
 起点课堂会员权益
起点课堂会员权益从原理切入,看大模型的未来
当罗永浩与豆包的辩论展现出AI的情感交互能力,大模型已从效率工具转向情感化设计新阶段。本文从温度参数调控到Prompt工程,深度解析大模型如何通过自训练与引导优化实现人格化进化。通过对比人类成长三要素,揭示AI发展正从技术竞赛转向人性化共生的未来路径。
相信大家都接触过大模型,比如 DeepSeek、豆包、ChatGPT 等生成式 AI 应用,当用户输入相关信息后,大模型就会快速输出相应的结果:文字、图片,甚至是视频。这是大家对大模型最常见的认识——效率工具。可当笔者看到25年底的《罗永浩年度科技创新分享大会》时,那段罗永浩和豆包的辩论彻底吸引住了笔者的眼球。
在吃瓜的同时,笔者关注了两个重点:“吵架能吵出心流”、“你还训练过情绪是吗”。通过罗永浩对豆包的感知,他道出了C端产品的本质:面向个体化用户重视情感的设计,通俗一点即抓住人的心/记忆点。正因这场辩论,笔者对大模型未来的发展也有了新的思考,本文就从大模型的原理切入与大家一块探索。
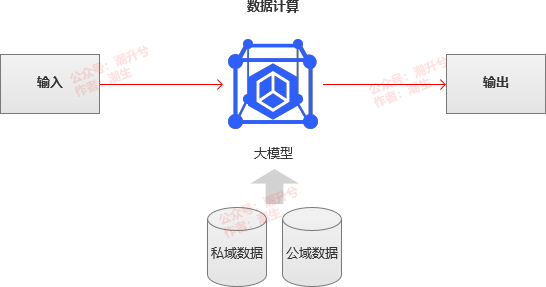
关于原理,大家耳熟能详的是大模型将用户的输入信息,基于公域或私域数据的计算,生成输出的过程(如下图所示)。
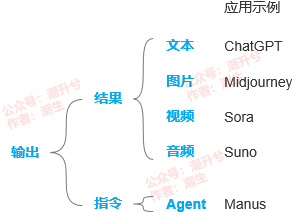
常见的 AI 应用,也是围绕输出的两个维度展开的(如下图所示)。
一开始,笔者也只是了解这些体感可察的内容,脑子中最常想的还是那些偏工程性的应用方案。当笔者试图反向顺着“输入 → 数据计算(模型) → 输出”的流程对“数据计算(模型)”深入了解时,发现在“输出”之前还有“自训练”、“引导优化”两个环节(如下图所示)。
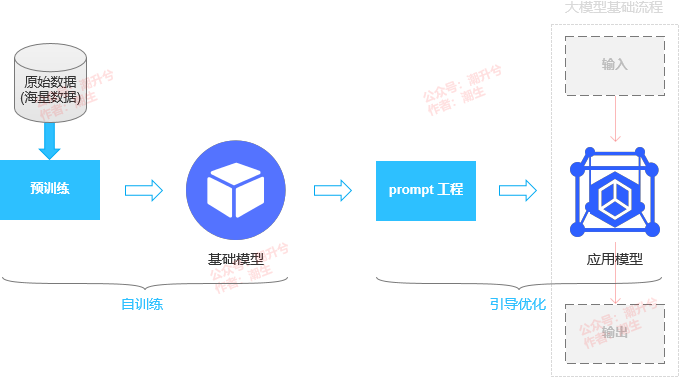
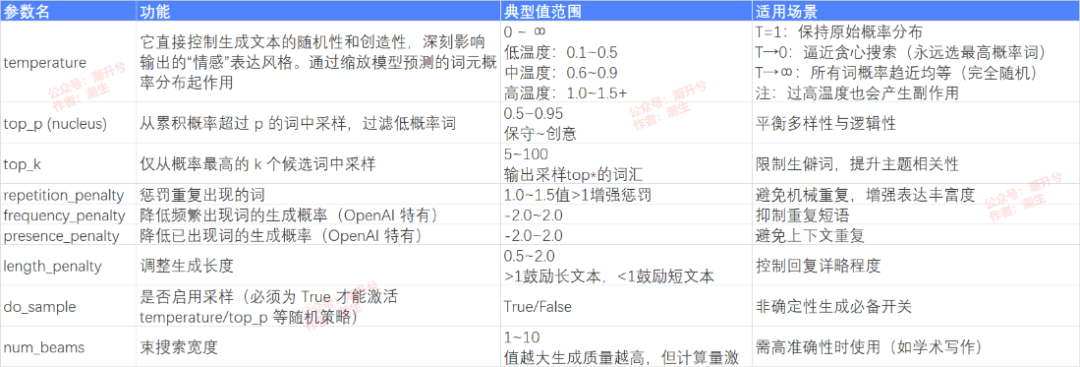
首先,先梳理自训练这个环节。它主要包括两个阶段,一个是通过干预数据(“喂”打标数据),并配置其内部的参数(神经网络权重,笔者在网络上整理了如下图所示的一些主流参数),定性了最初的基础模型。这一阶段就相当于编译了大模型的 DNA,定义了大模型的属性。另一个阶段是通过自生成内容(比如用户和大模型一次次对话反馈),再训练或优化自己,有点像一个学生在课堂之外通过接触其他信息源培养的能力或习惯。
接着,再梳理引导优化这个环节。在梳理前先说个生活中的故事,去年笔者在训练自家娃表达是与不是时,笔者会把他面前玩具一一拿起,然后对他说:“这个是不是你想要的玩具?是的话点头,不是的话摇手(说着笔者还做了相应的动作)。”在经过4次对话后,笔者终于找到了自己娃喜欢的玩具,他也学会表达是与不是,这个过程就很像 prompt 工程——像对待孩子一样,引导其解决问题。
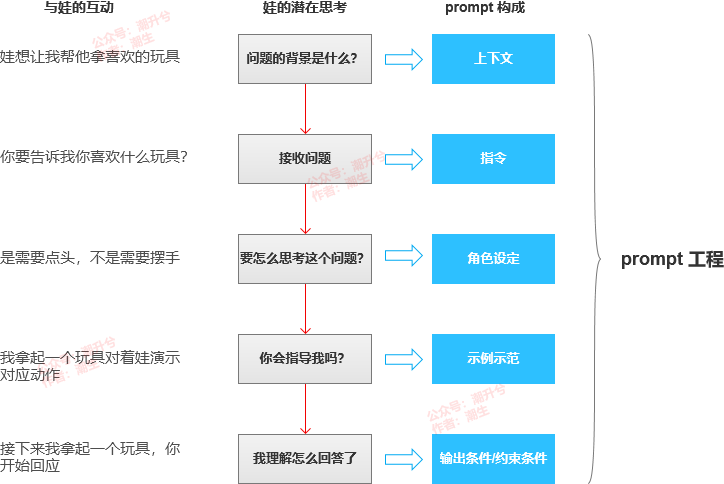
看完这里,你会不会突然发现大模型的打磨和一个孩子的成长很像?没错,你看孩子的成长其实分为三块:基因决定 + 环境影响 + 专业教育,而大模型的打磨也可以分成三块:基因决定(数据干预与参数配置) + 环境影响(自我训练或优化) + 专业教育(prompt 工程)。
也许大家也想过 AI 会替代自己而导致失业的焦虑,当我们都在关注“输出”侧的效率提升时,就会陷入“手工纺织者与纺织机拼效率”的陷阱。通过对大模型原理的深入,仍会发现针对“模型计算”相关的领域也充满着大量机会。我们还可以在大模型打磨公式的三个因子上寻找机会:你可以成为技术极客去对大模型的底层基因进行改造,让它有更多可能性;你也可以成为 AI 训练师引导大模型的人文发展,让它变得有“活人感”;你还可以参与 AI 的秩序共建,去规范安全边界让他成为一个“好人”。人类和 AI 一定是彼此共生的关系,也必须相互成全,彼此才有存在的意义。就像马歇尔·麦克卢汉说的那句话:我们塑造了我们的工具,然后我们的工具又塑造了我们。
最后,笔者再抛一个问题:除了“模型计算”、“输出”侧,“输入”侧可以做什么呢?欢迎留言互动讨论。
本文由人人都是产品经理作者【潮生】,微信公众号:【潮生兮】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


