
 起点课堂会员权益
起点课堂会员权益web系统中,导入功能的设计要点
相对于玉树临风的功能界面,导入,显得猥琐又懒散。但对于Web系统而言,导入,有时恰是当时境况下的最优解。

一、一个漫不经心的案例
业务场景:物流供应商制定收费规则(如下图),订单发货之后,自动进行物流费用核算。
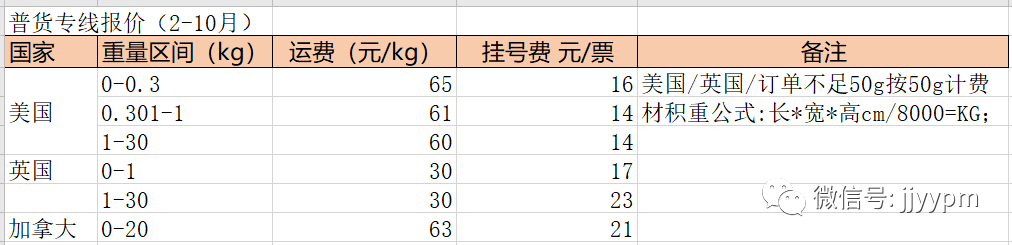
从上图可见,规则信息项包括:渠道名称、国家、是否计材积重、材积重系数、重量区间、最低起重、运算公式。
并且:
- 一个渠道,可以对多个国家 。
- 一个渠道+国家,可以有多个重量区间。
- 一个渠道+国家,只能有一个最低起重,只能一个是否计材积重、以及材积重系数。
- 一个渠道+国家+重量区间,只能有一个计算公式。
- 一个渠道+国家+重量区间+起止时间,是唯一的。
- ……
了解了以上,基本可以设置一个创建规则的结构:
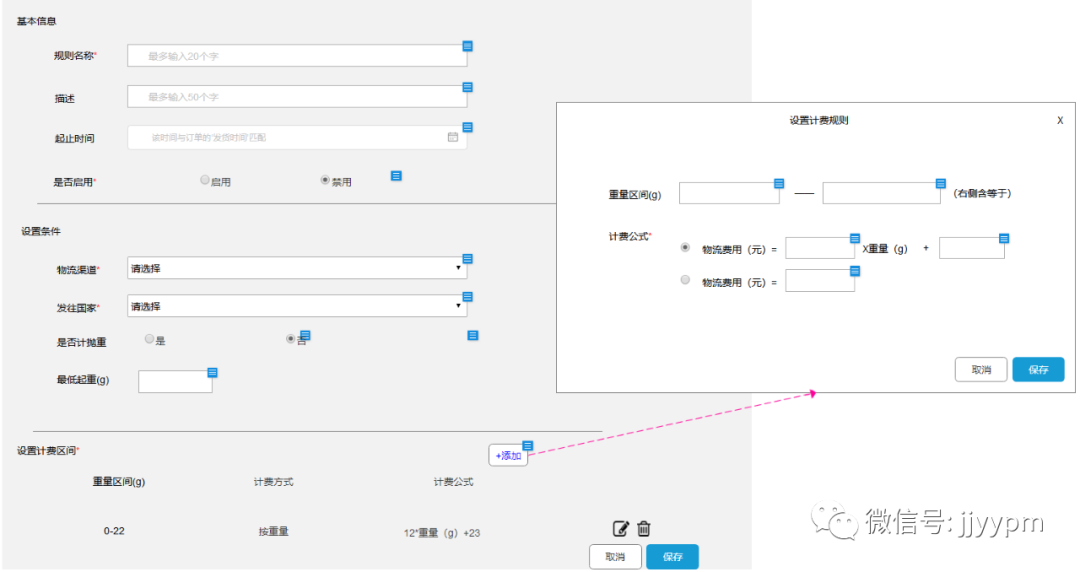
这个原型的特点之一是丑,第二个特点是存在一定量的前端交互。
但这时,出现一个客观问题——前端开发人员不够。
为了项目进度,第一版,决定采用导入的方式。
为啥呢?因为导入把页面操作都省了。
二、导入方式
在关系型数据库中(参考文章:《后端产品经理笔记之查询数据库》),数据表结构和Excel表结构相似。
所以这样的场景下,导入功能无异是短直快。
导入一般是从最小粒度开始的。一个渠道+国家+重量区间+起止时间,是最小的数据粒度。

但是看上图的表格导入,要考虑挺多问题。比如,我们知道,渠道+国家+起止时间相同的行,可以拟定为一组规则。
所谓一组,就是只有重量区间不同。那么这组拟定规则中,各行的重量区间不能有交叉:
- 与已经存在的同组规则的重量区间不能交叉;
- 起止时间不能交叉。
- 与已经存在的同组规则的起止时间不能交叉;
- 各行的最低起重要一致;
- 各行的是否计材积重一致;
- ……
整理一下要考察的项,基本和下图差不多。
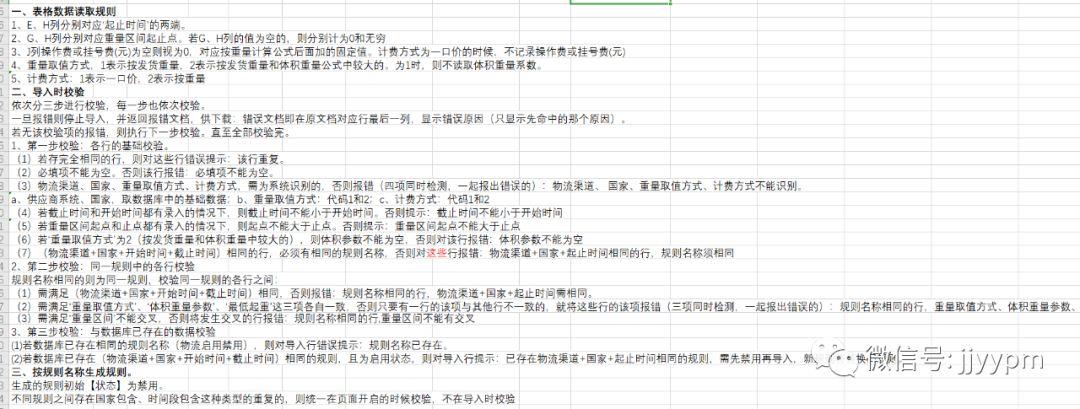
这样导入,看着没毛病,实现起来事倍功半。
首先,Excel不便于做复杂校验。
尽量做轻量校验,把数据带入系统之后,在页面承担更多工作。
其次,尽量提升数据最小粒度的颗粒度。
因为粒度一旦细致,就会倍增式地出现交叉校验。
再次,尽量在摘出具有共性的参数,导入之后再统一页面处理。
基于以上现状和方向,再次回归业务进一步掉研。如下:
业务会定期给卖家提供更新的报价方案。比如对1月份发货的订单定下了价格,结果2月出现疫情,需要涨价,于是2月修订价格,应用于2月发货的订单。而我们所说的起止时间,不是规则生效的时间,而是适用于的订单的发货的时间。
以上可以看出来,其实每一次修订,都可看做一次更新迭代。每次迭代,都可以将所有变化和未变化的都导入一遍。于是就可以将起止时间独立出来,放在最外层。也就是导入的这一批适用的订单的发货时间是一致的。
再看‘是否计材积重’。
它表达的是,一些货物是否按体积折算出重量。比如一车棉花,按实际重收费就亏了。因此,这个判断的场景一般是发货的时候,由渠道定的。
所以可以统一在导入之后,与渠道做关联。也就把这项,从导入的规则明细中剔除出来。
三、做了这个导入功能
于是导入的模板就简化为这样:

正常做:
(1)导入框:
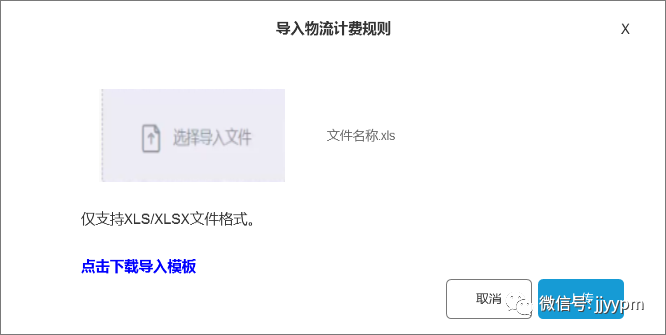
(2)校验
第一:校验导入的文件是否正确
表文件A-I是否对的上,对不上视为模板错误。直接报告文件错误,不再进入详情校验。
第二,校验内容
- 必填项不能为空
- 重量起点(g)<重量止点(g)
- 单元格内容需被系统识别或格式正确。
先判断不需要查表的项,再判断国家、物流渠道名称这些需要查表的项。
- 以A+B+C+D列判重,若存在重复的行,则对第二及其后的重复行报错.
- A+B列相同的行之间,重量区间不能交叉。
交叉的规则:假设重量区间a-b、e-f,若出现a< e<b、e < a < f、a< f<b、e < b < f任一种情况,则视为这两个区间交叉,则对第二及其后的重复行报错。
这里为啥不校验系统已存在的数据呢?
因为我们用起止时间,将这种本次导入与历史数据的重复规避掉了。具体就是:
全部校验通过,导入这一批,生成一个批次号,这个批次号需要编辑一个起止时间,这个起止时间不能与其他批次号的起止时间交叉。
这时候还余下一个参数 :是否计材积重。在编辑时间的时候进行编辑即可。如下图:
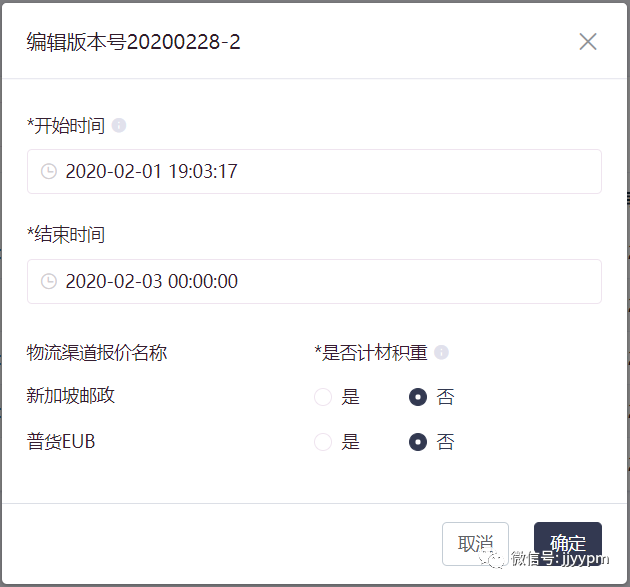
总结这个案例,物流费用规则的页面有两层:
(1)列表页:版本号维度。每成功导入一次,则生成一条对应的版本号数据。
每个版本号对应一批规则,对应同一个适用时间,因此通过版本号标定这一批规则,并将适用时间与版本号进行关联,而不与具体的规则明细关联,简单清晰。贴近业务场景。
(2)明细页:显示某一版本号下的全部规则明细。也就是导入的每一行规则。
四、姗姗来迟的小结
(1)导入的本质:
是将Excel的指定列,赋予数据库的某个字段,比如A列对应字段‘渠道名称’。
(2)导入时候的校验项很多,一条数据不止命中一个错误。
一般而言,按规则的顺序,每一行只报一个错误原因。
(3)因为可能需要反复校验多个校验项,所以依次进行,从简到难。比如:
- 优先是必填项不能为空,单元格内容格式正确。
- 然后才是核对数据是否存在于基础数据库中;
- 最后检测本次导入与已存在数的冲突性校验,比如重复。
(4)每校验一项内容,都将全部数据跑完。
比如四个校验项,100条数据。
先跑校验项1,将各行都检测完;都没错,则跑规则2,出错则报错。
下次修复后再次导入,则还是从验项一跑到验项四。
(5)导入的格式与性能有关
CSV格式的系统开心,秒传,但是用户优势不大喜欢。Excel相反。
(6)与历史数据的更新还是覆盖?这个情况让用户选了。
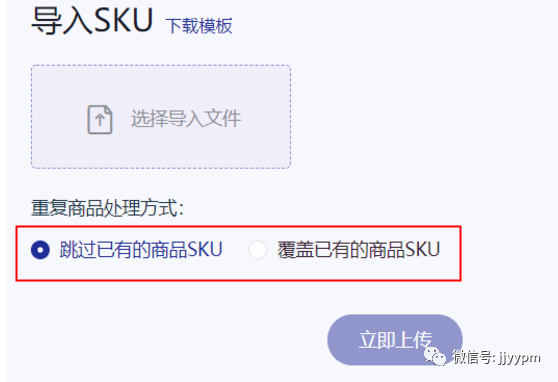
(7)一旦一条出错,是否全部不予导入呢?
一般而言,若是提交给另外的系统,那通过的基本就写入了,就没法回滚了。所以就部分正确则部分导入。
如果是自己系统,一般一旦一个写入错误,则全部回滚,全部检查,直至全部OK才写入。确保完整性。
(8)报错的方式
十几二十条就在弹框说明谁是错的就可以。过多数据的就Excel报错。
(9)Excel 模板可以做什么?
可以加表头标注,加注释说明,加第二分页。但是要开发知道。说明哪些区域是导入区。
(10)导入是猥琐的。但是也有主动使用导入的场景,比如:
从1688导出了订单的采购信息,包括物流单号等。这时候如果要把物流单号加到自己系统中去,一个个加入肯定费劲,直接导入就很快了。
另外其实案例的这个数据量上千,导入也是比较合适的。所以导入的功能是猥琐了点,但是有时候可以大用。
#专栏作家#
唧唧歪歪PM,公众号:唧唧歪歪PM(ID:jjyypm),人人都是产品经理专栏作家。书籍《后端产品经理宝典》作者,药学硕士转行互联网产品多年;熟悉跨境电商业务,医药领域;擅长大型后台体系,社交App。
本文原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议









想请问一下,如果需要导入有合并单元格的EXCEL表单,而且希望导入后页面显示也是有合并单元格的,可实现吗?
没这样设计过。
因为从设计方案层面上,出错率和开发都不太理性,宁可主动避开这种设计。欢迎关注公众号 jjyypm
学习了 。
看了半天想了想 还是做操作页面吧
有时候操作界面 满足不了。比如界面只能勾选100条 ,这货有一万条数据 。
比较硬核
谢谢 欢迎关注公众号 jjyypm