
 起点课堂会员权益
起点课堂会员权益90% 的 AI产品经理都在做错竞品分析(包括 4 周前的我)
当传统竞品分析遇上AI产品,三件套工具集体失灵!一位产品经理通过4周实战踩坑,揭示了SWOT、功能矩阵和六层架构在AI时代的致命缺陷——它们无法量化内容生成质量这个核心差异点。本文完整呈现从认知崩塌到重建的历程,提供3个全新分析框架、一套人机协作分工表,以及避免被反问倒的关键判断法则,为AI时代的产品经理重新定义竞品分析的本质。

连续做了 4 周 AI 竞品分析后,我发现一个反直觉的事实:传统竞品分析里最常用的三件套——SWOT、功能矩阵、六层架构——在 AI 产品身上几乎全部失效。本文复盘我从踩坑到重建框架的全过程,给出 AI 时代竞品分析的 3 个新框架、1 张人 × AI 协作分工表,以及评审时不会被反问倒的关键判断点。
一、起点:我以为我会做竞品分析
4 周前,我接到第一个 AI 竞品分析任务,需求场景是这样的:「对标一款主流 Agent 产品,评估市面上哪些模型适合接入,给出选型建议。」
我自信满满地拿出了多年的肌肉记忆:SWOT 分析、六层架构、功能矩阵图——传统 PM 的三件套,我闭着眼都能写。几天后我交出了一份厚厚的对比报告,自我感觉良好。
评审时被反问的第一句话是:「你这份报告跟分析两个 SaaS 软件有什么区别?」
那一刻我才反应过来:我用错了工具。AI 产品和传统软件的核心差异,根本不在功能多少,而在内容生成质量——而我手里所有的传统竞品分析框架,恰恰都不能量化这一点。
接下来 4 周,我又连续做了几轮 AI 竞品分析,拆解了多款 AI 产品、构建了多套评测集,才慢慢理清楚一件事:
传统竞品分析的 SWOT、功能矩阵、六层架构,在 AI 产品身上几乎全部失效。
这篇文章把这 4 周的认知崩塌和重建,整理成 3 个新框架。如果你也是从传统 PM 转 AI PM,希望你不用再花 4 周才发现这些坑。
二、第 1 个崩塌:功能矩阵图,在 AI 产品身上失效
我踩的坑
第二周,我接到一个任务:对比 4 款头部 AI 产品的「深度研究」功能(为避免具体产品测评嫌疑,下文以竞品 A/B/C/D 代称)。
我做了一张漂亮的功能对比表:
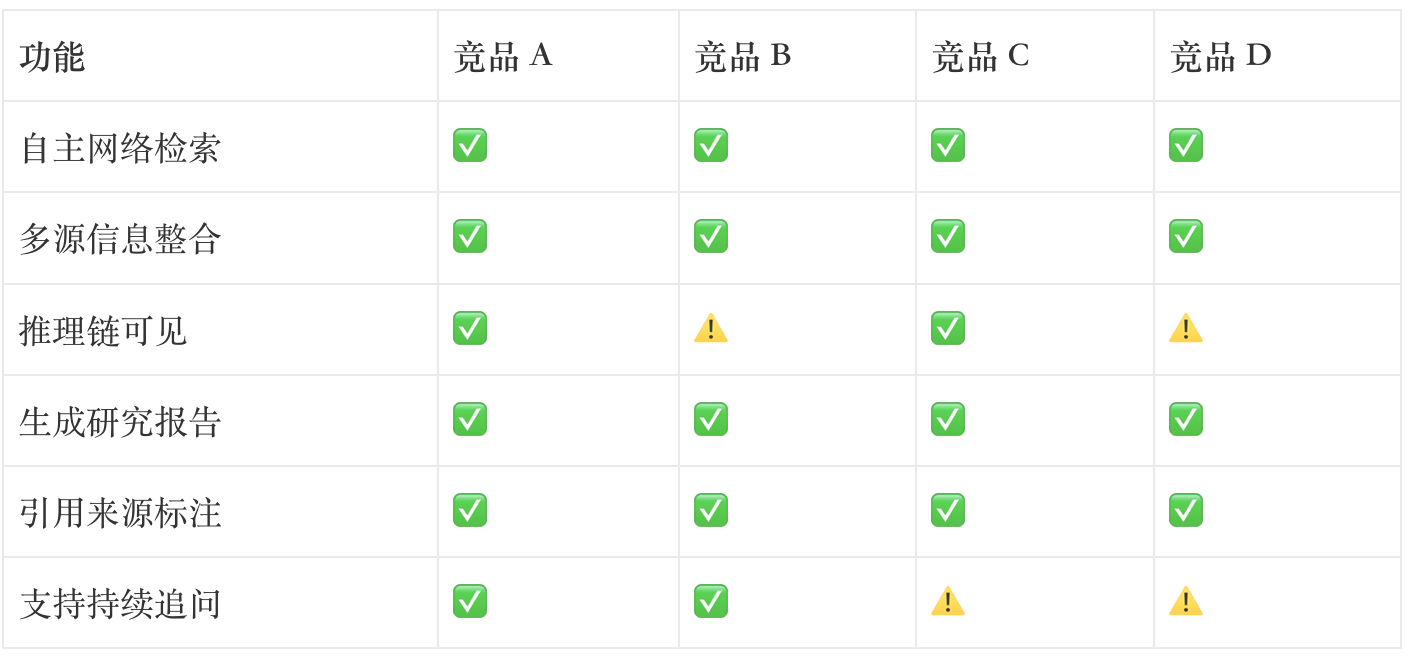
报告交上去之后,评审者皱着眉问我:「那你最后建议接哪个?」
我答不上来——因为打勾打叉的结果是:四个产品大同小异,我看不出谁更适合接入。
问题出在哪
传统功能矩阵图,统计的是「有没有这个功能」。但 AI 产品的核心差异从来不是「功能有没有」——绝大部分头部产品的功能清单都长得像同一张脸——真正的差异在「同一个功能,谁做得更好」。
而「好不好」是一个内容生成质量的问题,不能用 ✅❌ 表达。
我用什么替代
第三周开始,我把功能矩阵图改成了「内容生成质量评测表」。还是那 4 个产品的 Deep Research 功能,但评测维度换成了 5 个量化指标:
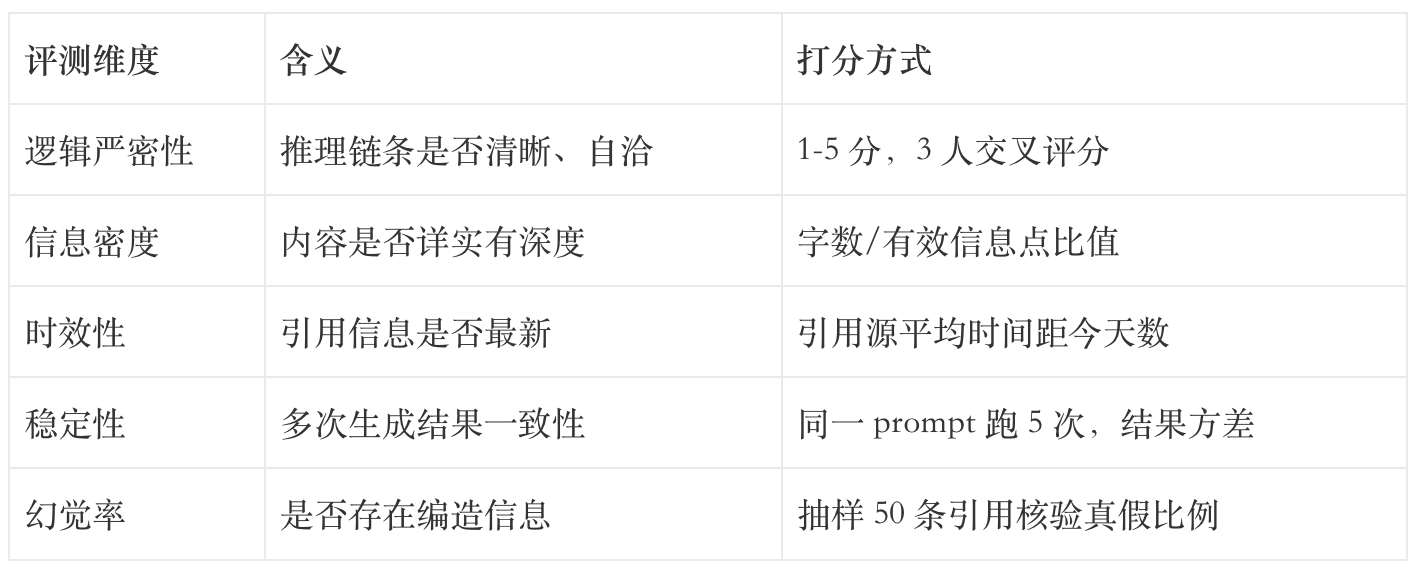
我同时构建了一个 30 题的评测集,覆盖新闻时效、金融分析、行业研究、学术综述四种典型场景,跑完之后才出对比结论。
第三周交报告时,评审者很快锁定结论:「这家产品的稳定性和幻觉率明显优于其他三家,可以重点测试接入。」对比之前那张打勾打叉的功能表,决策依据清晰多了。
「PM 视角」
功能矩阵图作为快照工具还是可以用——快速展示「市场上的产品都长什么样」——但作为决策依据它已经失效了。
AI 时代的功能对比,必须升级成质量对比。如果你交上去的竞品报告里没有「评测集 + 打分」,本质上你只是在做信息搬运,没有给决策者任何支撑。
三、第 2 个崩塌:六层架构,在套壳时代失去了信息量
我踩的坑
第二周中段,我尝试用传统的六层架构拆 4 家通用大模型厂商(同样以 厂商 A/B/C/D 代称):
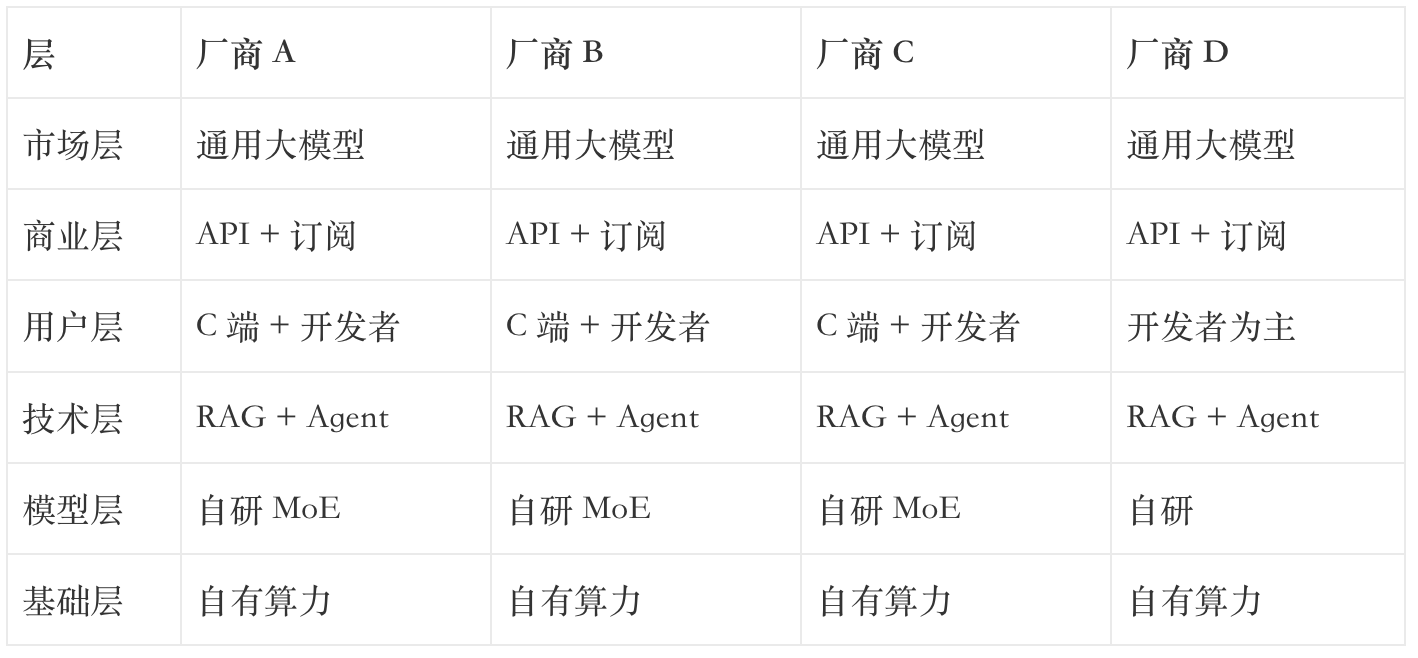
写完这张表,我盯着看了半小时——这表写了等于没写。
六层里有 4 层(商业层、用户层、技术层、模型层)几乎完全相同。剩下的市场层和基础层差异也小到看不出决策价值。
问题出在哪
六层架构是为「成熟软件赛道」设计的——它假设不同产品在每一层都有显著差异,所以横向对比有信息量。
但今天大部分 AI 产品本质上是「同一批底层模型 + 同一批向量数据库 + 同一类 Agent 框架」的不同套壳。技术层和模型层在很多赛道上已经趋同到 90% 以上的雷同度。
继续用六层对比,等于在比较「都用了同一款发动机的五辆车谁更强」——结果只能是没有结果。
我用什么替代
第三周我换成了一个新的拆解方式:四层架构 + Steps to AGI 分级。
四层架构(去掉冗余层)
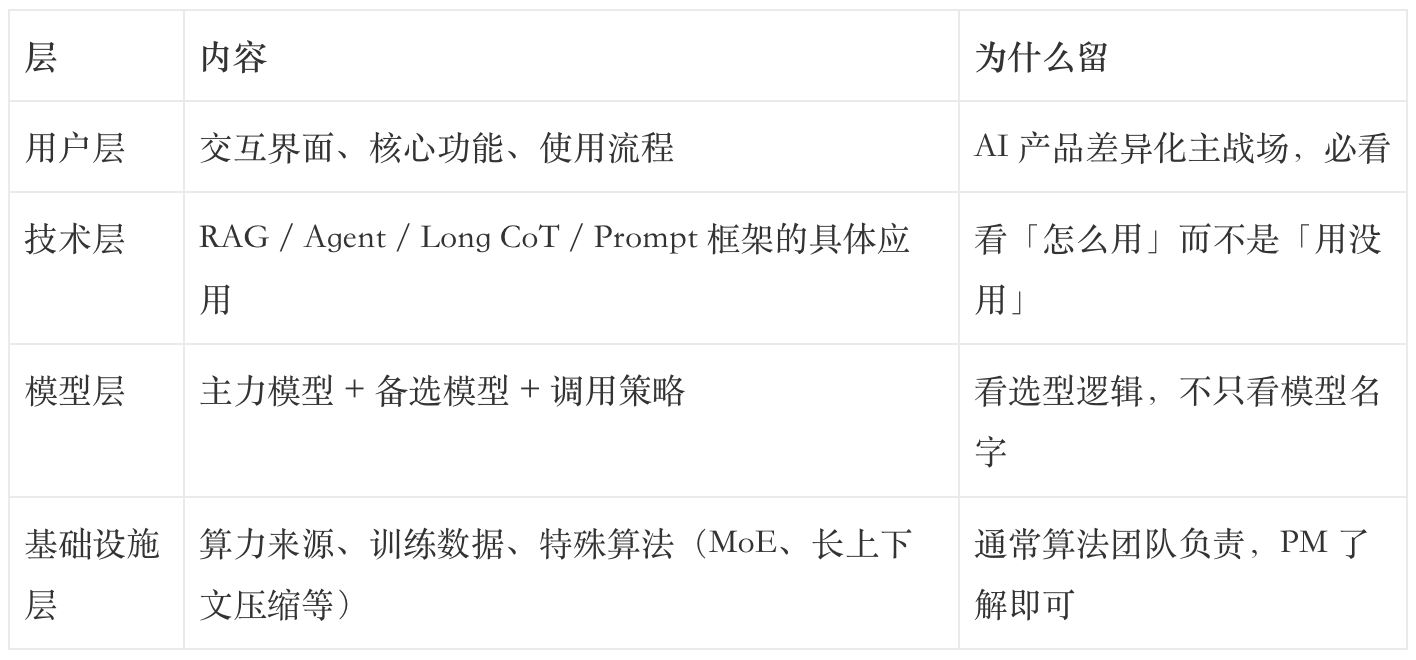
把市场层和商业层独立出来,作为「立项判断」的前置环节,而不是塞进竞品架构里。
Steps to AGI 分级(先定位竞品阶段)
这是我整个 4 周最大的认知收益。AI 产品的发展可以分成三个阶段:
- L1(对话级):以对话为核心,评测重点是「对话质量」——理解力、上下文记忆、回应自然度
- L2(推理级):能完成多步推理,评测重点是「推理深度」——逻辑链、Long CoT 表现、知识应用
- L3(任务级):自主规划并执行任务,评测重点是「任务完成度」——目标对齐、工具调用、自我修正
不同 L 级的产品,评测重点完全不同。 用 L1 的评测标准去测 L3 的 Agent 产品,约等于用「打字速度」评测一个程序员——驴唇不对马嘴。
「PM 视角」
做 AI 竞品分析前,先问一句:我和竞品都在 L 几? 这一步省的不只是时间,更是方向性的错误。
我现在的 SOP 是:先用 5 分钟把所有候选竞品按 L1/L2/L3 分类,不在同一级的直接剔除——它们不是真正的竞品,是不同物种。
四、第 3 个崩塌:跑公开榜单,不等于业务效果
我踩的坑
第一周做模型选型时,我列了一张「主流模型公开榜单成绩对照表」——MMLU、GSM8K、HumanEval、HellaSwag……一长串数字看上去专业极了。
结论部分我写道:「根据公开评测,推荐使用综合得分最高的那家模型。」
评审时被反问了一句:「那你在自己的业务场景里试过吗?」
我没试过。我只是把公开榜单的数字搬了过来。
后来在 POC 阶段做对比测试,结果完全反转:公开榜单分数最高的模型,在我们的业务场景下表现反而不如一款分数靠后的模型。原因很简单:榜单测的是通用能力,而真实业务场景往往是公开榜单根本不覆盖的细分领域。
问题出在哪
公开 Benchmark 解决的是「模型在通用能力上的相对位置」,而 AI 产品要解决的是「模型在你的业务场景里好不好用」。
这两件事经常完全无关。MMLU 高分意味着这个模型在多任务学习数据集上表现好,不代表它在你给客户写邮件、给用户做行业推荐、给法务团队审合同上一样靠谱。
我用什么替代
第四周我开始自建评测集,遵循三个原则:
- 优先采 Bad Case:从真实业务日志里捞翻车记录,AI 生成的样本只能作为补充
- 场景化拆维度:不同任务定义不同评分卡(推理类看逻辑链,生成类看流畅度,问答类看准确率)
- 人工筛选不可省:评测集最终一定要人工过一遍,AI 生成的题目大概率有偏差
模型选型不能只看分数,还要看四个维度的平衡:

最强的模型不等于最适合的模型。一款在公开榜单顶级的模型,如果业务场景是高并发、低成本的客服或推荐,选一个综合得分稍低但单价更便宜、时延更短的模型反而更合理。业务越细分,”最强”越不重要,”匹配”越重要。
「PM 视角」
公开榜单是入场券,自建评测集才是护城河。
我现在做模型选型,公开榜单只用来「剔除明显不及格」的模型,最终决策 100% 看自建评测集的结果。这个习惯让我在后续的选型评审上,明显减少了被研发同事用「你这个数据从哪来的」反问的次数。
五、4 周后我用的新框架(一张表说清楚)
把上面三个崩塌和重建总结成一张对照表:
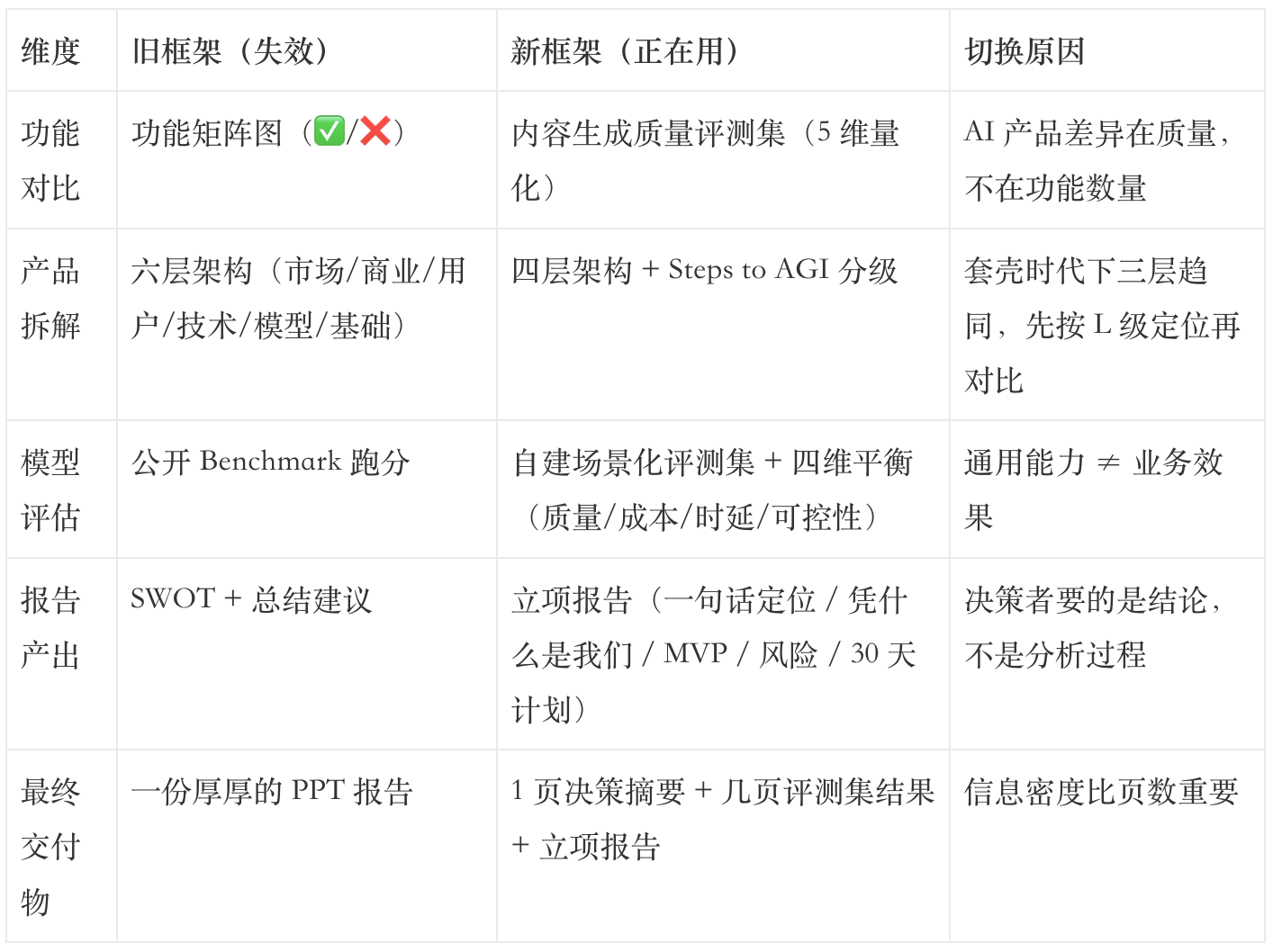
这张表是我贴在工位旁边的「4 周血泪表」。每次接到新的 AI 竞品分析任务,我会先对照一遍,确认自己用的是右边那列。
六、AI × 人在 AI 竞品分析里的协作分工
4 周里我也调整了一件事:我从「自己做完所有竞品分析」转变成「让 AI 做苦力,我做判断」。
但这件事最大的坑是:很多 PM 把判断也外包给 AI 了。AI 给什么结论就用什么结论,结果一上评审就被反问出三个「为什么」。
我现在的协作分工长这样:
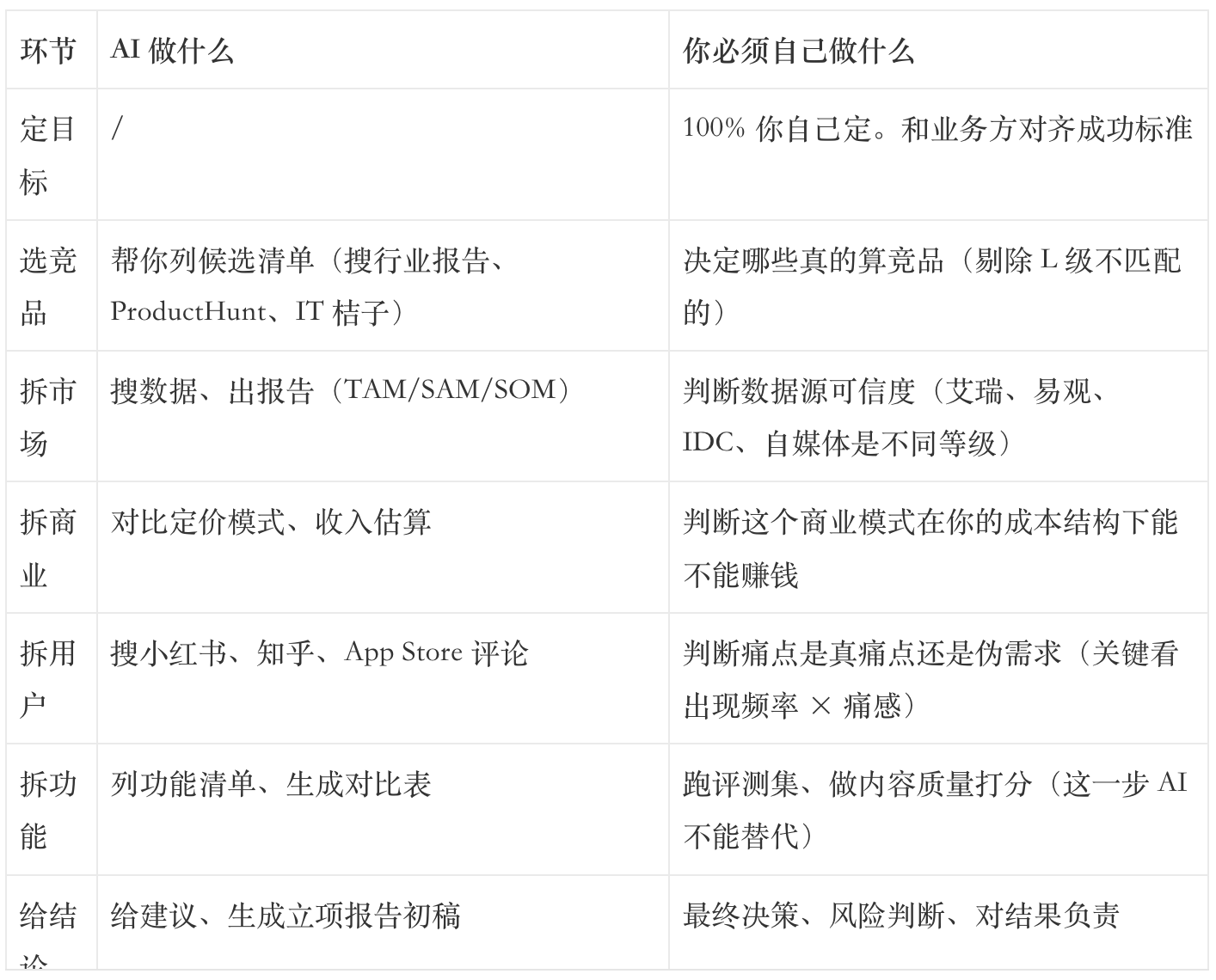
「PM 视角」
判断 AI 输出能不能直接用,我有一个简单的「三秒规则」:
如果 AI 给你的结论里,没有任何一句话需要你停下来想 3 秒以上——那这个结论大概率是套话。
真正有用的竞品分析,最终一定会出现「这一点和我的常识相反」的瞬间。如果通篇看下来都是「嗯,对,是这样」,意味着 AI 给的是平均值意见——而平均值不能成为决策依据。
七、结语:竞品分析的本质变了
4 周下来,我对 AI 竞品分析有一个最深的体感:
老竞品分析的本质是回答「我做什么 vs 别人做什么」,而 AI 竞品分析的本质是回答「我能定义什么样的内容质量标准,让自己的评测集成为护城河」。
第一种是功能视角,第二种是质量视角。第一种比的是清单,第二种比的是判断力。
也正因为这个转变,AI PM 和传统 PM 最大的差异不再是「会不会用 AI 工具」,而是「会不会做 AI 评测」——这件事很多 PM 都还没意识到,也是我观察到的、目前 AI PM 求职市场上区分度最高的硬技能之一。
如果你最近也接到 AI 竞品分析任务,给你 3 个我用了 4 周才学到的建议:
- 第一周别急着写报告,先花 3 天构建你的评测集——评测集的设计深度直接决定后面分析的天花板
- 不要相信公开榜单,自建场景化评测集是 AI PM 的基本功
- 不要外包判断,AI 是肌肉,判断是大脑
本文由 @浩子 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议






- 目前还没评论,等你发挥!


