
 起点课堂会员权益
起点课堂会员权益从Image2到Midjourney,一场血腥的技术哲学道统之争
Midjourney的美学风格曾让无数人第一次感受AI创作,但Image2正把生图从“灵感抽卡”推向“精确生产”。扩散模型从混沌中召唤秩序,自回归模型用理解来作画——文字是扩散模型永远无法愈合的伤口,不是训练不够,是架构层面的基因缺陷。

生图标准,正在被重写
用Image2几天后
我突然想到Midjourney怎样了?
AI生图圈一直以来都有个都市传说:
💡新模型三天降智,五天没热度
然后大家回到原来的工作流,该用啥用啥
但Image2不一样,用了几天之后,我意识AI生图的价值判断标准开始变了。
Image2带来的冲击不只在于“它也能画得好看”,而在于它把过去AI生图里最难受的几个问题,文字、局部修改、连续编辑、复杂指令执行、空间判断,做到了像素级别的可控性。
可控性在工作中,向来珍贵。

提示词:女生位置向前移一步,在她身后增加光源,勾勒微光剪影,女生的额头的头发减少几根
然后,我脑子里突然冒出一个问题:
💡曾经的王者Midjourney现在怎么样了?
Midjourney不死只是凋零
如果你和我一样是2022、2023年入坑AI生图的人,Midjourney几乎是你的第一站。
那种独特的、带着油画质感的美学风格,让无数人第一次感受到AI也能创作。它的商业模式也跑通了:纯靠订阅制,没有外部融资,David Holz带着一个小团队,做到了年收入过亿美元的规模。

相同提示词下,左:Midjourney7右:Image2
💡Midjourney依然在美学上体现个性
Image2能精准给出了文字信息
从2022年到2025年,Midjourney无论营收还是技术上,都是王者。
但在2025年之后,Midjourney的处境就开始变得微妙:

直到Image2出现,把灵感抽卡,向精确生产推进了一大步。这背后,其实是一场技术哲学道统之争。
道统之争:扩散模型vs自回归模型
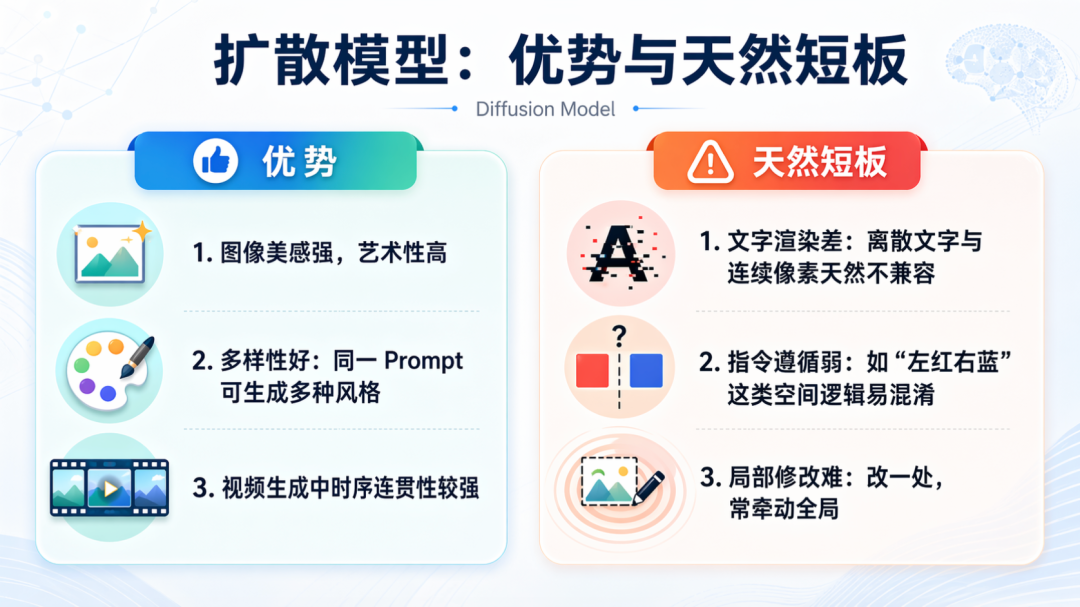
▌扩散模型:从混沌中召唤秩序
从噪声出发,一步步去噪,把秩序从虚无中凿出来。这套逻辑让扩散模型天生是美学动物,光影、构图、色彩自然协调,给它一个模糊意象,它还你一幅有灵魂的画。Midjourney、Sora、Veo、Seedance,所有叫得出名字的顶级模型,清一色是这个门派的信徒,统治AI视觉生成整整五年。
但正统有正统的原罪:文字是它永远无法愈合的伤口。这不是训练不够,是架构层面的基因缺陷,打多少补丁都治不好根。
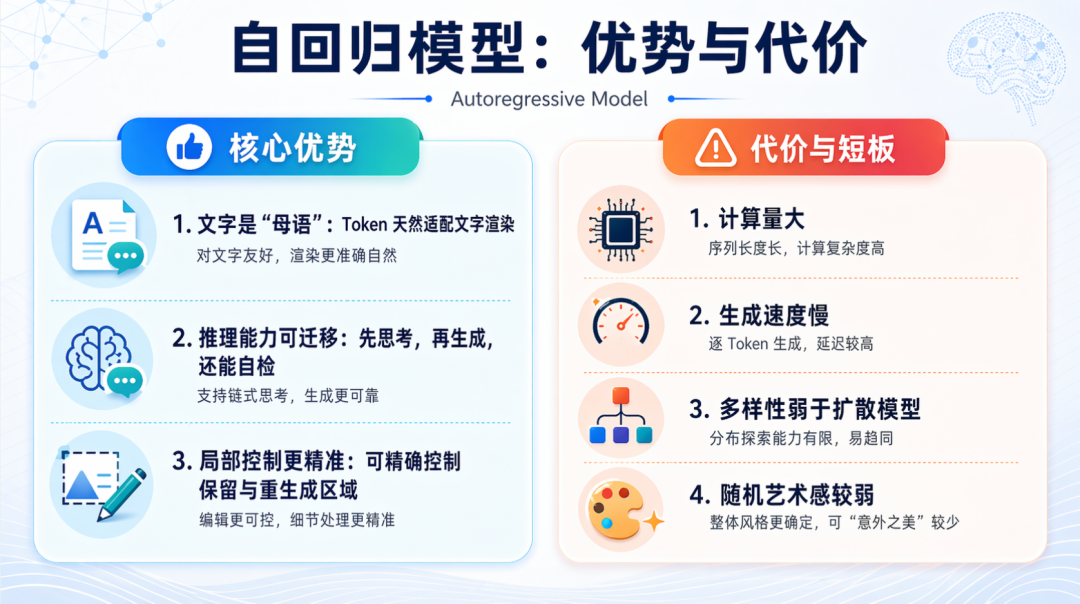
▌自回归模型:用理解来作画
GPT Image2把图像当成一种语言,像写文章一样一个Token一个Token地画出来。于是文字变成母语、GPT-4o的整个大脑直接参与作画、局部修改精准如手术刀。
它有”想”这个动作,扩散模型只有”感觉”。
扩散模型证明了机器可以有审美,自回归模型证明了机器可以有理解。Midjourney的美学护城河还在,但正被一个问题侵蚀:当理解越来越强,感觉还值多少钱?
这场道统之争,在视频领域同样在上演:但有趣的是,阵营换了位置。
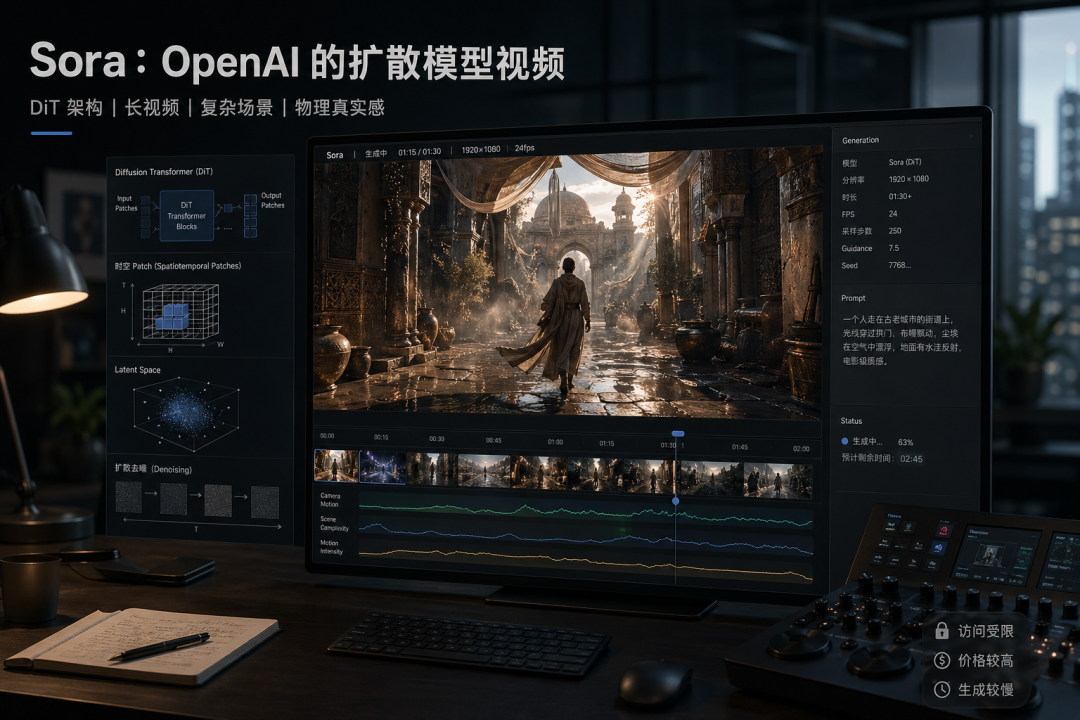
▌Sora:OpenAI的扩散模型视频
前几天被宣判死刑的Sora采用的是DiT(Diffusion Transformer)架构:扩散模型与Transformer的结合体。
它的核心思路是:把视频压缩成时空Patch(时空块),在潜空间(Latent Space)里做扩散去噪,最终还原出视频。Sora曾经的优势是长视频、复杂场景、物理真实感,能生成超过1分钟的连贯视频,场景切换自然,物理规律遵循较好。但它访问受限、价格昂贵,且生成速度较慢。
▌Seedance2.0:ByteDance的多模态扩散
Seedance2.0,大概率基于DiT扩散架构,但在此基础上做了一个关键突破:统一多模态音视频联合生成架构。
它支持同时输入最多15路混合模态:9张图像+3段视频+3段音频+自然语言,一次性生成带有同步音效的视频。
更重要的是它的两个核心能力:
•Identity Locking(身份锁定):
通过”Reference Cluster(参考簇)”机制,将角色的面部特征、服装纹理绑定到生成输出,在角色运动过程中保持视觉一致性。
•物理仿真:
能生成双人花样滑冰的高难度动作序列,冰屑飞溅、服装随动、光影折射,严格遵循真实物理规律。

▌两者核心差异对比

有意思的是:在图像领域,OpenAI用自回归颠覆了扩散模型的统治;在视频领域,双方都在用扩散模型竞争,差异在于多模态融合的深度和商业化的速度。
未来在哪里?
扩散模型和自回归模型的道统之争还远没有结束,他们之间的战场已经悄悄延伸到了下一世代:
📌生图:自回归将继续蚕食扩散模型的领地
GPT Image2已经证明,自回归架构在精确控制、文字渲染、指令遵循上有结构性优势。随着推理速度的提升和模型压缩技术的成熟,自回归生图的速度劣势会逐步缩小。
未来的生图模型,很可能走向混合架构,用自回归做语义规划和布局,用扩散模型做细节渲染和美学优化,取两者之长。
📌生视频:扩散模型短期仍是主流,但自回归化是趋势
视频生成的核心难题是时序一致性——相邻帧之间的连贯性,扩散模型在这方面有天然优势。但随着自回归模型处理更长序列的能力增强,”把视频Token化”的路线也在探索中。
OpenAI已经在尝试用统一的自回归架构同时处理图像和视频Token。这意味着未来可能出现一个模型,从同一个Prompt直接输出静图、GIF、短视频,由用户选择格式。
📌最终形态:多模态世界模型
无论扩散还是自回归,两条路最终都在走向同一个目标:
💡一个能够理解、创作、编辑整个视觉世界的多模态世界模型。
图像是它的一个输出切面,视频是另一个,3D场景、AR内容将是下一个。
当这一天到来,生图工具和生视频工具的分可能就会消失。
作者| 大先生
本文由人人都是产品经理作者【科技旋涡】,微信公众号:【科技旋涡】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。






- 目前还没评论,等你发挥!


