
 起点课堂会员权益
起点课堂会员权益从数据产品经理视角,聊聊数据处理
数据处理是数据产品经理最为重要的一环,相比最后 报表展示、分析报告、数据驱动,这一环往往耗时长、体现价值低,却牵一发而动全身。我们经常会听到,同一个功能数据分析结果截然相反,追溯原因发现在数据处理过程中,存在错误等。

本篇文章将以数据产品的角度来看数据采集后数据流的处理过程;并讲解一丢丢偏技术、但与数据产品产出息息相关的数据仓库。
一. 数据处理过程
数据产品经理的工作中一大部分都是将不可估测的数据转化为可见的报表、有结论意义的分析报告——也就是将数据从各种异构的数据源中、汇总,最终展示为报表、仪表盘、动态数据分析查询、结论性的分析报告等等。
1. 有哪些异构数据源呢?
- 服务端、客户端用户行为日志
- 用户的历史信息,定性信息(e.g.性别,职业的用户画像数据),定量信息(e.g.近30天的某个兴趣倾向程度)
- 第三方等获取的信息,e.g.爬虫数据、人工整理的数据等等
2. 这信息大都需要二次加工、清洗,生成结构化的数据
- 脏数据的清洗、整合,e.g.延迟数据的按照发生日归纳;
- 生成基础性的表,以提高数据的易用性,e.g.用户基础数据、行为数据的基础表;
- 生成可以直接应用于报表、分析的用户&行为结构化业务应用表;
轻描淡写的2个步骤,却是影响报表展示、分析结论的关键点,也是数据产品经理最需要细心处理的地方。
二. 数据仓库(Data Warehouse)
数据处理过程往往比较模糊,但“异构数据源->结构化的数据表->报表/分析报告”的过程中,我们常见的各种数据库表就是数据仓库的实体,如常见的hive,spark,Oracle等。那在数据产品经理日常数据处理中应该注意哪些数据仓库知识点呢?
1. 数据仓库分层
为什么要做分层呢?
- 更清晰的管理、追踪数据(清洗的数据结构、明确的血缘关系):有助于我们去查找数据处理的整条链路;
- 通过建立通用的中间表,减少重复计算:一张通用的中间表,能够有效提供能够直接贡献于下游业务数据表,以避免每次都从原数据中产出业务数据表;
- 清晰的数据仓库分层,将能够有助于我们分解数据处理过程:将复杂的数据->业务应用,拆解成多个步骤,每一层只处理单一的步骤;
数据分层具体是指?每一层应该注意什么呢?
操作数据层(ODS,Operational Data Store):该层级的数据,最接近数据源的原始面貌(内容和粒度与原始数据一致),通常是数据源直接经过ETL后,存储于此。从原始数据到ODS层,不建议做复杂的数据清洗,以免破坏原始数据,引起不必要的排查成本。
建议仅进行——
- 将json记录的日志,映射到各字段中;
- 作弊数据的清洗;
- 数据转码:将编码映射成具有真实含义的值
- 数据标准化,e.g.把所有的日期都格式化成YYYY-MM-DD的格式;
- 异常值修复,e.g.视频播放表:(包含用户id、视频id、播主、播放时间等)。
如果一个表划分为ODS层,那么一定要确认是否将原数据的有意义字段均清洗过来。
明细数据层(DWD,Data Warehouse Detail):对ODS层做一些业务层面的数据清洗和规范化的操作,e.g.用户播放视频的日志级表;
如果一个表划分为DWD层,是否清晰、明确的记录了业务层面的明细数据?
汇总数据层(DWS, Data Warehouse Summary):依据业务需求对ODS/DWD层的数据进行了汇总,e.g.带有用户画像信息的播放视频;
如果是DWS层的表,是否能够有效、便利的服务于业务方向统计需求?
应用数据层(ADS,Application Data Store):业务需要进行的统计数据结果,e.g.各类型用户的视频播放统计。
如果是ADS层的表,是否能够得到业务需要的统计数据?
维度表(DIM):存放基础信息,如用户属性表-性别、年龄等等。
如果是DIM层的表,是否全面记录了后续分析或统计需要用的各个维度?
除了固定为分层外,当然还有临时表(TEM)。
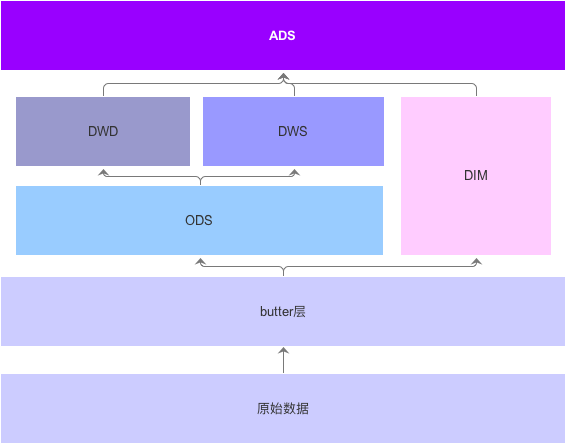
阿里/华为的数据仓库数据分级:操作数据层(ODS)、明细数据层(DWD)、汇总数据层(DWS)和应用数据层(ADS),维度表(DIM); 操作数据层、明细数据层、汇总数据层都是公共数据层。
此外,涉及表时,需要充分考虑这张表后续是哪个角色的同学使用,表是否足够易用?是否内容冗余?是否安全?
- 业务线的同学是否能够通过几条简单的SQL语句,拿到数据结果?
- 可以通过单张表格统计到数据还是需要多表关联获取?
- 单张表是不是内容冗余,是否会影响查询效率?
- 多表关联时,是否会有业务理解上的坑,e.g.多表间的字段是一对一,一对多,还是多对多,如何让使用者清晰的理解?
- 表中是否涉及敏感的字段,比如金额等,使用群体是否有足够的权限获取这些信息?
2. 元数据管理
元数据及应用也是数据仓库的重要组成部分,它是描述数据的数据(data about data),描述数据的属性信息,可以帮助我们非常方便地找到他们所关心的数据。
元数据记录了哪些信息?
- 数据的表结构:字段信息、分区信息、索引信息等;
- 数据的使用&权限:空间存储、读写记录、修改记录、权限归属、审核记录等其他信息;
- 数据的血缘关系信息:血缘信息简单的说就是数据的上下游关系,数据从哪里来到哪里去?我们通过血缘关系,可以了解到建立起生产这些数据的任务之间的依赖关系,进而辅助调度系统的工作调度,或者用来判断一个失败或错误的任务可能对哪些下游数据造成影响等等;而在数据排查过程中也可以帮助我们定位问题。
- 数据的业务属性信息:记录这张表的业务用途,各个字段的具体统计口径、业务描述、历史变迁记录、变迁原因等。
这部分数据多是我们手动填写,但却能大大提升数据使用过程中的便利性。
3. 离线数据仓库&实时数据仓库
此外,根据数据实时性,数据仓库可以分为离线数据仓库、实时数据仓库。
- 离线数据仓库主要记录t-1以上的数据,以天、周、月数据计算为主;
- 实时数据仓库是随着人们对实时数据展示、分析、算法的需求而出现的。
4. 总结
数据处理过程是数据产品经理 产出报表、分析报告耗时最久的部分,了解数据仓库的概念&关键点,有助于我们清晰、有效的处理数据,提高工作效率,将更多的时间用于业务洞察。
相关数据产品文档:
本文由 @ cecil 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 Pexels,基于 CC0 协议









大家期待已久的《数据产品经理实战训练营》终于在起点学院(人人都是产品经理旗下教育机构)上线啦!
本课程非常适合新手数据产品经理,或者想要转岗的产品经理、数据分析师、研发、产品运营等人群。
课程会从基础概念,到核心技能,再通过典型数据分析平台的实战,帮助大家构建完整的知识体系,掌握数据产品经理的基本功。
学完后你会掌握怎么建指标体系、指标字典,如何设计数据埋点、保证数据质量,规划大数据分析平台等实际工作技能~
现在就添加空空老师(微信id:anne012520),咨询课程详情并领取福利优惠吧!
👍👍👍