
 起点课堂会员权益
起点课堂会员权益图像的力量从未改变,只是换了一种驾驭方式
一张图片的选择如何影响产品宣讲的效果?设计师的‘眼睛’与AI生成图像的碰撞揭示了什么?从GAN时代的‘抽卡随机性’到多模态模型的‘意图理解’,AI图像生成技术正在重塑设计工作流。本文将深入探讨设计师如何在工具迭代中保持核心判断力,以及‘知道哪张图对了’为何成为AI时代最稀缺的能力。

一张图片改变了什么
那是一次公司内部的项目宣讲,产品方向是人工智能。
宣讲 PPT 的主视觉图还没有着落。我打开图库,开始找。那种图你大概能想象:要有科技感,但不能太冷漠;要有未来感,但不能太廉价;最好有人,有温度,但又不能太普通。我翻了很久,一张一张地否掉——这张太像股票网站的配图,那张光线太硬显得廉价,这张构图重心偏了放进 PPT 会很别扭,那张颜色和整个 PPT 的色调打架。
大概翻了半个多小时,快要放弃的时候,无意间滑到了一张。
我盯着它看了几秒钟,然后直接存下来。不是因为它完美,是因为它说出了那句话——那种”这个产品是认真的,它在做一件真实的事”的感觉。冷蓝色调,光从左侧窗户打进来,人物的视线落在画面之外某个我们看不见的地方,背景虚到几乎消失。整个画面有一种安静的专注感。
后来这张图放进 PPT,宣讲当天没有人专门提起它,但没有人说”这张图不对”。对于配图来说,这就是最好的结果——它在那里,它工作了,它没有让人出戏。
做体验设计师这几年,我经历过太多次这种”翻了很久、最后一眼就对了”的时刻。每一次,那个”对了”的感受都很具体,但很难描述——不是”好看”,不是”漂亮”,而是”它说出了这个界面、这个场景应该说的那句话”。
那次宣讲之后,我开始认真想一个问题:图像的力量,到底从哪里来?是工具给的,还是人给的?这个问题,在我越来越深地接触 AI 图像生成之后,答案变得越来越清晰。
几年后,那张图可以被”生成”出来,而不只是被”找到”。但知道”哪张图对了”的那个人,还是需要存在的。
设计师的眼睛
设计师的人看图,和普通人看图,有一些微妙但关键的不同。
普通人看图,看的是”好不好看”。设计师看图,看的是”这张图在这个界面里能不能工作”。这是两种完全不同的判断方式。一张图好不好看,是一个审美问题;一张图能不能在界面里工作,是一个功能问题。设计师训练出来的,是后者。
什么叫”在界面里工作”?举几个具体的例子。一张图的光线太硬,放在卡片组件里会抢焦点,用户的视线会被图像吸走,看不到旁边的文案——这张图不工作。一张图的色温偏暖,但整个 App 的视觉语言是冷调的,放进去之后整个界面的气质会断裂——这张图不工作。一张图的构图重心在右侧,但文案是左对齐的,两者在视觉上会互相打架,用户会感到一种说不清楚的别扭——这张图不工作。

这套判断,不是我专门学来的。是做了几年设计师之后,被无数次”这张图感觉不对”的反馈训练出来的。被客户毙图,被自己否图,为一张图的色调和同事争论半小时,为了找到一张”构图重心在左侧、留白在右侧、光线柔和、色温冷暖中性”的图翻遍图库——每一次这样的经历,都在强化同一套判断标准。
这套标准,是设计师对图像最核心的能力,也是我在 AI 时代最大的财产。
这是全文最重要的一个论点,我想在这里把它说清楚:工具可以降低执行的门槛,但它降不了判断的门槛。知道”这张图在这个界面里能不能工作”的人,在任何工具时代都有资格创造图像。Photoshop 没有让这个判断变得自动,Midjourney 没有,GPT-4o 也没有。工具越强大,”说得准”的人反而越稀缺——因为当所有人都能生成图,谁能生成”对的图”才是真正的差异化能力。
图像模型的来路
要理解今天的 AI 图像生成,必须知道它从哪里出发。这段历史比大多数人想象的要长,也比大多数技术文章讲的要有意思。
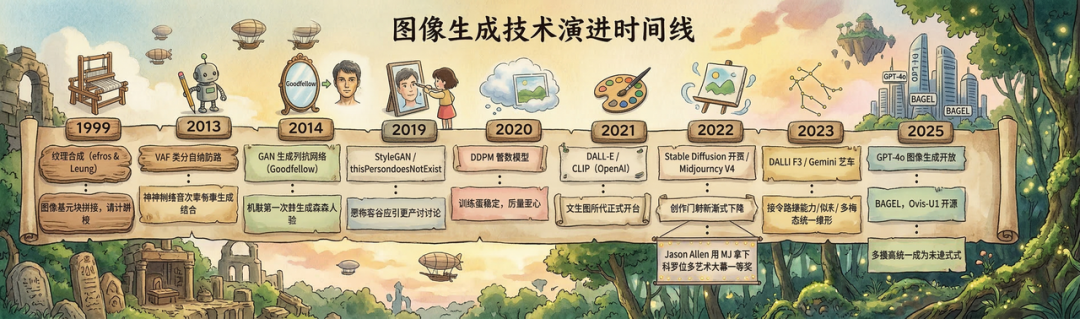
3.1 复制时代:机器只会”抄”,不会”想”
1999 年,研究者 Alexei Efros 提出了”纹理合成”方法——从已有纹理样本里逐像素复制、拼接,让图像一点点”生长”出来。砖墙、草地、木纹,机器可以模仿,可以延伸,但无法凭空创造。与此同时,研究者用 Markov Random Field 等统计模型描述像素之间的关系,将其用于图像生成与修复。
从设计师的视角来看,这个阶段的机器对图像的理解,停留在”纹理标签”的层面。它知道”砖墙长什么样”,但不知道”砖墙在这个界面里应该传递什么情绪”。这对设计来说几乎没有价值——设计需要的不是纹理,是有语义、有情绪、能在特定场景里”工作”的图像。机器只会”抄”,不会”想”。
3.2 GAN 时代:技术上真实,但对设计来说不可用
2014 年,Ian Goodfellow 提出生成对抗网络(GAN)。两个神经网络互相博弈:一个负责”造假”,一个负责”鉴别”,在不断对抗中,造假的那个越来越逼真。GAN 的出现,让机器第一次能够生成高度真实的人脸。2019 年,NVIDIA 的 StyleGAN 让这件事广为人知——网站 thispersondoesnotexist.com 让任何人都可以刷新一次,看到一张从未存在过的人脸。
我第一次看到 GAN 生成的人脸时,感受很复杂。皮肤的纹理太均匀,眼神里缺少一种说不清楚的东西,背景有时会出现奇怪的模糊和变形。这就是”恐怖谷效应”——当一个人造物太接近真实,却又不完全是真实的时候,人会产生本能的不适。
但作为设计师,我对 GAN 更根本的判断是:不可控。GAN 生成的图像有自己的”随机意志”,光线、构图、情绪全靠抽卡。你没有办法告诉它”我需要一张构图重心在左侧、色温冷暖中性、人物视线朝向右侧的图”。对设计来说,可控性比真实性更重要。技术上真实,但对我的工作来说,不可用。
3.3 扩散模型:它开始听话了
真正改变这一切的,是扩散模型的爆发。
2020 年,DDPM(去噪扩散概率模型)奠定了这一范式的理论基础。如果说 GAN 的生成过程像是一场对抗博弈,扩散模型更像一位雕塑家——从一块看似杂乱无章的”噪声石块”中,一层一层地雕刻出清晰的形状。训练更稳定,生成质量更高,而且更容易与文本结合。
2021 年,OpenAI 发布 DALL-E,文生图第一次触手可及。2022 年,Stable Diffusion 开源,Midjourney V4 发布,创作门槛断崖式下降。
这一年,还发生了一件让整个艺术界都开始焦虑的事:游戏设计师 Jason Allen 用 Midjourney 创作了一幅名为《太空歌剧院》的作品,拿下了科罗拉多州博览会美术竞赛数字艺术组的一等奖。消息一出,艺术家群体的愤怒几乎是即时的。有人说这是”创意工作的消亡”,有人说”几个关键词就能做到的事,还算不算艺术”。
我当时的感受,比愤怒更复杂一些。我第一次认真用 Midjourney,输入了一段描述,等待那张图生成出来的几十秒里,心里有一种很奇怪的东西在涌动。图出来的时候,我盯着它看了很久。光是对的,构图大致是对的,情绪也接近了。但它不完全是我想要的那张图——它是一个接近,一个草稿,一个起点。
然后我意识到:它开始听话了。不是完全听话,但它开始理解”冷蓝色调、浅景深、左侧留白”这样的指令了。对设计师来说,可控性的提升,比质量的提升更重要。这个工具,第一次进入了我的工作流候选名单。
2023 年,DALL-E 3 把文生图的指令跟随能力推上了新台阶——秘诀是用更精细的文字描述来训练模型,机器开始真正听懂人话了。
3.4 多模态统一:图像第一次有了”意图”
2023 年底,谷歌发布 Gemini,第一次把图像的”理解”和”生成”放进了同一个模型架构里。这个方向,在当时还只是一个展示,但它预示了一个根本性的转变:图像生成,不再只是一个独立的视觉任务,它开始成为多模态智能系统的一个组成部分。

2025 年 3 月,这个转变真正到来。GPT-4o 的图像生成能力正式开放,基本对齐了专用文生图工具的最高水准,同时还能做到更好的图像编辑、图文交织生成,以及利用世界知识进行推理性的图像创作——这些是单独的文生图模型无法做到的。同年,谷歌也开放了 Gemini 2.0 Flash 的原生图像生成能力,让大家第一次真正体验到原生多模态模型所能实现的图像生成。
从设计师的视角来看,这一刻意味着什么?意味着图像生成,第一次有了真正的”意图”。我可以说”这是一个健康类 App 的首页主视觉,用户是 25~35 岁的都市女性,我需要一种安静但有活力的氛围”——它能理解这个语境,然后给我一张在这个语境里”工作”的图。它不只是在生成一张图,它在理解我想说什么,然后用图像把它表达出来。
这和我当年在图库里找那张”一眼就对了”的图,本质上是同一件事。只是现在,它可以被生成,而不只是被寻找。
我现在怎么用它
从历史落回当下。我想说说,作为设计背景的 AI 从业者在 AI 时代,到底能转化成什么。
提示词的本质,是需求文档
普通用户的第一条提示词,往往是描述场景:
“画一个人坐在电脑前工作”
我的第一条提示词,是描述功能和情绪:
“这张图要放在公司官网首页的 Banner 区,公司是做人工智能的,目标用户是企业决策者,他们第一眼看到这张图,应该感受到’这家公司是认真的、有能力的’。色调偏冷,构图左侧留白给文案,人物视线朝向右侧引导用户往下看,光线柔和不要太硬”
两条指令,生成出来的图,差别很大。前者给你一张”示意图”,后者给你一张”有功能的图”。
这不是因为我掌握了什么特殊技巧。是因为我做设计师的时候,脑子里一直在跑的那套判断语言,可以直接搬进提示词里用。这套语言,设计师在写设计说明、做视觉规范、和开发沟通的时候天天在用,只是以前的使用对象是人,现在的使用对象是 AI。
设计词汇库的直接迁移
色彩与光线:warm neutral tones(暖中性色调)、cool-toned with warm accent(冷调带暖色点缀)、soft diffused light(柔和漫射光)、window light from upper left(左上方窗光)——这些不是我专门学来的,是做视觉规范时反复使用的描述词汇。
构图描述:left-heavy composition(左侧构图重心)、breathing room on the right(右侧留白)、centered subject with negative space(主体居中带留白)——做的时候,图文排版每天都在用这套逻辑。
情绪词汇:approachable but professional(亲切但专业)、calm and focused(平静专注)——这些是我在选图时脑子里一直在用的判断标准,现在变成了生成图像的指令。
一个真实的案例
公司官网首页 Banner 主视觉。需求是:体现公司的 AI 技术能力,目标用户是企业客户,第一印象要专业可信,不要太冷漠,要有人的温度。
我的第一条提示词:
A focused professional working in a modern tech environment, cool blue ambient light, soft window light from the left, shallow depth of field, left side of frame clear for text overlay, subject’s gaze directed slightly right, restrained and confident atmosphere, cinematic composition, muted color palette
生成了四个版本,第二个最接近——光线对了,构图对了,但人物的表情偏向”紧张”,和”专业可信”的调性不完全匹配。第二轮调整,在提示词里加入 calm and assured expression, not tense,第三个版本出来,直接用了。
整个过程,从写第一条提示词到确认最终图像,不超过十分钟。
这里最关键的一步,是第三步:知道什么时候”够了”。AI 生成的图像,有时候会在某一轮突然”对了”,但如果继续调整,反而会往错误的方向走。知道什么时候停下来,是一种需要被训练的判断力——而这种判断力,恰恰是设计师在日常工作中反复练习的。
驾驭它,而不是被它驾驭
图像的力量从未改变
从 Sketch 切图到 Figma 组件库,从 Figma 组件库到 AI 生成配图——设计师经历了工具的每一次迭代。每一次,都有人说”这个工具会取代设计师”。每一次,设计师都活下来了,只是工作方式变了。

从手绘到 Photoshop,从 Photoshop 到 Midjourney,从 Midjourney 到 GPT-4o——每一次工具革命,都在重新定义”谁有资格创造图像”。但有一件事从未改变:界面里的图像,必须为用户服务。它不是装饰,是信息,是情绪,是引导。这个判断标准,不会因为工具变了而自动获得。
工具可以降低执行的门槛,但它降不了”知道这张图在界面里应该做什么”的判断门槛。一张图好不好,好在哪里,差在哪里,怎么改才能更好——这套能力,不是工具给的,是长期的训练给的。
开源阵营正在追赶,战场比你想象的热闹
GPT-4o 图像生成开放之后,很多人以为这个赛道已经被几个大厂垄断了。但实际情况是,2025 年开源阵营的追赶速度超出了所有人的预期。
字节跳动 Seed 团队开源了 BAGEL——采用 MoT(Mixture-of-Transformers)架构,既使用自回归的 Transformer 进行文本与图像理解,又结合扩散模型生成图像,在多项基准测试上超越了 FLUX.1 和 SD3 等专用模型,以 Apache 2.0 协议完全开源。阿里国际推出了 Ovis-U1,仅 3B 参数量级,同样实现了理解与生成一体化,并完全开源。
这意味着,”统一多模态”不再只是闭源大厂的专利。2025 年被业内称为”全模态元年”,图像生成彻底从”独立工具”演变为”智能大脑的一个输出通道”。
对设计师的意义很直接:工具的选择只会越来越多,越来越好。但”哪个工具生成的图能放进我的设计稿”这个判断,永远需要人来做。工具的民主化,不会让”有眼光的人”变得多余,反而会让他们更稀缺。
对我来说
多模态统一之后,文字描述和图像生成会在同一个流程里发生。这对我来说,意味着”写需求文档”和”生成配图”之间的边界会消失——这不是威胁,而是一种效率的解放。写清楚”这张图在界面里要做什么”,本来就是设计师最基础的能力;现在,这个描述可以直接变成图像。
当所有人都能”说话生图”,谁能说得好、说得准、说得美,才是真正的差异化能力。提示词工程的本质,不是学会一套咒语,而是学会用语言精确地描述你的审美判断——你需要什么光线,什么情绪,什么构图,什么”感觉”。这套能力,不是工具给的,是长期的审美训练给的。
回到那次宣讲。
我在图库里翻了半个多小时,找到了那张冷蓝色调的图。它说出了”这个产品是认真的”那句话,宣讲当天没有人专门提起它,但它工作了。
我现在已经不需要翻半个小时了。我只需要把那个感觉,用语言描述出来,然后等待它被生成。
图像的力量,从未改变。变的,只是驾驭它的方式。
参考资料:本文技术部分参考了哈尔滨工业大学(深圳)苗嘉旭副教授的文章《从纹理合成到统一多模态:图像生成技术的30年变迁》(CSIG,2026年3月),以及 AI 小将的文章《GPT-4o生图发布之际,回顾视觉生成的发展历史》(2025年3月),在此致谢。
本文由 @Yeeda益达 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自作者提供






- 目前还没评论,等你发挥!


