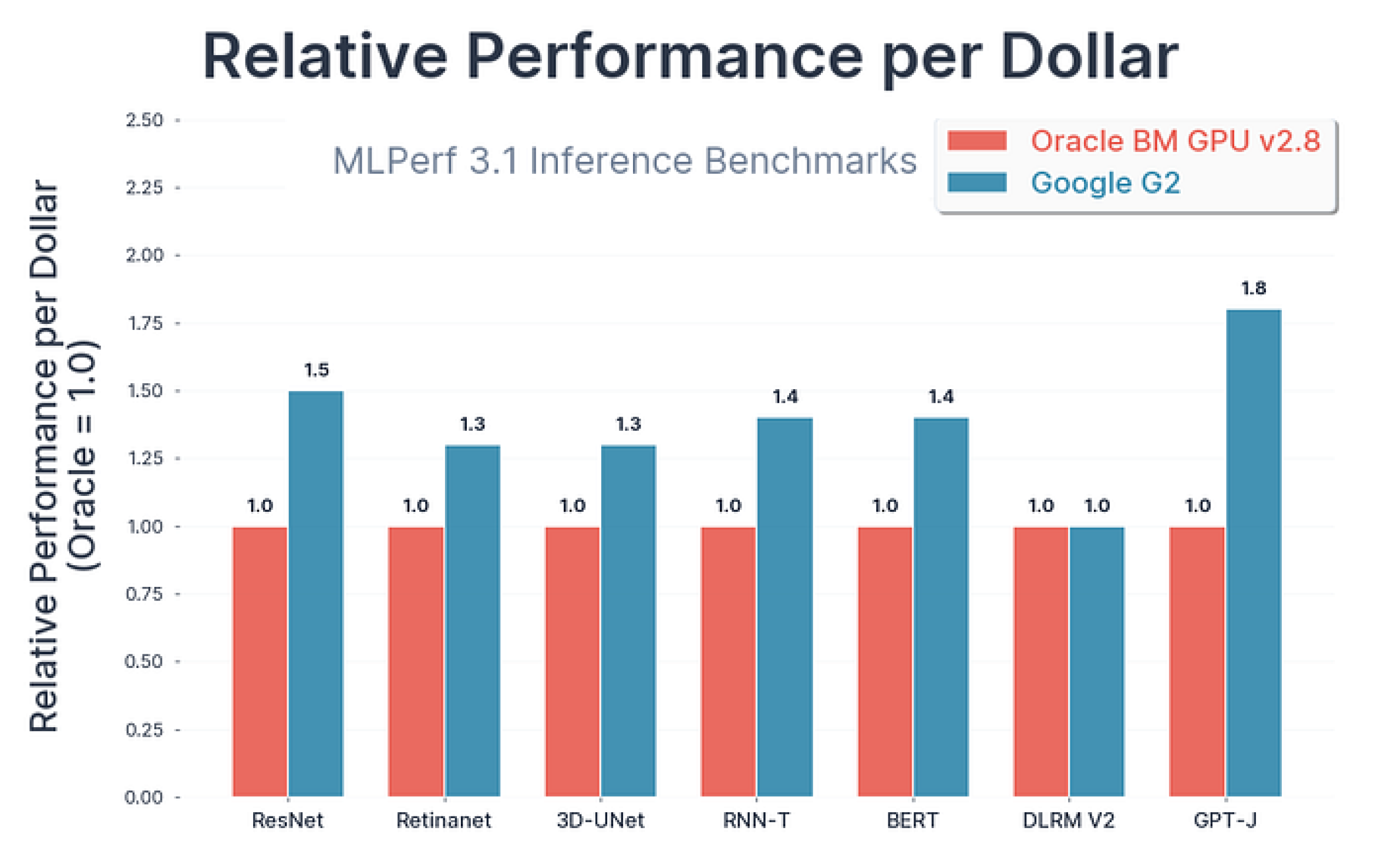
谷歌在 MLPerf 3.1 基准测试(主要用于衡量系统处理输入的速度)上进行了此项测试。
- 对于高难度的 AI 任务,配备强大 H100 GPU 的 A3 虚拟机比旧款 A2 虚拟机快得多,速度快 1.7 到 3.9 倍。
- 如果想在保证一定 AI 性能的同时节省成本,使用 L4 GPU 的 G2 虚拟机是个不错的选择。
- 测试表明,与类似云服务相比,L4 GPU 每花费一美元可实现高达 1.8 倍的性能提升。
像 Bending Spoons 这样的公司已经在使用 G2 虚拟机,高效地为用户带来新的 AI 功能。
AI 分布式系统
一旦根据需求选定了优化的硬件和模型架构,我们就进入下一阶段,即规划 AI 的分布式系统。
分布式系统的主要原理是…
将一个大任务拆分成多个小部分,让多台计算机同时处理这些小任务。
在 AI 领域,通过分担工作负载,这能够加快数据处理和模型训练速度。
因此,要创建分布式系统,我们需要考虑一些重要因素。我们先从概念上了解,然后再梳理其流程。
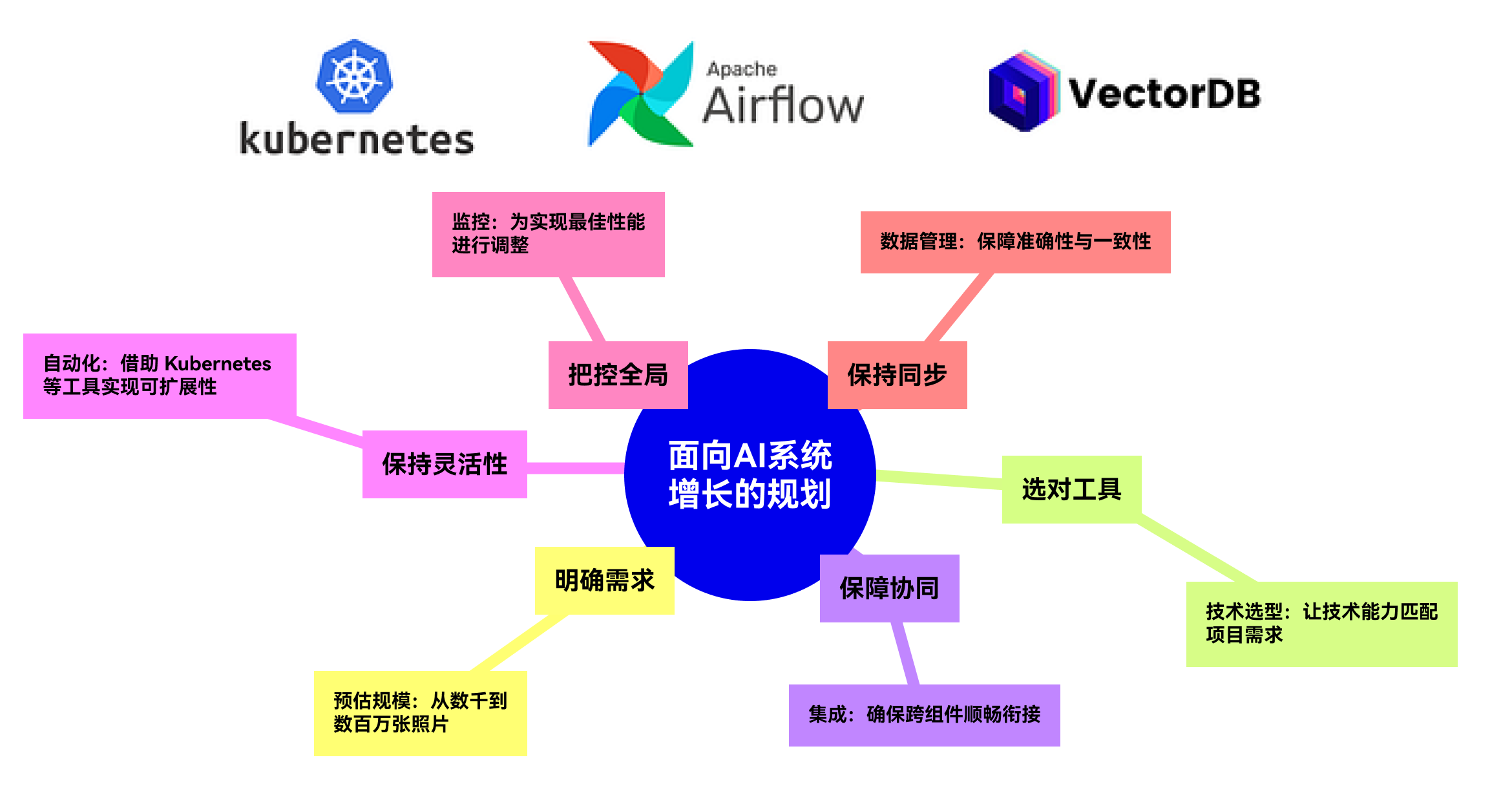
在将分布式逻辑应用到 AI 系统中时,我们需要考虑诸多因素。下面来看一下具体流程:
- 首先,要明确规模。我们处理的数据量是数百、数千还是数百万?尽早了解这一点,有助于我们合理规划系统,确保其能顺利扩展。
- 接下来,选择合适的工具。根据项目的规模和类型,我们需要合理搭配处理能力、内存和通信方式。云平台能让这一管理过程变得轻松许多。
- 然后,要确保各部分协同工作。系统的不同部分可能需要并行运行,或者在不同机器上运行。我们的目标是避免出现运行缓慢的情况,保持系统平稳运行。
- 之后,要保持灵活性。我们应实现资源调整自动化,而非手动操作。像 Kubernetes 这样的工具可以帮助系统根据负载变化自动调整。
- 我们还需要监控性能。密切关注系统有助于我们尽早发现问题,无论是数据分布不均,还是网络瓶颈。
- 最后,要确保一切保持同步。随着系统规模的扩大,保证数据和模型在所有部分的一致性至关重要。
网络优化
在确定 AI 系统的分布式架构后,你需要确保所有组件都能正确连接。
各组件之间必须能够顺畅、无故障地相互通信。
若分布式组件无法有效通信,训练代码或生产代码就可能出现问题。
下面来看看如何确保通信顺畅,不出现故障:
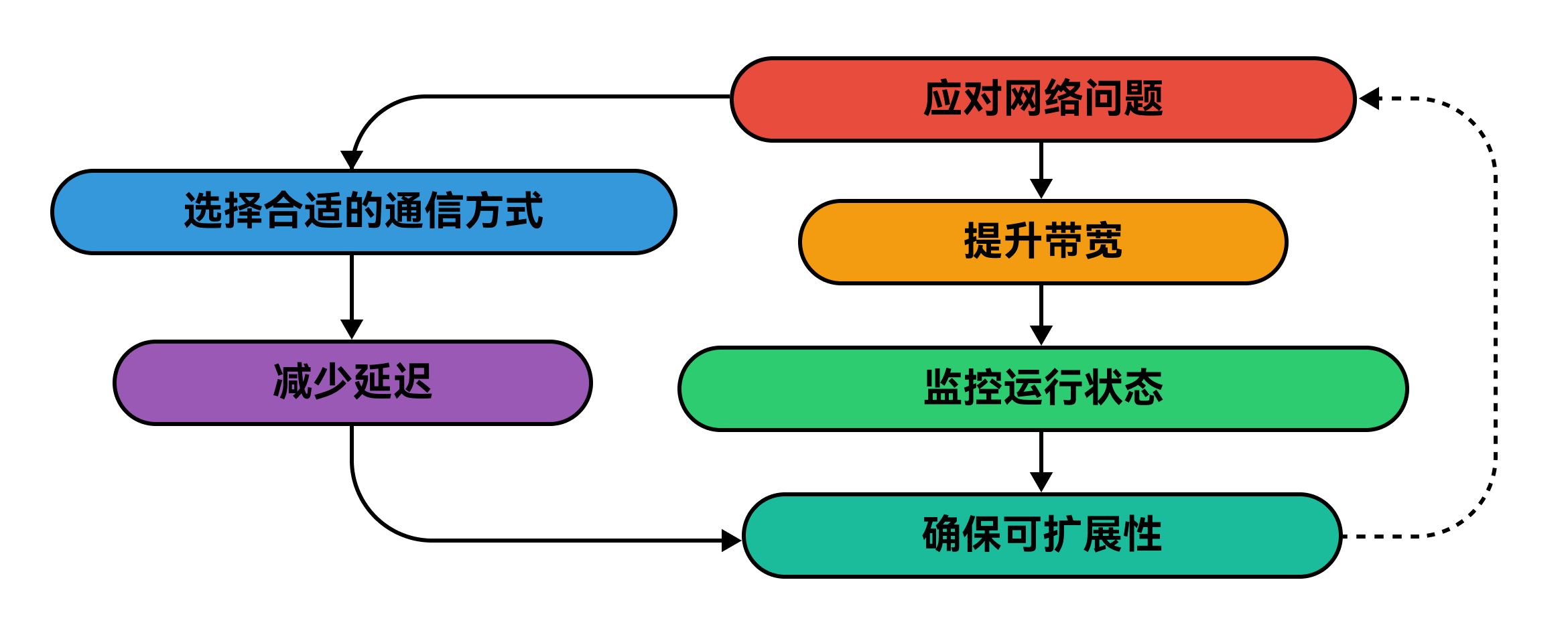
我们来详细分析一下:
- 首先,排查潜在的速度瓶颈。延迟、容量限制或数据丢失会严重影响性能,因此尽早识别这些风险很重要。
- 接着,减少延迟。为提高速度,我们可采用更快的连接方式、将机器放置得更近,甚至将部分处理任务转移到边缘端。
- 随后,提升带宽。网络路径狭窄会导致拥堵。我们通过压缩数据、对重要信息进行优先级排序或升级网络来解决这一问题。
- 之后,选择合适的通信方式。某些协议在处理大量负载方面表现更优。选对协议能确保系统快速高效运行。
- 我们还要为未来的扩展做好规划。随着系统规模扩大,网络也必须跟上节奏。关键在于采用可按需扩展的灵活架构。
- 最后,监控网络状况。定期检查有助于我们尽早发现问题。监控工具能在问题导致速度下降前发出警报。
AI 存储解决方案
在确定了用于训练或推理的硬件以及背后的分布式逻辑后,接下来你需要存储来保存训练好的模型,以及用户与 AI 模型交互产生的数据。
我们存储数据的方式不仅要适用于当下,还得能应对未来更多的数据。
我们有三种类型的数据存储系统:
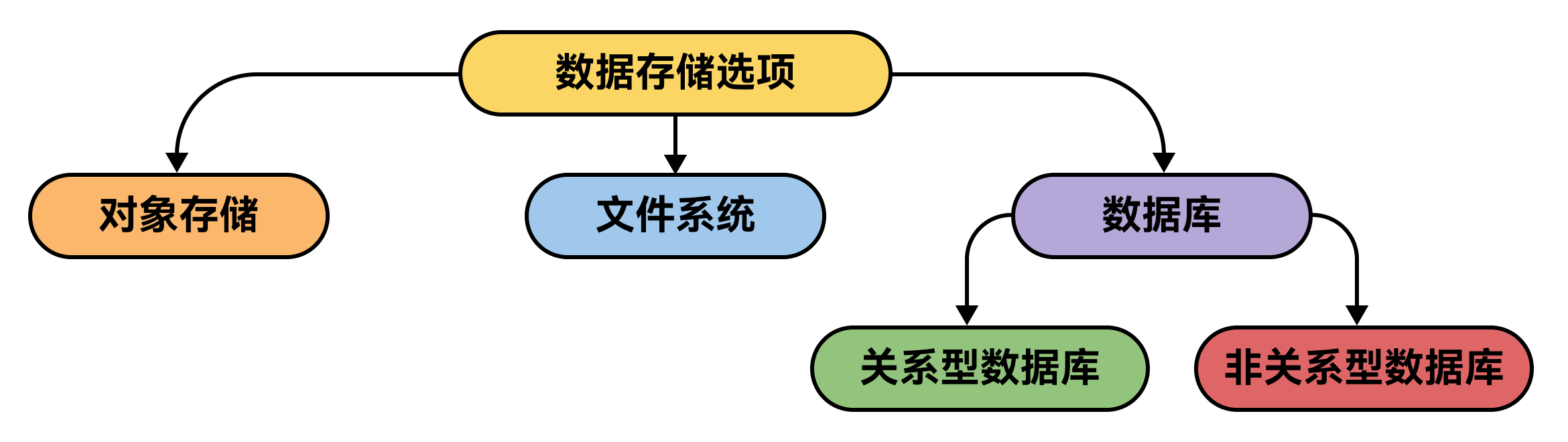
- 对象存储最适合大数据。在这种存储方式下,你可以不断添加文件,无需担心数据结构。当数据来自多个源头,之后需要整合时,对象存储就非常适用。
- 文件系统更适合规模较小、结构规整的场景。它就像是你电脑里的文件夹,有助于保持数据规整,在数据量有限且结构良好的情况下最为理想。
而第三种是数据库,当数据具有结构时,数据库很有用。以下是选择合适类型数据库的方法:
- 关系型数据库(SQL)非常适合规整且相互关联的数据。当数据存在明确的关系,比如用户、订单和产品之间的关系时,就使用关系型数据库。在对准确性和一致性要求较高的复杂任务中,它们表现出色。
- 非关系型数据库(NoSQL)适用于灵活多变的数据。如果数据无法规整地放入表格,或者增长迅速,像 MongoDB 或 Cassandra 这样的 NoSQL 数据库能提供所需的灵活性和可扩展性。
不过,工具并非唯一重要的因素,如何使用它们同样关键:
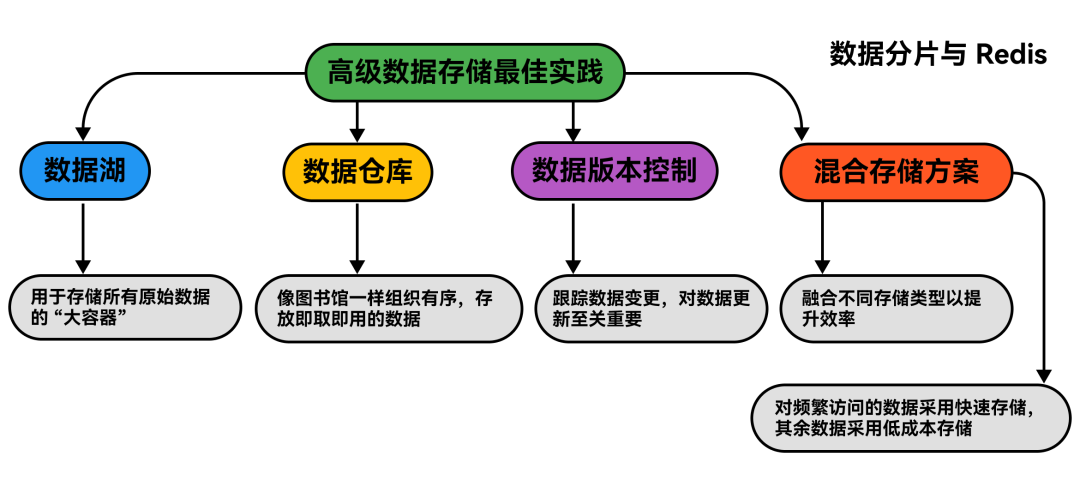
- 数据湖以原始形式存储所有数据。它就像一个巨大的容器,能容纳各种数据,供你日后整理和处理。
- 数据仓库存储经过清理、可直接使用的数据。这就好比一个组织有序的图书馆,你能迅速找到所需内容。
- 数据版本控制用于跟踪数据变化。在更新模型或处理随时间变化的数据时,这一点很重要,有助于保持数据有序,防止出错。
- 混合存储兼顾速度与成本。对常用数据使用快速存储,其余数据使用成本较低的存储。这样既能省钱,又能在必要时快速访问数据。
快速的数据访问对 AI 性能至关重要。
使用 Redis 这样的内存存储来实现快速检索,并应用数据分片来分散负载,避免速度下降。
在某些时候,你需要决定哪种存储设置最适合:云存储、本地存储,还是两者结合。
- 混合存储赋予你灵活性。你可以将敏感数据存放在自己的服务器上,而其他数据则使用云存储。这有助于平衡安全性与可扩展性。
- 多云策略提供了更多选择。通过使用多个云服务提供商,你可以避免被单一供应商锁定。这就好比有不同的菜单可供选择,具体取决于你的需求。
第二阶段:高级模型训练技术
到目前为止,我们已经讨论了硬件、存储以及如何充分利用它们。现在是时候看看训练技术的工作原理,以及我们如何对其进行优化。
优化神经网络训练的策略
AI 模型通常构建在神经网络之上,虽然许多模型从基本的梯度下降法起步,但在实际应用场景中,还有更先进的方法能取得更好的效果。
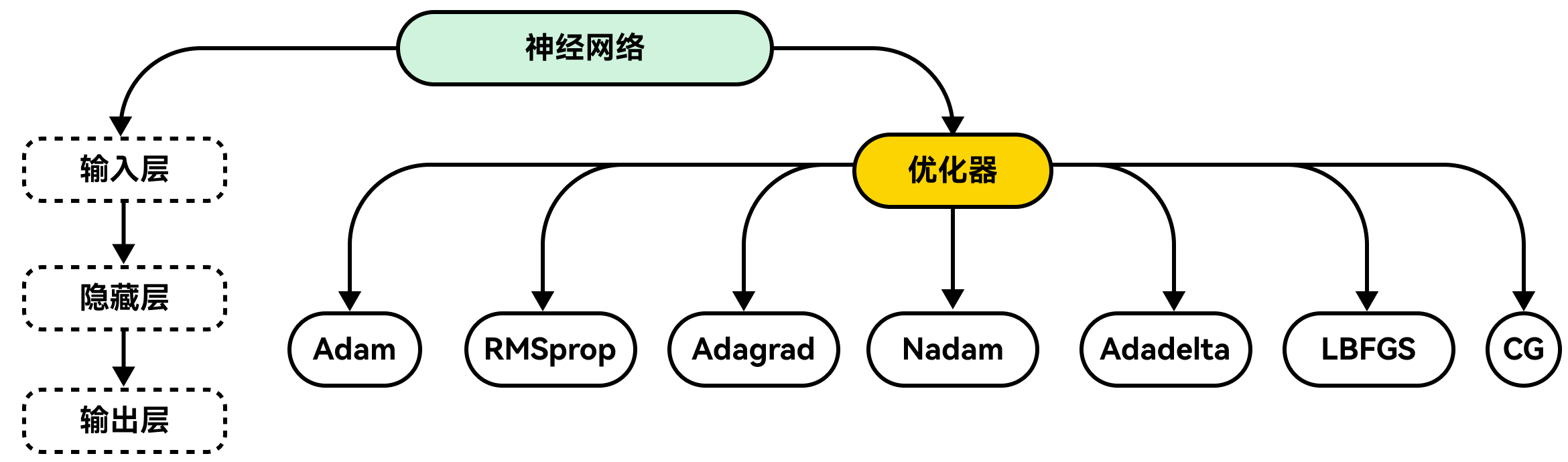
Adam 优化算法是个明智之选。它融合了 AdaGrad 和 RMSprop 的优点,能很好地处理噪声数据和稀疏梯度,因此成为广受欢迎的默认选择。

RMSprop 算法有助于提升学习稳定性。它会依据近期的梯度变化情况来调整学习率,在处理非平稳问题时表现出色。

Adagrad 算法能根据数据进行自适应调整。它针对每个参数分别改变学习率,这对于稀疏数据效果显著,但随着时间推移,可能会导致学习率下降过多。

我们来看一张简单的表格,它能让我们对现有优化器及其适用场景有个宏观了解。
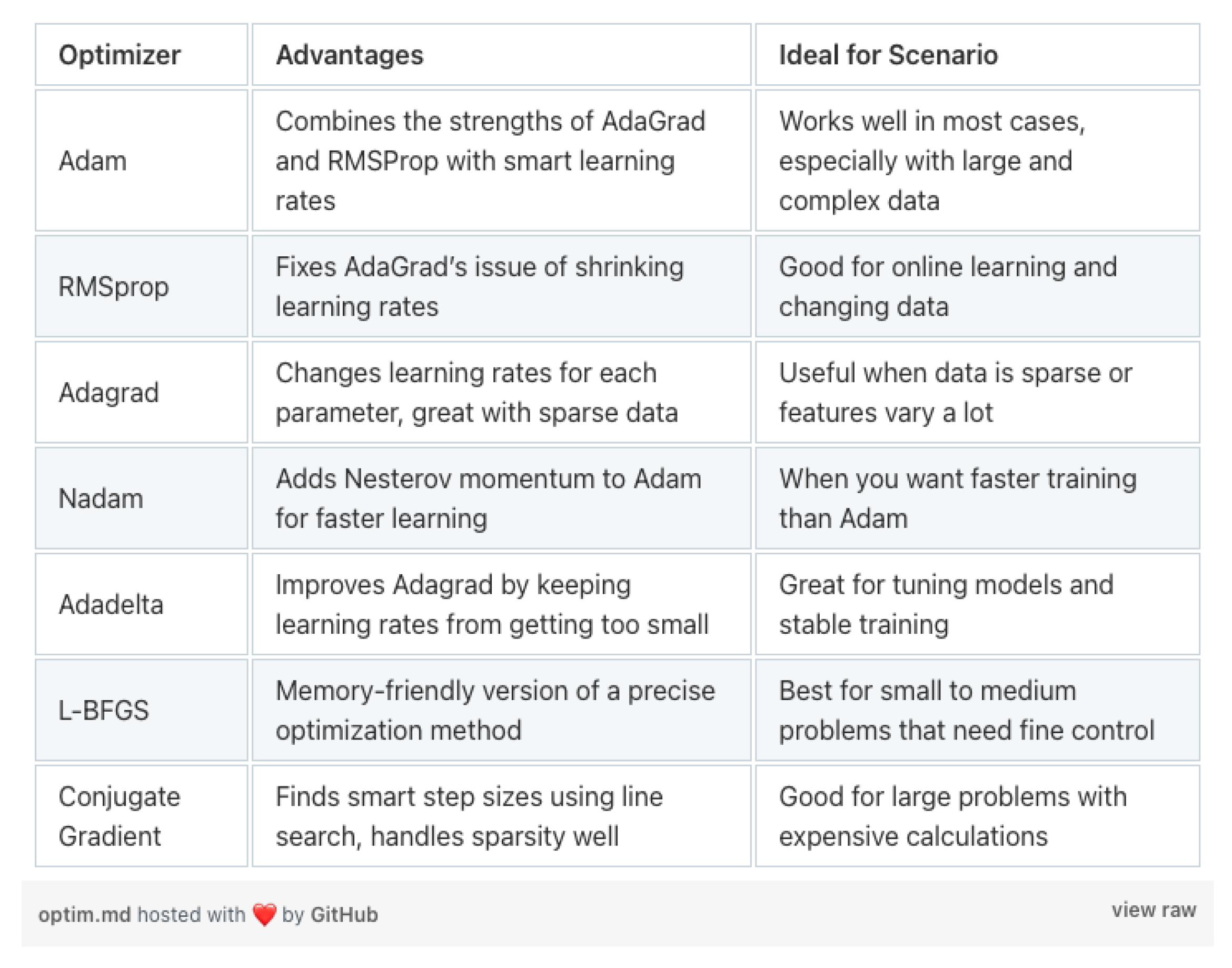
因此,这种对比能帮助机器学习工程师决定选择哪种优化器。
我们完全可以从 Adam 优化器入手。尽管不同优化器之间存在差异,但从实用的方法起步并获取一些初步认知很重要。
大规模训练的框架与工具
接下来是正则化技术,这对于防止过拟合、确保模型能很好地泛化到新数据至关重要。以下是一些能让模型在新数据上良好泛化的常用方法。
带权重衰减的 L2 正则化通过抑制较大的权重,使模型保持简单,从而起到作用。

模型中的 Dropout 层在训练过程中随机丢弃神经元,这样能降低模型过拟合的可能性。

基于验证损失进行早停。如果验证损失不再改善,那就没必要继续训练了。

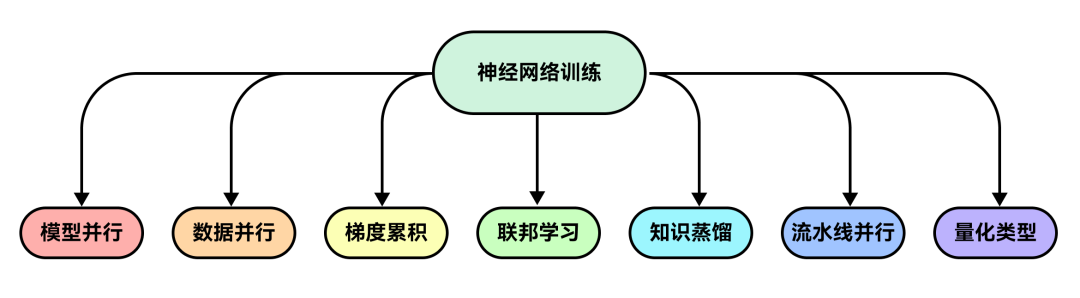
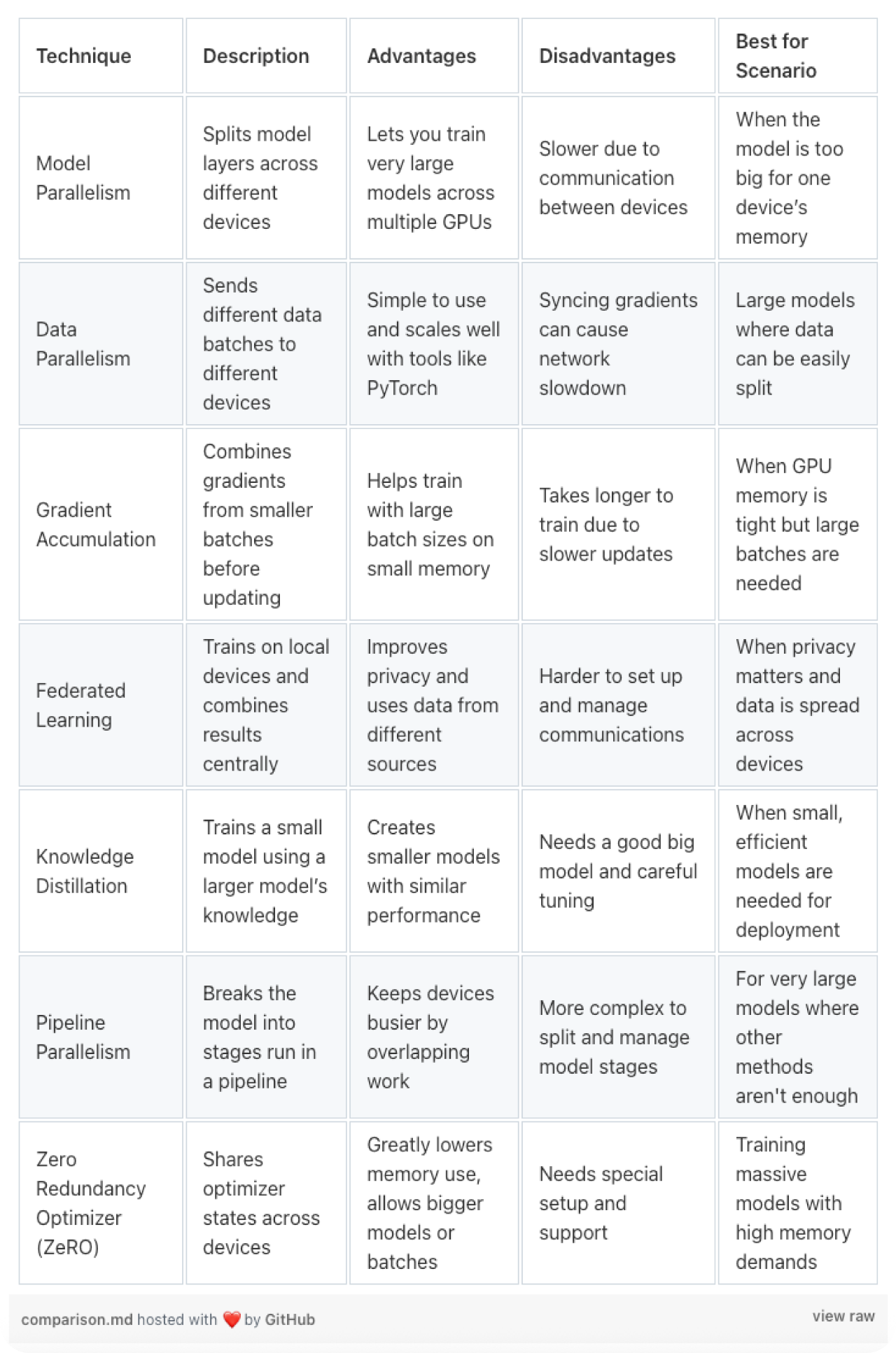
处理超大型模型会带来新的挑战。以下是一些应对方法,以便让处理过程更可控。
模型并行化是将模型拆分到多个 GPU 上,模型的不同部分在不同设备上进行处理。

数据并行化是将数据分散到多个 GPU 上,PyTorch 的 DataParallel 可自动管理这一过程。

梯度累积能实现更大的批次处理。当内存有限时,它通过在更新前累积梯度来解决问题。

联邦学习将数据保留在本地设备上。模型在各个设备上分别进行训练,仅共享模型更新。
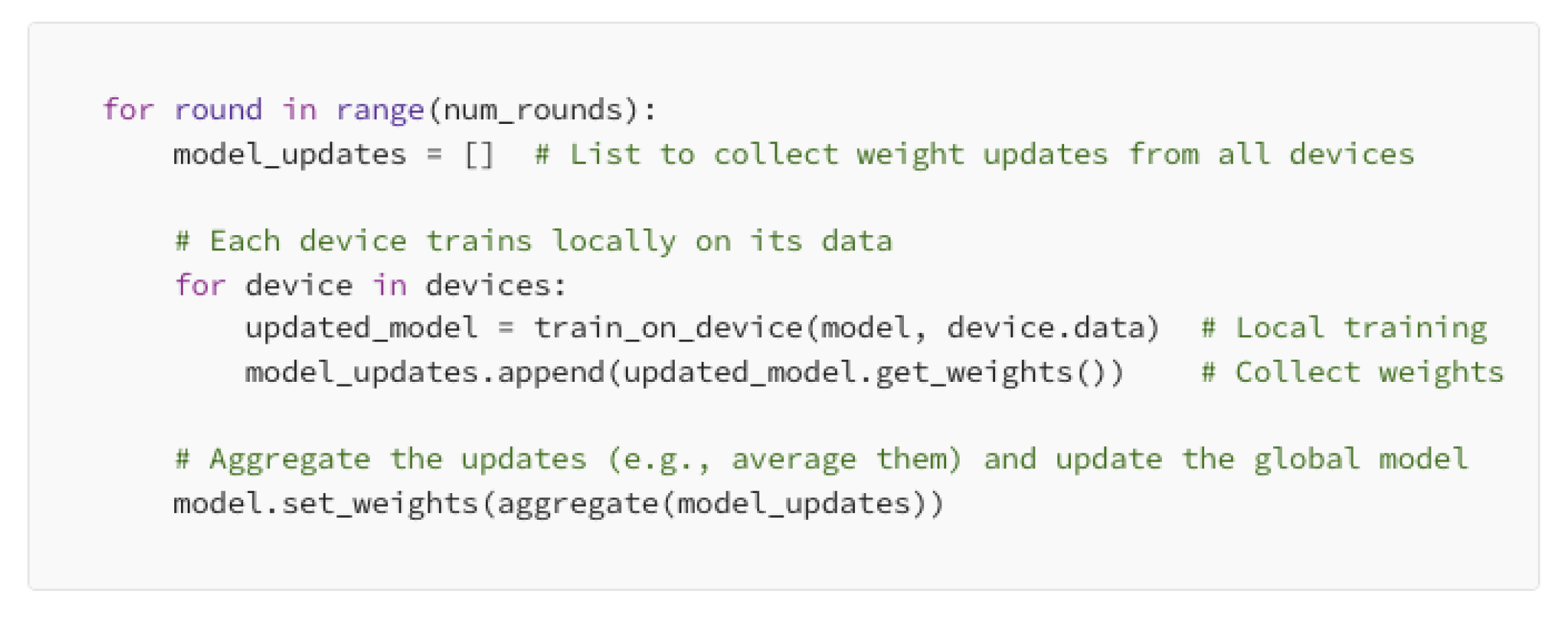
为了在不损失过多性能的前提下提高大型模型的效率,知识蒸馏是一种很好的方法。
利用大型 “教师” 模型来训练小型 “学生” 模型。这有助于在缩小模型规模的同时保持较高的准确率。

通过结合合适的优化器、正则化方法以及训练策略,即便面对大规模数据,我们也能构建出既强大又高效的模型。
我们可以做个对比表,以便更清晰地理解这些内容。
借助 TensorFlow 和 PyTorch 实现规模化
在大规模开展 AI 工作时,框架也起着重要作用。以下是一些热门选择:
最重要的框架
- TensorFlow 提供了 TensorFlow 分布式策略,有助于在 GPU 和 TPU 上高效扩展训练。
- PyTorch 以其 PyTorch 分布式功能闻名,支持在多个 GPU 和多台机器上进行扩展。
- Horovod 可与 TensorFlow、PyTorch 和 Keras 配合使用,提升在 GPU 和 CPU 上的可扩展性。
- Kubernetes 有助于在大规模运行时平稳部署和管理 AI 工作负载。
- CUDA 和 cuDNN 可加速 GPU 计算和深度学习性能。
- NeMo 专注于构建语音和自然语言处理模型。
模型扩展与高效处理
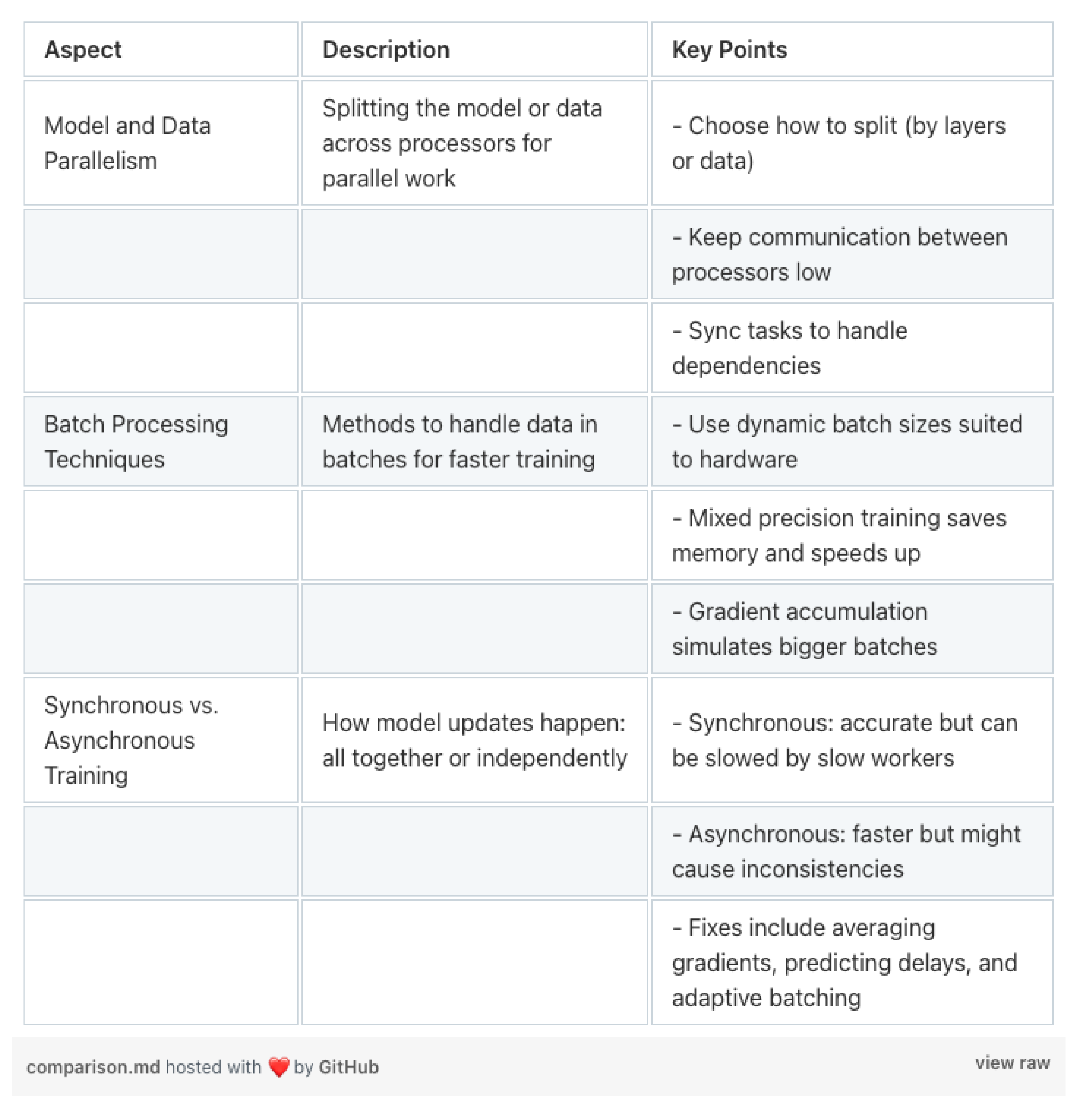
扩展模型是处理大数据集和复杂任务的关键。让我们探索一些简单的方法,对模型和数据进行并行处理、巧妙处理批次,并应对训练过程中的挑战。
模型并行,当模型对于单个 GPU 来说过于庞大时,我们可以将模型拆分到不同设备上。可以按层(纵向)或层的部分(横向)进行划分。目的是减少设备之间的数据传输。

我们可以使用像 NCCL 这样的高速通信库,来减少数据传输时的延迟,还可以
torch.cuda.synchronize () 确保各设备按顺序完成任务。

数据并行:我们可以在多个设备上,对不同的数据块运行相同的模型。当模型可在单个 GPU 上运行,但我们希望并行处理更多数据时,这种方法很有用。

反向传播后,分布式数据并行(DDP)会在各设备间同步梯度,以确保模型权重一致
我们还可以通过梯度压缩来减轻通信负载。以下是一个使用 8 位量化的简单示例:

高效批次处理:我们可以通过调整批次处理方式来提升速度并优化内存使用。
- 混合精度训练使用半精度(float16)以加快计算速度:

- 如果你的 GPU 无法处理大批次数据,梯度累积会有所帮助:

我们来了解一下同步训练和异步训练的基本区别:
同步训练:所有工作节点在更新权重前等待交换梯度。这样能确保模型的一致性,但最慢的工作节点会拖慢整体速度。
- 梯度平均
- 自适应批次大小
- 预测等待时间调度
异步训练:工作节点无需等待就更新权重。这能加快训练速度,但梯度可能过时。
- 使用过时梯度校正
- 动态调整学习率
- 维护模型版本控制以跟踪更新
那么,基于目前所学内容,我们用一张表格来进行总结:
撰文:Fareed Khan
本文由人人都是产品经理作者【TCC翻译情报局】,微信公众号:【TCC翻译情报局】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


