
 起点课堂会员权益
起点课堂会员权益这只”赛博龙虾”,正在重写数据治理的规则
发布4个月GitHub星标破18万、全球安装24.8万实例,OpenClaw这只"赛博龙虾"正让AI从"顾问"变成"员工"——它能7×24小时自动稽查数据质量、动态盘点资产、追踪运行时血缘,却也带来22%企业"影子部署"、高权限通道缺乏审计、跨系统操作难回滚等新风险。

2026年的春天,科技圈最火的词不是某款新大模型,而是一只”小龙虾”。OpenClaw,这款因红色龙虾图标得名的开源AI智能体框架,发布不到四个月,GitHub星标数就突破了18万,全球安装量超过24.8万个实例。工信部、国家互联网应急中心(CNCERT)、奇安信相继发布专项风险预警,BAT纷纷下场布局……这只”赛博龙虾”,显然不只是个工具圈的热闹。
对数据治理从业者而言,这场风波的意义远不止一个新工具的流行。Claw带来的,是一种范式级别的变化——它让AI从”给建议的顾问”变成了”真正动手干活的员工”。这个转变,对企业数据资产的管控、质量保障、安全合规,乃至整个治理体系的设计逻辑,都带来了真实的冲击。
01 Claw 到底是什么?先搞清楚再谈影响
在聊它对数据治理的影响之前,有必要先说清楚Claw(即OpenClaw)究竟是什么。很多人把它和ChatGPT、Copilot之类的对话助手混为一谈,但这个类比并不准确。
传统的AI助手更像一个”智囊”——你问它,它答你,但它没有办法帮你把报告真的发出去,或者直接修改数据库里的一条记录。Claw不一样,它的核心定位是一个”无头智能体运行时”,设计上就是为了在本地服务器上7×24小时自主运行,通过MCP协议(Model Context Protocol)调用各类外部工具,真正地”动手”完成任务。
Claw 的四层核心架构:
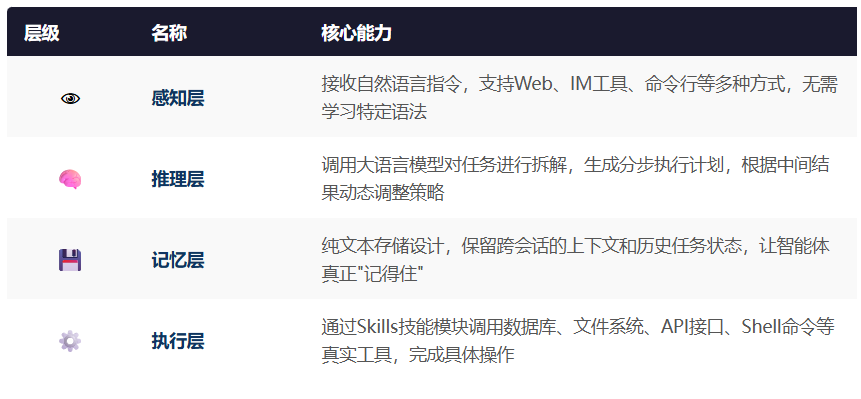
这个架构本身并不复杂,但”全流程自主执行”这件事,放在企业数据环境里,就成了一把双刃剑。
02 它给数据治理带来了什么?先说好消息
数据治理的从业者都知道,这个领域最大的痛点不是缺少方法论,而是执行成本太高。数据质量稽查要靠人工巡检,数据资产盘点要靠线下访谈,数据血缘梳理要跟着代码一行行追……Claw的出现,在若干个具体场景里,把这个成本切得很低。
数据质量管控:从”定期检查”到”持续巡逻”
传统的数据质量检查大多是批处理模式,T+1甚至T+7才能发现问题,等发现的时候下游报表已经出错了。Claw可以被配置成一个常驻的”质检员”,通过MCP协议持续连接数据仓库,按规则自动执行空值检测、格式校验、业务规则核查,发现异常立即通知,甚至直接生成问题工单。
一个典型的实际场景是:某零售企业的订单数据表每天凌晨同步,原本由数据团队每天早上手动跑SQL脚本检查。接入Claw之后,配置好检查规则,它会在同步完成后自动运行,把异常数据列表发到企业微信群,再也不用靠人”定闹钟”。
数据资产盘点:从”年度大扫除”到”动态台账”
问很多数据负责人,你们公司现在有多少张数据表,有多少字段有有效的业务含义注释,通常得到的回答是:”嗯……我们上次盘点是去年年初。”
Claw能做的,是定期爬取数据目录,自动识别新增表和字段,结合已有的文档和SQL血缘,尝试为未注释的字段生成业务描述并提交审核。它不能替代人做最终判断,但能把需要人工干预的内容从”全量”压缩到”增量+存疑项”,节省大量重复劳动。
数据血缘追踪:从”追不上”到”跑得过”
数据血缘一直是数据治理里最难啃的骨头,尤其是动态SQL和存储过程场景,传统的解析工具准确率普遍低于80%。Claw能做的是另一条路:不只解析SQL本身,而是通过持续监听数据流动事件,在运行时记录实际的数据来源和去向,建立运行时血缘图谱,补上静态分析的盲区。
一组说明问题的数字

03 坏消息:它也在制造新的治理难题
到这里,有人可能会觉得:这个工具挺好,赶紧引进。但别急,这才讲到故事的一半。Claw的高度自主性,本身就是它最大的风险来源。工信部的预警、CNCERT的通告、奇安信的分析报告,指向的问题不是偶发事故,而是结构性的安全隐患。
⚠️ 国家互联网应急中心(CNCERT)明确列出的三类风险
① 提示词注入:攻击者在网页或文档中嵌入隐藏的恶意指令,Claw读取后被诱导执行非授权操作,包括泄露系统密钥、转发敏感文件
② 误操作风险:因对用户指令的错误理解,导致删除文件、覆盖数据等不可逆操作,且缺少足够的确认机制
③ 插件投毒:第三方技能(Skills)存在恶意代码,利用Claw的高权限环境实施供应链攻击
风险一:数据主权边界模糊
Claw的设计理念是”本地优先”,但这并不等于”安全可控”。当它通过MCP协议连接企业内部数据库时,它实际上拿到了一个高权限的数据访问通道。问题在于:这个通道被谁使用、访问了什么数据、数据流向哪里,在默认配置下几乎没有审计记录。
更麻烦的是”影子部署”问题。工信部的监测数据显示,22%的受监控企业发现员工在IT部门不知情的情况下私自安装了Claw,这些未授权实例绕过了企业现有的安全管控体系,形成了大量隐蔽的数据泄露风险点。
风险二:数据操作缺乏事务回滚机制
传统数据库操作有事务的概念,出了问题可以回滚。但Claw执行的很多操作是”跨系统的复合动作”——它可能同时修改了数据库、发送了一封邮件、更新了一份Excel报表,这些动作没有统一的事务边界,一旦出现错误,回退的代价极高,有时甚至无法完全撤销。
风险三:让数据合规变得更难追溯
在GDPR、《数据安全法》、《个人信息保护法》的框架下,企业数据操作需要有完整的可审计记录。Claw的自主决策链路打破了传统的”人-系统-数据”线性访问结构,审计日志的生成和解释都面临新的挑战。当监管机构问”为什么这条客户数据被查询了三次”,而答案是”智能体自主决策的”,这显然不够。
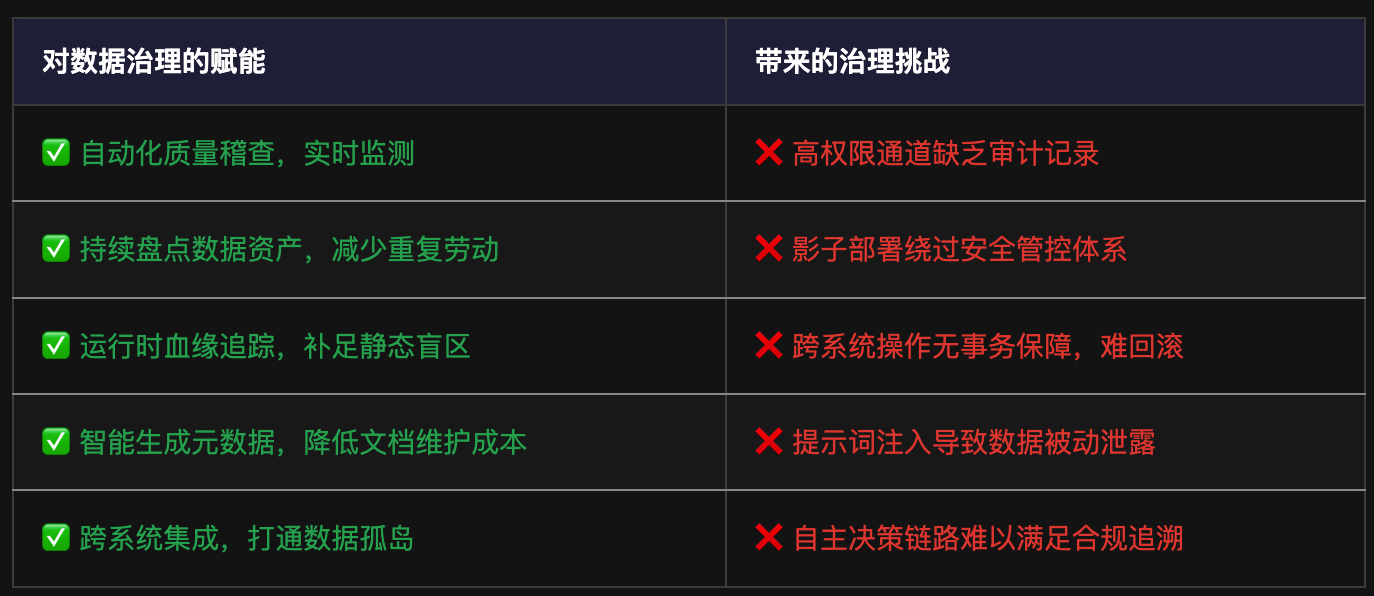
Claw 对数据治理的影响一览
04 数据治理框架需要跟着变了
面对这样的局面,有一个问题不可回避:现有的数据治理框架,是否还适用于”有自主AI智能体参与”的数据环境?
坦率地说,大多数企业的数据治理规范是在”人是唯一主动操作者”的假设下设计的。用户申请权限,审批后开放,操作留日志,定期审计——这套流程对付”人操作系统”是够的,但对付”AI代理人”,就出现了几个明显的缝隙。

这意味着数据治理团队需要在原有框架上补充几个新的模块:
一是针对AI智能体的身份管理机制,给每个部署的Claw实例分配独立的数字身份和细粒度权限;
二是智能体操作的专项审计日志标准,要能把复合操作的每一步记录清楚;
三是对智能体可访问的数据范围进行沙箱化隔离,避免它”顺手”接触到不应碰的数据。
数据是OpenClaw的粮食,没有高质量的数据,OpenClaw再聪明也发挥不出作用。但反过来,没有严格的治理,OpenClaw也可能成为最高效的数据泄露工具。
05 企业该怎么应对?几个实操方向
工信部和CNCERT已经发布了”六要六不要”的指导原则,但对于数据治理团队而言,需要从更具体的维度来考量。以下几个方向,是当前可以落地的。
第一步:清查,不要等通报
首先要摸清楚企业内部有没有已经存在的Claw部署,包括IT授权的和员工私自安装的。可以通过网络流量分析发现异常的AI推理请求,通过终端管控工具扫描是否有OpenClaw相关进程在运行。别等到安全事件发生再去盘点,那就晚了。
第二步:纳管,建立AI智能体的身份体系
类比人员IAM(身份与访问管理),给每一个经过授权的Claw实例颁发”数字工号”,明确它能访问哪些数据集、可以执行哪类操作、操作结果是否需要人工二次确认。这不是一个很新鲜的概念,但很多企业还没把它落到AI智能体这个主体上。
第三步:隔离,数据沙箱必须先建
Claw访问的数据库账号应当是只读的,除非有明确的业务场景需要写权限,而且写权限应当限制在特定的表和字段上。敏感数据(如客户个人信息、财务数据)在Claw可访问的视图层应当完成脱敏处理,不暴露原始字段。
第四步:审计,把AI操作纳入日志体系
确保Claw的每次外部工具调用都生成可检索的日志,格式应当与现有的安全审计系统兼容。一条Claw发起的操作记录应该包括:触发指令原文、推理决策摘要、实际调用的工具列表、操作时间戳、影响的数据范围。
📋 数据治理团队的优先级清单
🔴 高优先级:完成企业内部Claw实例的全面盘点
🔴 高优先级:制定AI智能体数据访问权限矩阵
🔴 高优先级:建立智能体操作日志的采集与存储规范
🟡 中优先级:对数据分类分级标准增加”AI可访问级别”标注
🟡 中优先级:评估Claw赋能的自动化质检场景,在沙箱中试点
🟡 中优先级:更新数据安全事件响应预案,纳入AI智能体相关场景
06 这不是反对,而是要驾驭它
读到这里,可能有人会觉得:这么多风险,不如别用。这个想法理解,但大概率行不通。
技术浪潮的逻辑从来不是”用还是不用”,而是”早用还是晚用”,以及”主动应对还是被动承受”。Claw这类AI智能体框架的渗透,对企业数据环境而言,更像是当年云计算或移动办公的大规模普及——你可以暂时不采纳,但你的同行可能已经在用,而且你的员工已经在偷着用了。
真正的问题从来不是技术本身危不危险,而是你有没有在它进门之前,把规矩立好。数据治理团队的价值,正在于此:不是做拦路虎,而是做好游戏规则的制定者,让Claw这类工具在企业内部发挥真正的效能,同时把风险关在笼子里。
这件事说起来容易做起来难。但有一点是确定的——2026年,不了解Claw的数据治理从业者,会比两年前不了解大数据的人更快速地感受到这种差距。
本文由人人都是产品经理作者【成于念】,微信公众号:【老司机聊数据】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


