
 起点课堂会员权益
起点课堂会员权益AI产品之路:机器学习(一)

文章分享了关于机器学习的一些知识,希望能够给各位PM带来收获。
2017年可以说是人工智能爆发的一年,传统互联网红利消失,熟知的大厂BAT都在人工智能上布局,作为一名互联网PM,深知技术的变革必然带来新机会。可对大多数互联网PM而言,面对ML(机器学习)、DL(深度学习)、NLP(自然语言处理)以及的各种概念以及底层所需的各种数学知识,不懂技术似乎让人望而却步了。
可事实并非全然如此,AI是手段,最终的目的也是要找到现实中可以落地和商业化的场景,去实现他的价值,虽然目前来看仍然是技术主导。不过可以确信的一点是,要进入这个领域,对底层知识和技术的要求是必然要高于互联网PM的水平。
本人目前是一名互联网PM,刚好上学得是相关专业,有点数学底子,也层自己撸过代码设计实现“基于BP前馈神经网络的图像识别”,打算进入未来进入AI领域,最近开始重新学习并搭建AI的知识框架,希望能分享出来大家一起来了解AI这个看起来“高大上”的东西。
首先,按照李笑来老师和罗胖的说法,学一个领域的知识,就是两件事(1)找概念(2)搭框架。特别是对于很多对概念都不了解的同学,一定要有个“知识地图”,如下:
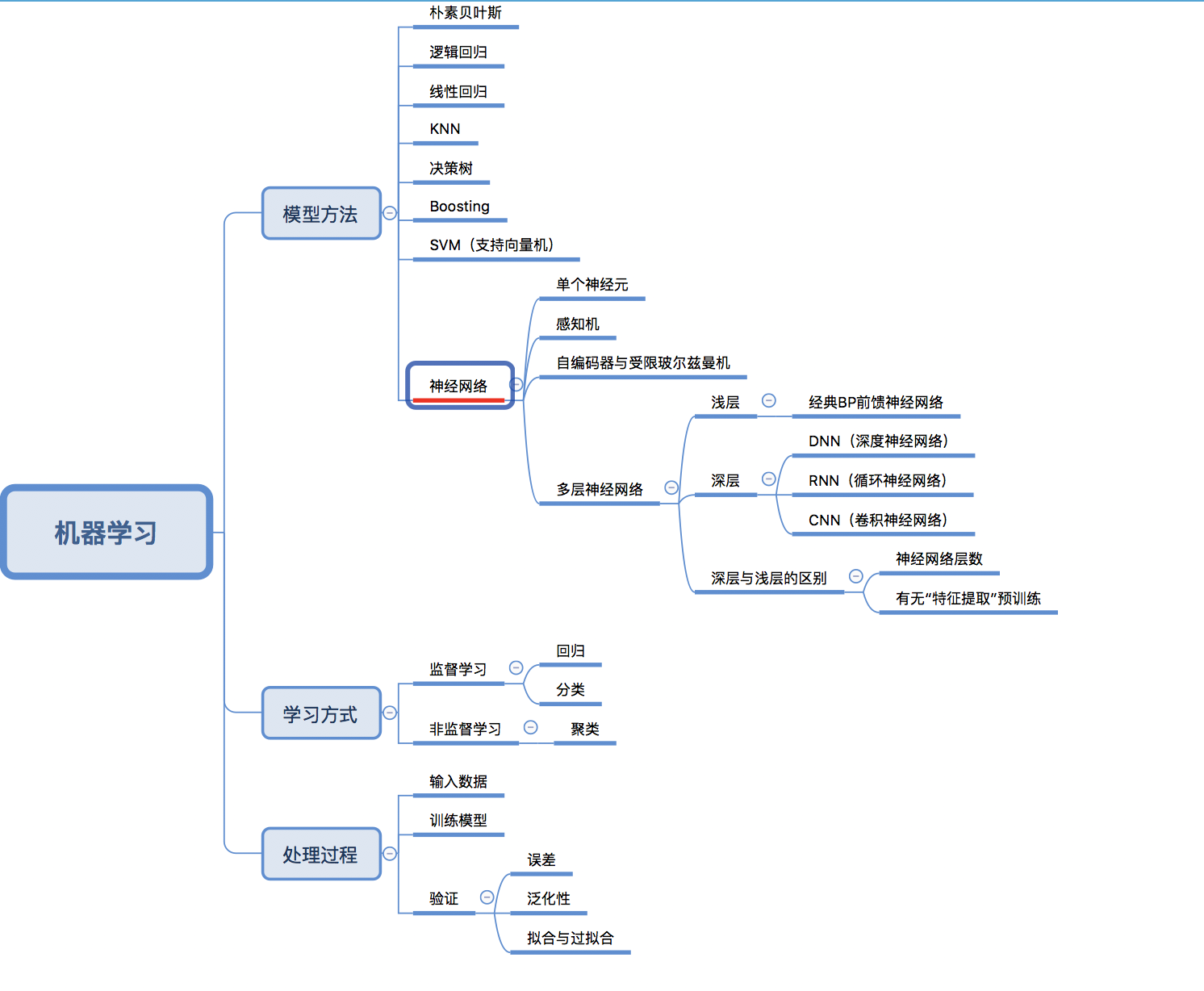
看到这个脑图,一些童鞋经常混淆的问题就明白了
- 机器学习是什么
- 深度学习是什么
- 机器学习与深度学习的区别是什么
- 机器学习监督学习方式的“回归思想”
下面我们一一来说
1.机器学习
概念定义(个人理解):通过大量已知数据(可能被标注,也可能无标注)去训练算法模型,总结出某种数据之间的映射关系(即规律),最终可以对未知数据实现智能处理(分类、识别、预测等)
举个例子,比如我这里有大量苹果和桃子的图片,并且每张图片都打上对应的种类标签,然后把这些图片喂给模型,让模型不断学习优化。训练结束后,我们又找一些没有打标签的苹果和桃子图片扔给这个模型,让他自己去做分类识别是苹果还是桃子,这就是一个完整的机器学习过程(有监督)。而所谓的“映射关系”,即“苹果图片”对应“苹果标签”,“桃子图片”对应“桃子标签”
2.基本概念
(1)学习方式
学习方式分为有监督学习和无监督学习,有监督学习即我们会再把数据给模型训练之前,进行人工的预先处理,打标签(学名:特征提取)。监督学习又分为回归与分类。
而无监督学习,就是无需通过人为的预先处理,直接把数据给算法,无监督学习对应的方法为“聚类”
(2)学习过程
- 训练集(训练样本):我们在训练算法模型时给他的数据
- 验证集:用训练样本训练好以后,我们还要用训练样本之外的数据,去检验这个算法模型的实际效果
- 误差:如何检验效果呢?在ML/DL里,就是通过“误差”的大小去判断(至于具体怎么计算,下一篇会讲到)
- 欠拟合:模型不能在训练集上获得足够低的误差
- 过拟合:训练误差与测试误差(在验证集的误差)差距过大,那么这个模型就不是好模型,因为只能用在训练样本上….而对其以外的数据都没有好的效果
- 泛化性:训练好的模型在其他数据上的使用情况,如果效果也很好,那就是泛化性好
那么问题来了,怎样才算合适的拟合呢?
其实在整个过程中,随着时间推移,算法的不断优化,在训练样本和测试样本的误差都在不断下降;但如果学习时间过程,训练集的误差持续下降,而验证集的误差却开始上升了。原因是模型为了在训练集上效果更好!已经开始学习训练集上的噪音和不需要的细节了。所以要找到合适的“拟合”,最好是找到训练误差还在下降,而测试误差刚好开始上升的那个“点”
3.机器学习与深度学习的区别
很多不知道的人,可能仅仅知道他们是包含关系,深度学习属于机器学习,但其实远远不止如此…..(这样太模糊了),从脑图可以看出,其实机器学习在方法上可以有很多种,比如:逻辑回归、决策树、朴素贝叶斯、线性回归、SVM支持向量机等,他们都属于机器学习,而我们也看到,最下面有一个“神经网络”,他们的等级与上面列举是属于一类的。
而神经网络这概念,可以分为“浅层神经网络”与“深层神经网络”
“浅层神经网络”中最经典的一个网络也就是“BP前馈神经网络”
“深层神经网络”,大概可以理解为我们所谓的“深度学习”(Deep Learning),而深层神经网络,下面又分为很多网络结构,如DNN、CNN、RNN
但这里要注意区分的是,深浅的区别不仅仅是“网络层数”的区别,更重要的是,“深度学习”(深层神经网络)较其他所有机器学习最厉害的一点:
他可以进行数据的特征提取“预处理”(省去了数据人工标注的大麻烦,同时可以对更多维和复杂的特征进行向量的提取和空间向量的转换,方便后续处理),而这也是他为什么要很多层的原因,因为其中多出来的网络层数,都是要用来进行数据特征提取预处理的
相信到一步,结合上面的脑图,我们就能分清“机器学习”与“深度学习”的真正区别了,不是简单的包含关系。
4.回归
个人觉得回归作为了解机器学习过程,是一个很好的入门了解。
所谓“回归”,看起来很深奥,其实并不是这样。我举个栗子:
y=2x这个一元函数,假设我们现在不知道他的斜率w=2,而我给你5数据y=2,4,6,8,10,对应的x分别为1,2,3,4,5。你是不是会自动假设,那他们之间是2倍的对应关系?没错!你“自动假设他们有某种对应关系”的这个过程,就叫“回归”;而你假设他们的关系是“2倍”,这就是“线性回归”了。
所以回归的定义(个人理解):我们看到大量事实或数据中,假设他们之间存在着某种对应关系。而机器学习中的回归(监督学习)要做的就是:尝试去让计算机找到大量数据之间这样的对应关系,那怎么找呢?
我们先假设一个关系吧:y=wx+b ,其中 w为权值、b为偏置,w为1Xn矩阵向量,x为nX1的矩阵向量(这几个概念就不做数学解释了,而为什么x不是实数而是矩阵,那是因为我们在现实世界的数据中,可能有N多个维度….而不仅仅是一维就可以描述这个数据特征的)
现在我要评判一个橘子的“好坏程度”,y代表“好坏程度”,而且都是打过标签的。x为一个三维矩阵向量分别代表【大小、颜色、形状】。那么代入公式:
y=w1X大小+w2X颜色+w3X形状+b (这里先假设b为0吧)
那么现在的任务就是分别找到合适的w1,w2,w3的值来准确描述橘子的“好坏程度”与“大小、颜色、形状”的关系。那么怎样确定是否合适呢?
通过“损失函数”Loss来定义(这里数学公式就不列了),Loss的含义就是把样本中所有x都代入“假设公式”wx+b中(这时候w与b的值几乎肯定是不准确的),然后得到值与真实的y值做比较的差值,就是损失函数Loss。那么Loss越小,说明这时候的w与b的值越接近真实的“线性关系”。所以我们最终机器学习的目的,就是求解出让Loss越小(当然无限接近于0最好)的对应的w与b的值,求出来之后,也就是机器学习模型“训练结束”!之后就是用验证集去验证是否会过拟合,来检验模型的泛化能力
当然这里要做几点说明了:
(1)这只是最为最为简单的一个机器学习栗子说明,着重了解一下机器学习中回归的基本思想
(2)这里我们并没有说怎么去寻找让Loss最小(或符合条件)的对应w与b的映射关系,后面我在分享“BP前馈神经网络的梯度下降时”会简单介绍这个求解基本思想过程
(3)如果你分析的数据本身是非线性关系,而你假设他们是线性关系并用对应的模型去训练,那么结果一定是“欠拟合”的(所以对于欠拟合的一另一个表达:你的想法不符合这个世界的现实…)
上面的关于机器学习的一些基本概念的分享,后续持续更新,希望能和大家一起走在AI的路上!
本文由 @ Free 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自PEXELS,基于CC0协议









感觉线性代数都丢回去了,咋办
在看tensorflow文档时候,一起看你写的真是帮了大忙了!
对于训练集和验证集我有不同的看法,验证集往往是从训练集中抽取的一部分为为最优模型输出做验证,模型出来用训练之外的数据测试模型的数据叫测试集
对,验证集还是有标签的只是没有输入,测试集才是真正类似真实需要去得到结果的新数据
瞬间觉得大学时期学的高数还是有作用的! ➡
不是高数,是线性代数吧 😎