
 起点课堂会员权益
起点课堂会员权益车载产品的语音交互导航场景
语音是人们日常生活中最常用的交互方式,也被逐渐应用车载产品中,本文将以驾车途中最常见的场景——导航场景,简单聊聊语音交互。

一、当前手机app语音导航功能如何?
以高德地图为例,在开启“驾车模式”和“首页摇一摇唤醒语音”后,在首页摇一摇即可语音输入指令。
1. 语音搜索地名
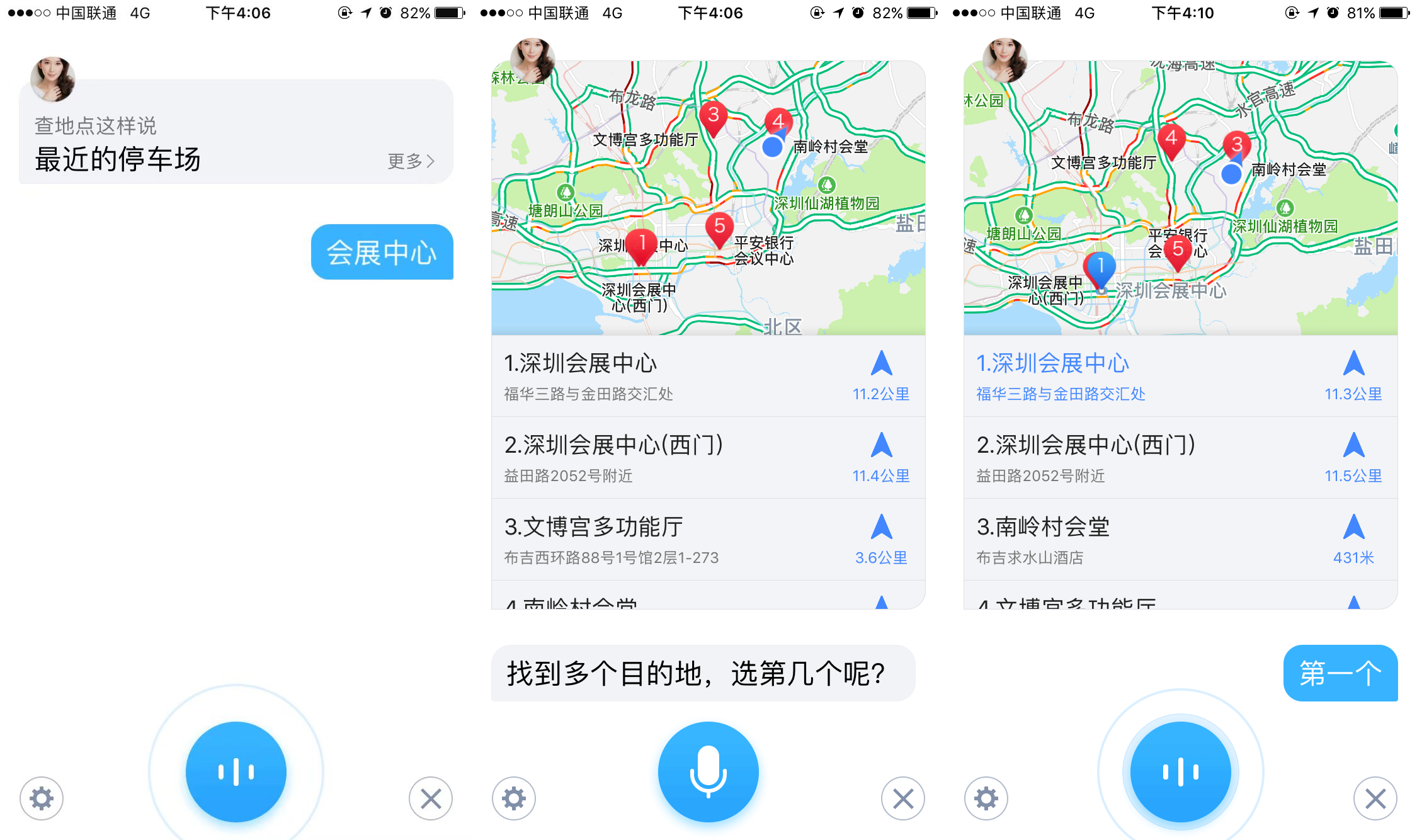
第一步:语音输入地名。测试中发现,目前仅支持地名或行车途中常见的服务站点(加油站、洗手间、服务站等),暂不支持“附近的吃饭地点”智能地点推荐功能。
第二步:根据语音提示选择目的地。测试中发现:目前仅支持“第x个”的固定格式,暂不支持地名或下一页等指令(图中地点有多页)。
第三步:开始导航。
有时,搜索的地名只有一个,便会确认是否开始导航。测试中发现,目前仅支持“是”指令,暂不支持“否”,且多次测试中“是”被高德地图识别为“超市”。
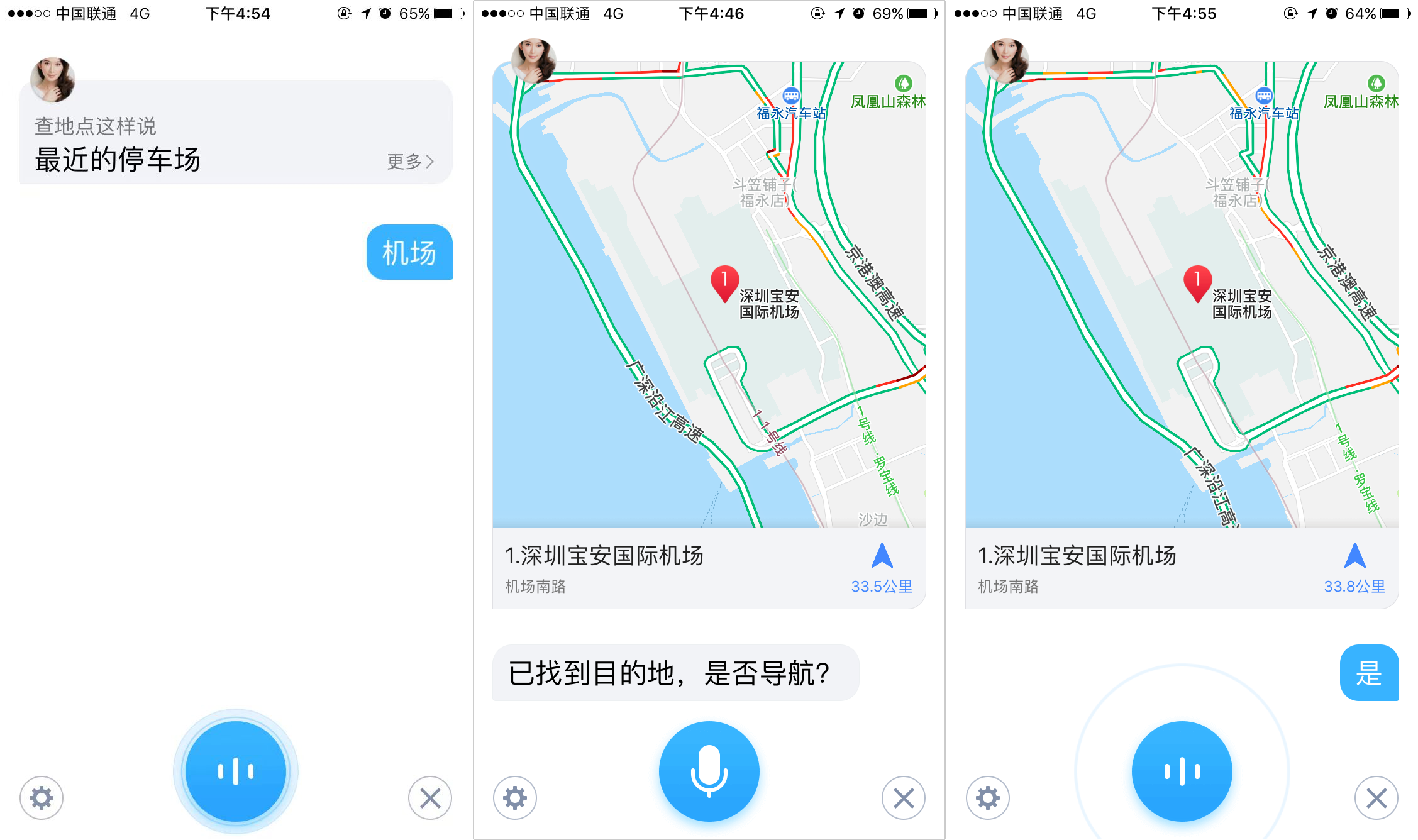
也支持快捷的语音指令,导航到xxx,即直接开始导航。测试中发现,当出现多个类似地点时,默认导航至该地点名单的第一个地点。
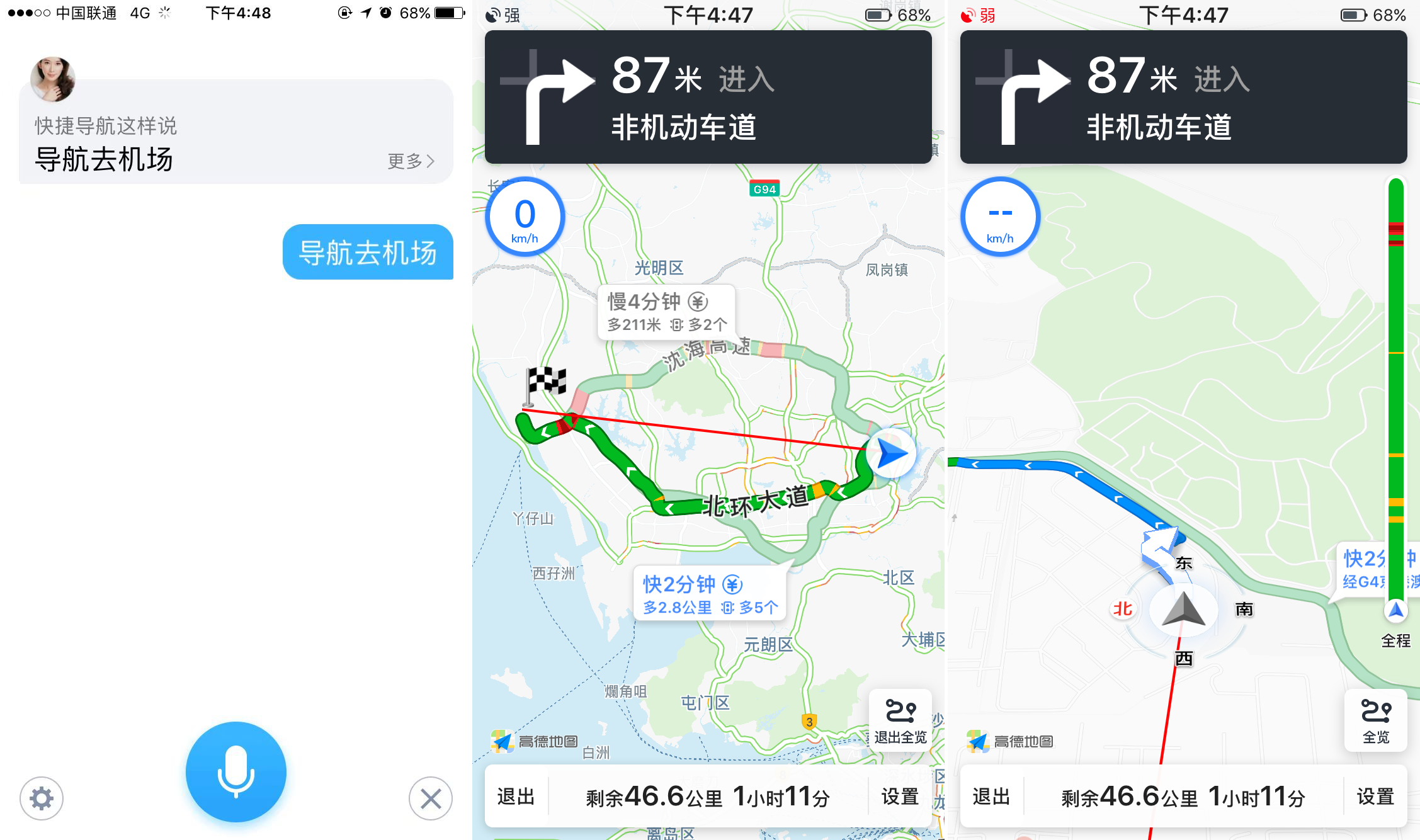
2. 语音导航
语音播报:途径地点、全程路长、预计所需时长、实时路况、监控提醒、服务站提醒。
测试中发现:语音导航中并不支持语音交互,若是需要在路途中寻找洗手间或更改路线,只能手动操作。然而这无疑增加了行车中的风险。
二、设想中的车载语音交互导航是怎样的?
设想应当基于需求,对于车载语音交互导航,用户的需求如下:
- 基本需求:在搜索目的地时可使用语音输入地名
- 期望需求:在导航途中可使用语音修改目的地或增加途经地
- 兴奋需求:在搜索目的地时可提供智能化的地点推荐
1. 基本需求
目前高德地图和部分车载智能中控台已经能做的,核心的关键在于对语音的识别率,这将极大影响语音交互的效率。
语音的高识别率需要大量的语音训练,中国人口音五花八门,各家产品皆很难达到较高的识别率。科大讯飞有语音开发合作平台,语音识别率达98%,与他们合作能极大的提高开发效益。
2. 期望需求
目前比较少见,常见的应用场景是滴滴拼车,拼完座后,高德地图会导航司机用最短的路程接完乘客并送达乘客到目的地,但高德地图并没有在C端产品上开放出该功能。
修改目的地和增加途经地只需要重新规划路线,该需求实现的核心在于对语音的高识别率、降噪和回音消除。行车途中若是对指识别错误,可能会导致导航错误,影响用户驾车情绪,增大行车风险。且高速驾驶中噪音较大,可能还会遇到车窗打开、车内喧哗等场景,降噪和回音消除是导航中保证语音高识别率的基础。
3. 兴奋需求
其实是一个低频需求,大部分的用户在开车前便已有了目的地,未有目的地的时候,也会现在美团或大众点评等平台上选好目的地,再上车。很少会出现,坐上了车,才想着要去哪里的场景。可能存在的场景是,用户在行车途中突然想改变目的地,或出来玩耍后未尽兴想继续玩,但不知道去哪里。
高德地图上便有附近地点的搜索,美团与大众点评等O2O平台上亦有附近商家推荐,与这两者合作,便能解决该需求。
三、语音交互导航的流程
如何去达成良好的车载语音交互导航体验,这里将以独立车载智能中控台的初次接入场景和导航场景为例进行说明。
1. 初次接入流程

接通电源:大部分独立车载智能中控台都不具备储电功能,需要在车上接电。然而车内环境狭小,也较为复杂,不同车型内饰也各有差异,需要在说明书上用通用的方式指引用户给中控台接通电源。
接通手机或汽车与中控台:应注意保持行车途中信号的稳定性。
进行新手引导:
- 自我介绍:产品角色亮相,支持功能介绍
- 基本规则介绍:让用户了解语音交互的基本使用方式
- 引导用户完成基本设置:家庭/公司地址设置、声纹识别等常用功能或隐私设置
需要注意的是:新手引导是极易被用户跳过或不用心听的,应该在新手引导后仍有触达用户的方式,让他们了解语音交互的基本使用方式或完成基本设置。
2. 导航场景

唤醒:
- 语音唤醒:当用户需要使用中控台是唤醒它,为了避免误唤醒,通常会将唤醒词设置为3~4个词,如“小飞鱼”,三字词和四字词在汉语中是相对较为低频的,有助于提高唤醒的准确率。可以使用定向语音,即只有固定位置的人说话才会被收录,只开放给驾驶位和副驾驶位。
- 唤醒反馈:中控台被唤醒后,进行反馈。简单的反馈可以是“叮”一声,但这样显得太冷漠,最好是使用“我在”“你说”等人性化的回应词或语句。
设置目的地:
(1)语音输入
这里以导航为例,用户输入的语音可能为“导航到会展中心”“会展中心”“去会展中心”“我想去会展中心”,需要对地名、“导航”、“去”的识别较为准确。
与唤醒词不同,目的地的语音通常为一句话,所包含的字词会较为复杂。语句的识别可简单划分为5个步骤:
- 判断语音结束点:判断从发声到结束,截取声音片段。
- 提取有效信息:将声音片段识别成一个个发音。
- 识别:将发音与文字匹配,将发音识别成特定的文字。
- 自然语言理解:根据算法理解语意。
- 对话管理:根据语意进行回复,引导进行下一轮的对话。
目前对话管理有两种识别模型,一种是使用人工定义回复的内容,另一种是通过机器学习的算法,提供自然语言的回复。
除开语句识别技术外,还要保障有清晰的声音获取。行车途中,难免会遇到较为嘈杂的环境,如车窗大开、高速驾驶、车内喧哗和空调声大等,需要进行降噪。目前比较常见的技术手段是使用双麦克风阵列降噪和回声消除。
(2)识别反馈
对输入的语音内容给予反馈。
- 识别完成反馈:“为你找到深圳会展中心,位于福华三路与金田路交汇处,是否导航”。
- 识别错误反馈:“抱歉,没有听清,请再说一遍”,需要注意的是,若是多次识别错误,可能是用户没有正确遵循语音交互规则,此时可进行基本规则介绍。
开始导航:
(1)确认是否开始导航
若用户回复“是”或“开始”,则上一步识别正确,开始导航。
若用户回复“否”或“取消”,则说明上一步识别错误,应重新设置目的地,应回复用户“主人,你想去哪儿呢?”,并进入设置目的地步骤的语音输入环节。
若用户回复其他“地名”,则说明上一步识别错误,应更改目的地,回复“为你找到深圳大剧院,位于深圳市罗湖区,是否导航”。
若识别错误,则回复“抱歉,没有听清,请问是否开始导航?”,重复识别错误3次,应当退出导航功能,避免用户不良情绪的积累。
(2)开始导航提示
提示用户导航已经开始,对行车里程、预计时长、路途车况、途经地点等内容进行播报。
如:“准备出发,路程约为14公里,目前道路通畅,预计需要28分钟,途经泥岗西路、红荔路、金田路,祝你一路顺风。”
(3)导航中语音交互规则介绍
行车途中,常见的需求有规避拥堵、更改目的地、寻找加油站、寻找服务站、寻找洗手间、寻找充电站等。长期以来,各类手机导航app和车机中控台在导航中都需要用手操作去更改路线,但这样会带来严重的行车风险。时速60km/h时,操作手机3s,就相当于盲开50m,发生事故的概率是平时的23倍。
用户并不知道行车途中可以使用语音交互进行指令,也不知道如何进行语音交互,故在前3次中导航,可进行导航中语音交互规则介绍。
这类语音交互是基于导航场景中的,故该部分的功能也应该在导航中才可有效开启。如“前方还有多远到达充电站”。
导航中:
(1)路况播报
常见的如前方拥堵、监控提醒、服务站提醒等。
当前方发生较大拥堵时,用户会有规避拥堵的需求,可询问用户“前方发生拥堵,预计通过时长为40分钟,是否规避拥堵?”,若用户在多次遇到拥堵时选择规避,则可默认帮用户进行规避拥堵,并提示“前方发生拥堵,预计通过时长为40分钟,已为你规避拥堵,节省拥堵时间30分钟。”
(2)输入语音指令
常见的如寻找附近的洗手间、增加途经地、更改目的地、规避拥堵等。需要注意的是,增加途经地的指令,在导航到达途经地后需继续原目的地的导航。
如:用户在长途行驶时,常会前往服务站休息或加油,会使用语音“去最近的服务站”,导航到最近的服务站后,用户下车休息一段时间返回车上,仅需一句“继续刚才的导航”,即可继续导航至原目的地。
有时,用户可能会听不清路况播报的内容,而输入语音“重复刚来的内容”、“我没有听清”。
这些语音指令都需要结合导航途中的不同场景来做具体的流程设计。
(3)识别反馈
需根据具体场景来提供识别反馈。
如:用户没有听清路况播报时,反馈“为你重新播放刚刚的内容,前方发生拥堵,预计通过时长为40分钟,是否规避拥堵?”
如:用户在长途行驶中,添加途径地服务站,导航至服务站后,在提示完“已到达服务站”后,可询问用户“是否继续导航至深圳大剧院?”
导航结束:
(1)结束导航提示
提示用户导航已结束。导航结束通常有两种场景,一是已到达目的地,此时提示“已到达目的地,导航已结束”,二是用户退出导航,此时提示“导航已结束”
(2)进入休眠状态
导航结束后,自动进入休眠状态,等待下一次唤醒。
完~
本文由 @陈想吃 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash,基于CC0协议。









你是不死用到了假的高德导航了哦?!多久测试的结果?
请问能否转载至公众号?
你公众号多少?我给你开白名单
AutoinFuture,谢谢~
陈建川?