
 起点课堂会员权益
起点课堂会员权益区块链随想录——一种设想中的公链架构

原本,这篇文章的标题是《区块链所预示的未来,需要什么样的基础设施?》,后来我反复想了好久,突然有一个有趣的念头紧紧的拽住了我,于是我完全沉迷其中无法自拔,只能放弃原来的写作内容与提纲,而是努力试图将自己的这个设想,阐述明白。当然,这还远远称不上一份白皮书!
一、区块链的本质是什么?
有人说是:分布式数据库;有人说是:分布式账本;还有人会进一步说明:就是一种以分布式方式记录账本的数据库,但是,这个数据库只能添加、读取,不能修改,删除。
在苦思冥想的过程中,我突然想到:什么“账本”呀,这完全就是一套版本控制系统。
- 除了初始提交,每一个提交都会有父提交——全部的提交历史,也构成了一个链,每一个commit,也可以说是一个block。
- 如果不经过特殊操作,所有的提交都不会消失,只会增加——区块链在这方面的限制更加严格。
所以:我们也许可以借助对版本管理系统的理解,来理解区块链。
二、联想:SVN与Git的区别
更远的版本管理系统,咱们不去提他,单说SVN与Git的区别:
SVN的版本号,是一个自增长的数字,因此,只能有一条链。

Git的版本号,是一串Hash值,不存在必须自增长的限制,因此Git的版本树形状会非常多样,通称DAG(有向无环图)。
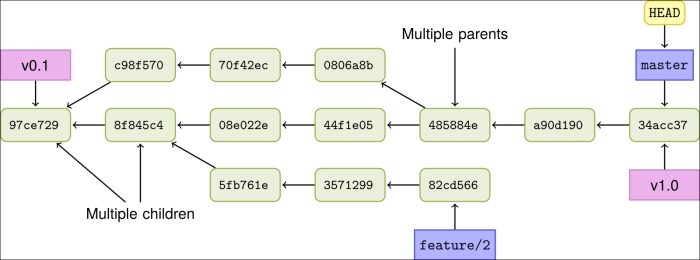
如果每一个节点,记录世界上的一批交易的话,我们就会发现SVN与Git的两种模式,存在性能上的巨大差距。因为SVN记录的交易,必须是串行的,任凭世界上同时发生多少交易,都必须依次记录!相比之下,Git的版本,就不必严格依序发生,最后的版本合并,也容易得多,这就是使得Git的并发性能,会好很多!
如果我没有理解错误的话:IOTA的DAG Tangle,应该受到Git的很多启发。
三、继续完善我们的设想——基于Git的分布式记账系统
1. 创造一个初始账户
- 建一个空的git仓库
- 创建一个root account文件,内容是:100000000
- 创建一个初始提交:init root account, 100000000
2. 新增一个账户A,并且从root得到转账
- 新建一个文件A,内容是:+20 from root
- 修改root文件,添加一行:-20 to A
- 创建第二次提交:root to A, 20
3. 如上所述,再创建第二个账户B,也从root得到转账
- 新建一个文件B,内容是:+20 from root
- 修改root文件,添加一行:-20 to B
- 创建第三次提交:root to B, 20
4. 创建一个fork仓库,包含原来的全部账本
5. 原始仓库继续发生交易
- 新建一个文件C,内容是:+20 from root
- 修改root文件,添加一行:-20 to C
- 创建第四次提交:root to C, 20
6. 在fork仓库中,发生另一次交易
- 修改A文件,内容是:-10 to B
- 修改B文件,内容是:+10 to A
- 创建一次新的提交:A to B, 10
7. 原始仓库合入fork仓库的变更
- fork仓库发起一次pull request
- 原始仓库accept pull request
- 由于两边的文件变更不存在冲突,所以合入直接完成,A向B转账的交易,也被计入主线
- fork仓库同步原始仓库的版本(git pull),fork仓库的账本同步至最新版本
四、基于Git的分布式记账系统——要点
1. 每一台Git Server,就是一个账本库
因此,一笔交易的双方,可以选择任意一台服务器,记录他们的交易。前提是:
- 这台服务器上的账本,是最新的(至少保存了交易双方账本的最新版本);
- 交易双方都信任这台服务器的记录是准确,且及时的;
- 理论上,这台服务器提供了转账与记账的服务,可以收取服务费。
2. 交易双方经过协商,可以选择任何一台服务器进行交易,并且支付费用
因此,账本服务器,存在竞争关系。理论上,以下优点将帮助交易服务器胜出:
- 交易账本数据最新最全(这是核心竞争力,否则交易速度将会变慢)
- 交易记录速度最快
- 交易费用最低(这需要一个平衡)
3. 数据同步成功率与服务可信度
为了确保自己的服务器上,拥有最新最全的数据。各家服务器都会有动力,频繁的拉取其他服务器的账本数据(git pull)。
可能存在这样的现象:A拉取B服务器的数据,但是出现了版本冲突,因为有账户x,同时在A、B记录了两笔不同的交易。理论上,需要B先拉取A服务器的数据,然后A才能成功拉取B服务器的数据。类似于我们git push之前,需要先git pull.
当A服务器拉取失败时,他有义务通知B服务器:“你的版本太老”。于是B服务器会拉取A服务器的数据。当A服务器再次重试时,拉取成功了。
于是,长期来看,A服务器拉取B服务器的数据,就会有一个成功率的记录。我们也可以记录,某台服务器,针对其他所有服务器的拉取请求,其成功率的数据。这样的数据,就代表其服务可信度。
4. 可信度最高的服务器,通常为了确保其数据的及时与准确性,需要投入大量的成本,他们的交易服务费用,也将会比较高(好的服务,当然应该贵一些)
于是:我们得到了一个良性的,分布式多中心的,交易账本系统!
五、三种交易类型与应对策略
1. 最简单的交易,就是发生在两个账户之间的
参考复式记账法,一笔交易我们至少需要同时修改两个文件,因此我们需要确保在那台git server上,两个账户文件都已经是最新版本了:
账户A说:我的账户地址是XXXX1,我的最新版本是YYYY1,你可以去以下服务器查证。
账户B说:我的账户地址是XXXX2,我的最新版本是YYYY2,你可以去以下服务器查证。
两个账户,都可以选择更加保守的策略,在更多的服务器上,互相查证对方的账户版本,是否为最新,并且最终商议出一个双方共同认可的交易服务器。
假设找不到一台服务器,同时保存了双方账户的最新版本,那就只能等待某一台服务器,最终同步到了最新的版本,然后再执行交易。
2. 对于频繁收钱,或者频繁支出的账户,如果每次都需要交易双方协调版本,那交易成本就太高了
以频繁收钱的账户为例,他可以对外公布一个自己的收款地址+服务器地址。所有的支付者,都到这个服务器上,与他交易。
付款者向指定服务器发出付款要求,指定服务器首先同步付款者的账户到最新版,交易服务器完成交易。
对于收款者而言,并发的支付请求,在交易服务器上被批量处理并记录。不必严格遵守交易的先后次序,只要最终被全部记录且数据一致即可。
频繁支出的账户,也可以按类似方式处理。
3. 从个人账户到银行账户
如果是个人对个人的交易,大家都是从我的钱包到你的钱包,这样的交易可以和具体的交易服务器无关,也可以说每次交易都可以选择任意的交易服务器。但是,如果是经常存在账户进出的情况,那么选择在某家“银行”开户,就变成很自然的事情。
过去是从个人钱包发起交易,每次选择交易记账的服务。现在变成直接委托某个交易服务器,完成进出。那么,不仅仅是完成数字货币进出,也完全可以将一部分数字货币,保存在那个“银行”里。这样当然会更加方便快捷。
后续的发展,我们可以想象:现在的银行能够为客户提供哪些服务,今后的数字货币银行,同样也有机会提供出来。
六、联想与结语
1.本文未完善之处
我没有深入去思考:如何达成信任这件事情。或者说:我认为通过算法保障信任,其实非常危险。因为绝大多数人,是无法真正理解算法,最后也只能是盲目信任。所以,信任只能来自于历史上是否清白,是否存在污点?算法公开是不够的,数据要公开,过程要公开,所有历史数据,都需要公开,这样才能够谈得上信任。
换言之,信任不是0/1的选择,信任是一个X%的事情。我对这个服务有80%的信任,于是我愿意冒着20%的风险,去使用这一服务,如此而已。
没有深入思考算法与协议的细节:为了实现一个几乎没有漏洞的架构,我现在大概只能算是完成了1%的工作,开了一个头而已。要是有朋友对于这个架构,也非常感兴趣,大家倒是可以一起研究一下。
2.未来的数字货币架构
一个逐渐完善的架构,肯定是分层、分模块,多个组件是可以组合/替换的。目前的大多数公链,都想的是打造一个完整的,全面可用的架构,我觉得他们多半都会失败。但是,有谁能够构造一个类似于TCP/IP这一的协议族呢?我非常期待!
作者:庄表伟
链接:https://www.jianshu.com/p/d2f1e9bd56ea
本文由 @庄表伟 授权发布于人人都是产品经理。未经许可,禁止转载
题图来自网络









小姐姐还懂技术呀? 🙄
非常感谢,算是有点明白了。