
 起点课堂会员权益
起点课堂会员权益白话数据产品(一)——数据仓库

数据仓库是存放收集来的数据的地方,数据仓库的特征有按时抽取、分层存储、切片存储、抽建模业务等。
数据产品的工作比较杂,从数据仓库建模,指标体系建立,到数据产品工具的设计,再到偶尔一些数据分析报告的撰写,甚至一些机器学习的预测模型都要有所了解。大公司可能每个职能都有专门的岗位来负责,小公司的话可能真的要你一条龙了。
其实数据产品从头到尾做的事情就是帮公司收集数据、存储数据、呈现数据、预测数据,拆分到具体的工作中,将会在下面介绍。
收集和存储数据:数据仓库
数据仓库是存放收集来的数据的地方,做数据分析现在一般尽量不在业务数据上直接取数,因为对业务数据库的压力太大,影响线上业务的稳定。
1. 数据收集的时间间隔
数据仓库里的数据按照数据收集的时间间隔大致分为两类:
- 一类是可以进行离线处理的数据,一般包括内部业务数据库及外部数据(比如:爬虫或第三方API);
- 一类是需要实时处理的数据,比如:内部业务日志数据。
对于第一类一般的处理多数要求在“天”级别,比如说:一天从业务数据库更新一次数据就足够了,一般采用MapReduce等批处理框架来处理数据,批处理框架在进行大量数据的计算的时候有计算资源比较廉价等优势。
而第二类实时数据处理,需要采用一些流处理框架,例如:Storm、Spark等,来处理数据,当业务发展到一定阶段,业务人员对数据的实时性要求会越来越高,也就对大数据技术团队提出了更高的要求,当然实时处理数据所需要付出的代价也是更高的。
我们要分辨清楚,哪些数据采用批处理就可以了,哪些数据是有实时处理的价值的,并不是说所有数据都实时处理就是更好,毕竟集群资源是有限的,要合理利用计算资源。
2. 数据的分层存储
另外数据仓库的数据存储是分层级的,这个架构一方面跟数据拉取方式有关,一方面也是为了对数据进行层级的抽象处理。
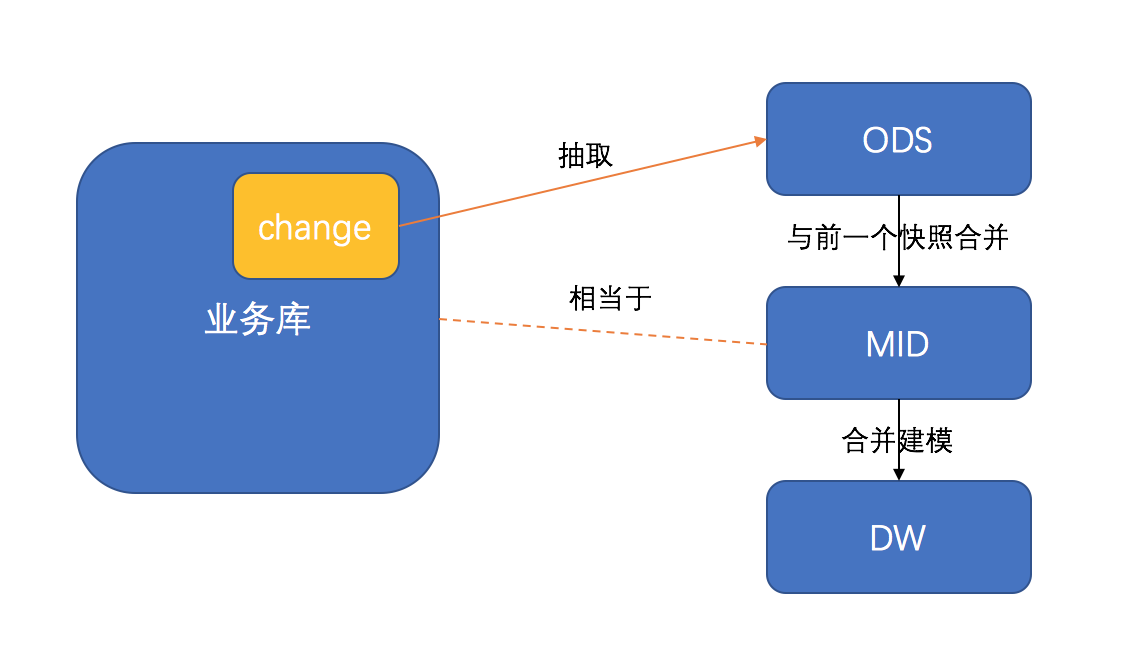
一般来说数据仓库会至少分为ODS、MID、DW三个层级,当然层级的名称每个公司可能不同,这里主要是在作用上进行区分解释。
- ODS层存储的是业务数据库在一个时间范围内新增或更新的数据,它的存储是线性增长的,有数据发生变化,ODS才会存储数据。
- MID层是经由ODS层数据计算得出的最新的完整版数据,相当于是业务数据库的一个拷贝,只不过是截止到某一个时间的。
- DW层是对MID层进行业务模型的抽象之后的合并层,将一些冗余的库表简化,做成比较利于数据抽取的库表。
因为MID层和DW层存储的都是完整的数据,业务数据库数据会不断增长,导致这两个层级里的数据每个切片的数据都是在增长,相当于是指数增长。
3. 数据的切片存储
数据库的存储是分时间戳的,相当于是把数据按照快照的方式存了n个版本,当你想追溯在某天某时间的数据的时候,就可以通过定位特定的时间戳,追溯到相关的数据。
这种设计避免了业务库数据会不断覆盖的问题,相当于是在数据分析的时候加了一个时间维度,提升了一个维度,看问题解决问题的角度也就被升华了。
4. 数据仓库建模
MID层向DW层抽象的过程,需要数据产品对业务库表进行建模。首先要清楚了解,你所要进行抽象的业务系统是什么样的(感觉数据产品好累,还要去了解别人的系统是怎么玩的╮(╯_╰)╭)。
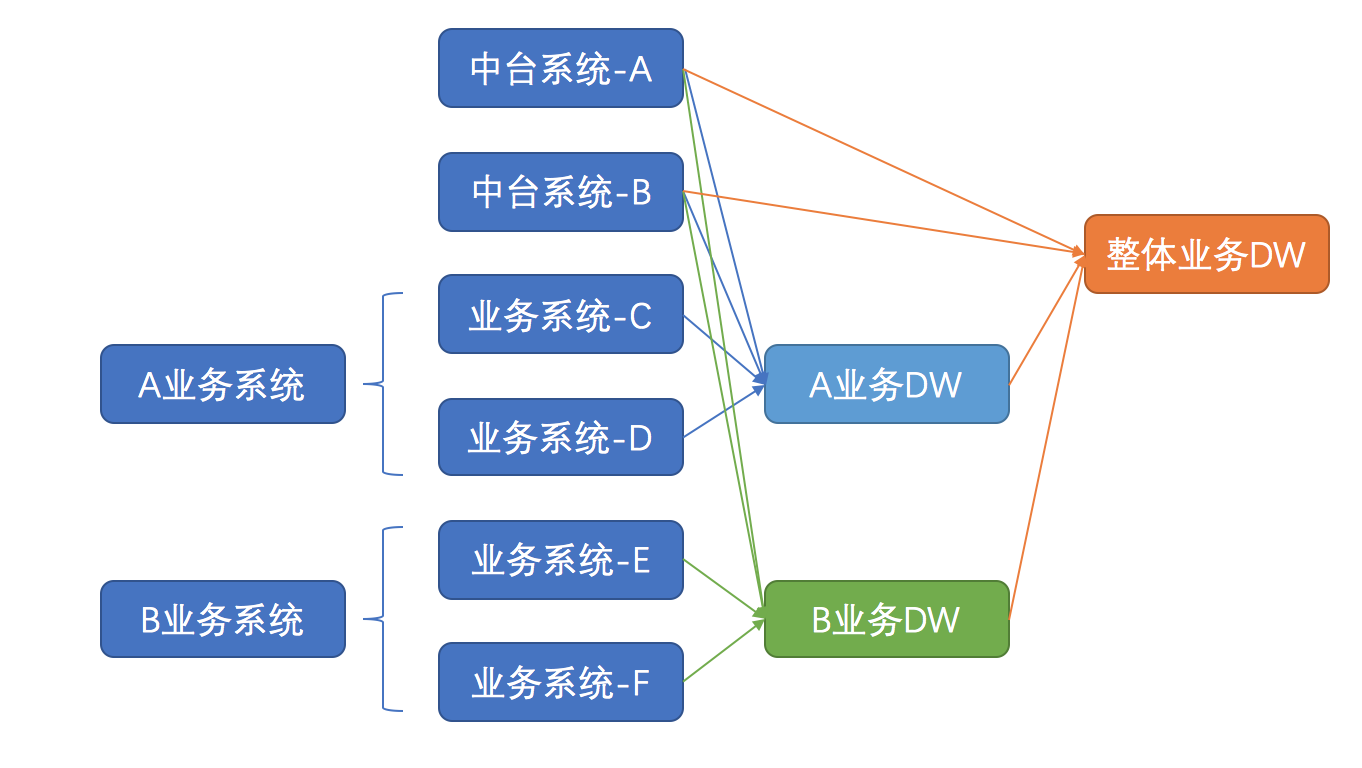
比如:你所要负责的是A业务系统的DW设计,那么首先你要把A业务系统的系统逻辑搞清楚,然后它所涉及的库表都了解清楚,包括业务本身的库表以及它所依赖的中后台系统的库表,以及各个数据库之间的关系是怎样,比如:是一对一还是一对多,当前库表是否是最细粒度的数据。
一般来说建模要做到模块互相独立,粒度统一。因为考虑到后期做指标和取数的方便,在不同粒度上都有表是比较好的。
比如:一个电商分期业务,可能在订单粒度上才能取到放款等数据,但是品类等维度又只能在商品粒度上取到(考虑到购物车,一个订单可能对应多个商品),这时候就需要两个粒度都建立对应的表才能满足不同的取数需求。
作者:小九,一枚互金数据产品
本文由 @小九 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 Pexels,基于 CC0 协议










怎么联系你,加我q2244999284
非常好,点个赞!最近刚接手广告平台的数据接入相关产品,看了一些SQL都没有你说的清楚
有点偏技术,好难懂,同产品岗😓
大家期待已久的《数据产品经理实战训练营》终于在起点学院(人人都是产品经理旗下教育机构)上线啦!
本课程非常适合新手数据产品经理,或者想要转岗的产品经理、数据分析师、研发、产品运营等人群。
课程会从基础概念,到核心技能,再通过典型数据分析平台的实战,帮助大家构建完整的知识体系,掌握数据产品经理的基本功。
学完后你会掌握怎么建指标体系、指标字典,如何设计数据埋点、保证数据质量,规划大数据分析平台等实际工作技能~
现在就添加空空老师(微信id:anne012520),咨询课程详情并领取福利优惠吧!
本来一般都会建就是有商品表和订单表啊,不知道你这是指的什么特别的
两个粒度都建立表指的是哪两个粒度各建立什么表
数仓建模的过程也是数据产品主导的吗?我们这边好像都是数据开发们主导的,产品主要focus在数据平台上面诶,是我的理解有误吗?
数据产品的工作这样的啊?感觉跟技术有很大挂钩呢。还想过转行数据产品经理岗的
“因为MID层和DW层存储的都是完整的数据,业务数据库数据会不断增长,导致这两个层级里的数据每个切片的数据都是在增长,相当于是指数增长“
你好,我想咨询下,为什么增长是指数增长,我的理解是每次只加上切片的增量数据就可以了吧
假设数据只增不改的单一场景下。对于ODS层,每增加一个切片是增加增量数据,但是对于MID层,每增加一个切片是增加了最新版的全量的数据。假设,每天稳定新增5000条数据,那ODS里面的数据总量就是5000、10000、15000…类似y=ax,但是MID层数据总量就是5000、15000、30000…类似y=ax^2+bx。
文中描述的指数增长不太准确,在这里假设的比较简单的场景下,相当于是二阶增长。
了解了,十分感谢
视频分享也欢迎大家订阅下
http://study.163.com/course/courseMain.htm?courseId=1005650014
很干货,给个赞
感谢分享