
 起点课堂会员权益
起点课堂会员权益想成为数据产品经理,先掌握这些数据分析方法论(二)
之前在《想成为数据产品经理,先掌握这些数据分析方法论》一文中,分享了一些基础的数据分析方法,从业务分析、用户分析和产品运营三个方面提供了一些分析的切入角度。接下来,进阶一步,我们再来看看还有哪些实用的分析工具。
一、业务分析:如何做诊断归因?
在《想成为数据产品经理,先掌握这些数据分析方法论》一文中分享过杜邦分析法,杜邦分析法是财务中常用的拆解指标的方法,可以将核心指标拆解为多个因素乘积的形式,如GMV=访客数*转化率*客单价。
在做完指标拆解后,应该如何进行进一步归因呢?本月GMV上涨了,是访客数增长的贡献还是转化率上升的结果,抑或是因为客单价的提升?
为此,我们需要引入另一个在财务领域广泛应用的分析方法——因素分析法。
1. 因素分析法是什么?
因素分析法是在将核心指标拆解为多个因素后,识别各因素对核心指标影响程度的一种方法。
我们将指标拆解后,当然,可以用控制变量法来计算每个因素的贡献,比如,假设上月的GMV、访客数、转化率、客单价分别为GMV0、V0、T0、M0,本月的GMV、访客数、转化率、客单价分别为GMV1、V1、T1、M1,那么
GMV0=V0*T0*M0
GMV1=V1*T1*M1
我们要判断访客数,也即流量的贡献,按照控制变量法,假设转化率和客单价与上月一样,访客数变化所带来的GMV提升为:
Attr_V=V1*T0*M0– V0*T0*M0
同样,计算转化率贡献的公式为:
Attr_T=V0*T1*M0– V0*T0*M0
这里用到的是传统的控制变量的思想,但要使用控制变量法需注意一个前提,那就是各个变量之间要相对独立,但真实情况下,各个因素之间都是相互影响的,很难保证独立性。
而因素分析法所采用的是连续替代的方法,在计算下一个因素的贡献时,会考虑到上一个因素的变化,可以有效地规避控制变量法中不独立的问题,我们具体看一下如何操作。
首先,我们在上月GMV0的基础上,用本月的访客数V1替换V0,接着再依次用T1替换T0,M1替代M0,可以得到:
上月GMV:GMV0=V0*T0*M0 ①
第一次替代V:V1*T0*M0 ②
第二次替代T:V1*T1*M0 ③
第三次替代M:V1*T1*M1 ④
而每一次替代前后的变化,就是对应因素的贡献值,即:
Attr_V=②-①
Attr_T=③-②
Attr_M=④-③
GMV1-GMV0= Attr_V+ Attr_T+ Attr_M
2. 举个栗子
下面,我们举个实际的例子来熟悉一下上述方法。
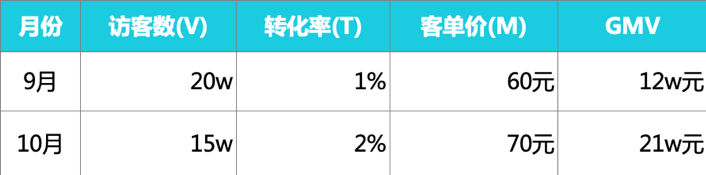
假设9月和10月的数据如下:
那么,用因素分析法依次替代后的结果如下:
9月GMV:GMV0=V0*T0*M0=12w ①
第一次替代V:V1*T0*M0=15*1%*60=9w ②
第二次替代T:V1*T1*M0=15*2%*60=18w ③
第三次替代M:V1*T1*M1=15*2%*70=21w ④
各因素的贡献率分别为:
Attr_V=②-①=9-12=-3w
Attr_T=③-②=18-9=9w
Attr_M=④-③=21-18=3w
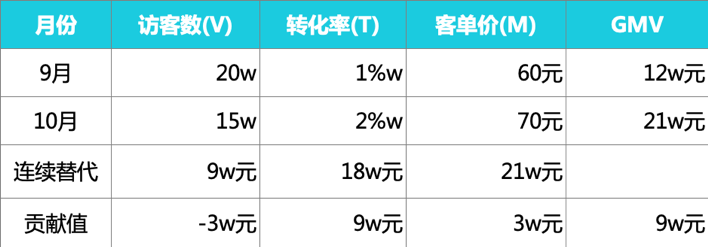
由此可见,10月的访客数较上月有所减少,导致了3w元GMV的流失,但流量显然更精准,转化率明显提升,且转化率的贡献最大,带来了9w元的GMV增量,此外,流量质量也较高,客单价有所上涨,带来了3w元的GMV提升。
因此,后续应该加强流量的引入,转化率可以分渠道进一步分析,针对高转化率的渠道进行重点运营,而客单价可以进一步分析是产品价格提升了,还是用户买的产品数量更多了。
因素分析法的作用,就在于可以找到关键的正向或负向因素,当精力或资源有限时,可以有的放矢,重点解决关键问题。
3. 替代顺序如何确定?
看到这里,不知道大家有没有发现,如果改变一下替代的顺序,各因素的贡献值会发生变化,比如,如果先替换客单价,那客单价的贡献值肯定跟上面的结果有所差异。
那么,我们应该如何保证因素分析法的有效性呢?
因素分析法是建立在某种前置假设的逻辑之下的,既然无法将各因素割裂进行分析,那么就依次考虑各因素的叠加效应,而这个次序需要遵循实际经济意义上的先后逻辑。
比如,以上述的访客数、转化率和客单价为例,自然是先有访客到访浏览,才会有下单转化,之后才会产生交易金额。也即先得有人来,来了才会决定买不买,决定买了再看花多少钱买。
同样,如果我们把GMV拆成价格*销量,那么应该先考虑价格的贡献,再计算销量的贡献,因为是先定价,才会有销量,而且销量很大程度会受到价格的影响。
二、用户分析:如何分析品牌认知差异?
网络社交媒体和电商平台中沉淀着大量的用户反馈信息,通过舆情的挖掘分析,可以为品牌商提供多角度的参考建议,指导品牌商进行产品或服务的优化。
很多品牌商都会定期找调研公司进行调研,从而了解用户对品牌的认知,以指导下一阶段的品牌形象建设或品牌差异化策略。
有很多调研的分析方法同样适用于舆情的分析,接下来就分享其中的一种——对应分析。
对应分析(Correspondence analysis)也称关联分析,是一种多元相依变量统计分析技术,是通过分析由定性变量构成的交互汇总表来揭示变量间的联系。
简单来讲,其实就是先将各类变量放到一起进行相关性分析,把关联度高的进行归类,达到降维的效果,如将为二维(两个分类),接着,再看各变量在这个二维空间中的位置,最终判断变量间的关联性。
对应分析与因子分析的差异,就在于因子分析是针对一个变量中的值进行归类,看的是相同变量的相似性,如老鹰和麻雀都可归为鸟类,而对应分析包括多个变量,还能看不同变量的关联性,如老鹰(鸟类)与食物(鼠)的关联度高,麻雀(鸟类)与谷类(食物)关联度更高。
对应分析的具体原理在此不做赘述,大家感兴趣的话可以上网查阅,接下来,我们看一看实际的例子(数据都是我编的,如有雷同,应该是抄我的)。
1. 基础入门:简单对应分析
现在,假如我们将用户的评论、反馈数据,通过切词、归类编码后,得到以下数据表:
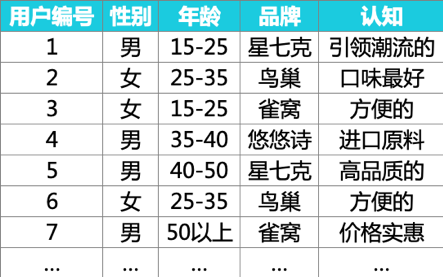
简单对应分析适用于两个变量交叉分析,我们先选“品牌”和“认知”这两个变量来进行对应分析。
在很多分析工具中都有对应分析的功能或程序包,我们以SPSS为例,在SPSS菜单中选择【分析】-【降维】-【对应分析】,选择行列分别为“品牌”和“认知”,可以得到以下摘要表:
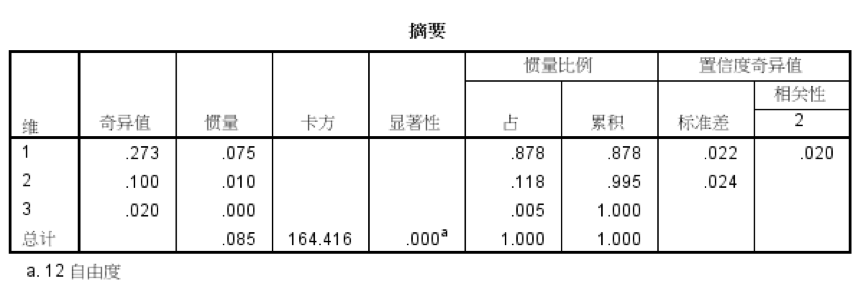
我们看到显著性sig=0.000<0.01,卡方检验通过。
然后,观察第一列“维”(也就是所谓的归类)和后面的累积惯量比例,可以看到维1和维2加起来的累积惯量比例已经达到99.5%,也即用这两个维度已经可以解释“品牌”和“认知”这两个变量中99.5%的信息。
接着,我们可以得到具体类别在这两个维度上的得分,生成对应分析图如下:
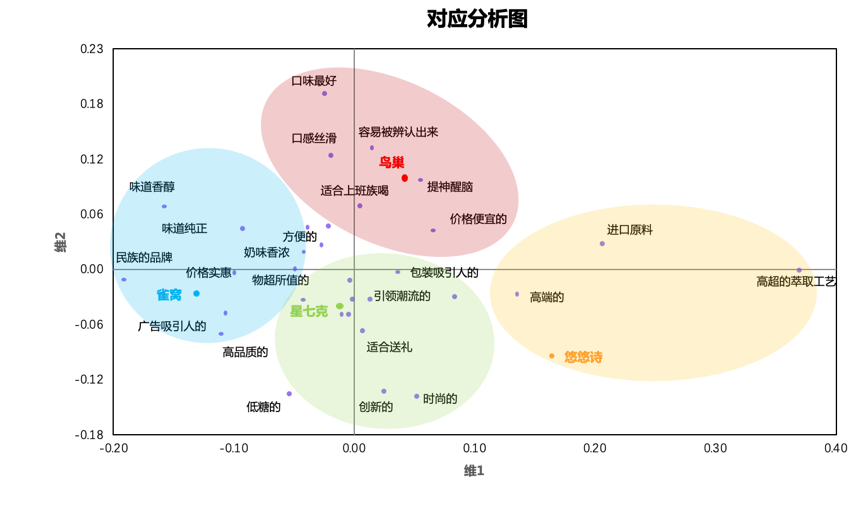
通过对应分析图分析关联性目前有多种方法,如向量分析、理想点与反理想点等。
这里我们用最简单的观察法进行定位分析,首先标出几个品牌的位置,然后观察品牌认知的形象词与品牌的距离,距离越近,说明关联程度越高。
至此,我们可以大致判断出各品牌在消费者心目中的形象。
2. 进阶拓展:多元对应分析
简单对应分析比较直观,但其缺点在于只能分析两个变量。如果我们除了分析品牌形象以外,还想看看各类型用户对于品牌认知的差异,那么就需要用到多元对应分析。
在SPSS菜单中选择【分析】-【降维】-【最优尺度】,选择分析变量为性别、年龄、品牌、认知,最终生成结果如下:

从图中可以看到,50岁以上女性更偏好悠悠诗,她们觉得悠悠诗是“高端的”。40-50岁人群更偏好星七克和雀窝。
多元对应分析的信息量相对较大,可以得到更丰富的解读,但理解较为困难,可酌情选用适宜的方式进行分析。
三、产品运营:如何评估产品功能价值?
之前的文章中讲到了评估产品使用广度、深度和粘性的指标,用来监控产品当前的使用状况。
但该方法只能适用于产品上线之后的效果评估,而在实际工作中,产品经理们还经常遇到另一类更为频繁且棘手的问题,那就是——没有资源,排不上期!
需求总是呈井喷之势,而资源始终是挤牙膏状态,产品经理平日做的最多的事就是进行需求评估,通过形(pai)而(nao)上(dai)的方法,将需求拍出,额,不对,排出优先级。
那么问题来了,我们应该怎样进行优先级的评估呢?
同样,我们可以向传统调研取取经,接下来,就跟大家分享一个方法——Kano模型。
1. 理论基础——双因素理论
在讲Kano模型之前,我们先熟悉一下这个模型的理论依据。
了解过组织行为学的同学对双因素理论肯定不会陌生,双因素即“保健因素”与“激励因素”,美国行为科学家赫茨伯格认为,满意的对立面并非不满意,而是没有很满意,而不满意的对立面也不是满意,而是没有不满意。
一段绕口令后,我们举个实际的例子,公司福利、公司政策、工作环境,这些因素容易引起员工的不满,但如果满足了这些基本条件,员工就会满意了吗?
这些在员工看来只是基本的“保健因素”,就像每天都能吃饱并不能使我们幸福一样,而个人成就、社会认同、个人成长,才是能给员工带来满足感的“激励因素”。
赫茨伯格认为“保健因素”来自于外部环境,而“激励因素”是一种内在激励,马斯洛底层的生理、安全和感情需要都可以认为是“保健因素”,而自我实现等高层需求属于“激励因素”。
说白了,放到产品的语境下,就是有的功能是必需的,但不能让用户爽,而有的功能真的可以让用户感到爽,激发用户的“Aha Moment”。
2. 研究方法——Kano模型
Kano模型的底层逻辑和双因素理论一样,在做问卷调研时,一般会问正向和负向向两个问题,即:
- 正向:有这个功能,你的态度
- 负向:去掉这个功能,你的态度
依照此方法,对于每一个功能,我们都可以收集并汇总统计用户的态度数据。
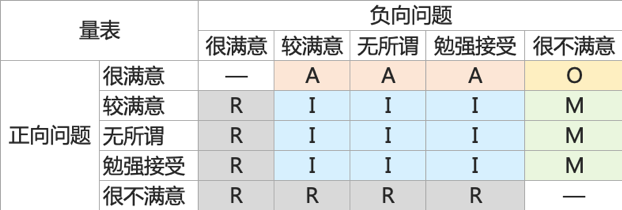
基于上面的数据统计,可以进一步计算出Better-Worse系数,表示该功能可以增加满意/消除不满意的程度。
增加后的满意系数 :(A+O)/(A+O+M+I)
消除后的不满意系数 : -1*(O+M)/(A+O+M+I)
我们将所有功能的Better-Worse系数放到一张图上,就可以对功能进行归类分析了。以手机为例,构建假数据制图如下:
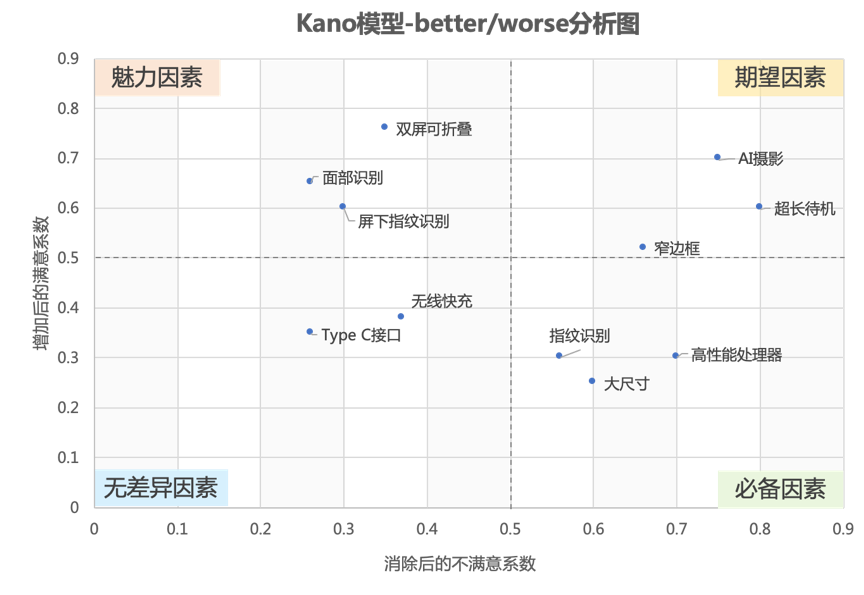
- 魅力因素:非必要需求,但可以给用户意外惊喜。
- 期望因素:用户很期望被满足的需求,没被满足的话会很失望。
- 必备因素:必要的基础需求,有的话很正常,但绝不能没有。
- 无差异因素:用户不太在乎,有没有都无所谓。
通过象限图我们可以看到,双屏可折叠等黑科技非常吸人眼球,虽然不是必需的,但却可以大大提升满意度。
AI摄影、超长待机等功能属于期望因素,跟用户的满意度有很大关系,所以很多手机品牌商不断在摄影功能、待机时长上做文章。
高性能处理器、大尺寸、指纹识别已经逐渐成为必备因素,这与行业的教育引导有关,当大家都习惯了用手机打游戏、看视频,高性能、大尺寸自然会成为必要条件。
还有一些功能虽也有所创新,但比较鸡肋,用户不太关注,如type-c接口、无线快充。
Kano模型比较适用于产品的需求调研,无论是前端产品还是后端产品,先可基于定性访谈收集需求,再收敛需求进行定量调研。
针对期望因素和必备因素,需要重点维护及迭代优化,而魅力因素属于亮点功能,有时间精力可以逐步加大投入。对于无差异因素,应当减少维护和运营的成本,甚至将功能下架。
每个功能所处的位置并不是静态的,甚至往往会随着时间推移发生很大的变化,就跟产品都有生命周期一样,功能也会有自己的生命周期,定期运用Kano模型进行产品功能分析,可以帮助我们掌握需求变化,从而指导下一阶段的产品升级。
#专栏作家#
Mr.墨叽,公众号:墨叽说数据产品,人人都是产品经理专栏作家。电商行业资深产品经理,擅长策略构建,数据分析。
本文原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议










大家期待已久的《数据产品经理实战训练营》终于在起点学院(人人都是产品经理旗下教育机构)上线啦!
本课程非常适合新手数据产品经理,或者想要转岗的产品经理、数据分析师、研发、产品运营等人群。
课程会从基础概念,到核心技能,再通过典型数据分析平台的实战,帮助大家构建完整的知识体系,掌握数据产品经理的基本功。
学完后你会掌握怎么建指标体系、指标字典,如何设计数据埋点、保证数据质量,规划大数据分析平台等实际工作技能~
现在就添加空空老师(微信id:anne012520),咨询课程详情并领取福利优惠吧!
GMV=访客数*转化率*客单价
转化率=下单数/访客数
客单价=销售额/顾客数
GMV=下单数*销售额/访客数
为啥不比对这几个呢? 🙄
怎么拆都可以,只要有经济意义。
按你的拆法,也应该是 GMV=顾客数*销售额/顾客数=销售额,绕了一圈儿回去了,
因为我这里的转化率是用户转化率,转化率=下单的顾客数/访客数。