
 起点课堂会员权益
起点课堂会员权益数据分析师手记:如何用贝叶斯检验和VIF筛选用户特征
品牌建设中,精准的用户画像往往被忽视,而这恰恰是营销成败的关键。本文通过真实案例分析,揭示盲目投放的致命陷阱,并给出从数据收集到SPSS分析的全套方法论,教你如何用科学方法锁定真正的目标用户群体,避免无效营销的巨额浪费。

作为品牌创始人,如果不知道产品受众长啥样,就像浪浪山小妖怪里的设计师一样,只能凭感觉做决策。
我见过一个美妆品牌,每个月光在小红书上种草就花了8万多块钱,结果一年下来发私信主动联系的访客却不超过5个。
当我给品牌做诊断分析后,才发现问题出在:公司上下居然没有一个人知道产品的目标用户是谁,认为只要给钱就卖,人人都是产品的用户。因为不知道目标用户是谁,所以自然不会想到在哪里能找到目标用户,以什么样的方式能说服目标用户买单。
可能有人不以为然,那么他就不会理解:为什么卖咖啡的瑞幸要花重金成立一家数据应用公司——瑞幸咖啡信息技术(厦门)有限公司,认缴金额1.3亿元,是所有子公司之最?为什么阿里巴巴要竞购星巴克的中国股权,难道卖咖啡真的很赚钱?却不知道星巴克还有700万付费会员用户。
话说回来,我又是如何帮品牌刻画目标用户的画像?
先说一个容易上手的偷懒方法,很多人都知道,就是看BCG波士顿、埃森哲、尼尔森、艾瑞等咨询公司出的市场分析和消费研究报告,半天时间就能拿到一份非常精致的用户画像。
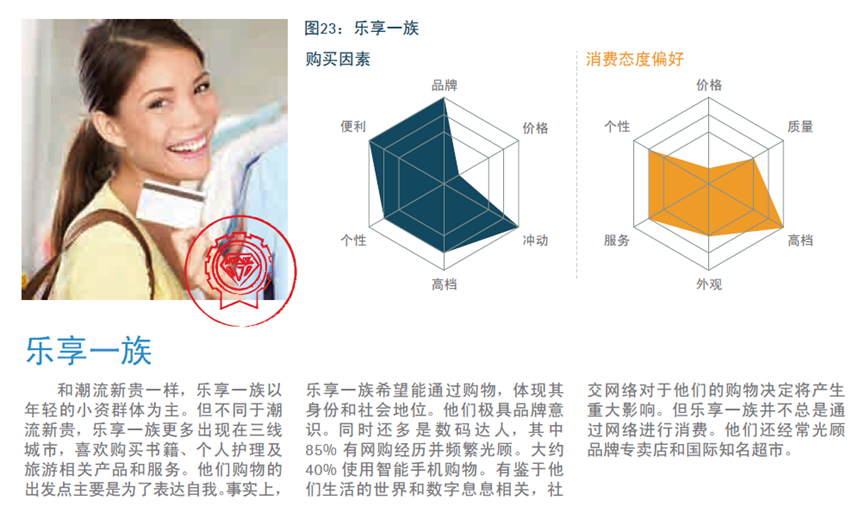
然而,当我们按这份用户画像上的标签/关键词去投广告、找用户时,可能会得到这样一种结果:那些目标用户对产品并不感兴趣,更不会为之买单。
原因是这些数据不具代表性,不能代表具体产品的真实用户特征。
为了避免有人抬扛,我有必要说明一下数据分析师的职业操守:数据搜集和统计分析所付出的成本不应超出(<)利用这些信息制定一个好决策所得到的收益,否则就是小题大做。大白话就是,如果一份用户画像能帮客户多赚10万块钱,但做这份用户画像却要花客户11万块钱,那么这份用户画像真没必要按照我说的严谨方式来做。
1、抽样方案:把咨询公司的研究报告当作参考文献,综合各家分析维度做成一份用户特征表单,表单里的每个维度都是可能影响目标用户做出购买行为的因素。虽然还不确定这些因素是否真的会影响目标用户的购买行为,但还是要尽量做得全面、细致一些,比如销量还可以再单独列项。如果最后验证不相关,还可以剔除,就怕样本不够,又要返工补充调研数据。

注:为了方便后续使用SPSS软件分析样本数据,特意对数据信息做了分类——名义型数据没有高低之分,如性别、民族;有序型数据有高低之分,但没有可比性,差距不能说明有现实意义,因为取值大小可人为规定,如学历、等级、排名;标度型数据既有高低之分,也有可比性,如温度、身高、体重。
2、数据来源:(A)回想买过/用过产品的用户有什么特征:性别、年龄、所在城市、文化程度、收入水平……(B)如果你的产品一单也没卖出去,那么可以先去观察同类产品、替代品、互补品的客户,比如你要卖猪脚饭,可以先去同行的店面踩点,看看那些顾客都是来自哪里,一个人来还是结伴而行,那些经常吃快餐的人都有什么特点,从事何种职业……(C)把自己当作目标用户,亲自体验购物过程,或者回顾自己购买同类产品的经历,想想当时自己是在什么处境下做出的购买决定,在网上下单还是到店消费,有没有先买折扣券/办会员卡……
3、样本校验:做完数据收集和量化处理后,我会扪心自问两个问题,一个是样品量够不够,能否说明销售现状?这类问题可以通过SPSS功效分析来解决——分析/功效分析/平均值/单因素ANOVA检验/填写参数,运行后就会得到每组最少需要多少个样本。如果实际每组数量≥计算值,那么样本量充足;如果实际每组数量<计算值,那么样本量不足。
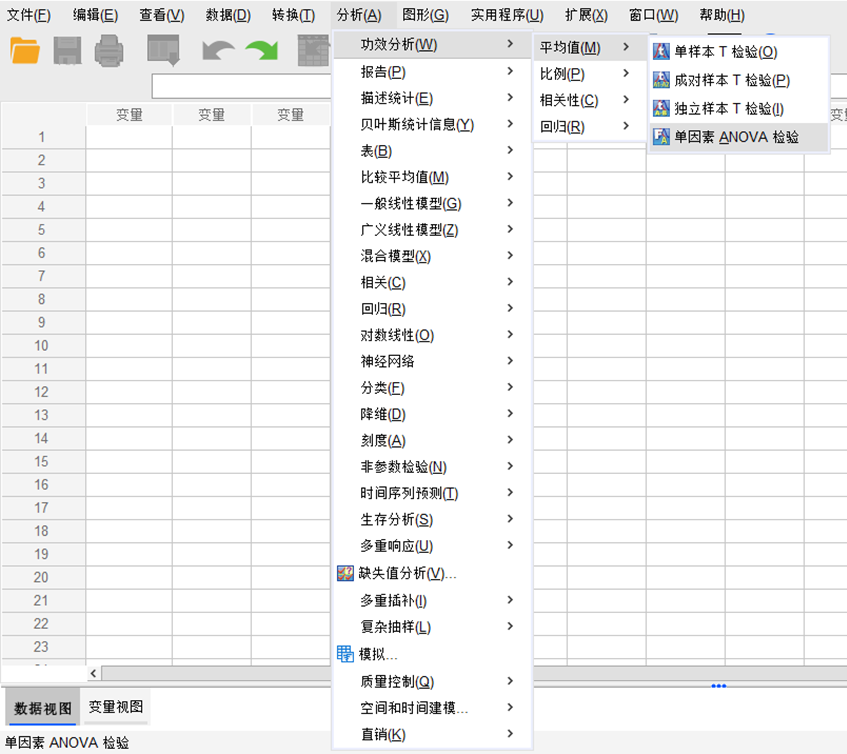
另一个问题是样本是否具有代表性,能否代表所有目标用户的特征?假如样本“歪”了,抽到的样本全是极端用户。还有,人为定义的分组是否具有真实性,客观上确实存在差异?比如消费行为相同的两个人,只是因为年龄不同,就被分到了不同的小组。这类问题可以使用SPSS单因素ANOVA检验功能来解决——分析/贝叶斯统计信息/单因素ANOVA检验/填写参数(勾选估算Bayes因子,默认先验运行;只有手握大量历史经验数据时,再自定义先验分布),运行后就会得到BF10、后验概率P、95%可信区间。如果BF₁₀>3,差异存在概率≥0.8,95%可信区间[x,y]不包括0,那么可以说明分组合理,同时侧面证明抽样正常,样本具有代表性。

4、特征筛选:既然存在样本量不足的情况,那么肯定也会存在样本量冗余的情况,这种情况体现在两个方面。一方面是样本变量和目标不相关,比如用户性别并不影响产品销量。这时,使用SPSS软件可以批量诊断样本的相关性——分析/贝叶斯统计信息/皮尔逊相关性。

另一方面是样本变量之间存在多重共线性干扰,比如可支配收入正向拉动产品销量(相关系数=0.58),价格敏感度负向抑制产品销量(相关系数=-0.49)。由于二者存在内在关联——可支配收入越低,用户对价格越敏感,若将两个变量同时纳入销量回归模型,二者各自对销量的影响会被削弱。所以,判断样本是否存在共线性非常有必要,而且是必须要做,决定了不相关变量的去留。而决策依据就是看方差膨胀因子VIF,使用SPSS软件可以快速算出——分析/回归/线性/填写参数/统计量(勾选共线性诊断)。

做完数据分析所有前置工作,接下来就可以开展经常被拿出来讨论、容易被看见的模型搭建——用户分类、寻找最大影响因子、行为归因、做销售预测等。
结束语:
每一次决策的成功绝非机缘巧合,而是蓄谋已久,只是筹划经过不被外人看见和理解罢了。所以,当你做事不敷衍、不心存侥幸,期间肯定会被人说不值得,但不要认为自己做错了。
本文由 @三匹匠 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。








瑞幸成立数据公司的例子很典型,说明用数据驱动决策不是口号。其实不止咖啡,很多消费品类如果能像这样自建画像系统,营销ROI会明显提升。
很多公司还没有数据意识,主要是数据分析投资太大了,不见得能立即看到效果。
咨询公司的报告确实有局限性,但直接否定它的价值可能有点绝对。对于初创品牌,一份行业报告至少能帮他们快速建立用户认知框架,后续再校准也不迟。
没有否定人家的价值啊,认真看,第一步抽样方案就是要找参考文献,参考行业报告的分析维度