
 起点课堂会员权益
起点课堂会员权益语音交互科普:AI能和你语音聊天吗?

为什么会有语音交互?它适用于什么场景?不适用于哪些?文章为你解读。
什么是语音交互
在没有机器之前,人类最早的交互方式就是语言和动作。如今,在自然交互方式的趋势下,我们又回到了语言这种交互形式上。
原始的交互方式,就是人与人用语言、动作、眼神交互,人与物用动作交互。机器刚出现的时候,并没有人机交互的理念,机器很难操作,需要人去学习和适应。肖尔斯的“QWERTY”键盘会流传开来就是因为这种字母的排列设计可以降低打字速度,避免快速输入造成按键连杆的互相干涉。
二战期间的研究促进了人因工程的发展,机器适应人类、提高人的效率的理念得到发展。在计算机领域,从命令行界面(CLI)进入到图形用户界面(GUI)是一大突破,随后发展到目前的主流操作方式触控,使用手指在屏幕上滑动点按。语音交互界面(Voice User Interface,VUI)、手势、动作、表情交互,甚至脑机接口,都属于自然用户界面(NUI)。
从载体上分,语音交互以手机或电脑为载体,或以其他硬件为载体。除了这些,在客服、教育和医疗等行业也都有应用,如客服语音质检、口语测评等。

图1 语音交互界面的形式
如何评价语音交互
VUI的效率高还是低?
高效的交互方式就是好的交互方式。人机交互在于提高人的使用表现,从速度、准确性、注意负荷三个维度衡量。让用户速度越快、越准确,并且占用最少注意负荷的就是好的交互。我们来看几种情况。
输入文本:效率极高。人说话的速度比打字快,且不需要分心看屏幕,考虑到打字输入也有错误,语音交互在输入文本表现不错。因此很多产品都会在文本输入处加上语音入口。
布置任务:如果我们想打快车回家,用语音助手还是图形界面的打车APP更快?由于路径短,语音助手的理论速度更快,唤醒Siri并说句话,不需要打开APP再点选。在现有状况下,输入任务容易出错。如果命令语言出现偏差,语音助手听不懂你的意思,就会导致任务失败。我们需要思考该怎么布置任务,是说“我要打车回家”还是“打开XX并打车回家”?如果语音助手三次都听不懂命令,你还会继续尝试吗?放弃语音布置任务,只要打开APP,找到熟悉的入口点击操作就完成了。
输出:相比即时的图形反馈,语音是一种不太合格的输出方式,它过于缓慢、效率低下。由于听觉是线性的,我们只能听完一句话再听下一句,而不能像视觉一样瞬间完成图片加工,也不能在文本间扫描跳过,电话语音服务系统就是这种浪费时间的方式。另外,持续听语音还会消耗大量注意和记忆资源,如果客服念完却没有听到想要的内容,重听按0是另一场噩梦。另一方面,我们大部分的信息来自于视觉,但语音方式不能输出视觉信息。
适合双手被占用的场合
语音交互适合在哪里使用?双手被占用时,如驾驶、烹饪、游戏等情况。比如,开车时眼睛需要看路,双手握着方向盘,而且车内环境既安静又私密,这种情况下就适合使用语音交互。另外,在输出层面上,如果视觉通道被占用,听觉通道更适合接收紧急和重要的通知。
门槛极低
语音交互的支持者认为,语音是最自然的交互方式。人人都会说话,门槛极低,尤其对于输出困难人群(如视力障碍人群),他们完全可以无障碍的使用语音交互的形式。但是另一方面,习惯触控的人群不一定愿意转向语音,对新技术有畏难情绪的人群也可能不愿意尝试语音交互这种“新”的技术。
语音可以传递情感,但人还不适应和机器交谈
语音由于有声调和节奏,相比文字,更能传递情感。问题在于我们不习惯和机器人或者手机对话,据统计,在公共场合使用Siri的人只有3%。我们默认语言是人和人交流的方式,或是和猫、狗这种我们认为有人性的动物交流的方式。当人与物进行交流时,更多会采用动作交互。因此人和手机说话时会有很奇怪的感觉,尤其对于东方人来说,心理障碍可能会更大。
为了减少用户的压力,拉近心理距离,很多智能语音助手会设定自己的“人物形象”。例如Siri高冷又忠诚,微软小冰可爱又贫嘴。另外,语音助手大多是女性声音,也是因为女性的声音听起来更加和善包容。在操作过程中出现问题,如果响起了男性的声音,容易给使用者产生被责备、被批评的感觉。
不过,语音助手也不能太像真正的人。恐怖谷理论认为,对于和人越来越像的东西,我们的好感会上升,但我们厌恶很像人而不是人的东西,例如僵尸。从恐怖谷的理论来看,我们可能会害怕逼真的语音助手。
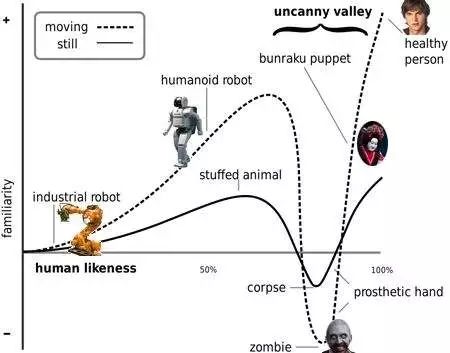
图2 恐怖谷
不适合在公开场合使用
语音交互不适合在公开场合使用,尤其是图书馆、办公室这类安静的场合。
身份识别问题。在汉堡王的一则视频广告里,售货员最后凑近屏幕,说“OK google, what’s the whoppers?”。“OK google”是安卓手机和Google Home的唤醒词,用户会发现在自己没有下达命令的情况下,设备已经启动并搜索了皇堡,这是设备缺少身份识别系统造成的。为此有产品推出了声纹识别系统以保障支付安全问题,至于声纹验证的可靠性则是另外一个问题。
隐私方面也是如此,相比起屏幕,公共场合的输入和输出对话更容易被听到。敏感的金融、医疗和私人信息风险更大。
场景分析
总体来说,语音交互至少需要满足噪音低和私密两条要求,在众多的场景中,车内和家里是满足要求的,加上手机上的移动场景,共3大场景。Mary Meeker在2016年的报告也指出,美国语音使用的主要场景是家里(43%),车上(30%),路上(19%),工作仅占3%。
语音交互发展难点
语音交互系统发展的历史并不短,早在1952年,贝尔实验室就开发了能够识别阿拉伯数字的系统Audrey。1962年,IBM发明了第一台可以用语音进行简单数学计算的机器Shoebox。
在发展了半多个世纪后,语音交互仍没有达到成熟应用的水平,遇到的困难贯穿开发到使用流程。
一套完整的语音交互系统有三个典型模块,语音识别(Automatic Speech Recognition,ASR)将声音转化成文字,自然语言处理过程(Natural Language Processing,NLP)将文字的含义解读出来,并给出反馈,最后通过语音合成(Text to Speech,TTS),将输出信息转化成声音。

图5 典型的语音交互系统模块
远场识别难题
第一个难题是获取语音的问题。语音质量高的前提下,才能有较好的语音识别结果。有些公司宣称自己的语音识别率达到了95%甚至99%,但其前提条件往往是声源距离很近、环境特别安静、说话人的普通话特别标准,而非日常的应用场景。
获取用户语音,根据距离分为近场识别和远场识别两种情况,后者难度更大。
手机上的语音交互是典型的近场,距离声源近,语音信号的质量较高。另一方面,采集语音的交互相对简单,有触摸屏辅助,用户通过点击开始和结束进行信号采集,保证可以录到用户说的话。
远场语音交互以智能音箱为代表,声源远,不知道声源具体位置,环境中存在噪声、混响和反射。单麦克风无法满足要求,需要麦克风阵列支持。用户可能站在任意方位,被语音唤醒后,需要定位到声源位置,向该方向定向拾音,增强语音并降低其他区域和环境的噪声。
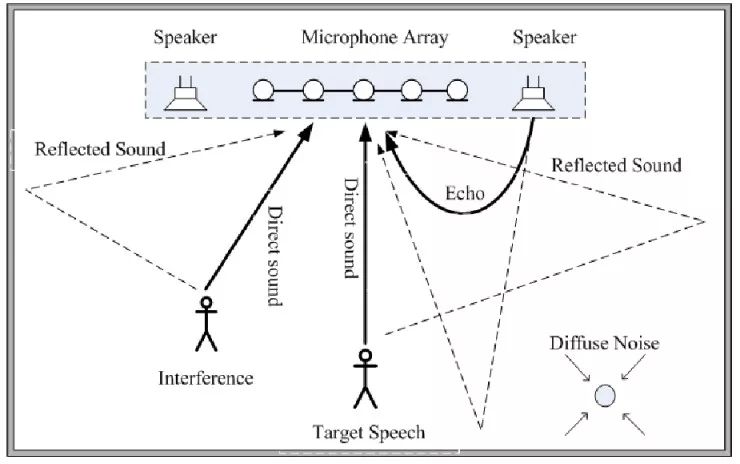
图6 远场识别示意图(来源:雷锋网)
语音识别正确率
实际工作中,常用的指标是识别词错误率(Word Error Rate)。微软语音和对话研究团队负责人黄学东最近宣布微软语音识别系统错误率由5.9%进一步降低到5.1%,可与专业速记员比肩。进步来自于两方面,一是技术,包括隐马尔可夫模型、机器学习和各种信号处理方法,另一方面是庞大的计算资源和训练数据。
语义识别
如果你和语音助手进行过对话,会发现其语义理解还停留在固定模式识别的套路上,根据用户话中特定的词做出反应,不一定能给出正确的回答。
约翰·希尔勒提出过“中文房间”的思想实验,一个不懂中文、会说英语的人在一个封闭房间中,房间里有一本英文手册告知如何处理相应的中文信息。用中文写的问题从窗户递进房间里,这个人对照手册进行查找,将对应的中文写成的解答写在纸上并递出去。房间外的人可能会觉得这个人很懂中文,实际他一窍不通。训练机器来理解语义类似于这个过程。通过训练,我们让机器的反应接近于能够理解,但无法像人类一样真正理解语言。
语言是人和人之间交流的工具,某种程度上适合人的认知系统,如何期待机器更好的理解我们?
目前来讲,遇到的问题至少有分词、歧义和未知语言处理。中文不像英文单词有空格分开,而且歧义性高,对AI有更高的要求。例如“南京市长江大桥”就可以分成“南京市/长江大桥”和“南京市长/江大桥”两种,“鸡不吃了”有多种含义,和Siri说“打开饱了么外卖”,在它没有学过“饱了么”这个单词的情况下,它将如何处理?
多轮对话问题
我们觉得语音助手很蠢,有时是因为它违反了人类对话的原则。人类对话看似简单,但会根据对方的背景和自己掌握的信息,调整对话内容,上下文之间也会有呼应关系。但是,现有的很多产品,其对话缺少关联性,语音助手不理解上下文背景,只能进行单轮对话,看似进行的多轮对话其实也只是多个单轮对话的组合。
“愚蠢”带来的一是不自然,二是增加任务难度。比如当你问语音助手,“明天的天气是什么?”它说下雨,再接着问“后天呢?”,这时它并不明白提问的是后天的天气,只能再完整地问一次“后天的天气是什么?”。
在下面这个对话里,小冰一会儿说阴阳师是游戏,一会儿是电影,并没有对话的记忆。
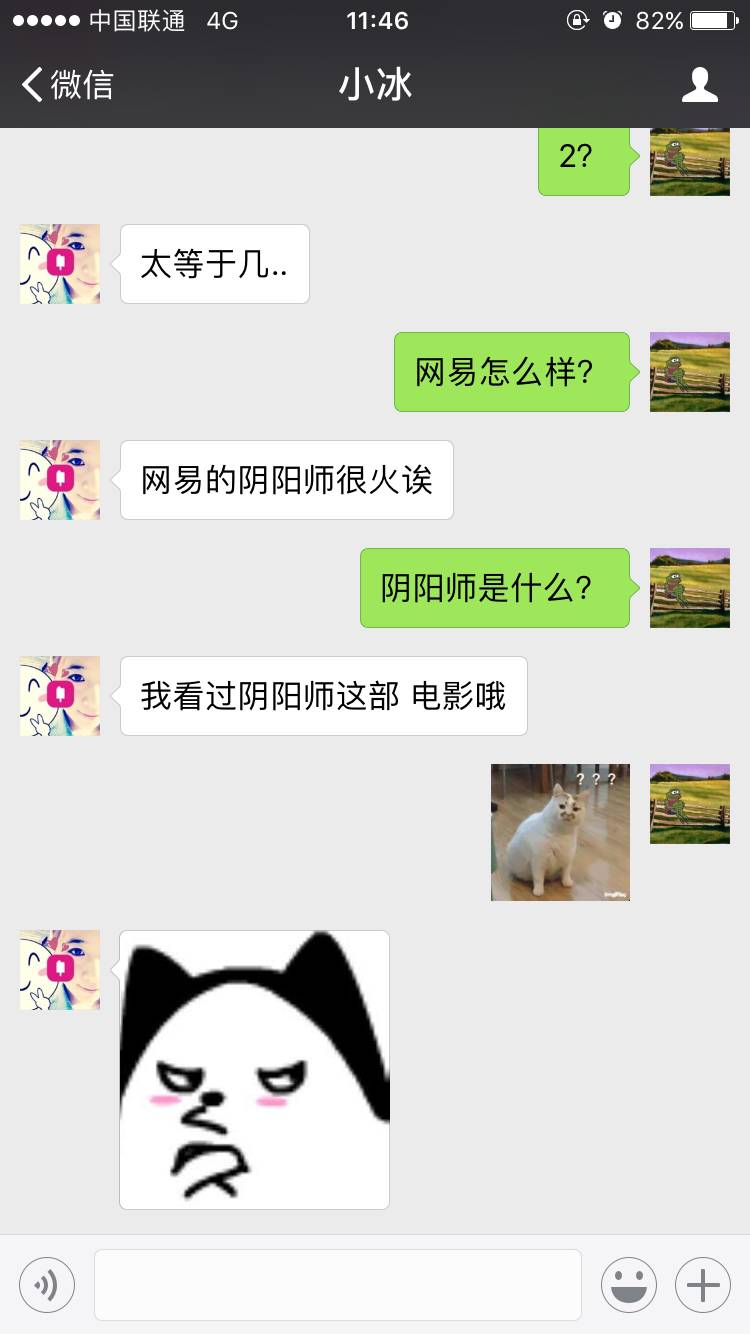
图7 小冰没有对话的记忆
语音交互设计规范
由于语言尤其口语的形式不固定,变化很大,VUI的交互设计和GUI截然不同,更加细致繁琐。亚马逊已经给开发者提供了成熟的交互设计规范。
语音交互设计至少可分为几步:首先建立功能目的;其次撰写脚本,即用户和系统如何对话;第三步是制定流程、用户使用路径等,还需要定义技能的结构,包括完成一个功能需要哪些参数、用语有哪些变化,例如对于同一个功能,用户可以说“天气怎么样”也可以问“外面下雨吗”。
远场语音交互产品的冷启动
远场语音交互产品存在冷启动周期,只有积累了一定数据才可以更好提升产品体验,但如何提高销量、积累数据是产品启动时需要思考的问题。如果希望语音交互产品可以成为平台,千万量级是基本门槛,如果Echo在今年的销量可以达到预计的两千万台,基本上有了足够数据,有成为平台的希望。国内一些模仿者使用节日促销的模式,例如双十一天猫精灵99元的售价,卖出了100万台,希望通过这种方式进行数据的初步积累。
缺乏持续使用动力和核心场景
新鲜劲过去后,很多人会对语音交互失去兴趣,触控仍然是主要的交互方式。Creative Strategies的数据发现,97%的人在两周时间内会对Alexa的新功能失去兴趣。Voice Lab的数据发现,62%的安卓用户很少或者偶尔使用语音助手,这一比例在iOS用户上是70%。目前,语音交互缺乏只有其才能实现的核心功能,即使亚马逊的Echo,它最多的用途仍然是听歌,缺少核心竞争力和不可替代性。
问题讨论
语音交互是否会成为主流交互方式
笔者的意见是,就像触控没有取代鼠标键盘,语音交互不太可能成为主流的交互方式。交互界面本来就是多模态的,语音交互将丰富现有的交互形式而不会取代其他。如前文所述,语音交互不能解决所有问题,只是在特定的场景可以发挥作用。
伴随语音的多交互通道是不错的选择,例如语音和触控结合可以提高准确度,语音和视觉结合,实现语音输入加视觉反馈,或者加上手势等。
是否需要追求语音交互的纯洁性
Echo团队认为,语音是最自然的交互方式,因此坚持设计语音交互,但语音输入和视觉输出的模型已被证明其成功性,我们在手机上使用的语音交互模型就是如此。新品Echo Show也装上了屏幕,可以显示视觉信息了。所以是否有必要坚持纯粹的语音交互模型?答案似乎已经很明显。新问题是,如果Echo加上了屏幕,用户会认为它是音箱还是平板?
语音交互的定位
本质上,语音交互允许人通过语音的方式完成任务,能通过语音完成的,触控也可以,Siri可以做到的,Echo也可以,做不到的大家都做不到。所以语音交互能够完成什么独有的任务以体现它的价值呢?
VUI vs. CUI
语音设计师Cheryl Platz在她的Medium上反复提及一个问题,VUI还是Conversational UI?
语音交互界面是基于单独的任务,它的模式是简单的“下命令——完成任务”,然而这不是自然的对话,我们需要思考如何下命令,距离对话太远了。如果要朝着CUI的目标,语音交互必须更加智能和流畅,允许通过真正的对话完成任务,像和真人说话一样。
隐私问题
如果语音助手要更好用、更智能,就需要不断收集用户的信息。所以我们是否需要语音助手改变自己的反应?如果语音助手目的就是商业的,那么我们是否信任它并提供信息,从而让它更了解我的喜好?
另一方面,语音助手是否安全?通过唤醒词唤醒的语音交互产品会保持待机,从环境中获取声音,这种机制可能被利用。在一则新闻中,Echo被破解并成为了一个24小时窃听器,还有连接方式,德国禁止销售的一款儿童语音玩具“My Friend Cayla”,其蓝牙连接就被证明是不安全的,儿童与玩具对话的语音可能被第三方获取。
语音交互界面的测试方式
和普通产品的研究方法共通,可用性测试、访谈等方法依然适用于研究语音交互系统。测试VUI时可以特别注意一些地方,例如用户的反应,成功率,停顿或者失败等等。有一些特定指标可以用于评估,例如速度准确度、用户付出的认知努力、清晰易懂度、系统友好程度和声音质量等。
下面介绍一个有趣的语音交互界面测试方法:Woz法。由于语音交互系统成本较高,在系统开发前,通过Woz(Wizard of Oz)的原型测试发现问题,成本很低。由一名研究人员扮演Wizard,一名普通研究人员协助,用户操作后,由Wizard在暗处手动播放反馈。
语音交互仍需要发展,技术成熟需要时间。但它的出现意味着我们可以用更多方式操作设备、传递信息,我们离理想的交互界面更近了一步。以上对语音交互做了简单的总结,有疏漏和想法不成熟之处,欢迎交流指正。
参考资料:
- Cathy Pearl. Designing Voice User Interfaces. O’Reilly Media, 2016
- Clifford Nass, Scott Brave . Wired for Speech. MIT Press
- Cheryl Platz. The Narrowing Rift: Voice UI and Conversational UI. Medium: Microsoft Design
- Amazon Alexa:Voice Design Guideline. Amazon
- 极限元,一文读懂智能语音前端处理中的关键问题,雷锋网
作者:汪梅子,网易产品发展部用户研究员,目前对接智能硬件的用户研究工作。喜欢自己不知道的事情,在用户研究的路(树)上继续成长着。
本文作者@武慧新,由@用盐有点咸(微信公众号:用盐有点咸) 授权发布,未经许可,禁止转载。
题图来自unsplash,基于CC0协议










同感 现在的有屏音箱到底是音箱还是平板呢 感觉有相互融合的趋势
很好的文章,很全面